
笔者链接:扑克中的黑桃A
专栏链接:论文精读
本文关键词 : 运行时配置; 配置理解; 配置缺陷检测; 配置故障诊断; 配置应用
引
诸位技术同仁:
本系列将系统精读的方式,深入剖析计算机科学顶级期刊/会议论文,聚焦前沿突破的核心机理与工程实现。
通过严谨的学术剖析,解耦研究范式、技术方案及实证方法,揭示创新本质。我们重点关注理论-工程交汇点的技术跃迁,提炼可迁移的方法论锚点,助力诸位的技术实践与复杂问题攻坚,共推领域持续演进。

每日一句
永远不要被阴云吓倒,
只要我们相信自己,
只要我们敢于接受挑战,
我们的心就会得到冶炼,
我们的前路就不会永远黑暗。

目录
[一.软件运行时配置:为何 "调节系统" 如此关键?](#一.软件运行时配置:为何 “调节系统” 如此关键?)
[1. 运行时配置的独特属性与风险](#1. 运行时配置的独特属性与风险)
[(1) 动态可调性句号](#(1) 动态可调性句号)
[(2) 规模与复杂性句号](#(2) 规模与复杂性句号)
[(3) 功能与性能双重影响句号](#(3) 功能与性能双重影响句号)
[(4) 高故障风险句号](#(4) 高故障风险句号)
[2. 配置研究的发展脉络与防御窗口](#2. 配置研究的发展脉络与防御窗口)
[(1) 设计阶段句号](#(1) 设计阶段句号)
[(2) 部署前阶段句号](#(2) 部署前阶段句号)
[(3) 运行阶段句号](#(3) 运行阶段句号)
[二.三阶段研究框架:配置管理的 "全生命周期防护"](#二.三阶段研究框架:配置管理的 “全生命周期防护”)
[1. 配置分析与理解:摸清 "调节旋钮" 的原理](#1. 配置分析与理解:摸清 “调节旋钮” 的原理)
[(1).配置设计理解:解析 "调节系统" 的设计逻辑](#(1).配置设计理解:解析 “调节系统” 的设计逻辑)
[(2).配置约束提取:挖掘 "调节规则" 的隐藏密码](#(2).配置约束提取:挖掘 “调节规则” 的隐藏密码)
[(3).配置影响域分析:追踪 "调节操作" 的连锁反应](#(3).配置影响域分析:追踪 “调节操作” 的连锁反应)
[2. 配置缺陷检测与故障诊断:筑牢 "故障防护墙"](#2. 配置缺陷检测与故障诊断:筑牢 “故障防护墙”)
[(1).配置故障调研:盘点 "故障病历本"](#(1).配置故障调研:盘点 “故障病历本”)
[(2).配置缺陷检测:提前排查 "潜在隐患"](#(2).配置缺陷检测:提前排查 “潜在隐患”)
[(3).配置故障预防:设置 "安全警戒线"](#(3).配置故障预防:设置 “安全警戒线”)
[(4).配置故障诊断与修复:快速 "故障抢修"](#(4).配置故障诊断与修复:快速 “故障抢修”)
[3. 配置应用研究:让 "调节系统" 高效运转](#3. 配置应用研究:让 “调节系统” 高效运转)
[(1).配置参数推荐:找到 "最相关的旋钮"](#(1).配置参数推荐:找到 “最相关的旋钮”)
[(2).配置性能调优:拧到 "最佳挡位"](#(2).配置性能调优:拧到 “最佳挡位”)
[三.研究现状对比:国内外的 "技术路径差异"](#三.研究现状对比:国内外的 “技术路径差异”)
[1. 技术选择偏好差异](#1. 技术选择偏好差异)
[2. 漏洞与平台覆盖差异](#2. 漏洞与平台覆盖差异)
[3. 实验数据与开源情况差异](#3. 实验数据与开源情况差异)
[4. 对比实验与评估体系差异](#4. 对比实验与评估体系差异)
[四.核心挑战:配置研究的 "拦路虎"](#四.核心挑战:配置研究的 “拦路虎”)
[1. 配置复杂性与规模难题](#1. 配置复杂性与规模难题)
[2. 跨平台与动态环境适配](#2. 跨平台与动态环境适配)
[3. 误报率与自动化修复瓶颈](#3. 误报率与自动化修复瓶颈)
[4. 缺乏统一标准与评估体系](#4. 缺乏统一标准与评估体系)
[五.未来方向:构建 "智能配置管理系统"](#五.未来方向:构建 “智能配置管理系统”)
[1. 配置分析与理解的深化](#1. 配置分析与理解的深化)
[2. 缺陷检测与诊断的升级](#2. 缺陷检测与诊断的升级)
[3. 配置应用的智能化](#3. 配置应用的智能化)
[4. 标准与生态建设](#4. 标准与生态建设)
[六.实用工具推荐:配置管理的 "利器"](#六.实用工具推荐:配置管理的 “利器”)
[1. 配置分析与理解工具](#1. 配置分析与理解工具)
[Slither 句号](#Slither 句号)
[ConfMapper 句号](#ConfMapper 句号)
[EnCore 句号](#EnCore 句号)
[2. 缺陷检测与诊断工具](#2. 缺陷检测与诊断工具)
[SPEX 句号](#SPEX 句号)
[ConfDiagnoser 句号](#ConfDiagnoser 句号)
[X - ray 句号](#X - ray 句号)
[3. 配置应用工具](#3. 配置应用工具)
[BestConfig 句号](#BestConfig 句号)
[OtterTune 句号](#OtterTune 句号)
[PrefFinder 句号](#PrefFinder 句号)
[七.总结:配置是软件的 "神经调节系统"](#七.总结:配置是软件的 “神经调节系统”)
文献来源
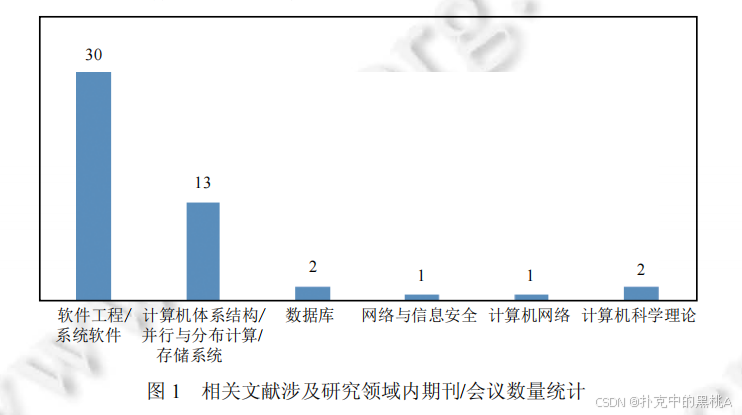
周书林, 李姗姗, 董威, 王戟, 廖湘科. 软件运行时配置研究综述.
软件学报, 2024, 35(1): 63--86.
DOI:10.13328/j.cnki.jos.006835
已标明出处,如有侵权请联系笔者。
在数字化时代,软件系统就像城市的 "电力网络",从我们每天用的办公软件到支撑银行交易的后台系统,都在默默运转。而软件运行时配置,就像是这个网络里的 "智能调节站"------ 通过调整各种参数旋钮,让软件能适应不同场景:比如突然涌入的用户流量、不同的硬件环境,甚至是用户的个性化需求。但这个 "调节站" 如果出问题,后果可能很严重:Google 曾统计,29% 的服务崩溃是因为配置错误;亚马逊、Salesforce 等大公司更是因为一个小小的配置参数设错,导致全球服务瘫痪,损失数亿美元。
《软件运行时配置研究综述》就像一本 "配置调节站维修手册",梳理了 2011 - 2022 年 122 项核心研究,把配置管理分成 "看懂旋钮""排查故障""高效调参" 三个阶段,帮我们搞懂怎么让这个 "调节站" 安全又高效地运转。不管你是写软件的开发者、维护系统的运维人员,还是研究技术的学者,这篇解读都能让你明白配置管理的关键技巧。
一.软件运行时配置:为何 "调节系统" 如此关键?
软件运行时配置可不是简单的参数列表,它更像家里的 "智能家电控制面板"。你用空调遥控器调节温度、风速,不用断电重启,空调立马响应;软件也是一样,通过修改配置参数,不用重新安装,就能切换功能、调整性能。但如果面板上的按钮太多、说明不清,你很可能按错键 ------ 软件配置也是如此,参数复杂、规则隐晦,很容易出问题。
1. 运行时配置的独特属性与风险
软件配置的 "脾气" 很特别,这些特点让它既灵活又危险,就像一把 "双刃剑"。
(1) 动态可调性句号
运行时配置最方便的一点是 "即改即用"。比如你用 MySQL 数据库时,发现连接数不够了,改一下 max_connections 参数,不用重启数据库,新的连接就能进来;就像调节风扇档位,拧一下旋钮,风速立马变化。
但这种 "即时生效" 也藏着风险:如果把 cache_size(缓存大小)设太大,内存不够用,软件可能突然崩溃,就像把洗衣机水位设太高导致漏水一样。
(2) 规模与复杂性句号
现在的软件越来越复杂,配置参数多到能让人头昏。Hadoop 这种大数据软件,核心配置文件里有 500 多个参数;就像高端音响的遥控器,按钮密密麻麻,光是 "音量" 就分 "主音量""低音""高音" 好几个。
参数类型也五花八门:有的是数字(如端口号 8080),有的是文字(如日志路径 "/var/log"),还有的是开关(如是否启用加密 enable_ssl = true)。
更麻烦的是参数之间 "互相牵制":比如启用加密功能(enable_ssl = true),就必须同时设置证书路径(ssl_cert),否则软件启动不了;这就像你用烤箱选了 "烧烤模式",就必须把烤盘放进去,不然会报错。
如果不懂这些 "隐藏规则",很容易按错键。
(3) 功能与性能双重影响句号
配置参数能同时影响软件的 "能做什么" 和 "做得快不快"。功能上,把 log_level 设为 "debug",软件会记录详细日志帮你找问题,但可能泄露敏感信息;就像监控摄像头开了 "夜视模式",看得清楚但耗电更多。
性能上,配置的影响更明显:研究发现,光调整文件系统的几个配置参数,软件速度能差 9 倍!MySQL 里 20% 的配置错误,会让查询速度变慢 5 倍以上。
还有些 "反直觉" 的情况:比如 JVM 的 heap_size(内存大小)设太小,软件会频繁卡顿;设太大,反而启动变慢。这就像自行车轮胎打气,太少骑不动,太多容易爆胎,得找到 "Goldilocks zone"(刚刚好的范围)。
(4) 高故障风险句号
配置故障就像 "隐形杀手",隐蔽又破坏力强。研究人员分析了 546 个真实故障案例,发现 70% - 85.5% 是参数设错导致的:有的是格式错误(比如把端口号写成文字),有的是取值离谱(比如把超时时间设为 1 毫秒),还有的是参数之间 "打架"(比如客户端超时比服务器端短)。
跨软件的配置故障更难查。比如 Hadoop 集群里,"Namenode" 的块大小和 "Datanode" 的磁盘块大小不匹配,数据就会读写失败;这就像不同品牌的充电器混用,可能充不上电甚至损坏设备。41% 的配置故障要查超过 24 小时,就因为参数之间的关系太复杂,像一团乱麻。
2. 配置研究的发展脉络与防御窗口
关于软件配置的研究,就像医生研究 "怎么预防和治疗配置故障",已经成了软件工程领域的热门课题。
预防配置故障有三个关键 "时间窗口",就像预防疾病要 "早发现、早干预":
(1) 设计阶段句号
从源头简化配置,就像家电厂商设计遥控器时只保留常用按钮。研究发现,54.1% 的配置参数从来没人改过,47.4% 的数字参数用户只用过不到 5 个值。这意味着很多参数是 "多余的",就像遥控器上的 "定时关机" 按钮,你可能一年都用不上一次。把这些 "僵尸参数" 删掉,用户就不容易按错了。
(2) 部署前阶段句号
部署软件前检查配置是否合法,就像出门前检查门窗是否关好。工具可以自动核对 "基础规则":比如端口号必须在 1 - 65535 之间,文件路径必须存在;复杂一点的,比如分布式系统里所有服务器的 cluster_id 必须一样,就像全班同学的校服必须统一。
(3) 运行阶段句号
软件运行中监控配置异常,就像家里的烟雾报警器,有问题立马提醒。监控工具能捕捉到 "配置无效""参数冲突导致功能变慢" 等信号,触发告警;性能调优工具还能根据实时情况动态调参,比如用户变多了,自动增加服务器的 thread_pool_size(线程池大小),就像空调感应到房间人多,自动调高风速。
二.三阶段研究框架:配置管理的 "全生命周期防护"
软件运行时配置研究可按用户使用逻辑分为三个递进阶段,每个阶段聚焦不同目标:配置分析与理解旨在 "懂参数、知规则",配置缺陷检测与故障诊断聚焦 "防故障、快修复",配置应用研究则致力于 "用好配置、提效降本"。三阶段形成闭环,共同保障配置的安全高效使用。
就像养植物,要经历 "了解它的生长规律""防治病虫害""让它长得更好" 三个阶段。这三个阶段环环相扣,缺一不可。
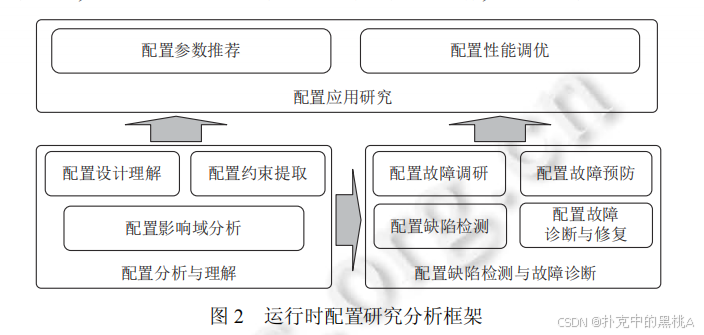
1. 配置分析与理解:摸清 "调节旋钮" 的原理
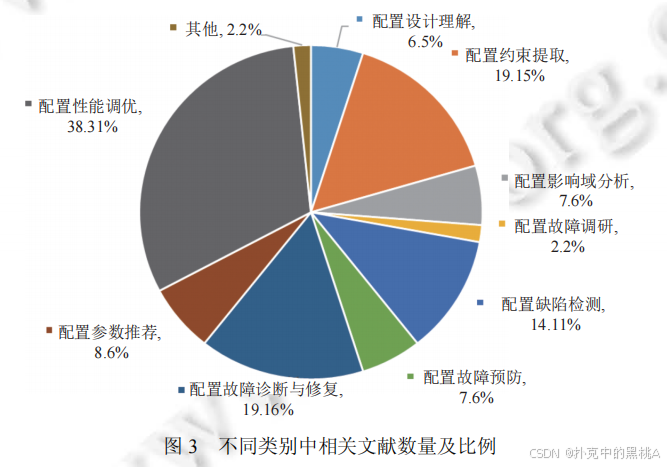
配置分析与理解是配置管理的基础,目标是揭示配置的设计逻辑、约束规则和影响范围,帮助用户从 "盲目调参" 转向 "理性配置"。该阶段包含配置设计理解、配置约束提取和配置影响域分析三大研究方向。
就像要想用好配置,得先搞懂每个 "旋钮" 是干嘛的、有什么规则、拧动后会影响哪里。这就像用新家电前读说明书,知道 "温度旋钮" 怎么用、不能超过多少度、调温度会影响耗电。
(1).配置设计理解:解析 "调节系统" 的设计逻辑
配置设计理解通过挖掘源码中的配置模式与演化规律,揭示开发者如何设计参数功能、交互关系和维护策略,为配置优化提供依据。
研究配置的设计逻辑,就像拆解开遥控器,看看厂商为什么这么设计按钮 ------ 哪些按钮常用、按钮之间怎么联动、更新换代时按钮怎么变。
参数设计与使用特征句号
学者们分析了 620 份用户配置故障报告,发现了一个有趣的现象:很多参数是 "摆设"。54.1% 的参数从来没人改过,就像遥控器上的 "童锁" 按钮,大部分人可能都不知道它的存在;47.4% 的数字参数用户只用过不到 5 个值,比如把 "亮度" 只设过 "低、中、高" 三档。
用户更爱改 "性能按钮"(如缓存大小)和 "功能开关"(如是否开日志),对 "技术细节按钮"(如线程池实现方式)兴趣不大。这给开发者提了个醒:配置设计要 "抓大放小",把常用参数放显眼位置,复杂参数藏起来,就像遥控器把 "音量""频道" 放最容易按到的地方。
配置框架选择与影响句号
软件里的 "配置框架" 就像遥控器的 "芯片",决定了能支持多少功能。研究人员分析了 GitHub 上 1938 个 Java 项目,发现有 11 种常用 "芯片":基础款(如 Java Properties)简单轻便,但功能少,不支持复杂参数;高级款(如 Typesafe Config)能支持嵌套参数、环境变量,但占内存大,就像智能遥控器功能多但耗电快。
小项目选基础款够用就行,大项目就得权衡功能和成本,优先选社区活跃的框架 ------ 就像买手机选销量高的型号,维修和更新更方便。
配置演化规律句号
软件升级时,配置参数也会 "进化"。学者追踪了 4 款云计算软件的更新历史,总结出 16 种 "进化模式":比如 50% 的 "常量变参数"(把代码里写死的数值改成可配置),都是因为这个值在某些环境下出了问题。就像最初的空调温度只能设 26 度,后来发现有人觉得冷、有人觉得热,就改成了可调节的旋钮。
但参数 "进化" 也有问题:23% 的参数被改名或删掉后,说明书没及时更新,用户还在按旧按钮,结果当然没用。这就像家电升级后遥控器按钮变了,但说明书还是老版本,让人 confusion。
工程实践与挑战句号
配置管理的 "最佳实践" 就像使用遥控器的 "注意事项"。学者通过访谈 50 家企业,总结出 9 条核心规则:比如 "新增参数必须写说明书""改配置要先在小范围测试""敏感参数(如密码)要加密存"。
但实际操作中问题不少:不同团队的配置规则不统一、说明书和实际功能对不上、改配置前不知道会影响什么。为此,研究人员开发了 Config2Code 工具,像 "配置管理小助手",自动帮你完成 "加参数 - 写文档 - 建测试" 的流程,让效率提升 40%。
(2).配置约束提取:挖掘 "调节规则" 的隐藏密码
配置约束就是参数的 "使用说明书",告诉你 "这个按钮能拧到多少""按了 A 按钮必须同时按 B 按钮"。提取这些规则,就像从一堆杂乱的说明里整理出清晰的操作指南。
基于源码分析的约束提取句号
软件源码里藏着最权威的约束规则,就像遥控器的电路设计图能告诉你每个按钮的作用。Xu 等人开发的 SPEX 工具,能像 "电路检测仪" 一样分析源码,找出 5 类规则:
类型约束:比如 "port 必须是数字",就像 "音量旋钮只能转数字,不能输入文字";
取值范围:比如 "timeout 必须大于 0",就像 "空调温度不能低于 16 度";
取值集合:比如 "log_level 只能选 debug/info/warn/error",就像 "洗衣机模式只能选标准 / 快速 / 轻柔";
取值关联:比如 "启用 SSL 时,ssl_cert 不能空",就像 "选烧烤模式时,必须放烤盘";
依赖关系 :比如 "用代理时必须填代理地址",就像 "用蓝牙耳机前必须先开机"。
SPEX 在 Httpd、MySQL 里提取规则的准确率达 87%,但太复杂的跨函数规则可能漏检,就像电路太复杂,检测仪偶尔会看走眼。
针对 C/C++ 软件的 "怪脾气"(比如宏定义、指针),Zhou 等人开发了 ConfMapper 工具,专门定位参数在源码里对应的变量。就像找到遥控器上 "音量 +" 按钮对应的内部线路,在 Nginx、Redis 等软件里,它的 "找线" 准确率达 91%。
基于样本数据的约束挖掘句号
如果看不到源码,也能通过分析大量正确的配置样本总结规则,就像观察别人怎么用遥控器,总结出 "按'静音'后再按'音量 +'会取消静音" 的规律。Zhang 等人的 EnCore 工具分析 thousands 个正确配置,能发现两类规则:
- 环境关联:比如 "内存大于 32GB 时,heap_size 通常设 8GB 以上",就像 "冬天开空调,温度通常设 24 度以上";
- 参数关联 :比如 "max_connections 和 thread_cache_size 通常 10:1 搭配",就像 "空调温度设 26 度时,风速常用自动档"。
ConfigV 工具更灵活,就算样本里有错误配置也能分析,通过统计 "90% 的人都这么设" 来提炼规则,就像 "虽然有人把空调温度设 30 度,但 90% 的人设 24 - 26 度,所以推荐这个范围"。
基于文本语义的约束提取句号
配置文档、日志里也藏着规则,就像家电广告、故障提示里能找到使用说明。Xu 等人的 ConfTypeInferer 工具能通过参数名字猜类型:含 "port" 的多是数字,含 "path" 的多是路径,准确率 89%;不确定的就去源码里验证,就像不确定 "定时" 按钮怎么用,去看电路原理图确认。
Xiang 等人发现,60% 的用户手册里有明确规则(如 "max_users 不能超过许可证数量"),但 97% 的软件没在代码里加检查 ------ 就像说明书说 "不能用湿手按按钮",但遥控器没做防水设计。他们开发的 PracExtractor 工具能从手册里提取这些规则,生成自动检查代码,就像给遥控器加个 "防湿手" 提示灯。
软件日志里也有线索,比如日志里 "invalid timeout: 0, must be> 0" 直接告诉你 "timeout 必须大于 0"。Zhou 等人的 ConfInLog 工具能从日志里 "抓" 出这些规则,准确率 85%,就像从家电报错提示里学使用规则。

(3).配置影响域分析:追踪 "调节操作" 的连锁反应
改配置参数后会影响软件的哪些功能?就像调空调温度会影响耗电、房间湿度,需要搞清楚 "连锁反应"。这对测试和故障排查很重要。
配置交互识别句号
有些功能需要 "多个按钮一起按" 才能触发,就像电视的 "投屏功能" 需要同时按 "信号源" 和 "投屏" 按钮。软件里的 "配置交互" 也是如此:比如 Hadoop 里 "map_reduce = true" 且 "combine_enabled = true" 一起设,才能触发某段优化代码,单独设一个没用。
Song 等人的 iTree 工具就像 "功能探索员",通过动态测试和决策树算法,找出这些 "组合按钮" 的规则。Nguyen 等人的 iGen 工具更厉害,能支持复杂的 "或关系" 规则(比如 "参数 A=1 或者参数 B=2 都能触发功能"),准确率提升 20%。
污点传播分析句号
追踪参数取值在软件里的传播路径,就像追踪 "一滴墨水在水里怎么扩散"。Lillack 等人的 Lotrack 工具把配置参数当 "墨水",追踪它影响哪些代码。和传统方法比,它只盯和配置直接相关的代码,范围缩小 60%。比如在 Apache Tomcat 里,它能精准找到 "max_threads 参数影响的线程池代码",就像知道 "调节水龙头流量会影响水管哪个部位的压力"。
交互复杂性度量句号
参数之间的 "互动" 越复杂,软件越难调。Meinicke 等人的 VarexJ 工具能给这种复杂性 "打分":比如 "控制流交互度" 看参数组合影响多少代码分支,"数据流交互度" 看影响多少数据依赖。结果发现,分布式系统的 "互动分" 是单机软件的 3 - 5 倍,就像中央空调的调节复杂度比单台空调高得多,因为要协调多个房间的温度。
配置敏感的变更影响分析句号
改参数后哪些代码会变?Angerer 等人的方法就像 "交通导航",在地图上标出 "改了 A 参数后,B、C 路段会受影响"。这能帮测试人员精准选择要测的代码,在回归测试中减少 35% 的测试用例,就像修路时只封受影响的车道,不用全路封闭。
2. 配置缺陷检测与故障诊断:筑牢 "故障防护墙"
就算配置设计得再好,也可能出故障。这一阶段就像 "家电维修",包括 "统计常见故障""提前排查隐患""故障发生后快速修" 三个步骤。
(1).配置故障调研:盘点 "故障病历本"
分析真实故障案例,就像医生总结 "常见病病历",知道哪些问题最常见、怎么发生的。
功能故障特征句号
Yin 等人分析了 546 个配置故障,发现:
- 70% - 85.5% 是参数设错(比如格式不对、值太离谱);10% - 20% 是版本不兼容(新软件用旧参数);4% - 9% 是组件冲突(A 软件和 B 软件参数不匹配)。
- 最容易犯的错是 "违反基础规则"(38.1% - 53.7%),比如端口号写负数,就像把空调温度设成 - 10 度;其次是 "参数打架"(12.2% - 29.7%),比如客户端超时比服务器短,就像你定了 5 分钟后关火,但锅里的菜要煮 10 分钟。
- 63% 的故障会让软件直接 "罢工",28% 让功能变弱,9% 只报错但还能用。41% 的故障要查一天以上,就因为没明确的错误提示,像家电坏了只闪红灯,不告诉你哪里坏了。
性能故障特征句号
Han 等人研究了 193 个性能故障,发现 59% 是配置问题导致的,而且:
- 性能故障很 "挑值":比如
cache_size超过内存 80%,速度立马慢 70%,就像汽车超速后发动机无力。 - 隐蔽性强:67% 的性能故障没明显报错,只是变慢,容易被当成 "人太多",就像空调积灰后制冷变慢,你可能以为是天气太热。
- 多参数 "合伙捣乱":43% 的性能故障是多个参数设错导致的,比如 "连接数设太大 + 线程缓存设太小",会让 CPU 忙着创建线程,没空处理业务,就像同时开太多 app 导致手机卡顿。
(2).配置缺陷检测:提前排查 "潜在隐患"
检测配置相关的代码缺陷,就像出厂前检查遥控器按键是否灵敏、电路是否短路,避免用户拿到手就出问题。
功能代码缺陷检测句号
Behrang 等人的 SCIC 工具能发现 "虚假按钮"------ 说明书上有这个参数,但软件里根本没实现功能。在 Httpd 和 MySQL 里,它找到 15% 这样的 "假参数",就像遥控器上的 "定时" 按钮按了没反应。
Toman 等人的 Staccato 工具专门查 "动态更新 bug":比如你改了参数,但软件的某个模块没收到通知,还在用旧值,就像你调了空调温度,但卧室风口没反应。Legato 工具则通过数学证明确保更新不会出问题,就像工程师用公式证明电路设计安全。
He 等人发现 86.7% 的性能缺陷很 "反直觉":比如增大 buffer_size 想减少 IO,结果因内存竞争反而变慢,就像给自行车装太大的篮子,反而骑不动。他们的 CP - Detector 工具能对比 "说明书预期" 和 "实际效果",精准找出这种缺陷。
故障反应能力缺陷检测句号
软件遇到配置错误时的 "报错能力" 很重要,就像家电坏了要明确提示 "缺水" 还是 "漏电"。SPEX - INJ 工具故意输错配置(比如给数字参数输文字),发现只有 32% 的软件会说清错在哪(如 "timeout 必须大于 0"),其他只说 "配置无效",让人摸不着头脑。
Li 等人的 ConfTest 工具测试了 6 款大型软件的 2000 个参数,发现:对 "类型错"(如文字当数字)报错率 78%,但对 "参数关联错"(如漏设依赖参数)报错率只有 23%;日志里常漏说 "哪个参数错了",就像家电只说 "出错了",不说哪个按钮按错了。
配置相关测试优化句号
参数太多导致 "组合爆炸",测试不完怎么办?就像遥控器按钮太多,不可能试遍所有按法。Qu 等人的方法是 "精准测试":改了哪个参数,就只测受影响的代码,像只按了 "音量" 按钮,就不用测 "频道" 功能。在回归测试中,他们对比新旧版本代码,只测受影响的参数,时间缩短 50%。
Marijan 等人的 Titan 工具像 "测试规划师",用算法找出 "最少测试用例",覆盖所有参数。在 Firefox 和 LibreOffice 中,它能把测试用例减少 40% - 60%,还不影响效果,就像用最少的按键组合试遍遥控器所有功能。
(3).配置故障预防:设置 "安全警戒线"
配置故障预防在软件启动或部署前主动发现问题,避免故障进入生产环境,是降低损失的关键环节。就像出门前检查煤气灶是否关紧,避免着火。
基于知识的预防句号
Eshete 等人的 Confeagle 工具像 "安全检查员",对照安全标准查配置:比如 "默认密码没改""敏感信息明文存" 等问题,在 50 个 Web 应用里查出 32% 有高风险配置,还会建议 "把 allow_anonymous 设为 false"(关闭匿名访问)。
Otsuka 等人的工具像 "老中医",通过历史故障记录总结规律:比如 "服务崩溃常因 max_memory 超过内存 90%",新配置一来就对比,预警准确率 76%,就像根据 "天冷容易感冒" 的经验,提醒你加衣服。
Huang 等人的 ConfValley 框架让开发者用 "声明式语言" 写规则,比如 "max_users <= license_limit"(用户数不超过许可证),启动时自动检查,就像给家电设 "温度上限",超过就报警。
基于模拟的预防句号
Xu 等人的 PCheck 工具像 "启动前自检",分析源码找出参数生效的条件(如 "port 参数要在 bind 函数前设置"),生成检查器在启动时运行,拦住 68% 的启动故障,就像汽车启动前自检,发现没油了不让开。
Sun 等人的 Ctest 工具 "借刀杀人"------ 用软件自己的单元测试查配置。先找出测试覆盖的参数,再生成各种取值试测,能发现 "值合法但功能错" 的问题,比如 "timeout 设 1ms 导致测试超时失败",就像用烤箱自带的 "快速预热" 功能测试温度是否准。
Cheng 等人优化了测试顺序,让 "容易发现故障" 的用例先跑,检测速度提升 40%,就像医生先查最可能的病因,节省时间。
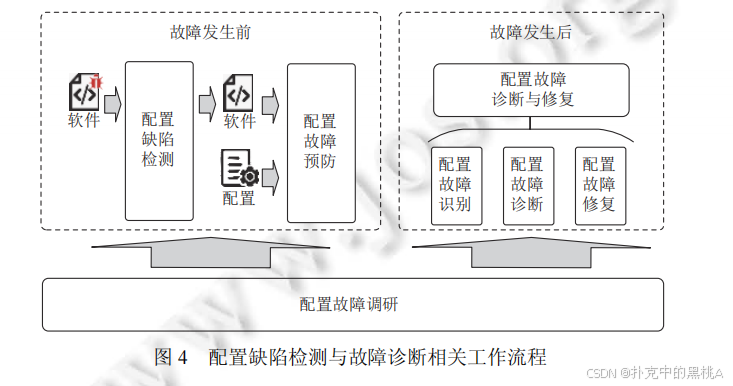
(4).配置故障诊断与修复:快速 "故障抢修"
当配置故障发生后,快速定位原因并修复能显著减少损失。该环节包含故障识别、诊断和修复三个步骤,就像家电坏了,师傅上门后迅速定位问题、换零件。
配置故障识别句号
先判断故障是不是配置导致的,就像医生先判断发烧是不是感冒引起的。Xia 等人的模型分析故障报告里的关键词(如 "配置""参数"),预测准确率 81%;Xu 等人的 EFSPredictor 工具综合多种特征,准确率提升到 85%。
Wen 等人的 CoLUA 工具更聪明,不仅判断是不是配置问题,还推荐可能相关的参数。比如报告 "服务启动不了",它会优先怀疑 "port""bind_address" 等启动相关参数,就像家电不启动,先怀疑电源和开关。
Yuan 等人的 CODE 工具监控 Windows 注册表访问规律,比如 "先读 path 再读 timeout" 是正常模式,违反了就提示配置可能错了,在 Office 和浏览器里准确率 91%,就像发现 "先按静音再开音量" 的操作不对劲,提示遥控器可能有问题。
配置故障诊断句号
配置故障诊断的核心是定位导致故障的可疑参数,减少人工排查时间。
Rabkin 等人的 ConfAnalyzer 工具通过静态分析定位源码中配置参数的读入位置,构建 "参数 - 异常点" 映射关系(如 "port 参数读入后用于 bind 函数,若 bind 失败则可能是 port 被占用")。故障发生后,工具通过检索映射关系快速定位可疑参数,在 Hadoop 案例中诊断准确率达 82%。
Dong 等人的 ConfDoctor 工具分析两部分代码:配置参数影响的程序语句,以及触发故障的出错栈涉及的语句。若两部分语句存在交集,则该参数为可疑参数。例如,"max_connections 参数影响连接创建语句,而出错栈显示'连接创建失败'",则 max_connections 被标记为可疑参数,在 Tomcat 故障中定位准确率达 79%。
Zhang 等人的 ConfDiagnoser 工具基于瘦切片技术确定每个参数影响的控制流信息,对分支语句插桩记录正常运行时的执行路径;故障发生后,工具寻找与故障路径最相似的正常路径,分析差异最大的分支语句对应的参数,定位故障原因。在 MySQL 和 Apache 中,该工具能在 5 分钟内定位 85% 的配置故障。
针对跨组件配置故障(如微服务间参数冲突),Sayagh 等人提出跨栈切片依赖图,追踪不同组件间的调用关系和参数传递路径。故障发生时,从出错日志位置反向追溯依赖图,定位可能影响该日志的所有组件的配置参数,在分布式系统中跨组件故障诊断覆盖率达 76%。
Attariyan 等人的 X - ray 工具针对性能故障,通过插桩记录程序基本块的执行开销,结合动态信息流追踪估算每个配置参数对性能瓶颈的影响程度(如 "cache_size 过小导致 30% 的 IO 开销"),将参数按影响程度排序,辅助定位性能调优目标。
配置故障修复句号
配置故障修复旨在提供具体的修复建议或自动完成修复,减少人工操作成本。
Huang 等人的 Ocasta 工具通过层次凝聚聚类算法,将历史修复中频繁同时修改的参数聚为一类(如 "max_memory 和 heap_size 常一起调整");当新故障发生时,工具基于用户提供的故障复现操作和时间,重放聚类参数的不同取值组合,检查故障是否修复,在企业级存储系统中修复成功率达 72%。
Potharaju 等人的 ConfSeer 工具解析用户配置为键值对,用 TF - IDF 算法计算与配置故障知识库文档的相似度,匹配成功后将知识库中的修复方案(如 "将 timeout 从 1s 改为 5s")推荐给用户。在 Microsoft 云服务中,ConfSeer 缩短了 60% 的故障修复时间。
Talwadker 等人的 Dexter 工具通过解析故障日志筛选关键信息(如 "file not found 对应 log_path 参数错误"),将修复操作与日志信息关联形成数据库。新故障发生时,工具匹配日志信息快速推荐修复方案,在开源软件中修复建议准确率达 78%。
3. 配置应用研究:让 "调节系统" 高效运转
配置应用研究聚焦 "如何高效使用配置",通过参数推荐和性能调优帮助用户快速找到满足需求的参数列表和取值,提升软件可用性和性能。
(1).配置参数推荐:找到 "最相关的旋钮"
软件参数太多,就像遥控器按钮密密麻麻,不知道哪个对应你要的功能。参数推荐工具能帮你快速找到相关参数,就像搜索 "调亮度" 立马告诉你按哪个键。
功能相关参数推荐句号
Jin 等人的 PrefFinder 工具像 "搜索助手",你输入 "怎么设置日志轮转",它就找名字相关的参数(如 log_rotate_size),在 Eclipse 和 Linux 里推荐准确率 78%,就像搜 "空调定时" 帮你找到定时按钮。
Sayagh 等人的 ConfigMiner 工具 "看历史病例",从开发者社区的问题里找规律,比如 "日志太大" 常涉及 log_rotate_size 和 log_level,新问题来了就推荐这些参数,准确率 82%,就像医生根据 "咳嗽病人常开止咳药" 给你推荐药。
Hamidi 等人从 Facebook 隐私配置数据里找 "按键组合",比如 "开好友可见时,常关陌生人查看",推荐你下一步怎么设,让配置时间缩短 50%,就像遥控器按 "电影模式" 自动调暗亮度、开大音量。
性能相关参数推荐句号
找出对性能影响大的参数,就像知道空调的 "温度" 和 "风速" 对耗电影响最大,调这两个就行。Cao 等人的 Carver 工具测参数对性能的影响,从 50 多个参数里挑出 10 个关键的(如缓存大小),让调优范围缩小 80%,就像从一堆按钮里标出 "最影响耗电的 3 个键"。
Kanellis 等人针对数据库,在不同负载下测参数影响,发现 Cassandra 里 memtable_flush_period_in_ms 对写入速度影响最大(权重 35%),就像知道空调的 "压缩机频率" 对制冷速度影响最大。
Li 等人的 LearnConf 工具找 "和性能操作相关的参数",比如和 "磁盘读写" 相关的 buffer_size,和 "锁竞争" 相关的 lock_timeout,关联度 91%,就像知道 "空调滤网清洁度" 影响制冷效率,推荐你关注这个。
(2).配置性能调优:拧到 "最佳挡位"
配置性能调优通过优化参数取值组合最大化软件性能(如吞吐量、响应时间、资源利用率),是配置应用的核心场景。研究方法可分为基于搜索、基于模型和其他方法三类。就像调汽车油门和档位让油耗最低、速度最快。
基于搜索的调优方法句号
这种方法像 "试错找最优":试不同参数组合,看哪个性能最好。Zhu 等人的 BestConfig 工具很聪明,有限次数内先均匀试几个值,再根据结果缩小范围,在 Spark、Flink 里 30 次内找到近最优配置,吞吐量提升 31% - 48%,就像调空调时先试 24、26、28 度,再在最好的附近微调。
Wang 等人的 SmartConf 工具能 "动态适应",就像智能空调感应房间人数调温度。开发者设个目标(如响应时间 < 100ms),工具实时监控,超时了就加线程数,波动控制在 10% 以内。
Bao 等人的 ACTGAN 工具用 AI 学 "好配置的特征",比如 "cache_size 和 memory 成正比",指导下一步怎么试,性能比传统方法好 25%,就像学高手调空调的规律,不用瞎试。
基于模型的调优方法句号
先建 "参数 - 性能" 模型,再用模型预测最优值,就像先画 "温度 - 耗电" 曲线,再根据曲线找最省电的温度。Siegmund 等人建线性模型,量化参数和交互的影响,比如 "heap_size 和 thread_count 一起调影响最大",给调优指方向。
Guo 等人用回归树建非线性模型,预测更准,后续优化后准确率再升 15%。Ha 等人的 DeepPerf 用神经网络,误差比传统模型低 20% - 30%,就像用更复杂的公式预测天气,更准。
针对数据库的 OtterTune 工具先找 "相似负载",比如现在的负载和上周三下午像,就用当时的最优配置,让 PostgreSQL 和 MySQL 吞吐量提升 18% - 74%,就像根据 "昨天 30 度时开 26 度最舒服" 今天也这么调。
| 模型类型 | 支持参数类型 | 数据来源 | 优势 | 局限性 | 代表工具 |
|---|---|---|---|---|---|
| 线性模型 | 布尔、数值 | 性能测试 | 可解释性好,训练快 | 难以捕捉复杂交互 | Siegmund 方法 |
| 非线性模型 | 布尔、数值 | 性能测试 | 捕捉复杂交互能力强 | 可解释性差,需更多样本 | DeepPerf、CART |
| 混合模型 | 布尔、数值 | 性能测试 + 程序分析 | 结合代码语义,精度高 | 依赖代码可得性 | ConfigCrusher |
其他调优方法句号
Feng 等人的 Relax 工具专治 "资源竞争",比如 CPU 占满、上下文切换频繁,就像多人抢用一个水龙头导致堵塞。它找出影响资源的参数(如 thread_pool_size),自动调整解决竞争,性能提升 20% - 50%。
Moreno 等人的 QUEST 工具给搜索引擎调优,根据查询特征(如 "短查询""多关键词")推荐配置,准确率提升 15% - 25%,就像根据 "看电影" 还是 "听音乐" 调音响模式。
三.研究现状对比:国内外的 "技术路径差异"
软件运行时配置研究在全球范围内呈现不同的技术偏好,这种差异与应用场景、研究导向和工业界需求密切相关。国内外研究配置的 "套路" 不太一样,就像中西方做饭,都追求好吃,但方法不同。
1. 技术选择偏好差异
国内研究聚焦工程化工具开发,注重实际效果和落地应用。在配置性能调优(占国内论文 38%)和模糊测试检测(占 22%)领域成果突出:清华大学团队开发的 ContractFuzzer 针对工业界需求优化,支持批量检测和 HTML 报告生成,被多家企业采用;国防科技大学的 ConfMapper 工具解决 C/C++ 软件参数映射难题,在 Nginx、Redis 等软件中实用价值显著。国内研究更关注 "如何快速解决实际问题",工具设计强调易用性和兼容性。
国外研究深耕理论基础,技术覆盖更全面。在符号执行(占国外论文 35%)和形式化验证(占 10%)领域领先:MIT 团队的 SPEX 工具从理论上定义配置约束类型,为后续研究提供框架;斯坦福大学的 OtterTune 工具不仅实现数据库调优,还深入分析模型泛化能力,理论深度更强。国外研究注重 "构建通用技术体系",论文中算法证明和理论分析占比更高。
简单来说:
国内研究像 "家常菜",讲究实用、能快速上桌。在性能调优(占国内论文 38%)和模糊测试(22%)上强,工具比如清华大学的 ContractFuzzer 支持批量检测、生成 HTML 报告,企业用着方便;国防科技大学的 ConfMapper 专门解决 C/C++ 软件的参数映射问题,实用性强。国内更关注 "怎么快速解决实际问题"。
国外研究像 "分子料理",讲究理论、追求体系。在符号执行(35%)和形式化验证(10%)上领先,MIT 的 SPEX 工具从理论上定义约束类型,斯坦福的 OtterTune 不仅调优,还深入分析模型为什么准。国外更关注 "怎么构建通用技术体系"。
2. 漏洞与平台覆盖差异
国内研究更关注区块链、大数据等新兴领域的特有配置问题。在分布式系统跨组件配置故障(占国内特性漏洞研究的 45%)、容器化环境配置适配(占 23%)等方向投入多:浙江大学团队开发的工具支持 EOS 区块链合约的配置检测,而国外工具仍以传统服务器软件为主。这与国内 DeFi 应用活跃、云计算落地快的产业环境密切相关。
国外研究则兼顾传统与新兴领域,漏洞覆盖更全面。除分布式系统外,对嵌入式软件(如物联网设备配置)、安全攸关系统(如医疗软件配置)的研究占比达 30%,体现更广泛的应用视野。平台支持上,国内外均以 Linux 环境为主,但国外对 Windows、macOS 等多平台适配研究更早,工具通用性更强。
简单来说:
国内研究像 "川菜",聚焦特定领域做得深。分布式系统跨组件故障(45%)、容器化配置(23%)研究多,浙江大学的工具支持 EOS 区块链合约检测,而国外还在盯传统服务器软件。这和国内 DeFi 火、云计算落地快有关。
国外研究像 "自助餐",覆盖广。除了分布式系统,还研究嵌入式软件(如物联网设备)、医疗软件配置,占 30%。平台支持上,国内外都以 Linux 为主,但国外更早适配 Windows、macOS,工具通用性强。
3. 实验数据与开源情况差异
国内研究 81% 使用真实平台数据(如 Hadoop 集群日志、Etherscan 合约),注重实际效果验证。例如, ContractFuzzer 在 1000 个真实合约上测试,用实际漏洞检出率证明效果。但国内工具开源率仅 26%,多数为学术原型,缺乏持续维护,实际应用范围受限。
国外研究平衡使用案例分析(34%)和平台检测(66%),既验证理论也关注实践。63% 的工具开源(如 Slither、OtterTune),形成活跃社区:Slither 被全球数千开发者使用,衍生出 20 多个优化版本;OtterTune 开源后被集成到多家云服务平台。开源生态加速了技术迭代和工业界落地。
简单来说:
国内研究像 "自家厨房",用真实数据做饭。81% 的研究用真实平台数据(如 Hadoop 集群日志),ContractFuzzer 在 1000 个真实合约上测效果。但工具开源率仅 26%,多数是实验室原型,就像私房菜不对外传秘方。
国外研究像 "开源菜谱",数据和工具都共享。63% 的工具开源(如 Slither、OtterTune),Slither 被全球开发者用,衍生出 20 多个版本;OtterTune 被集成到多家云平台。开源让技术迭代更快,就像大家一起改菜谱,越改越好。
4. 对比实验与评估体系差异
国外 51% 的论文包含多工具对比实验,常与最新技术比较(如将新工具与 state - of - the - art 方法对比),实验设计更严谨。例如,评估调优工具时,会对比 BestConfig、OtterTune 等多款工具的性能提升幅度和收敛速度。
国内 48% 的论文包含对比实验,但对比对象较单一,多与经典工具(如 Oyente)对比,缺乏与同类新工具的竞争分析。这与国内开源工具少、生态不完善有关,难以获取最新工具进行对比。评估指标也更侧重 "准确率""检出率" 等基础指标,对 "可扩展性""泛化能力" 等深层指标关注较少。
简单来说:
国外研究像 "厨艺比赛",对比严格。51% 的论文和最新工具比,比如调优工具会和 BestConfig、OtterTune 比谁快、谁效果好。国内 48% 的论文也对比,但多和经典工具(如 Oyente)比,少和同类新工具比,就像只和家常菜比,不和新菜式比。
四.核心挑战:配置研究的 "拦路虎"
尽管软件运行时配置研究取得显著进展,但面对软件规模的持续增长和应用场景的复杂化,仍存在四大核心挑战制约技术实用化。虽然研究不少,但配置管理还有四大 "难关",就像调复杂家电时遇到的麻烦。
1. 配置复杂性与规模难题
现代软件的配置参数规模呈指数增长,大型分布式系统的参数可达数千个,参数间的关联关系形成 "约束网络"。静态分析技术面对百万行级代码时效率骤降:分析包含 1000 个参数的软件,传统工具需数小时甚至数天,难以满足实时分析需求。动态分析则因 "参数组合爆炸"(n 个参数存在 2ⁿ 种组合)难以覆盖所有场景,例如 20 个布尔参数的系统存在百万种组合,穷尽测试需数月时间。
参数类型的多样化加剧了复杂性:除基本类型外,结构化参数(如 JSON 嵌套配置)、动态生成参数(如根据环境自动添加的参数)、加密参数(如敏感信息加密存储)的解析和约束提取难度大,现有工具支持不足。跨语言开发的软件(如前端用 JavaScript、后端用 Java、数据库用 SQL)因配置机制差异大,统一分析工具开发困难。
简单来说:
参数太多、关系太乱,就像遥控器按钮多到按不过来,还互相联动。大型软件参数上千,组合起来呈指数增长(n 个参数有 2ⁿ 种组合),20 个参数就有百万种可能,测不完。
参数类型复杂:JSON 嵌套配置、动态生成的参数、加密参数都难解析,就像遥控器有触屏、语音、按键多种输入,不好统一控制。跨语言软件(前端 JS、后端 Java、数据库 SQL)配置机制不同,工具难通用。
2. 跨平台与动态环境适配
不同软件平台的配置机制差太远:区块链合约配置存在链上,传统服务器存在文件里,嵌入式设备存在寄存器里,就像不同品牌家电的遥控器不通用,得重新学。
配置 "脾气" 随环境变:在 8GB 内存服务器上 cache_size = 4GB 合适,在 2GB 边缘设备上就会崩溃;低负载时好的参数,高负载时可能变糟,就像空调在南方潮湿天气和北方干燥天气里,最佳温度不同。现有工具多按静态环境设计,不会 "随机应变"。
3. 误报率与自动化修复瓶颈
工具常 "喊狼来了":30% 以上的错误提示是假的,比如把 "可选参数没设" 当故障,就像遥控器提示 "童锁没开",但你根本不用童锁。
修复能力弱:多数工具只说 "哪错了",不说 "怎么改";跨组件故障难修,比如 A 和 B 软件参数不匹配,要协调改两个地方;修复可能引新问题,比如减小 cache_size 解决内存溢出,却导致 IO 变慢。
4. 缺乏统一标准与评估体系
配置缺陷分类、性能指标、工具评估方法尚无统一标准,导致研究结果难以对比。配置缺陷缺乏公认分类体系,不同研究对 "重入漏洞""权限漏洞" 的定义存在差异,检出率统计口径不一,无法客观比较工具效果。就像家电没统一接口,不同品牌充电器不能混用。配置缺陷分类没标准,不同研究对 "参数冲突" 定义不同,结果没法比;评估数据集少,工具在不同数据上表现差 40%,不知道谁真厉害。
评估数据集的缺乏制约技术迭代:现有研究多使用自制数据集,包含的漏洞类型和软件类型有限,且缺乏标注信息(如漏洞触发条件、影响范围)。基准测试平台的缺失使工具性能评估缺乏统一参照,相同工具在不同数据集上的表现差异可达 40%,影响技术可信度。
五.未来方向:构建 "智能配置管理系统"
针对这些难题,未来研究要向 "更智能、更通用、更落地" 发展,就像把普通遥控器升级成 "语音控制 + 自动适应" 的智能遥控器。
1. 配置分析与理解的深化
智能化约束提取句号
用大语言模型(LLM)当 "超级翻译",从文档、源码、日志里跨模态提规则:比如从手册 "超时建议 5 - 30 秒"、源码里的 if (timeout < 5)、日志 "invalid timeout: 3" 里,都能提取 timeout >= 5 的规则。LLM 理解上下文的能力,能抓更复杂的规则。
动态约束学习句号
建 "环境 - 配置 - 性能" 模型,像智能空调学 "人多 + 高温时开 24 度最舒服"。通过监控实时数据,模型能动态调规则,比如高负载时 timeout 自动延长 50%,解决静态规则 "水土不服" 的问题。
配置知识图谱构建句号
整合参数元信息(名称、类型、描述)、约束关系(依赖、互斥、关联)、影响域(关联代码段、把参数信息、规则、影响范围、故障案例建成 "知识地图",像家电说明书加了 "按钮联动表""常见故障地图"。你能查 "哪些参数影响数据库速度""开 A 功能要设 B 为 X",一目了然。
2. 缺陷检测与诊断的升级
面向配置的测试生成句号
结合 "符号执行(推理论证)" 和 "模糊测试(随机尝试)" 生成测试用例,像既按说明书正规操作,又乱按按钮试极限情况。优先测高风险路径(如权限、资金相关代码),效率更高。
智能故障诊断句号
用图神经网络(GNN)建 "参数 - 代码 - 故障" 关系图,像医生看 "症状 - 器官 - 疾病" 关联。GNN 能抓跨组件关系,比如 "A 软件参数通过 RPC 影响 B 软件故障";再用因果推理分清 "相关" 和 "因果",避免误诊。
自动化修复技术句号
学历史修复案例生成补丁,像师傅看 "上次这个故障换了电容" 这次也这么修。用 transformer 模型学修复模式,比如 "重入漏洞加锁""整数溢出加范围检查",再自动验证修复是否安全,不引新问题。
3. 配置应用的智能化
自适应性能调优句号
开发环境感知的调优框架:通过传感器或监控工具实时采集环境特征(硬件资源、网络状态、负载特征)和系统性能指标(响应时间、吞吐量、资源利用率);用强化学习训练调优 agent,根据环境和性能的实时变化动态调整参数(如 "CPU 利用率超 80% 时减少 thread_count""网络延迟增加时增大 timeout");支持多目标优化(如 "在保证响应时间 < 100ms 的同时,使 CPU 利用率 < 70%"),平衡性能与资源消耗。
建 "环境感知调优框架",像智能汽车根据路况自动换挡。实时采硬件、网络、负载数据,用强化学习调参:CPU 高了减线程数,网络慢了加超时,平衡性能和资源。
轻量化调优工具句号
优化算法降低资源消耗:采用增量分析技术,仅重新分析配置变更部分(如 "修改 cache_size 后仅重新评估缓存相关代码"),减少重复计算;开发分布式检测框架,利用云计算或边缘计算资源并行处理大规模配置分析任务(如 "同时分析 thousands 个容器实例的配置");设计轻量级模型(如压缩神经网络、决策树),使调优工具能在嵌入式设备、边缘节点等资源受限场景运行。
让工具变 "轻",能在边缘设备跑:改一点配置就只重分析相关部分,不用全量算;用分布式框架并行处理大规模配置;模型压缩变小,像把厚重的说明书浓缩成小手册。
配置推荐的个性化句号
基于用户画像和场景特征提供个性化推荐:分析用户角色(开发者、运维人员、普通用户)和需求(功能配置、性能调优、安全加固),推荐相关参数(如向运维人员推荐性能参数,向开发者推荐调试参数);结合软件应用场景(电商促销、金融交易、物联网监控),推荐场景适配的参数取值(如促销场景推荐 "高并发配置模板",交易场景推荐 "高安全配置模板");学习用户调参历史,推荐符合用户习惯的参数组合,降低学习成本。
学用户习惯,推荐你常用的参数组合,像遥控器记住你常按的 "26 度 + 自动风"。
4. 标准与生态建设
配置缺陷分类标准句号
扩展 CWE(Common Weakness Enumeration)标准,建立统一的配置漏洞分类体系:定义基础缺陷类型(如 "类型错误""取值范围违规")、关联缺陷类型(如 "参数依赖缺失""互斥参数冲突")、环境相关缺陷类型(如 "环境不匹配""负载敏感故障"),明确每种类型的定义、特征和示例。标准将为研究提供统一术语,便于成果对比和交流。
简单来说:
扩展 CWE 标准,统一缺陷定义:比如 "类型错误""范围违规""参数冲突" 都明确定义,像家电故障统一分类 "不制冷""噪音大"。
公开基准数据集句号
构建包含真实配置故障的标注数据集:覆盖不同软件类型(服务器、区块链、嵌入式)、编程语言(Java、C/C++、Python)和漏洞类型;标注信息包括漏洞位置、触发条件、影响范围、修复方案;定期更新数据集,纳入新型漏洞案例(如 AI 模型配置漏洞)。数据集将为工具评估提供客观依据,推动技术迭代。
简单来说:
建带标注的故障数据集,覆盖不同软件、语言、漏洞类型,像收集各种家电的故障案例,标清 "症状、原因、修法",供工具测试。
开源工具生态句号
推动配置工具开源,建立社区协作机制:鼓励研究者开源工具源码和测试数据,方便复用和改进;搭建工具交流平台,促进工业界与学术界合作(如企业提出实际需求,学术界开发解决方案);定期举办配置故障检测竞赛,激发创新活力。完善工具文档和教程,降低使用门槛,推动技术从实验室走向工业界。
简单来说:
推动工具开源,建社区协作:企业提需求,学者开发;定期办 "配置故障检测大赛",促创新;完善文档教程,让更多人会用,像开源菜谱大家一起完善。
六.实用工具推荐:配置管理的 "利器"
无论是开发者、运维人员还是研究者,掌握以下工具能显著提升配置管理效率,覆盖配置分析、缺陷检测、性能调优全流程。就像好厨子得有好刀,搞配置管理也得有趁手的工具。以下工具覆盖 "分析 - 检测 - 调优" 全流程,好用还免费。
1. 配置分析与理解工具
Slither 句号
由 Trail of Bits 开发的静态分析框架,支持以太坊智能合约和传统软件的配置分析。能提取参数依赖关系、识别未使用参数、检测配置相关代码 smell(如 "硬编码敏感信息")。Slither 提供丰富的 API,开发者可自定义分析规则(如 "检测未初始化的状态变量"),集成于 VS Code 插件和 CI/CD 流程,实时提示配置风险。安装命令:pip install slither-analyzer,使用示例:slither contract.sol --print variable - dependencies。
简单来说:
静态分析 "瑞士军刀",支持智能合约和传统软件。能找参数依赖、未用参数、硬编码密码等问题,像遥控器检测仪查按键是否灵敏。集成到 VS Code 插件,写代码时实时提示风险。安装:pip install slither-analyzer,用法:slither 你的软件代码 --print variable-dependencies(看参数依赖)。
ConfMapper 句号
针对 C/C++ 软件的参数映射工具,自动定位配置参数在源码中的对应变量。支持 Nginx、Redis、Apache 等主流软件,通过识别参数解析函数和使用语句构建映射关系,输出参数 - 变量对应表和可视化调用链。工具帮助开发者理解参数作用机理,为后续约束提取和故障诊断奠定基础。使用方法:下载源码后编译,运行 confmapper --src /path/to/source --output result.json。
简单来说:
C/C++ 软件 "参数定位器",帮你找到参数在源码里对应的变量,像找到遥控器按钮对应的线路。支持 Nginx、Redis 等,输出参数 - 变量对应表和调用链,帮你懂参数作用。用法:下源码编译后,confmapper --src 源码路径 --output 结果.json。
EnCore 句号
从配置样本中挖掘关联约束的工具,支持跨组件约束提取。通过分析大量正确配置文件,生成参数取值关联规则(如 "max_connections 与 thread_cache_size 正相关")和环境关联规则(如 "内存> 32GB 时 heap_size 通常 > 8GB"),输出可视化约束网络图。适用于源码不可得的场景,帮助用户快速掌握参数间的隐性关系。
简单来说:
配置样本 "规律挖掘机",从大量配置文件里找参数关联(如 "max_connections 和 thread_cache_size 正相关"),输出可视化关系图,像从大家用遥控器的习惯里总结规律。适合没源码时用。
2. 缺陷检测与诊断工具
SPEX 句号
静态约束提取与故障注入工具,支持从源码中提取类型、范围、关联等约束,生成检查器在部署前检测配置合法性。配套的 SPEX - INJ 工具能基于约束生成故障用例,评估软件的故障反应能力(如错误提示清晰度)。SPEX 在 Httpd、MySQL 等软件中约束提取准确率达 87%,是配置缺陷预防的得力工具。
简单来说:静态约束 "提取器"+ 故障 "注射器"。从源码提规则,生成检查器查配置;还能故意输错配置看软件反应,评估报错能力。在 Httpd、MySQL 里提规则准确率 87%,帮你提前拦故障。
ConfDiagnoser 句号
通过路径对比定位故障参数的诊断工具,适用于 Hadoop、MySQL 等分布式系统。工具先记录正常运行时的执行路径信息,故障发生后寻找最相似的正常路径,分析差异最大的分支语句对应的参数,快速定位故障原因。在实验中诊断准确率达 85%,显著缩短故障排查时间。
简单来说:
故障 "侦探",通过对比正常和故障时的代码路径,定位问题参数。在 Hadoop、MySQL 里 5 分钟定位 85% 故障,像对比家电正常和故障时的运行声音找问题。
X - ray 句号
性能故障诊断工具,量化参数对性能的影响程度。通过对二进制程序插桩,记录基本块执行开销,结合动态信息流追踪估算每个参数对性能瓶颈的贡献(如 "cache_size 过小导致 30% 的 IO 开销"),将参数按影响程度排序,辅助定位性能调优目标。支持 Linux 平台的 C/C++ 软件,适用于生产环境的性能问题诊断。
简单来说:
性能故障 "CT 机",量化参数对性能的影响,比如 "cache_size 小导致 30% IO 开销"。支持 Linux C/C++ 软件,帮你找到性能瓶颈参数,像测家电各部件耗电占比。
3. 配置应用工具
BestConfig 句号
自动化性能调优工具,支持 Spark、Flink、Hadoop 等大数据系统。采用 divide - and - diverge 采样算法和 bound - and - search 搜索算法,在有限采样次数内找到接近最优的配置,使吞吐量提升 31% - 48%。工具无需源码,通过命令行接口与目标软件交互,支持自定义性能指标(如吞吐量、响应时间),适合运维人员使用。
OtterTune 句号
数据库专用调优工具,基于机器学习推荐最优配置。通过聚类算法找到与当前负载相似的历史负载,用高斯过程模型预测配置性能,推荐最优取值。支持 PostgreSQL、MySQL、MongoDB 等主流数据库,在工业界部署中使吞吐量提升 18% - 74%,减少数据库管理员的调优负担。
PrefFinder 句号
参数推荐工具,根据用户需求快速筛选相关参数。通过计算参数名称与用户查询的文本相似度,推荐功能相关参数,在 Eclipse 和 Linux 配置中推荐准确率达 78%。工具支持命令行和网页版,输入自然语言查询(如 "如何设置日志轮转")即可返回相关参数列表及描述,降低用户查找参数的难度。
七.总结:配置是软件的 "神经调节系统"
软件运行时配置研究已经从 "零散工具" 发展成 "全流程体系",就像从 "手动调温" 的老式空调,进化到 "自动感知、智能调节" 的智能家居系统。三个阶段环环相扣:看懂参数是基础,排查故障是保障,高效调参是目标。
未来,配置管理会更智能:机器自动学规则,故障早发现早修复,参数随环境自动调。但技术再好,也需要人来用好:开发者要简化配置设计,运维人员要善用工具,研究者要突破技术难关。
在 "软件定义一切" 的时代,配置管理水平直接决定软件的好用程度和安全程度。就像好的家电调节系统让你用得舒服又省心,好的软件配置管理能让系统稳定运行、高效响应,支撑我们的数字生活更顺畅。希望这篇解读能帮你用好软件的 "调节旋钮",让每个软件都能 "听话又能干"!
尾
本期技术解构至此。
论文揭示的方法论范式对跨领域技术实践具有普适参考价值。下期将聚焦其他前沿成果,深入剖析其的突破路径。敬请持续关注,共同深挖工程实现脉络,淬炼创新底层逻辑,在学术与工程融合中洞见技术演进规律,推动领域范式持续进化。