🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java实战项目
Python实战项目
微信小程序|安卓实战项目
大数据实战项目
PHP|C#.NET|Golang实战项目🍅 ↓↓文末获取源码联系↓↓🍅
这里写目录标题
- 基于大数据的用户贷款行为数据分析系统-功能介绍
- 基于大数据的用户贷款行为数据分析系统-选题背景意义
- 基于大数据的用户贷款行为数据分析系统-技术选型
- 基于大数据的用户贷款行为数据分析系统-视频展示
- 基于大数据的用户贷款行为数据分析系统-图片展示
- 基于大数据的用户贷款行为数据分析系统-代码展示
- 基于大数据的用户贷款行为数据分析系统-结语
基于大数据的用户贷款行为数据分析系统-功能介绍
基于大数据的用户贷款行为数据分析系统是一套运用Hadoop分布式存储和Spark大数据处理技术构建的金融数据分析平台,专门针对用户贷款行为模式进行深度挖掘与风险评估。该系统采用Python作为主要开发语言,结合Django Web框架构建后端服务架构,前端运用Vue+ElementUI+Echarts技术栈实现数据可视化展示。系统核心功能围绕贷款用户的多维度行为数据展开,通过HDFS分布式文件系统存储海量用户数据,利用Spark SQL进行高效的数据查询与统计分析,运用Pandas和NumPy进行数据清洗与特征工程处理。整个系统能够从用户基本画像、收入年龄结构、职业工作背景、地理位置分布等多个维度深入分析用户贷款行为特征,并通过机器学习算法构建贷款违约风险预测模型,为金融机构的信贷决策提供数据支撑。系统采用MySQL数据库存储分析结果,通过直观的图表形式展现数据洞察,帮助用户理解不同群体的贷款行为规律与风险分布情况。
基于大数据的用户贷款行为数据分析系统-选题背景意义
选题背景
随着数字金融业务的快速发展,银行和消费金融机构面临着日益增长的信贷风险管理挑战。传统的风控模式在处理海量用户数据时存在效率瓶颈,而大数据风控技术通过运用大数据构建模型的方法对借款人进行风险控制和风险提示,已成为金融科技公司竞争的核心业务场景。当前金融机构在贷款审批过程中,需要综合考虑用户的个人信息、收入状况、职业背景、历史信用记录等多维度因素,但缺乏有效的技术手段对这些复杂的非结构化数据进行深度分析和模式识别。金融机构普遍有风控需求,底层业务逻辑几乎完全相同,只是面对客群、金融产品、风险偏好存在差异。在这样的背景下,如何利用大数据技术对用户贷款行为进行科学分析,建立有效的风险识别和预测机制,成为了金融行业亟待解决的重要问题。基于Hadoop和Spark等大数据技术栈的贷款行为分析系统,能够有效处理大规模数据集,为金融风控提供更加精准和高效的技术支撑。
选题意义
本课题通过构建基于大数据的用户贷款行为数据分析系统,能够为金融机构提供更加科学化、智能化的风控决策支持工具,这对于提升信贷业务效率和降低违约风险具有一定的实用价值。从技术角度来看,该系统整合了Hadoop分布式存储、Spark大数据计算、机器学习等现代数据科学技术,为相关技术在金融领域的应用提供了一个较为完整的实践案例。从业务价值角度分析,系统能够帮助理解不同用户群体的贷款行为特征,识别潜在的高风险客户,虽然作为毕业设计其影响范围有限,但仍可为小规模的金融数据分析场景提供参考方案。该系统还具备一定的教学和学习价值,通过多维度的数据分析和可视化展示,能够帮助使用者更好地理解金融风控的基本原理和大数据技术的实际应用方法。同时,系统的开发过程涉及数据清洗、特征工程、模型构建等多个环节,为大数据和金融科技相关专业的学生提供了较为全面的技术实践机会,有助于培养复合型的数据分析人才。
基于大数据的用户贷款行为数据分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的用户贷款行为数据分析系统-视频展示
大数据毕业设计选题:基于大数据的用户贷款行为数据分析系统Spark SQL核心技术
基于大数据的用户贷款行为数据分析系统-图片展示
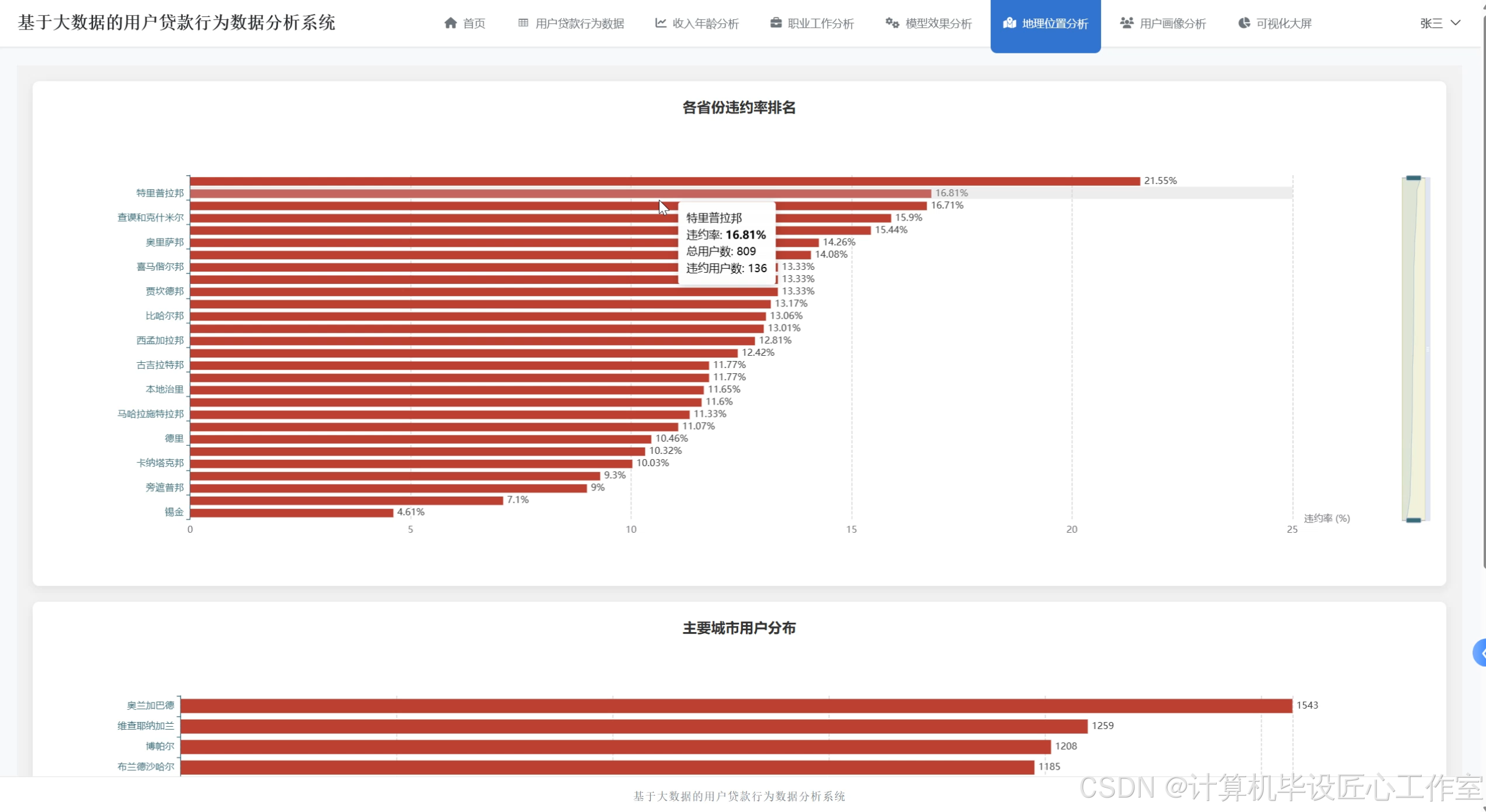
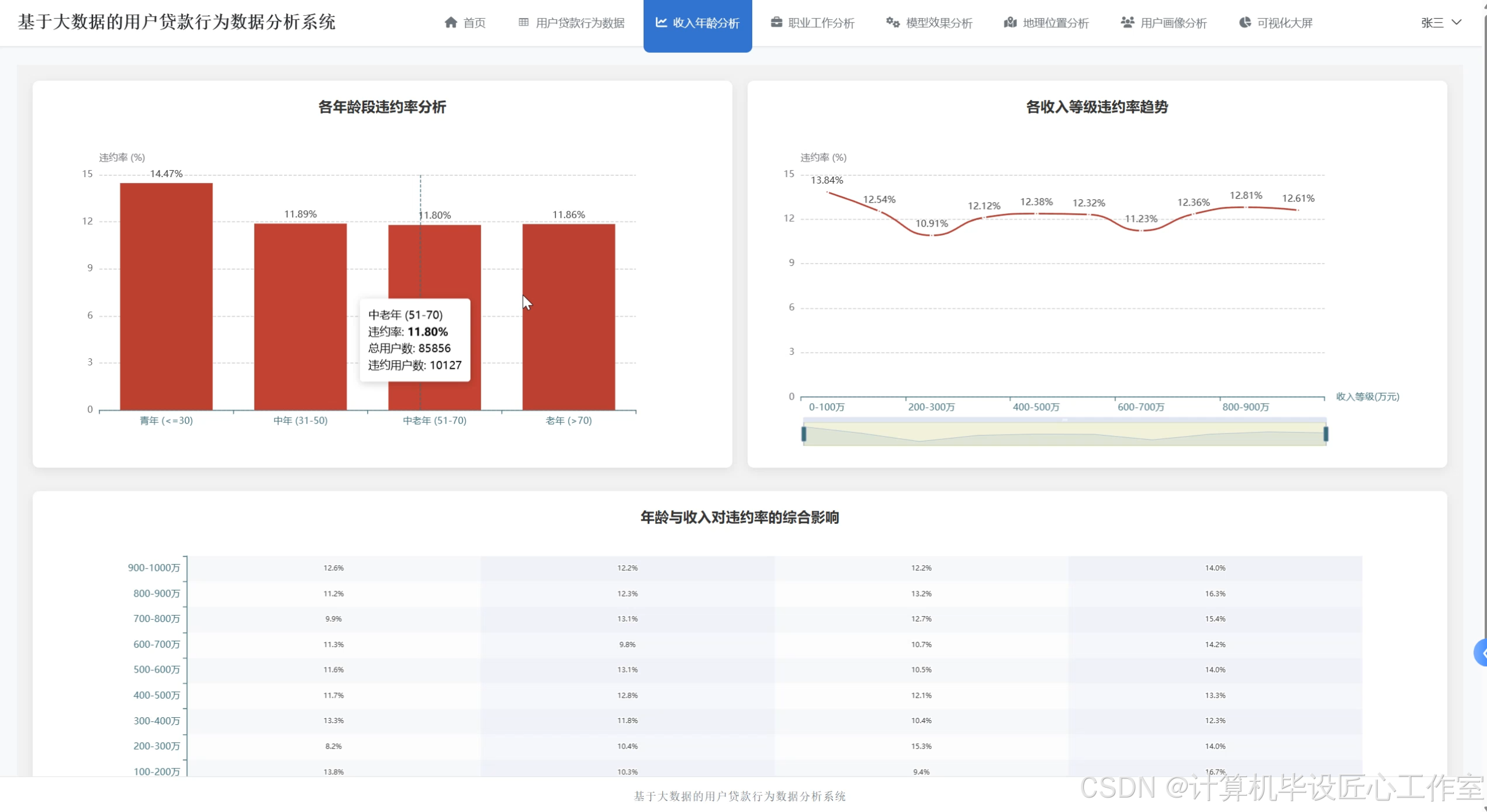
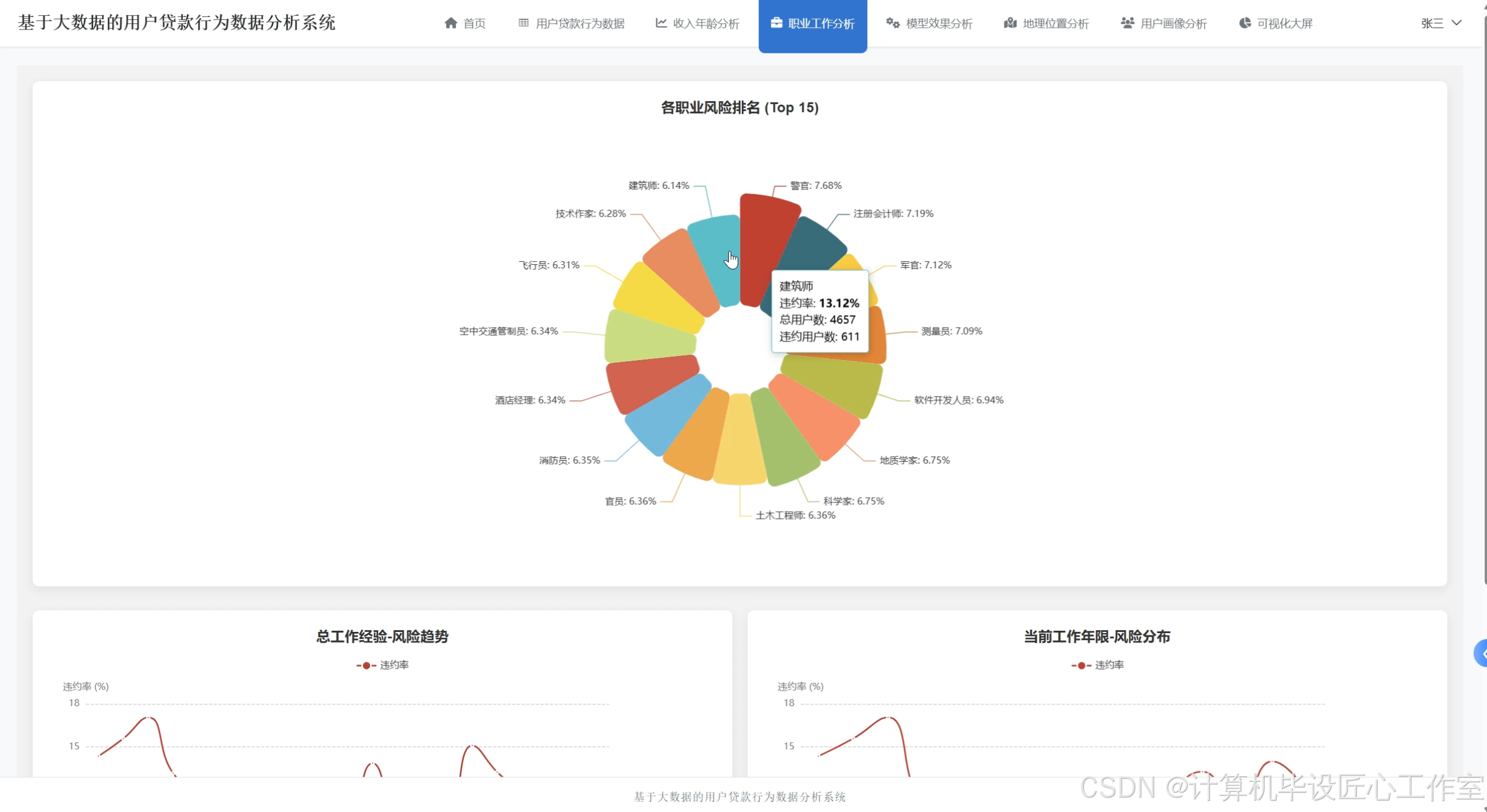
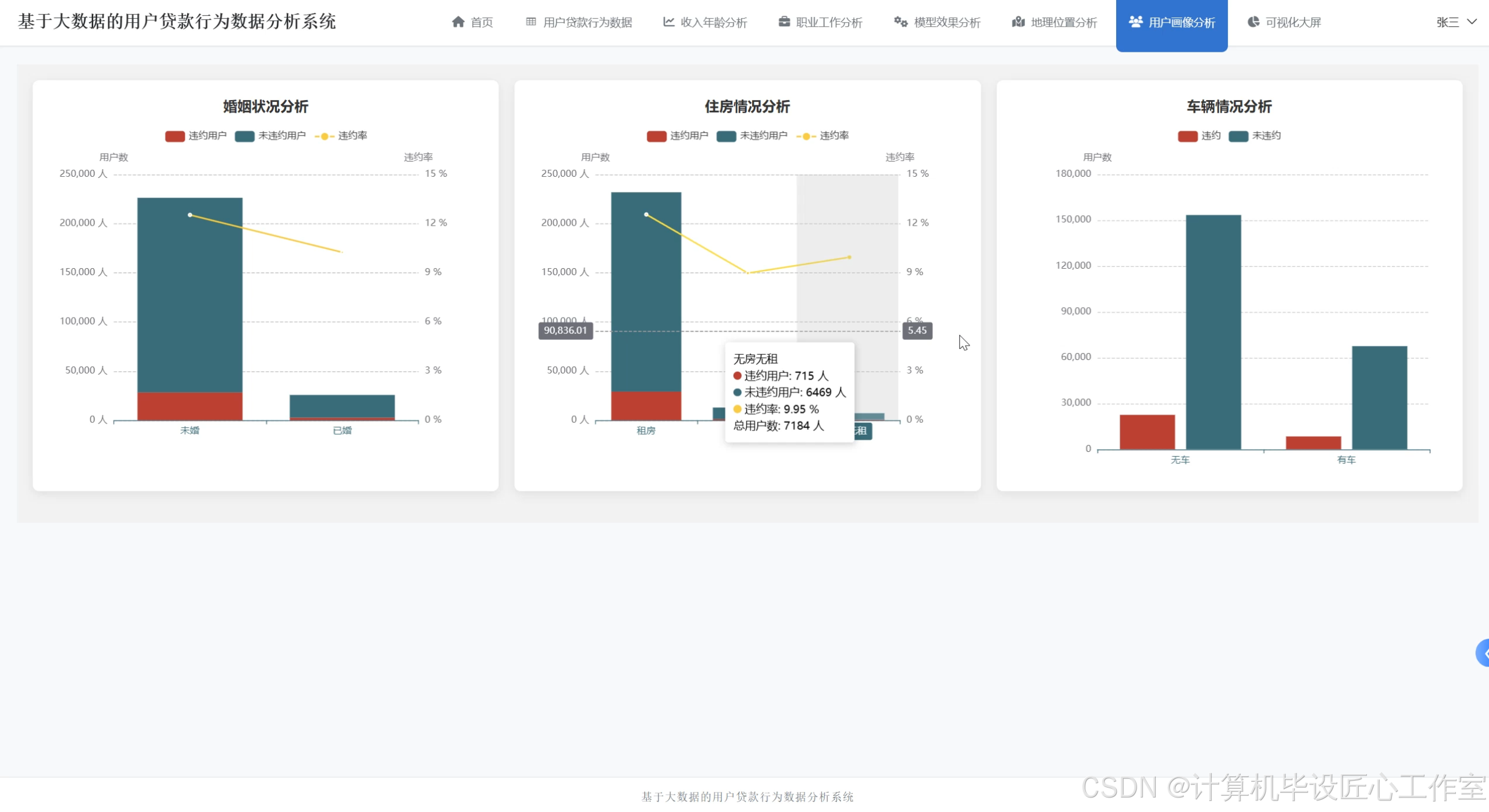
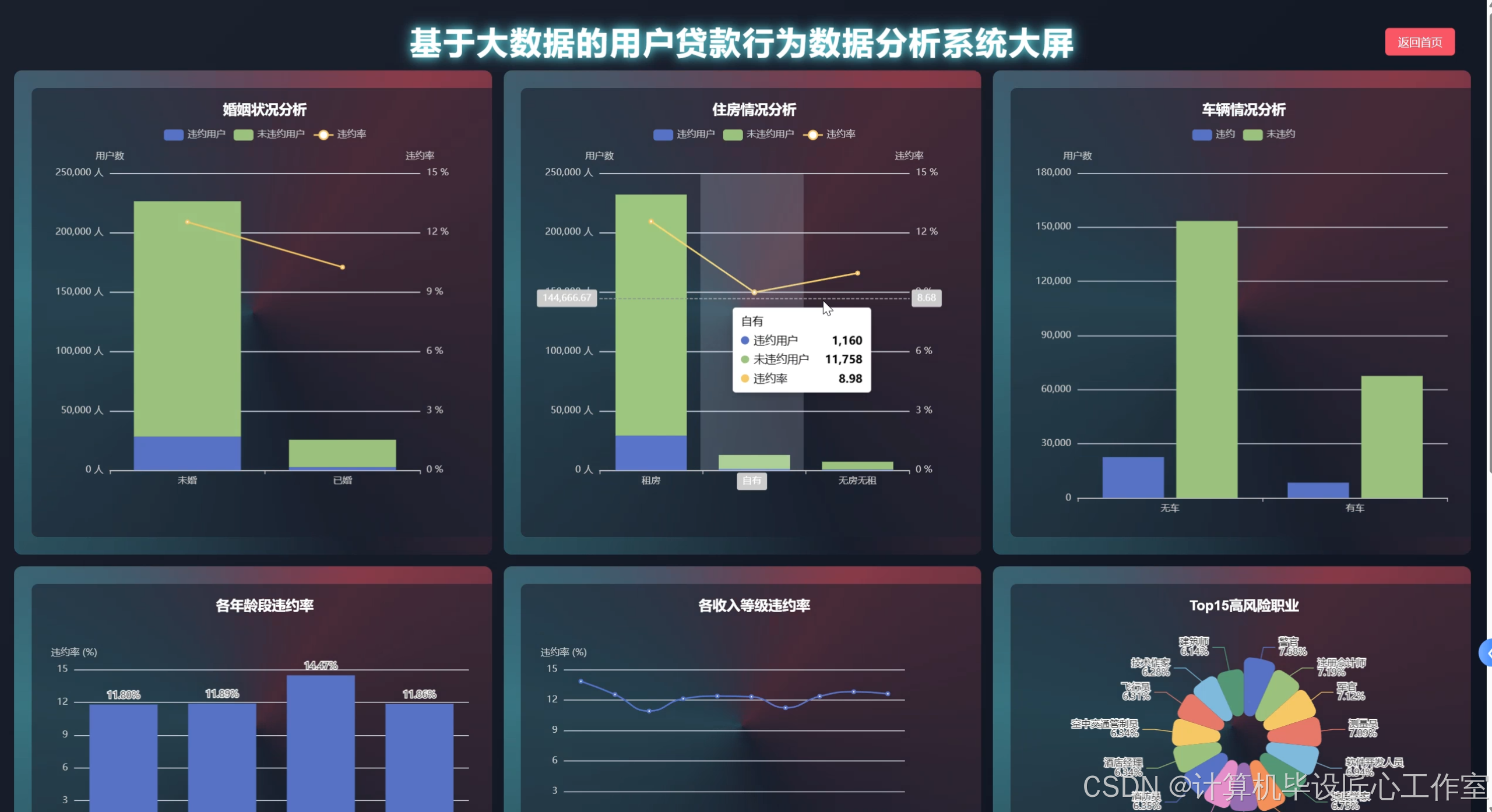
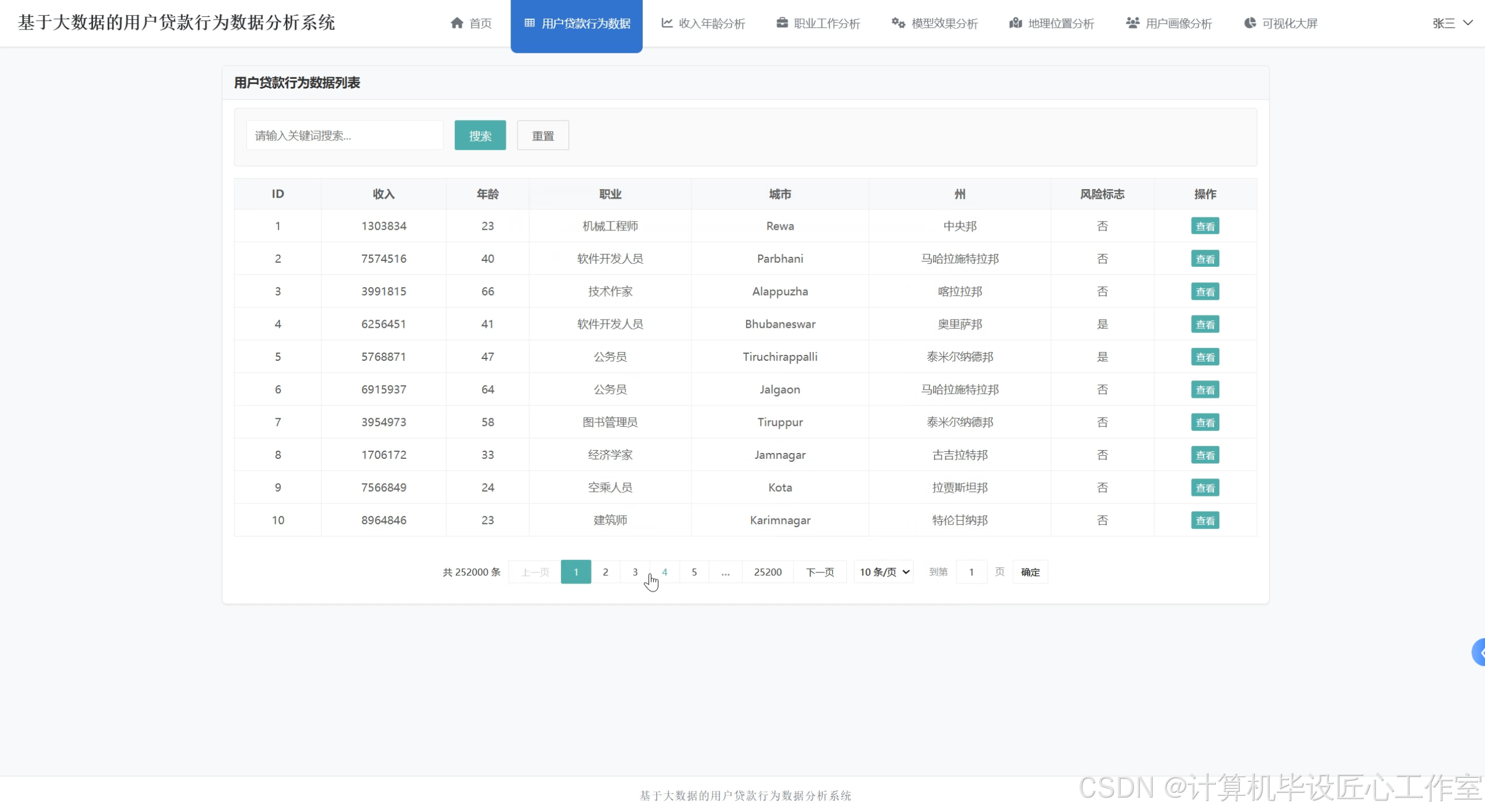
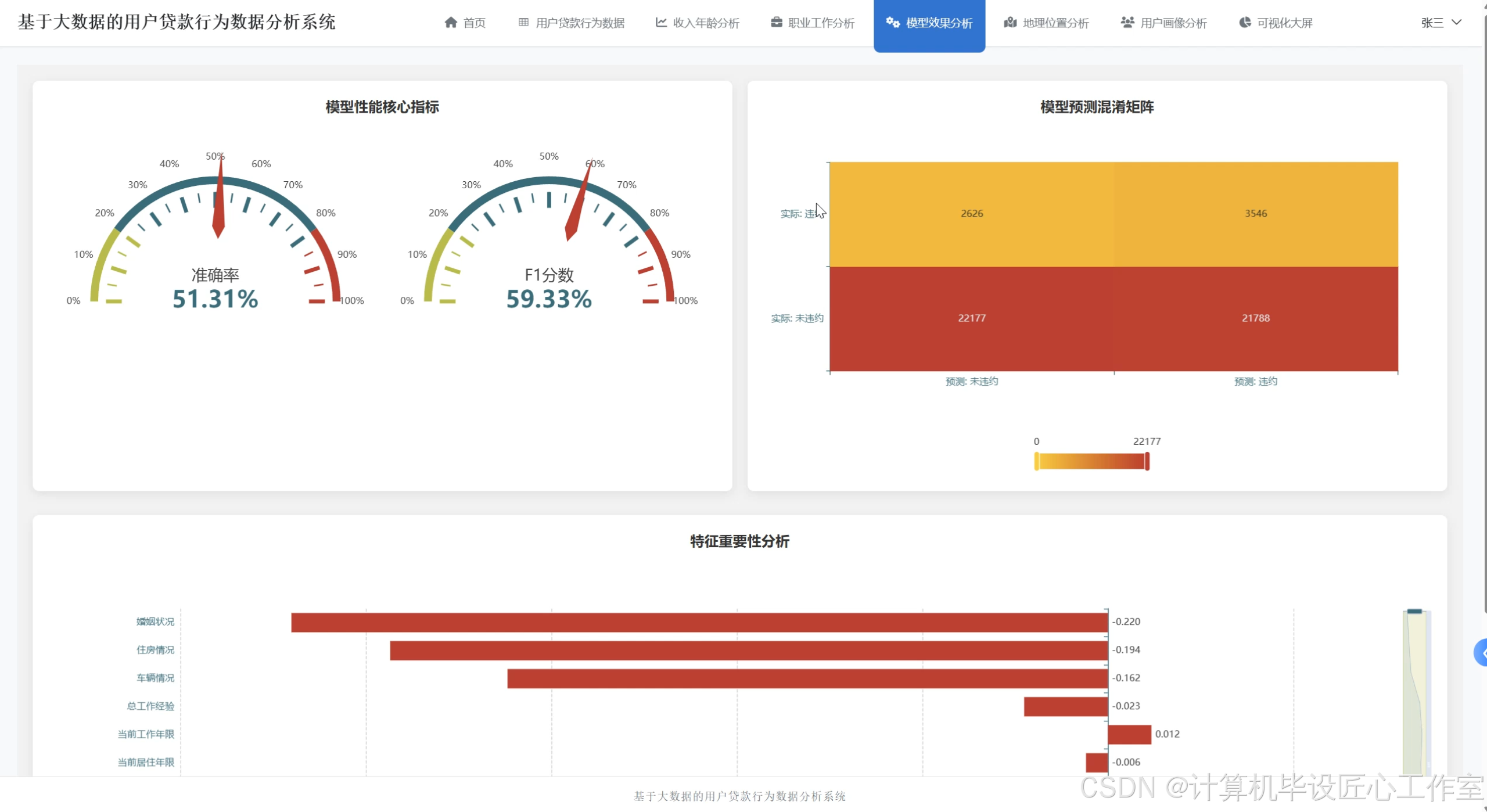
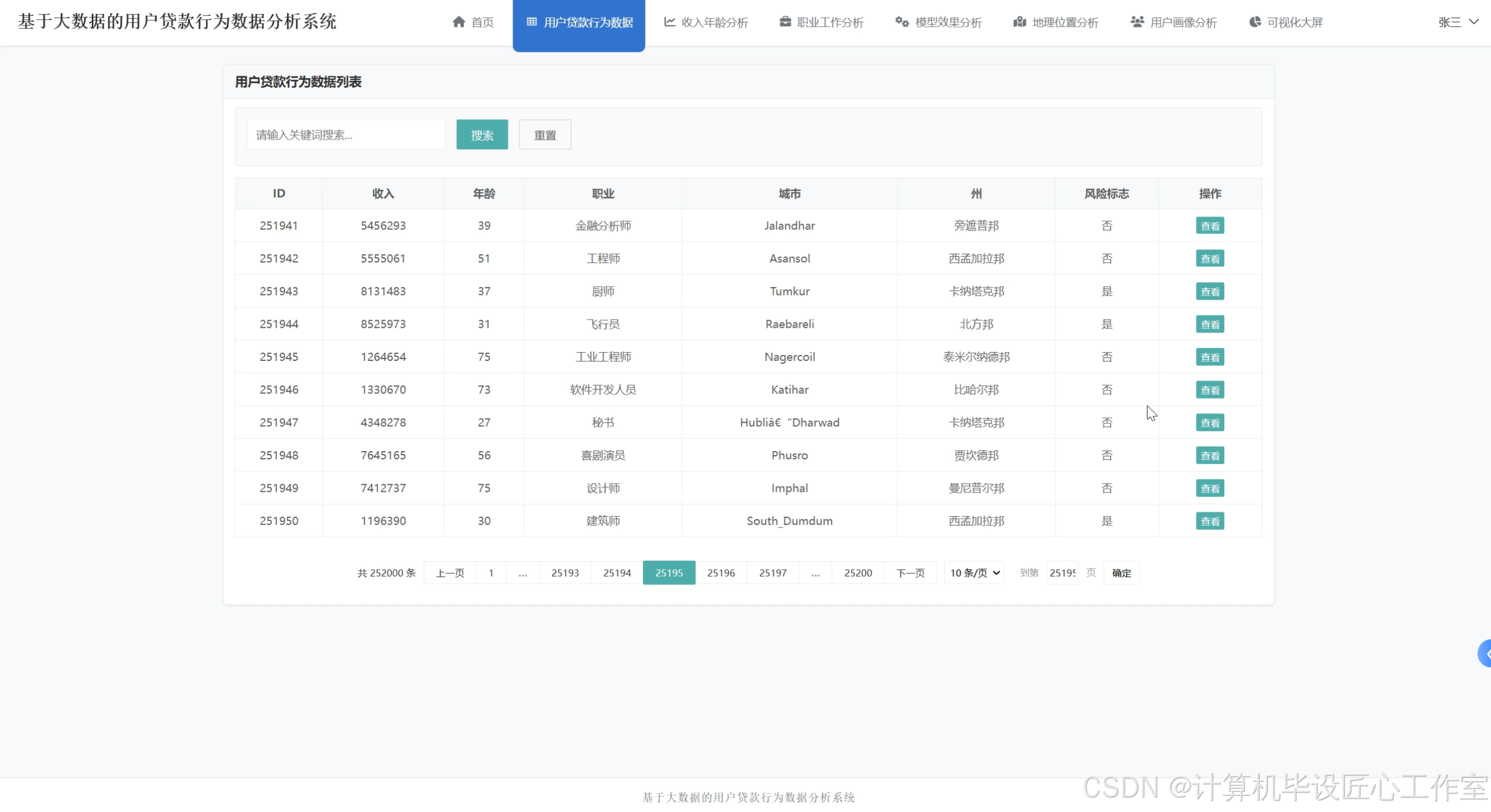
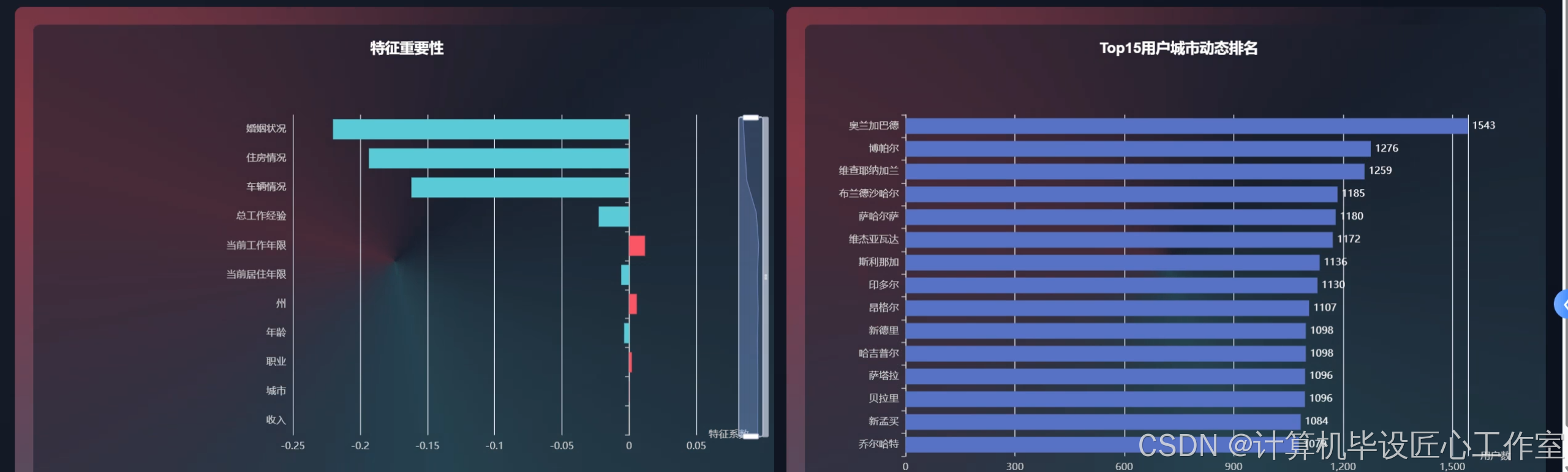
基于大数据的用户贷款行为数据分析系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, when, avg, sum, desc, asc, round
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType
from pyspark.ml.feature import StringIndexer, VectorAssembler, StandardScaler
from pyspark.ml.classification import LogisticRegression, DecisionTreeClassifier
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml import Pipeline
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import re
spark = SparkSession.builder.appName("LoanBehaviorAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def user_profile_analysis(df):
marital_analysis = df.groupBy("marital_status").agg(
count("*").alias("用户数量"),
avg("income").alias("平均收入"),
avg("age").alias("平均年龄"),
(sum(when(col("risk_flag") == 1, 1).otherwise(0)) / count("*") * 100).alias("违约率")
).orderBy(desc("用户数量"))
marital_df = marital_analysis.toPandas()
marital_df["违约率"] = marital_df["违约率"].round(2)
marital_df["平均收入"] = marital_df["平均收入"].round(0).astype(int)
marital_df["平均年龄"] = marital_df["平均年龄"].round(1)
marital_df = marital_df.sort_values("用户数量", ascending=False)
marital_df["用户占比"] = (marital_df["用户数量"] / marital_df["用户数量"].sum() * 100).round(2)
high_risk_marital = marital_df[marital_df["违约率"] > marital_df["违约率"].mean()]
marital_df["风险等级"] = marital_df["违约率"].apply(lambda x: "高风险" if x > marital_df["违约率"].mean() else "低风险")
house_analysis = df.groupBy("house_ownership").agg(
count("*").alias("用户数量"),
avg("income").alias("平均收入"),
avg("current_job_yrs").alias("平均工作年限"),
(sum(when(col("risk_flag") == 1, 1).otherwise(0)) / count("*") * 100).alias("违约率")
).orderBy(desc("用户数量"))
house_df = house_analysis.toPandas()
house_df["违约率"] = house_df["违约率"].round(2)
house_df["平均收入"] = house_df["平均收入"].round(0).astype(int)
house_df["平均工作年限"] = house_df["平均工作年限"].round(1)
house_df["用户占比"] = (house_df["用户数量"] / house_df["用户数量"].sum() * 100).round(2)
house_df["收入稳定性"] = house_df.apply(lambda row: "稳定" if row["平均工作年限"] > 3 else "一般", axis=1)
return marital_df, house_df
def income_age_analysis(df):
df_pandas = df.select("age", "income", "risk_flag", "experience", "current_job_yrs").toPandas()
df_pandas["age_group"] = pd.cut(df_pandas["age"], bins=[0, 25, 35, 45, 100], labels=["青年", "中年", "中老年", "老年"])
df_pandas["income_level"] = pd.cut(df_pandas["income"], bins=[0, 300000, 600000, 1000000, float("inf")], labels=["低收入", "中等收入", "中高收入", "高收入"])
age_group_analysis = df_pandas.groupby("age_group").agg({
"age": "count",
"income": "mean",
"experience": "mean",
"risk_flag": lambda x: (x == 1).mean() * 100
}).round(2)
age_group_analysis.columns = ["用户数量", "平均收入", "平均工作经验", "违约率"]
age_group_analysis["平均收入"] = age_group_analysis["平均收入"].round(0).astype(int)
age_group_analysis["用户占比"] = (age_group_analysis["用户数量"] / age_group_analysis["用户数量"].sum() * 100).round(2)
income_level_analysis = df_pandas.groupby("income_level").agg({
"income": ["count", "mean"],
"age": "mean",
"current_job_yrs": "mean",
"risk_flag": lambda x: (x == 1).mean() * 100
}).round(2)
income_level_analysis.columns = ["用户数量", "平均收入", "平均年龄", "平均工作年限", "违约率"]
income_level_analysis["平均收入"] = income_level_analysis["平均收入"].round(0).astype(int)
income_level_analysis["用户占比"] = (income_level_analysis["用户数量"] / income_level_analysis["用户数量"].sum() * 100).round(2)
income_level_analysis["风险评级"] = income_level_analysis["违约率"].apply(lambda x: "高风险" if x > 15 else ("中风险" if x > 8 else "低风险"))
return age_group_analysis.reset_index(), income_level_analysis.reset_index()
def loan_prediction_model(df):
df_ml = df.select("age", "income", "experience", "current_job_yrs", "house_ownership", "car_ownership", "profession", "city", "state", "risk_flag")
categorical_columns = ["house_ownership", "car_ownership", "profession", "city", "state"]
indexers = [StringIndexer(inputCol=col, outputCol=f"{col}_indexed", handleInvalid="keep") for col in categorical_columns]
numeric_columns = ["age", "income", "experience", "current_job_yrs"]
indexed_columns = [f"{col}_indexed" for col in categorical_columns]
all_feature_columns = numeric_columns + indexed_columns
assembler = VectorAssembler(inputCols=all_feature_columns, outputCol="features")
scaler = StandardScaler(inputCol="features", outputCol="scaled_features")
lr = LogisticRegression(featuresCol="scaled_features", labelCol="risk_flag", maxIter=100)
pipeline = Pipeline(stages=indexers + [assembler, scaler, lr])
train_df, test_df = df_ml.randomSplit([0.8, 0.2], seed=42)
model = pipeline.fit(train_df)
predictions = model.transform(test_df)
evaluator = BinaryClassificationEvaluator(labelCol="risk_flag", metricName="areaUnderROC")
auc_score = evaluator.evaluate(predictions)
accuracy_evaluator = BinaryClassificationEvaluator(labelCol="risk_flag", metricName="areaUnderPR")
pr_score = accuracy_evaluator.evaluate(predictions)
prediction_summary = predictions.groupBy("risk_flag", "prediction").count().collect()
confusion_matrix = {}
for row in prediction_summary:
confusion_matrix[f"实际_{row['risk_flag']}_预测_{row['prediction']}"] = row["count"]
feature_importance = model.stages[-1].coefficients.toArray()
feature_names = all_feature_columns
importance_df = pd.DataFrame({
"特征名称": feature_names,
"重要性系数": feature_importance,
"重要性绝对值": np.abs(feature_importance)
}).sort_values("重要性绝对值", ascending=False)
importance_df["重要性排名"] = range(1, len(importance_df) + 1)
model_metrics = pd.DataFrame({
"评估指标": ["AUC Score", "PR Score", "训练样本数", "测试样本数"],
"指标值": [round(auc_score, 4), round(pr_score, 4), train_df.count(), test_df.count()]
})
return model_metrics, importance_df, confusion_matrix基于大数据的用户贷款行为数据分析系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
Java实战项目
Python实战项目
微信小程序|安卓实战项目
大数据实战项目
PHP|C#.NET|Golang实战项目🍅 主页获取源码联系🍅