参考文本转语音TTS工具合集(上),资料搜集自网络。
KittenTTS
KittenML团队推出开源TTS,模型体积仅为25MB,参数量约1500万,是目前最小的开源TTS模型之一。无需GPU支持,可在树莓派、低功耗嵌入式设备或移动端实时运行,预置4男4女共8种音色,支持多语言(目前主要支持英语),并通过ONNX/PyTorch格式集成到各种应用中。
技术原理
- 模型压缩技术:通过知识蒸馏或参数剪裁技术,将传统百兆级TTS模型大幅压缩至25MB。在压缩过程中,尽量保留语音的自然度,确保输出语音的质量不受影响。减小模型体积,提高运行效率,使其能够在低功耗设备上高效运行。
- CPU推理优化:采用ONNX Runtime进行推理加速,避免对GPU的依赖。使得KittenTTS能够在资源受限的设备上实时运行,满足各种实时交互场景的需求。
- 端到端神经语音合成:采用端到端的神经语音合成技术,直接将文本映射到语音波形,无需复杂的中间步骤。兼顾效率与语音自然度,提升整体的语音生成效果,使得生成的语音更加流畅自然。
- 离线缓存机制:首次运行时会下载模型权重并缓存到本地,后续运行无需联网。提高模型运行效率,增强实用性,使其能够在无网络环境下稳定运行。
安装及使用:
py
pip install kittentts, soundfile
from kittentts import KittenTTS
import soundfile as sf
m = KittenTTS("KittenML/kitten-tts-nano-0.1")
audio = m.generate("This high quality TTS model works without a GPU", voice='expr-voice-2-f')
sf.write('output.wav', audio, 24000)高级使用技巧
- 自定义音色:可通过训练自己的语音数据来生成新的音色。提供训练工具和文档,帮助开发者进行音色定制。
- 集成到Web应用:支持ONNX格式,可将其集成到Web应用中。通过WebAssembly技术,可部署到浏览器中,实现网页端的语音合成功能。
- 嵌入式系统集成:轻量化设计和CPU优化使其能够轻松集成到各种硬件设备中。可使用C++或其他语言将KittenTTS移植到目标硬件上。
FlowSpeech
ListenHub背后的TTS技术,支持流式响应,最快三秒开读,合成1000字的内容,也只需要10秒种。
技术特点:
- 上下文感知:通过对上下文的深度理解,让模型不仅能读出来,真正弄懂内容;
- 多模态支持:基于多模态模型,不仅能读文字,还能读图片、PDF、文稿;
- 智能剪裁:通过智能感知,可自动去除所有不适合朗读的内容,如广告、代码块、乱码等
GPT-SoVITS
参数量仅330M+77M。
Muyan-TTS
MYZY AI团队论文推出开源Muyan-TTS,专为播客场景设计,能够在无需大量目标说话人数据的情况下实现高质量的语音合成,并支持说话人适配和个性化语音定制。
预训练超过10万小时的播客音频数据,能够实现零样本语音合成,即无需大量目标说话人的语音数据,仅通过少量参考语音和文本即可生成高质量语音。还支持说话人适配功能,可以通过少量目标说话人的语音数据进行微调,实现个性化语音定制。其合成速度快,仅需0.33秒即可生成1秒音频,适合实时应用,并且能够自然连贯地合成长篇内容,如播客、有声书等。
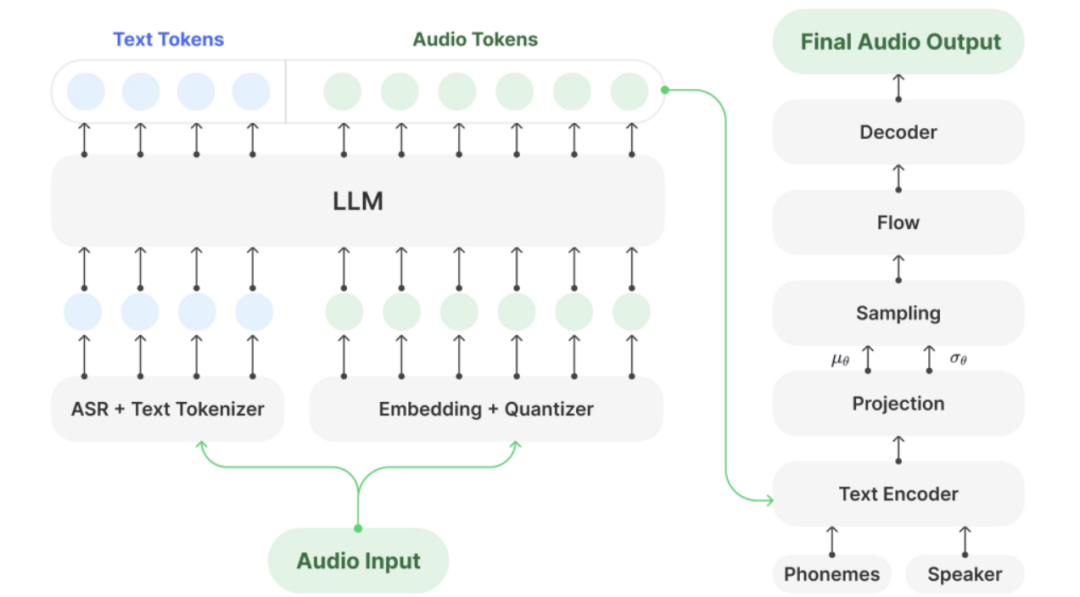
原理
- 框架设计:基于GPT-SoVITS框架,结合预训练的Llama-3.2-3B,以及SoVITS模型进行音频解码。LLM负责将文本和音频token对齐,生成中间表示,而SoVITS模型则将中间表示解码为音频波形。既利用LLM强大的文本语义理解能力,又通过SoVITS模型实现了高质量的音频生成。
- 数据处理:数据集包含超过10万小时的播客音频数据,经过多阶段处理,包括数据收集、清洗和格式化,确保数据的高质量和多样性。步骤:
- 数据收集:从开源数据集和专有播客内容中收集音频数据,经过质量评估后,保留高质量音频;
- 数据清洗:通过音乐源分离、去混响、去回声和降噪等技术,提升音频质量;
- 数据格式化:将音频分割为单句,去除短于5秒的片段,并使用ASR模型将音频转录为文本,形成平行语料库。
- 预训练与微调:LLM在平行语料库上进行预训练,学习文本和音频token之间的关系。在此基础上,通过SFT,利用少量目标说话人的语音数据进一步优化模型,提高语音合成的自然度和相似度。
- 解码器优化:采用VITS基础模型作为解码器,减少幻觉问题,提高语音生成的稳定性和自然度。解码器在高质量音频数据上进行微调,进一步提升合成语音的保真度和表现力。
- 推理加速:通过高效的内存管理和并行推理技术,显著提高推理速度,降低延迟。模型支持API模式,自动启用加速功能,适合实时应用。
功能
- 零样本语音合成:传统语音合成需大量目标说话人数据,门槛高。Muyan-TTS只需少量参考语音和文本,就能生成高质量语音。
- 说话人适配:当下用户对语音个性化需求多样。通过少量目标说话人语音数据微调,可定制个性化语音。不管是甜美女声、沉稳男声,还是特殊风格语音,都能精准实现。
- 快速生成:在快节奏的内容创作中,速度至关重要。合成速度惊人,0.33秒就能生成1秒音频。无论是实时场景还是批量生成,都能快速响应。
- 长内容连贯合成:传统TTS模型合成长篇内容时易出现衔接问题。Muyan-TTS凭借先进技术,能自然连贯地合成播客、有声书等长篇内容。它准确把握语义和情感,使语音在语速、语调、停顿上自然流畅,给听众带来良好的听觉享受。
- 离线部署友好:支持本地部署和推理,保证数据隐私。
测评
在与CosyVoice2、Step-Audio、Spark-TTS、FireRedTTS和GPT-SoVITS v3等其他开源TTS模型的对比中,Muyan-TTS在合成速度上表现出色,仅需0.33秒即可生成1秒音频,是目前测试模型中最快的。在语音质量和自然度方面,Muyan-TTS也表现出色,其在LibriSpeech和SEED数据集上的测试结果显示,其在词错误率(WER)、说话人相似度(SIM)和平均意见得分(MOS)等指标上均达到较高水平。
在零样本语音合成测试中,在LibriSpeech测试集上取得3.44%的WER,4.58的MOS和0.37的SIM,在SEED测试集上取得4.09%的WER,4.32的MOS和0.41的SIM。
通过在少量目标说话人数据上进行监督微调,Muyan-TTS-SFT在语音质量和说话人相似度方面进一步提升。在LibriSpeech测试集上,Muyan-TTS-SFT的WER为4.48%,MOS为4.97,SIM为0.46,相较于基础模型有显著提升。
部署
bash
git clone https://github.com/MYZY-AI/Muyan-TTS.git
cd Muyan-TTS
conda create -n muyan-tts python=3.10 -y
conda activate muyan-tts
make build
sudo apt update
sudo apt install ffmpeg
# 启动API服务,默认端口8020
python api.py实例
py
async def main(model_type, model_path):
tts = Inference(model_type, model_path, enable_vllm_acc=False)
wavs = await tts.generate(
ref_wav_path="assets/Claire.wav",
prompt_text="Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.",
text="Welcome to the captivating world of podcasts, let's embark on this exciting journey together."
)
output_path = "tts.wav"
with open(output_path, "wb") as f:
f.write(next(wavs))
print(f"generated in {output_path}")
import time
import requests
TTS_PORT = 8020
payload = {
"ref_wav_path": "assets/Claire.wav",
"prompt_text": "Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.",
"text": "Welcome to the captivating world of podcasts, let's embark on this exciting journey together.",
"temperature": 0.6,
"speed": 1.0,
}
url = f"http://localhost:{TTS_PORT}/get_tts"
response = requests.post(url, json=payload)
audio_file_path = "logs/tts.wav"
with open(audio_file_path, "wb") as f:
f.write(response.content)ZipVoice-Dialog
论文,随着notebook lm的大火,对话语音合成(播客生成)也火了一把,ZipVoice(论文,GitHub)在零样本对话语音合成上的扩展ZipVoice-Dialog。解决现有对话语音合成模型在稳定性和推理速度上的瓶颈,实现又快又稳又自然的语音对话合成。ZipVoice-Dialog模型文件、训练代码和推理代码以及6.8k小时的语音对话数据集OpenDialog已全部开源。
相对单说话人语音合成,对话语音合成需要在一句话中合成不同的说话人音色,且需实现自然且准确的说话人切换,因此更有挑战性。此前的对话语音合成模型均为自回归模型,面临着推理速度慢和合成稳定性差的问题。ZipVoice-Dialog基于非自回归模型建模,借助ZipVoice架构的建模能力和针对对话语音的技术优化,实现又快又稳又自然的对话语音合成。
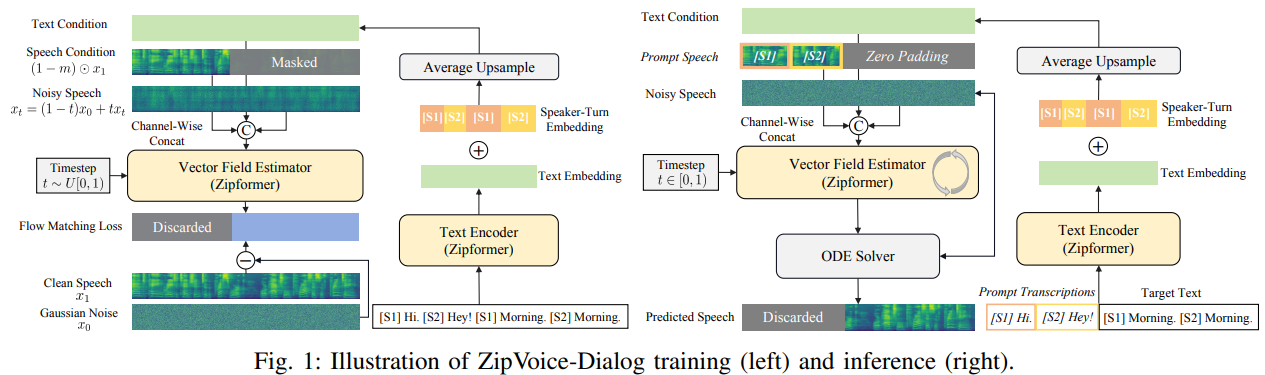
应用
- 说话人轮次嵌入向量:精准区分对话角色
对话语音合成中的一个常见问题是说话人的语音混淆,即在某些说话人轮次中使用错误的说话人音色。为解决这一问题,引入Speaker-Turn Embedding(说话人轮次嵌入向量,STE)为模型提供细粒度的精准说话人身份提示,降低模型对说话人切换建模的难度。首先对输入文本的每个token根据角色匹配其对应的STE,然后把STE加在文本token的Text Embedding上送入主干网络。 - 课程学习:从单说话人到对话的稳定迁移
由于对话语音中包含两个说话人音色,其声学上的高复杂度导致文本-语音对齐关系较难学习。为了解决这一问题,采用课程学习策略,使用单说话人语音的预训练解决对齐难题,两阶段训练:- 单说话人语音数据预训练,复用ZipVoice在100k小时单说话人数据集Emilia上的权重,夯实语音-文本对齐能力;
- 对话语音数据微调,在对话语音数据上微调,学习说话人角色切换和自然对话语音风格。
- 立体声扩展:双声道对话的沉浸感优化
在一些应用场景下,将双人语音分别分配到不同的声道上可得到更好体验,通过以下技术将ZipVoice-Dialog进行扩展,实现双声道生成功能:- 权重初始化:以单声道ZipVoice-Dialog模型的权重作为训练起点,其中单声道模型的输入输出投影层的权重通过复制和缩放以适配双声道模型的扩展维度,避免随机初始化导致的性能损失;
- 单声道语音正则化:训练中交替使用双声道与单声道数据,通过共享核心模型权重,防止过度遗忘单声道语音知识;
- 说话人互斥损失:由于角色重叠时通常带来语音质量降低,使用说话人互斥损失惩罚两声道同时发声的帧。
在由真实语音对话构建的中英文对话语音合成测试集上对比ZipVoice-Dialog与其他两个对话语音合成模型Dia、MoonCast;ZipVoice-Dialog在参数量显著减小和推理速度显著提升的同时,实现说话人相似度(cpSIM)、词错误率(WER)、语音质量(UTMOS)和说话人转折准确度(cpWER)的显著改善。
OpenDialog
大规模高质量训练数据是增强LLM性能的基础,但对话语音合成领域目前尚无大规模开源数据。团队构建6.8k小时的对话语音合成数据集OpenDialog,包含1.7k小时的中文数据和5.1k小时的英文数据。
构建流程:
- 对话语音数据挖掘:通过VAD过滤非语音段→说话人日志模型标注角色→ASR转录生成文本→LLM分类筛选对话内容,从大量音频中提取有效对话语音文件;
- 带角色标签的精准ASR转录:基于WhisperD模型实现带角色标签的转录,有效解决传统说话人日志+ASR模型方案在短语音片段(如嗯、对)上的的识别错误和角色错配问题;
- 低质量样本过滤:为了保证训练数据质量,一方面采用一系列人工设计的规则过滤掉 ASR转写异常的语音数据,过滤规则包括异常的说话人轮次数、非预期的符号、异常的词数时长比、过多的字符重复以及过长的单词等;使用DNSMOS得分作为语音质量参考,过滤掉得分小于2.8的嘈杂语音。