1. 引言
1.1 研究背景与问题缘起
随着ChatGPT、Sora等生成式人工智能模型的突破性进展,我们正站在教育范式变革的历史节点。传统的个性化学习系统,多依赖于预先构建的知识图谱和静态的学生模型,实现的是在有限路径下的"选择题"式自适应。生成式AI的涌现能力------包括深度的语境理解、自由的内容创造、连贯的逻辑推理和自然的多轮对话------使其能够扮演一个更具动态性、生成性和认知深度的学习伙伴。然而,当前产业界和学术界的多数应用,仍停留在将AI视为一个"超级内容生成器"或"知识问答机"的层面,未能从根本上触及个性化学习的核心:即对学习者认知过程的深度理解、赋能与优化。
1.2 问题提出
当前研究存在三大瓶颈:
- 动态感知不足:现有系统难以实时捕捉并更新学习者的情感状态、元认知策略和思维演进过程。
- 认知支持浅表化:支持手段多为提供答案或资源,缺乏对学习者认知架构的干预,未能有效管理其认知负荷,以促进高阶思维。
- 伦理考量滞后:在追求效率的同时,对数据隐私、算法公平及人机主体性等伦理风险的系统性研究尚不充分。
1.3 研究内容与价值
本研究旨在提出并阐释一个全新的生成式AI教育应用范式。我们将其定位为 "数字镜像"与"认知负能者"的协同体 。前者实现对学习者全息、动态的建模,后者则在此基础上提供精准的认知干预。本文的核心研究内容是构建一个 "人机协同双向进化"模型 ,并深入剖析其背后的伦理挑战与规制路径。本研究的价值在于,从理论和实践两个层面,为构建负责任的、以增强人类智能为终极目标的新一代个性化学习环境提供关键性的支撑。
2. 文献综述与理论框架
2.1 生成式AI在教育应用中的演进路径
- 1.0 阶段:内容生成工具。侧重于自动化生成习题、教案、课件等,提升教学准备效率。
- 2.0 阶段:对话式答疑助手。以智能导学系统为代表,通过问答提供即时支持,但对话深度和语境理解有限。
- 3.0 阶段(本研究聚焦点):情境感知的个性化学习伙伴。融合多模态信息,具备长期记忆和用户画像能力,能够进行启发式、引导式的教学对话,关注学习者的认知与情感状态。
2.2 个性化学习理论的内核深化
个性化学习已从路径个性化 (学什么、何时学)深化为过程个性化(如何学)。这不仅包括知识状态的评估,更囊括了:
- 认知风格:场依存型与场独立型等。
- 元认知能力:计划、监控、调节自身学习过程的能力。
- 动机与情感 :学习驱动力、挫折耐受度、焦虑水平等。
生成式AI为实现这种深度个性化提供了前所未有的技术可能。
2.3 核心理论框架:"数字镜像"与"认知负能"的融合
-
2.3.1 "数字镜像"理论模型
- 内涵:"数字镜像"是一个由AI构建并维护的、对学习者认知、情感和行为的动态数字化映射。它不是一个静态标签的集合,而是一个能够模拟、预测学习者行为的计算模型。
- 构成维度 :
- 知识状态镜像:对概念掌握程度、知识结构、错误模式的动态描绘。
- 认知过程镜像:表征问题解决策略、注意力分配、工作记忆负荷等。
- 元认知镜像:反映其学习计划性、自我检查与调节策略。
- 情感动机镜像:刻画在学习过程中的情绪变化、兴趣点与内在动机水平。
- 构建技术:基于Transformer架构的序列建模、对交互日志的深度学习分析、潜在语义分析等。
-
2.3.2 "认知负能"机制
- 理论基础 :源于Sweller的认知负荷理论。人类工作记忆容量有限,学习过程中的负荷分为内部负荷 (源于知识本身的复杂性)、外部负荷 (源于糟糕的教学设计)和关联负荷(用于图式构建的有效负荷)。
- AI的负能角色 :生成式AI的核心作用是通过精准干预,最大限度地减少无效的外部认知负荷 ,并优化关联认知负荷。
- 实现方式 :
- 信息过滤与整合:从海量网络信息中提取、精炼并组织与学习者当前目标最相关的内容。
- 复杂任务分解:将复杂问题分解为符合"最近发展区"理论的、可管理的子步骤。
- 多模态表征:根据学习者偏好,将抽象概念以文本、图示、类比、故事等多种形式呈现,降低理解门槛。
- 自动化基础操作:承担繁琐的计算、格式调整等低认知价值工作,让学习者聚焦于核心逻辑。
3. "人机协同双向进化"支持者模型构建
本章旨在提出并详细阐述一个名为"人机协同双向进化"的生成式AI个性化学习支持者模型。该模型的核心思想是:学习者与AI并非简单的主客体关系,而是形成一个相互塑造、共同成长的耦合系统。 AI通过构建并更新学习者的"数字镜像"来提供精准的"认知负能",而学习者在AI支持下的行为与成长又反过来训练和优化AI本身。模型是一个包含四个逻辑层次(感知层、决策层、交互层、进化层)的动态闭环系统,其整体架构如下图所示:
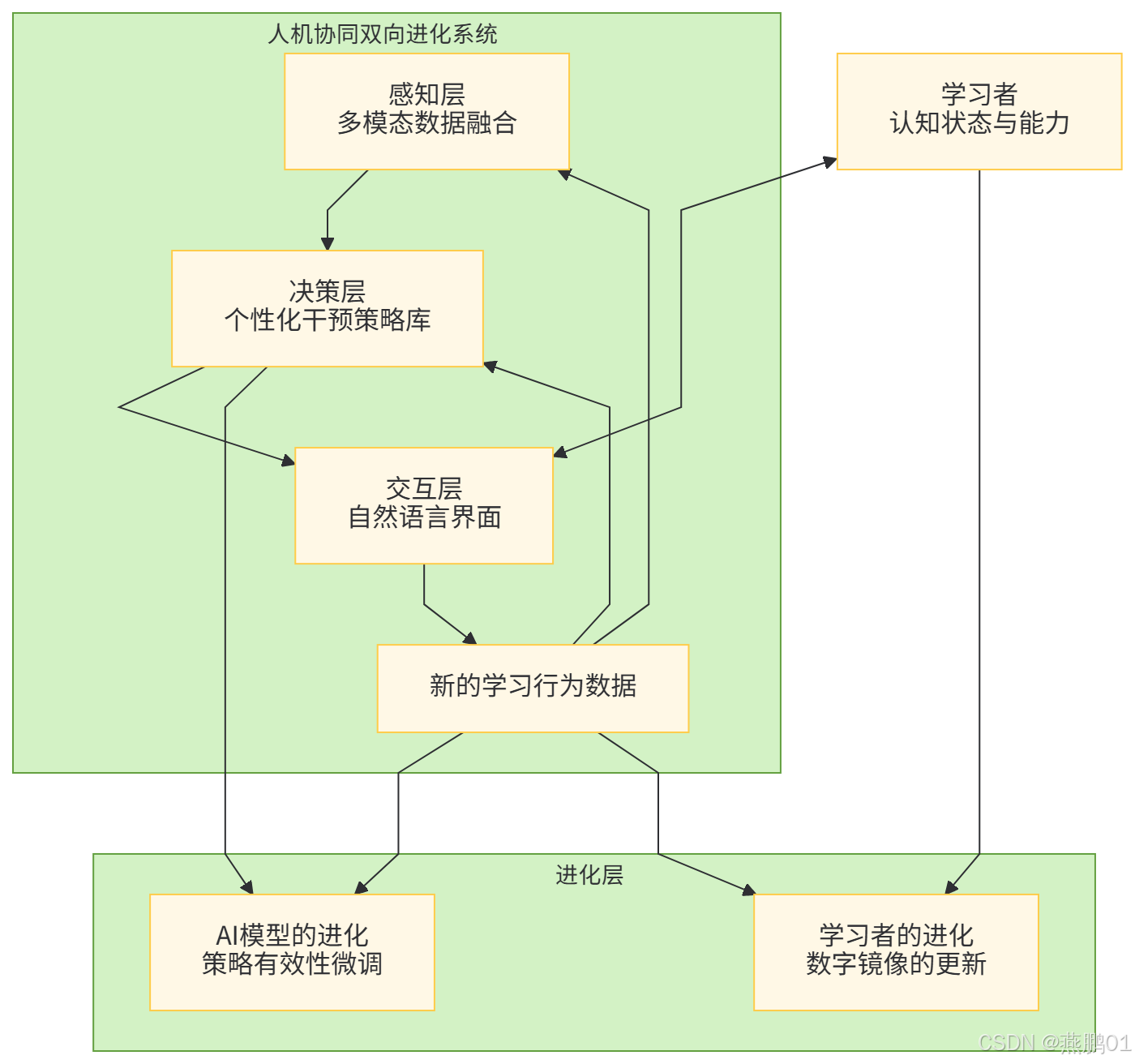
3.1 感知层:多模态数据融合与动态"数字镜像"构建
感知层是整个模型的基础,其任务是从多维度、多模态的交互数据中,实时感知并描绘学习者的状态,构建其动态的"数字镜像"。
3.1.1 多模态数据采集与预处理
-
数据来源:
- 显性认知数据 :
- 对话文本:与AI的全部问答记录,蕴含知识疑问、思维逻辑和语言能力。
- 作业与测评数据:答题正误、用时、修改痕迹、错误类型。
- 自我总结与笔记:学习者主动创作的内容,反映其知识组织与元认知水平。
- 隐性行为数据 :
- 交互日志:在学习平台上的点击流、页面停留时间、视频暂停/回放点、菜单搜索关键词。
- 问题解决路径:在交互式编程环境或虚拟实验室中的操作序列,可用于分析其问题解决策略。
- 情感与生理数据(需审慎授权) :
- 语音信号:通过麦克风采集的语调、语速、停顿,用于分析困惑、确信或挫折感。
- 视觉信号:通过摄像头采集的面部表情(如专注、疑惑)、头部姿态。
- 生理信号:通过可穿戴设备采集的心率、皮电反应,作为认知负荷的间接指标。
- 显性认知数据 :
-
数据预处理与向量化 :
采用嵌入技术将非结构化的多模态数据转化为机器可理解的数值向量。例如,使用Sentence-BERT处理文本,使用预训练视觉模型处理图像表情,将时间序列的行为日志转化为特征向量。所有这些向量构成一个全面描述学习者当前状态的状态向量。
3.1.2 "数字镜像"的动态建模
"数字镜像"不是一个静态的学生档案,而是一个随时间演化的、高维的、可计算的状态模型。我们将其建模为一个动态图网络或一个由循环神经网络维护的状态空间。
-
核心维度:
- 知识状态子图:以概念为节点,以掌握程度为边权,动态反映知识结构的变化与薄弱点。
- 认知特征向量:表征当前工作记忆负荷、注意力集中度、主要认知风格(如场依存/独立)。
- 元认知水平指标:包括计划性、监控准确性(能否正确判断自己的理解程度)、调节策略的丰富性。
- 情感动机状态:当前的情感效价(积极/消极)与唤醒度(平静/兴奋),以及对当前任务的内在动机水平。
-
更新机制 :
"数字镜像"以流式方式更新。每一个新的交互事件(如一次答题、一次提问)都会作为一个输入,通过模型(如LSTM或Transformer)计算出新的状态向量,从而实现对学习者画像的实时、平滑更新。
3.2 决策层:基于"数字镜像"的个性化干预策略库
决策层是AI作为"认知负能者"的"大脑"。它接收来自感知层的"数字镜像"状态,并从一系列预设的、经过教育学理论验证的干预策略中,选择并生成最合适的支持内容。
3.2.1 策略选择的决策逻辑
决策过程是一个条件-动作的匹配系统,但其核心在于对"数字镜像"的深度解读。
- IF (状态) THEN (策略) :
- IF :"知识状态子图"显示概念A与概念B的链接薄弱,且 "认知特征"显示当前工作记忆负荷较高。
- THEN:触发**"动态脚手架"** 策略,而非直接讲解,以降低外部认知负荷。
- IF :对话文本分析显示学习者得出一个逻辑跳跃的结论,且 "元认知水平"显示其自我监控能力较弱。
- THEN:触发**"苏格拉底式诘问"** 策略,引导其审视思考过程。
- IF :学习者快速连续地答对多个问题,且 "情感动机"状态显示为"轻松"。
- THEN:触发**"元认知训练场"** 策略,促使其进行深度反思。
3.2.2 核心干预策略详解
-
动态脚手架策略
- 目标:在学习者的"最近发展区"内提供恰到好处的支持,并随着其能力提升而逐渐淡出。
- 实现:AI根据"数字镜像"中的知识漏洞和认知负荷水平,生成提示、样例、部分解决方案或思维导图框架。例如,在编程学习中,AI不是直接给出代码,而是生成一个包含关键注释的函数框架,让学习者填充核心逻辑。
-
苏格拉底式诘问策略
- 目标:培养批判性思维和深度推理能力,引导学习者自我发现并纠正错误。
- 实现 :AI被设计为一个"诘问者",通过一系列问题发起挑战:
- 澄清性问题:"你所说的'效率更高'具体是指什么?"
- 探究假设的问题:"你的这个方案基于什么前提?这个前提一定成立吗?"
- 证据与理由问题:"有哪些数据或现象支持你的观点?"
- 视角与反例问题 :"如果从Y的角度看,会有什么不同?你能想到一个反例吗?"
此策略强制学习者外化其思维过程,并进行自我审查。
-
元认知训练场策略
- 目标:将学习者的注意力从任务内容转移到其自身的思维过程和策略上。
- 实现 :AI在关键节点主动进行元认知提示:
- 计划阶段:"在开始之前,你计划采用什么策略?"
- 监控阶段:"你目前的理解程度如何?有没有感觉困惑的地方?"
- 评估阶段 :"你刚才的解决方法非常巧妙,你能总结一下它的核心思想吗?" 或 "有没有可能还有一种更简洁的解法?"
这旨在将元认知技能从一种"隐性知识"显性化,并通过反复练习内化为习惯。
3.3 交互层:自然、共情的对话界面
决策层的策略最终通过交互层传递给学习者。本模型强调自然语言作为核心交互媒介,因为它最符合人类沟通习惯,能承载复杂的逻辑和情感。
- 对话管理:系统需要维护复杂的对话状态,理解指代、管理话题的切换,确保对话的连贯性。
- 情感计算与共情响应:AI需要生成不仅正确、而且具有情感智能的回应。例如,当"数字镜像"检测到学习者有挫败感时,AI的回应应是鼓励性的:"这个问题确实挑战性很大,我们分解开来看,你已经完成了第一步,这很棒!" 这种共情能建立信任,维持学习动机。
3.4 进化层:双向反馈与模型迭代
这是实现"双向进化"的关键,使系统成为一个活的、能够学习的学习者。
-
AI的进化(机向人进化):
- 反馈回路 :学习者对AI提供的支持的直接反馈(如"有帮助"/"无帮助"按钮)、间接反馈(如忽略AI的建议、或立即接受)以及长期的学业成绩数据,都构成了强化学习信号。
- 迭代机制 :这些信号被用于对生成式AI模型(特别是策略选择器)进行微调,使其干预策略变得越来越精准、有效和个性化。例如,如果某种类型的"脚手架"总是被学习者跳过,系统将降低该策略的优先级或调整其呈现方式。
-
人的进化(人向机进化):
- 反馈回路:学习者在AI支持下所取得的一切进步------新知识的掌握、错误模式的纠正、元认知能力的提升------都会实时地更新其"数字镜像"。
- 迭代机制 :一个更新后的、更先进的"数字镜像"会引导AI提供下一阶段更适配、更具挑战性的支持。这就形成了一个正向反馈循环:AI的支持促进了学习者的成长,学习者的成长又指引AI提供更高级的支持,从而实现二者在能力阶梯上的共同攀升。
总结而言,本章所构建的"人机协同双向进化"模型,是一个将状态感知、智能决策、自然交互和持续进化融为一体的有机系统。它从理论和实践上定义了生成式AI如何超越工具角色,成为一个能够与学习者共同成长的、真正的"认知负能者"。
4. 前沿伦理挑战与规制路径
4.1 核心伦理挑战
- 挑战一:算法偏见与"镜像牢笼"
- 风险:若训练数据存在对特定性别、种族、文化背景的偏见,AI构建的"数字镜像"可能失真,并可能通过"回音室效应"不断强化这种偏见,最终将学习者禁锢在算法定义的"牢笼"中,限制其多元化发展。
- 挑战二:数据隐私与"数字透明人"
- 风险:构建精细"数字镜像"的过程,意味着对学习者思想和行为的全方位、无死角监控。这创造了福柯意义上的"全景监狱",导致数据滥用、心理压力和学习行为异化。
- 挑战三:认知依赖与主体性消解
- 风险:当AI过于强大和贴心,学习者可能放弃独立思考,形成"路径依赖"和"思维惰性",导致解决问题能力、抗挫折能力和知识内化能力的退化。
4.2 综合性伦理规制路径
-
路径一:技术可解释性与算法问责(技术层面)
- 措施:发展可解释AI技术,使"数字镜像"的关键特征和AI的决策逻辑能够被教师和学生理解。例如,AI应能回答"我为什么认为你在这个知识点上存在困难?"。
- 框架:建立"算法影响评估"制度,在教育场景部署前对AI模型进行公平性、偏见审计。
-
路径二:数据信托与协同治理(治理层面)
- 措施:引入"数据信托"模式。由学校、家长、教育专家和学生代表共同信任的独立第三方机构,作为受托人来管理、授权和使用学生的学习数据。这改变了当前平台独占数据的局面,将数据主权归还给学习者共同体。
- 机制:建立明确的数据采集"负面清单",明确规定哪些敏感数据(如情绪数据)在任何情况下都不得采集。
-
路径三:人在回路的混合增强智能(设计层面)
- 措施:在系统设计中硬性规定"教师在回路"和"学习者在回路"原则。AI提供的学习路径重大调整、长期评估报告等,必须经由教师审核确认。同时,系统应允许学习者查看并质疑自己的"数字镜像",并有权选择是否接受AI的深度介入。
- 目标:确保人类始终处于主导和监督地位,AI是"增强智能"而非"替代智能"。
5. 结论与展望
5.1 研究结论
本文系统论证了将生成式AI重新定义为"数字镜像"与"认知负能者"协同体的必要性与可行性。通过构建"人机协同双向进化"模型,我们展示了AI如何通过深度感知和精准干预,实现从"知识传递"到"认知赋能"的范式转变。同时,本文前瞻性地揭示了这一范式所内蕴的伦理风险,并提出了一个技术、治理与设计三位一体的综合性规制路径,强调发展与治理必须同步演进。
5.2 未来展望
未来的研究可在以下几个方向深入:
- 跨学科融合:探索AI在支持STEAM等跨学科项目式学习中,如何构建统一的"数字镜像"并提供整合性支持。
- 具身化与沉浸式学习:在虚拟现实/元宇宙环境中,研究生成式AI如何作为"具身学伴",在三维交互空间中提供情境化、沉浸式的个性化指导。
- 终身学习AI学伴:构建伴随个人一生的AI学习伙伴,其"数字镜像"能够跨阶段、跨场景持续演进,为从基础教育到职业发展乃至老年教育的全生命周期学习提供支持。