0 前言
Transformer的系列已经来到了第四篇,在前面的三篇文章中介绍了词嵌入和位置编码、自注意力机制以及Add&Norm&FFN。再来回顾一下Add&Norm&FFN和内容:
-
Add在Transformer中指的残差连接,可以有效缓解梯度爆炸,通过快捷连接可以构建深层网络,训练更加稳定。
-
Norm在Transformer中是层归一化(Layer Norm),需要针对同一通道的数据进行计算,得到均值方差等,然后再进行归一化。注意与Batch Norm进行区分。
-
FFN本质上其实是两个全连接层连接,中间包含一个ReLu激活函数,以此增强网络的非线性。
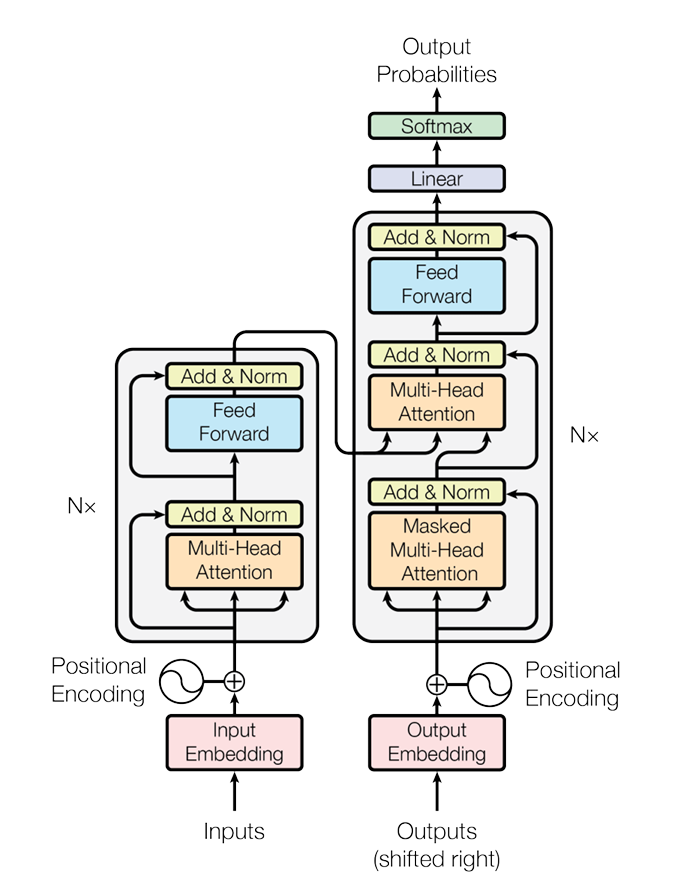
其实Transformer的关键点我们基本已经介绍的差不多了,解码器和编码器中有着非常多类似的内容,只不过应用起来略有区别。前面的内容都是基于Encoder来介绍的,今天就来看一下Decoder的结构是什么样的。
1 思维导图
掌握Transformer的解码器结构要着重关注它的输入、第一个注意力机制中的掩码操作、第二个注意力机制中的Q、K、V分别来自哪里,以及解码器的输出。
2 Decoder的输入
Transformer刚问世时,其实是为了解决翻译问题,因此我们通过翻译任务来介绍Transformer解码器的输入。
假设现在我们要翻译一句话,将I Love You翻译成我爱你,事实上我们在将I Love You输入至编码器之前,需要为它加上起始标记和终止标记,一般我们分别用 < s >和< /s >表示。也就是说我们的输入内容是:
\< s \> I Love You \< /s \>
那么解码器在训练的时候需要输入目标序列,也就是我爱你,也要加入起始标记和终止标记,那就是:
\< s \> 我 爱 你 \< /s \>
但是在实际训练中,我们需要将它整体右移一位,变成
\< s \> 我 爱 你
为什么这么操作呢?我们需要了解一下Transformer的训练过程:
-
1、Encoder输入\< s \> I Love You \< /s \>,Decoder输入\< s \>,Transformer输出我;
-
2、Encoder输入\< s \> I Love You \< /s \>,Decoder输入\< s \> 我,Transformer输出爱;
-
3、Encoder输入\< s \> I Love You \< /s \>,Decoder输入\< s \> 我 爱 ,Transformer输出你;
-
4、Encoder输入\< s \> I Love You \< /s \>,Decoder输入\< s \> 我 爱 你,Transformer输出< /s >;
所以大家理解为什么要右移一位挤掉< /s >了吧,相当于为了让Transformer学习到什么时候该停下来。
但是上面说的过程其实是不准确的,因为Decoder的输入其实不是一个个输进去,为了实现并行计算,而是将\< s \> 我 爱 你全都输入进去了。
但是训练的时候在翻译我为I的时候,肯定是不知道"我"后面要跟着"爱"这个字的,你把它整个输入进去,不就相当于提前告诉了Transformer目标序列么?这样训练效果肯定大打折扣。
所以Transformer中加入了掩码矩阵。也就是第一个注意力机制要学习的内容。
3 第一个注意力机制
这个注意力机制其实和之前的计算没有本质的不同,只不过加入了掩码矩阵。
3.1 举个例子
在上一节我们已经提到过,我们训练的时候,将整个目标序列都输入进了Transformer,但是为了防止Transformer偷看,我们要在第一个注意力机制中加入掩码。
举个例子,现在老师要教我们把I Love You,翻译成我爱你,他现在在黑板上写上了英文I Love You,也同时写上了我爱你。但是他提前都让你看到了答案肯定教学效果不好,他教学是这么一个步骤:
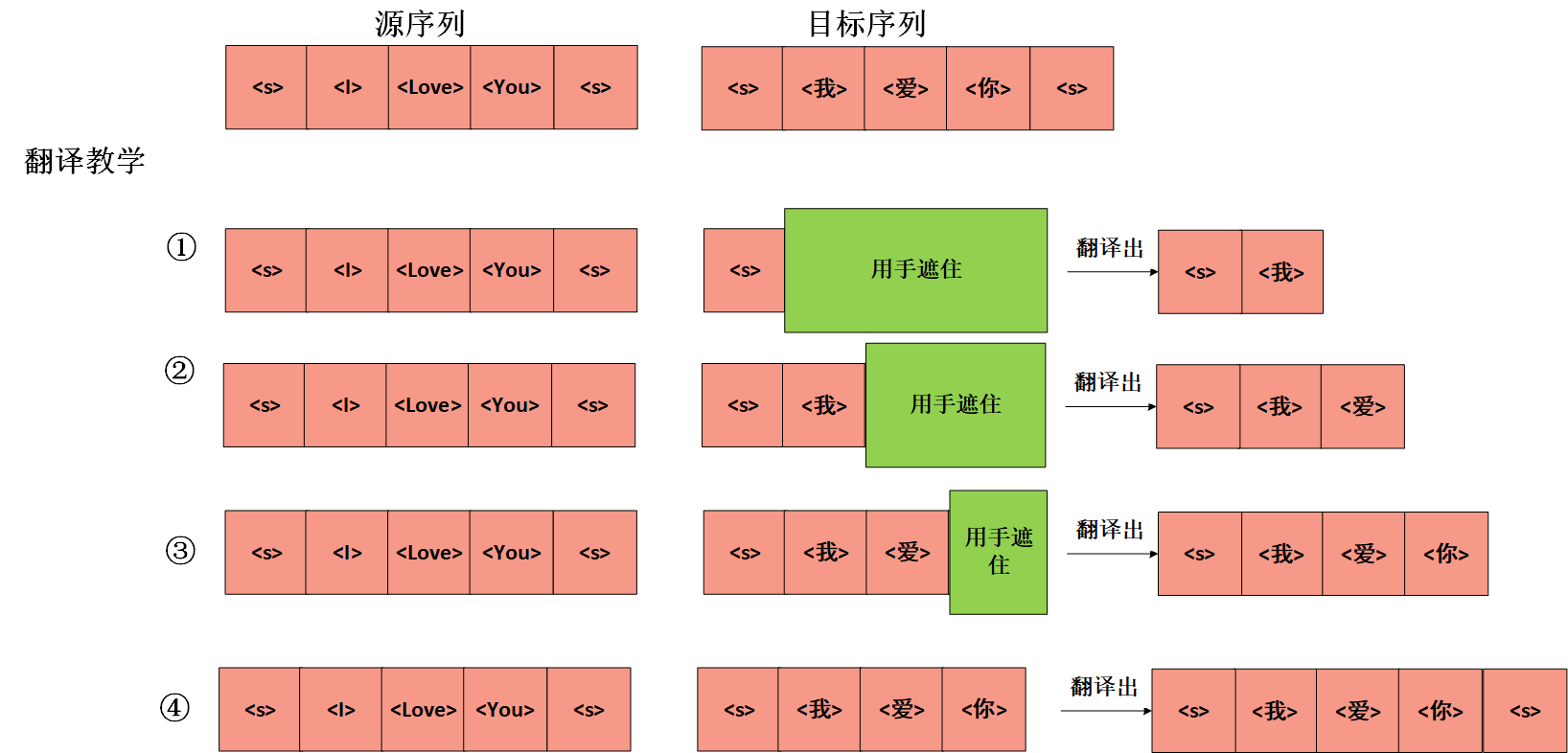
看见没,虽然他一次性把答案都写在了黑板上,但是为了让你学习效果好,他一开始用手遮住了你还没学习的内容,教你一步步学习,已经学习过的内容你是可以看的,但是还没学习过的内容,不准你看。
左边的输入就是Encoder的输入,右边的输入就是Decoder的输入,而"用手遮住"这个操作就是在第一个注意力机制中加入掩码矩阵完成的。
3.2 掩码矩阵
假设我们的输入是3×6矩阵,通过Wq、Wk、Wv得到QKV矩阵:
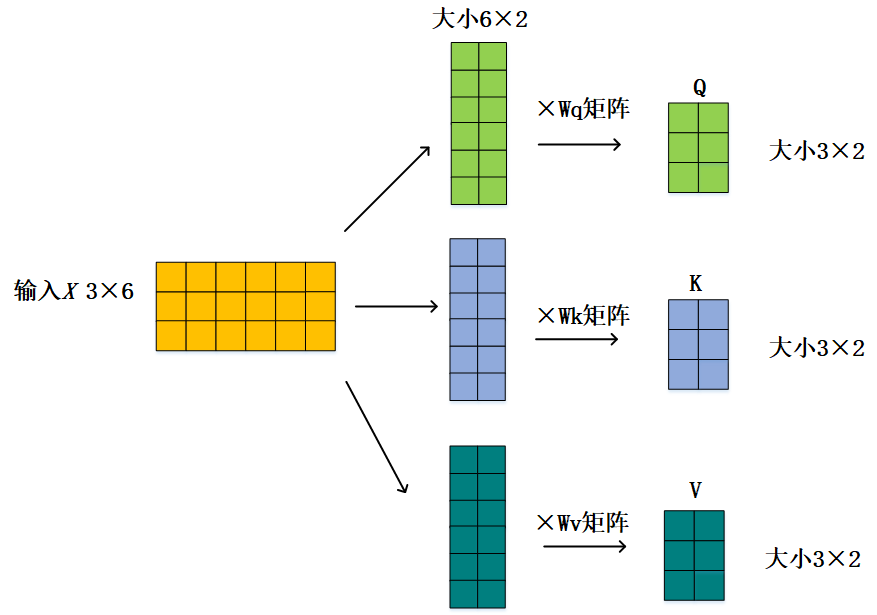
然后通过Q和K计算得到注意力分数矩阵Y:
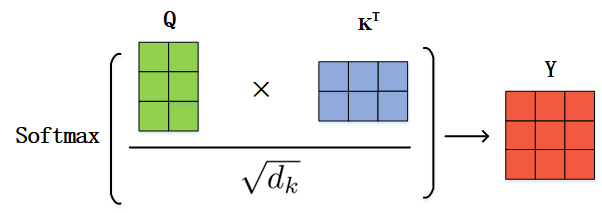
正常情况下我们直接通过Y矩阵和V相乘就得到了最终的输出Z:
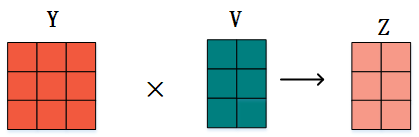
但是这样的话,Encoder的输入信息目标序列本来都体现在V中,现在这么相乘,Z矩阵岂不是包含了目标序列的全部信息?
这样在训练时,还没开始一个个翻译呢,就知道了答案,为了不让Decoder知道全部信息,又可以一次性将信息全部输入进去达到并行计算的目的,我们在注意力分数矩阵Y上面动了手脚,加入了掩码矩阵:
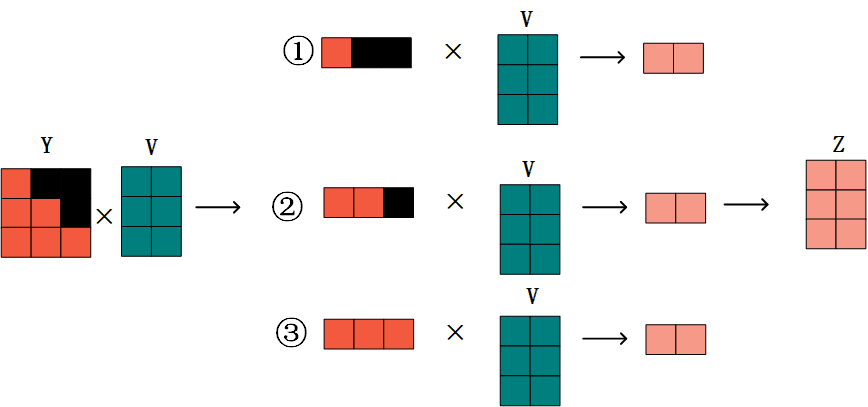
事实上就是在Y矩阵的上三角将其全部置零或者变成一个很小的数这种操作,这时候我们再来做矩阵乘法,我们可以发现:
-
第一步时,矩阵乘法的结果,不会包含V矩阵第二行第三行的信息;
-
第二步时,矩阵乘法的结果,不会包含V矩阵第三行的信息;
-
第三步时,矩阵乘法的结果,包含V矩阵所有的信息;
这种掩码的操作恰恰就实现了在进行下一步之前我们只能获取到前面的信息,但是不能获取到后面的信息,和刚才举的例子,老师用手蒙住是一个道理。这就是第一个注意力机制与之前的不同地方所在,我们再回过头看Decoder的图,就对掩码的操作很了解了。
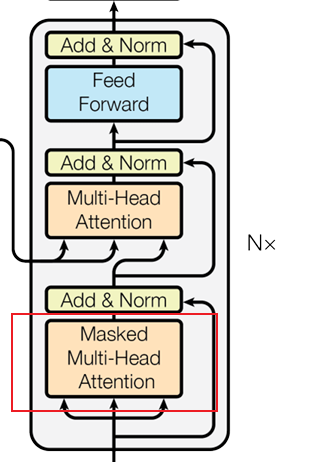
4 第二个注意力机制
其实第二个注意力机制就是下图的内容,可以发现箭头的来源不一样,有两个箭头来源于Encoder,有一个箭头来源于上一个掩码注意力再经过Add&Norm的输出,这也是第二个注意力机制和之前不一样的地方,它的QKV来源是不相同的,KV来自于Encoder。Q来自于Decoder,为什么要这样设计?
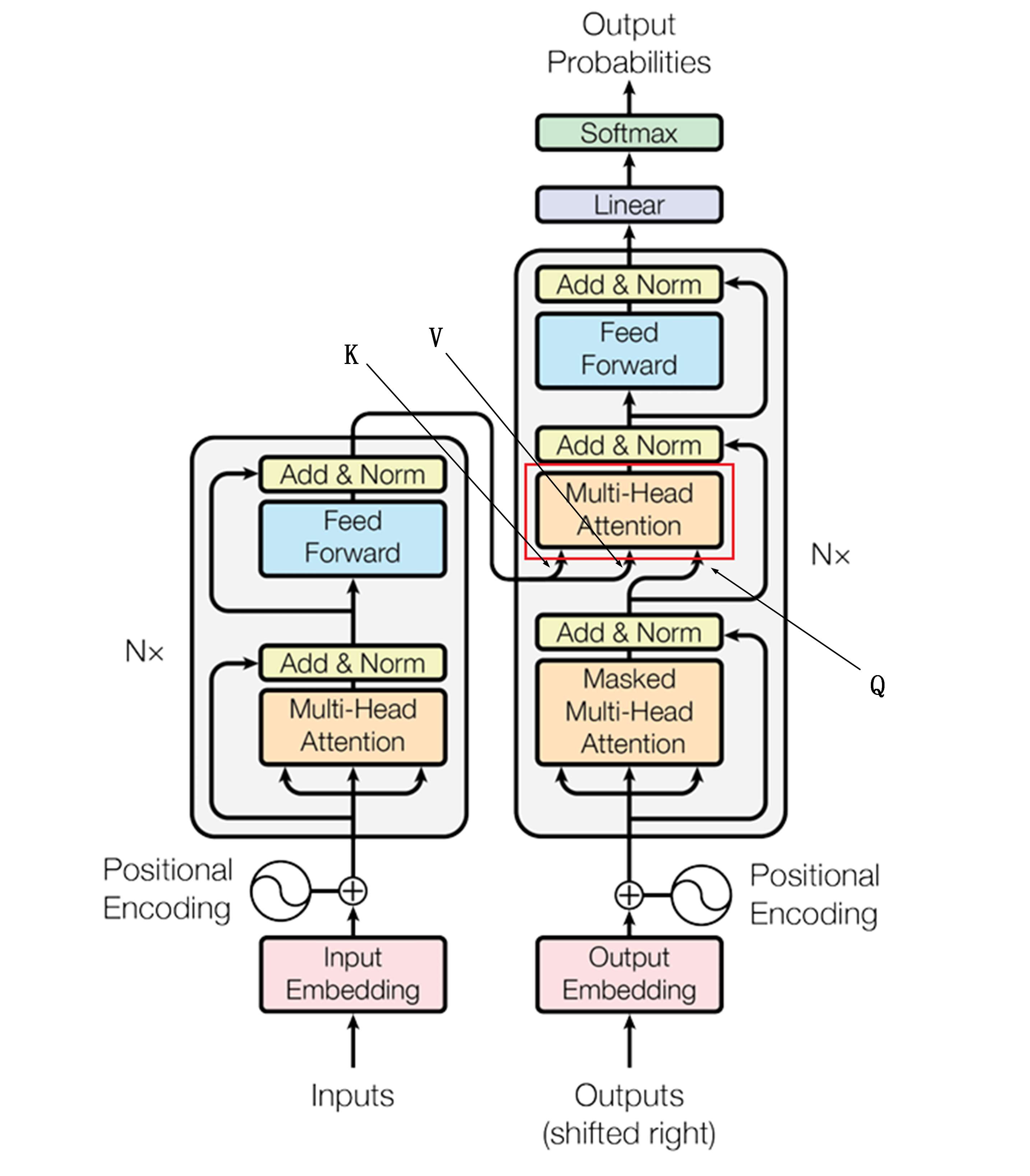
我们依然用翻译的任务来举例,来自于Encoder的信息K和V包含了"I Love You"的具体信息,它的标签(K)和内容(V),至于"I Love You"本身关注什么(Q),解码器不需要知道,解码器只知道自己关注什么。因此解码器带着疑问(Q),去和Encoder中的K、V在再做运算,以推理出自己该预测出什么词。
就像学生做题,有了具体的疑问(Decoder的Q),去查找书本的资料(Encoder的KV),再得到自己的答案。
再经过了第二个注意力机制后,再次通过残差连接和层归一化,最后经由Linear和softmax计算出具体的概率,一句概率去预测自己该得到什么结果。
5 Decoder的输出
我们再来详细说说解码器到底怎么得到最终的输出,回到我们的输入:
Encoder的输入:\< s \> I Love You \< /s \>
Decoder的输入:\< s \> 我 爱 你
训练的标签: 我 爱 你 \< /s \>
我们通过Encoder的输入和我Decoder的输入得到一组概率分布,然后找到概率最大的那个Index,再去真实标签里面去找,就可以得到我们的最佳输出。

当然这是训练的过程,但是在实际测试过程中,我们一开始可没有目标序列作为Decoder的输入,就像老师教完了你翻译,不会用手遮住正确答案,而是直接出题你做,因此测试的过程是这样的:

可以看出,测试时,我们Decoder的输入不再是整个序列,而是目前掌握的已知信息,你翻译多少,Decoder的输入就有多少,此时没有整个目标序列了,也就不再有什么Mask掩码操作。Decoder也和Encoder一样,由多个相同的模块堆叠而成,最后再连接全连接层,再加上softmax。
下一篇:对Transformer进行总结。
有疑问大家可以私信我,或者添加我:alongcode ,也欢迎大家关注我的gzh:阿龙AI日记。