视频生成中的多主体开放集个性化
paper title:Multi-subject Open-set Personalization in Video Generation
paper是Snap发表在CVPR 2025的工作
Code:链接
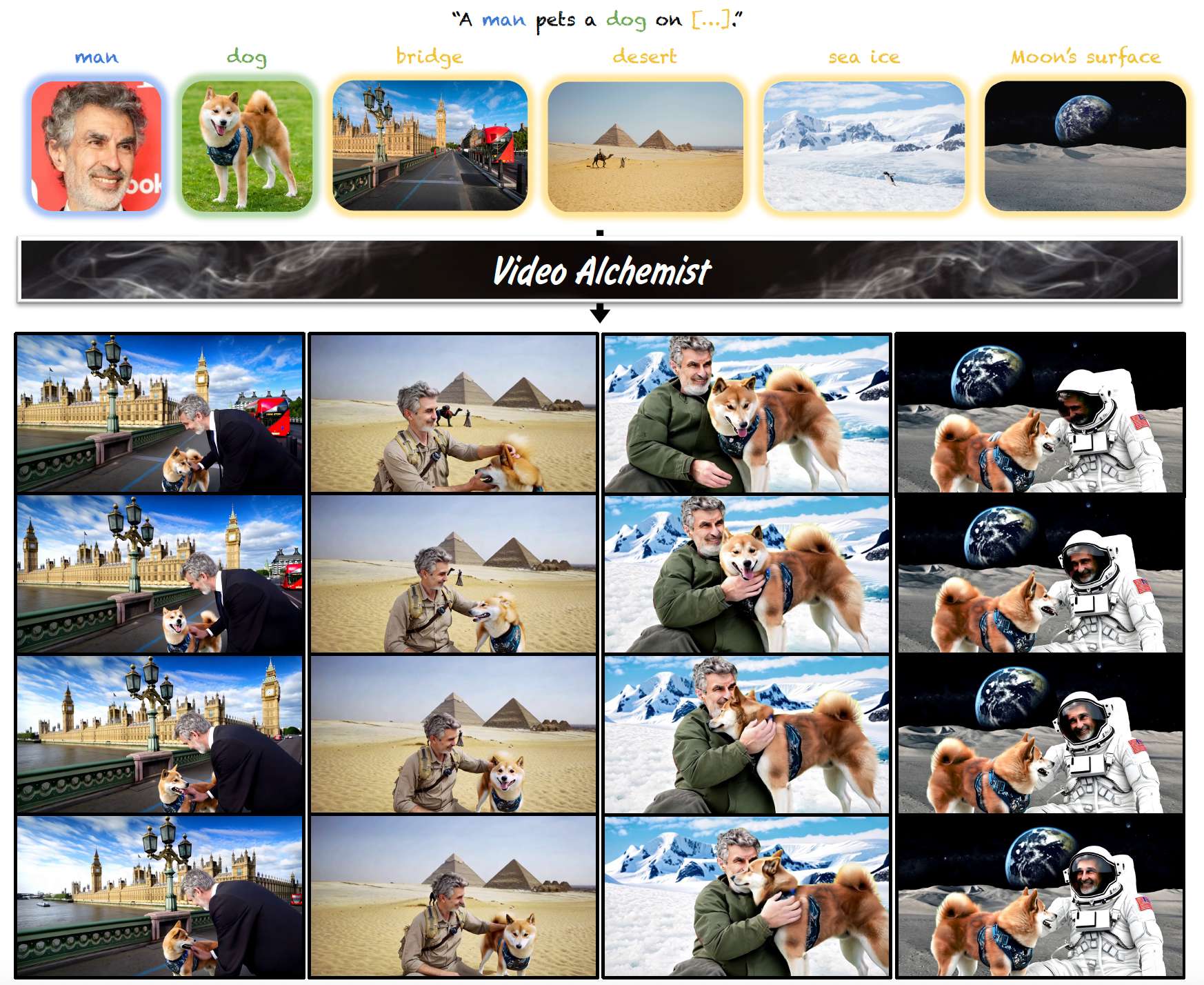
图1. 在给定文本提示以及每个主体的参考图像(例如,人、狗)和背景图像(例如,桥、沙漠、海冰、月球表面)的情况下,Video Alchemist 合成自然的动作,同时保持主体身份和背景逼真度。
Abstract
视频个性化方法允许我们合成包含特定概念(如人物、宠物和地点)的视频。然而,现有方法通常局限于有限的领域,需要对每个主体进行耗时的优化,或仅支持单一主体。我们提出了 Video Alchemist ------ 一种视频模型,具备内置的多主体、开放集个性化能力,既可用于前景物体,也可用于背景,从而消除了测试阶段耗时优化的需求。我们的模型基于一种新的 Diffusion Transformer 模块构建,该模块通过交叉注意力层将每个条件参考图像及其对应的主体级文本提示融合起来。开发如此大型模型面临两个主要挑战:数据集和评估。首先,由于参考图像和视频的成对数据集极难收集,我们从视频中采样选定帧作为参考图像,并合成目标视频的片段。然而,尽管模型在给定参考帧时可以轻松对训练视频去噪,但它们在泛化到新场景时往往失败。为缓解这一问题,我们设计了一条新的自动数据构建流程,结合了大量图像增强。其次,评估开放集视频个性化本身就是一个挑战。为此,我们提出了一个个性化基准,重点关注主体保真度的准确性,并支持多样化的个性化场景。最后,我们的大量实验表明,在定量和定性评估中,我们的方法显著优于现有的个性化方法。
1. Introduction
扩散模型 28, 63, 64 使我们能够从文本提示 4, 6, 29, 48, 62 合成具有自然运动的真实感视频。这种质量和逼真度为个性化铺平了道路------即在未见过的上下文或背景中生成包含特定物体和人物的视频。已有多种方法被提出用于生成包含特定人物或宠物的内容,但它们仍然局限于封闭集的对象类别。有些方法仅支持人脸 26, 45 或单一主体 32, 78, 80, 88,而另一些方法仅适用于前景对象 8, 9, 76。此外,许多方法还需要代价高昂的测试阶段优化 45, 78, 80。
在本文中,我们提出了 Video Alchemist ------ 一种具备广泛个性化能力的视频生成模型。我们的模型支持多个主体和开放集实体的定制,包括前景对象和背景。重要的是,我们的方法无需微调即可引入新概念。图1展示了两个主体在四种背景下的个性化视频。Video Alchemist 基于为个性化专门设计的新型 Diffusion Transformer 模块 53 构建。每个模块包含两个交叉注意力层:一个用于整合描述整个视频的文本提示,另一个用于引入每个参考图像的嵌入表示。为了实现多主体条件建模,我们采用了一种简单而有效的主体级融合方法,将每个主体的文字描述与其图像嵌入相结合。
但我们如何收集数据来训练模型呢?理想情况下,需要一个包含大量主体的视频和图像数据集,每个主体在不同的光照 、背景 和姿态 下被捕获。不幸的是,收集这样的开放集实体数据集在最佳情况下非常困难,而在最坏情况下几乎不可能。另一种方法是从同一个视频中提取参考图像和目标视频片段。然而,这种方法有一个显著的缺点------与身份无关的因素在不同视频帧之间仍然具有很高的相关性,从而导致我们称之为"复制-粘贴效应"。这一问题在基于重建的方法中很常见,例如 IP-Adapter 85,如图5所示。结果,模型难以合成在未见过的背景、光照和姿态下的多样化视频。为了缓解这种过拟合,我们设计了一条数据构建流程,能够自动从目标视频中提取对象分割,并构建针对个性化的专用数据增强,以确保模型关注参考图像的主体身份。实验表明,使用所提出的数据增强进行训练可以显著缓解复制-粘贴效应,如图6所示。
另一个挑战是缺乏合适的基准来评估多主体视频个性化。通常,我们通过计算生成视频与参考图像之间的相似度得分来评估视频个性化结果 32, 58, 85, 88。然而,这一指标并不适用于多个实体,因为它无法分别关注每个主体。为解决这些限制,我们引入了 MSRVTT-Personalization ------ 一种全面而健壮的个性化评估协议。该新基准支持在不同的条件模式下进行评估,包括基于人脸裁剪、单个或多个任意主体,以及前景对象与背景的组合。不同于图像级的相似性,我们在对象分割级别评估主体保真度。实验结果表明,在定量和定性评估方面,Video Alchemist 都优于现有的个性化方法。此外,我们还进行了广泛的消融研究,以验证所提出组件的有效性。
我们的贡献总结如下:
- 我们提出了 Video Alchemist,这是一种新的视频生成模型,支持前景对象和背景的多主体开放集个性化。
- 我们精心构建了一个大规模训练数据集,并引入了训练技术以减少模型过拟合。
- 我们提出了 MSRVTT-Personalization,这是一种新的视频个性化基准,提供多种条件模式,并能够准确测量主体保真度。
2. Related Work
扩散视频模型。扩散模型 28, 29, 56, 63, 64 已经在生成真实感图像方面展示了令人印象深刻的能力。在这一成功的基础上,近期研究探索了其在文本条件视频合成中的应用 4, 6, 22, 23, 44, 46, 48, 60, 62, 84, 87。ImagenVideo 60 和 Make-A-Video 62 使用级联的时间和空间上采样器进行视频生成。VideoLDM 4 微调预训练的潜在图像生成器和解码器,以生成时间一致的视频。与之前基于 U-Net 57 架构的模型不同,SnapVideo 48 采用 FiT 10 并扩展到十亿参数规模的模型。更近期的 Sora 6 采用 Diffusion Transformer 53,实现了高分辨率、长时长的视频合成。尽管这些研究已经取得了显著进展,但仅依赖文本提示会将生成内容限制在语言能够描述的范围之内。
个性化图像生成。该任务旨在使用少量输入图像,将生成模型定制为新的概念和主体 2, 19, 24, 25, 33, 36, 51, 58, 61, 68, 73, 75, 85。例如,DreamBooth 58 为每个主体优化整个文本到图像模型,而 Textual Inversion 19 为每个主体学习一个文本嵌入,并利用该嵌入生成新颖图像。Custom Diffusion 36 学习组合多个概念,每个概念由文本嵌入和交叉注意力权重表示。然而,这些基于优化的模型需要为每个新概念进行权重微调或嵌入优化,这不可避免地速度较慢且容易过拟合。
近期研究探索了基于编码器的方法,以减少测试阶段的微调需求 1, 14, 20, 37, 59, 61, 71, 77, 82, 85。IP-Adapter 85 学习了一种轻量化的解耦交叉注意力机制用于图像条件建模。Instance-Booth 61 训练一个图像编码器,将参考图像转换为文本标记,并引入适配器层以保留身份细节。我们的模型同样使用编码器,但我们专注于多主体的视频个性化。
个性化视频生成。已有多项工作将模型个性化技术扩展到视频 12, 18, 26, 32, 42, 45, 47, 76, 78, 80, 86, 88。DreamVideo 78 使用一种基于优化的策略,训练图像适配器以捕捉主体的外观,并训练运动适配器以建模动态。相比之下,StoryDiffusion 88 采用一种无优化的方法,利用一致的自注意力机制和语义运动预测器,确保平滑过渡和一致的主体。
然而,大多数现有方法都集中在有限的领域。有些方法仅限于人脸个性化 26, 45 或特定类别的单一主体 32, 78, 80, 86, 88,而另一些方法则仅关注前景对象 8, 9, 76。与之相对,我们提出了一种视频模型,支持跨前景对象和背景的多主体开放集实体的定制。与我们的工作密切相关的 VideoDrafter 42 在两个阶段实现开放集视频个性化:文本到图像个性化以及首帧动画。相比之下,我们的端到端方法缓解了长视频合成中的主体一致性差这一显著局限,这是首帧动画方法常见的问题。
3. Methodology
我们的目标是学习一个生成式视频模型,该模型以文本提示和一组代表提示中每个实体词的图像为条件。
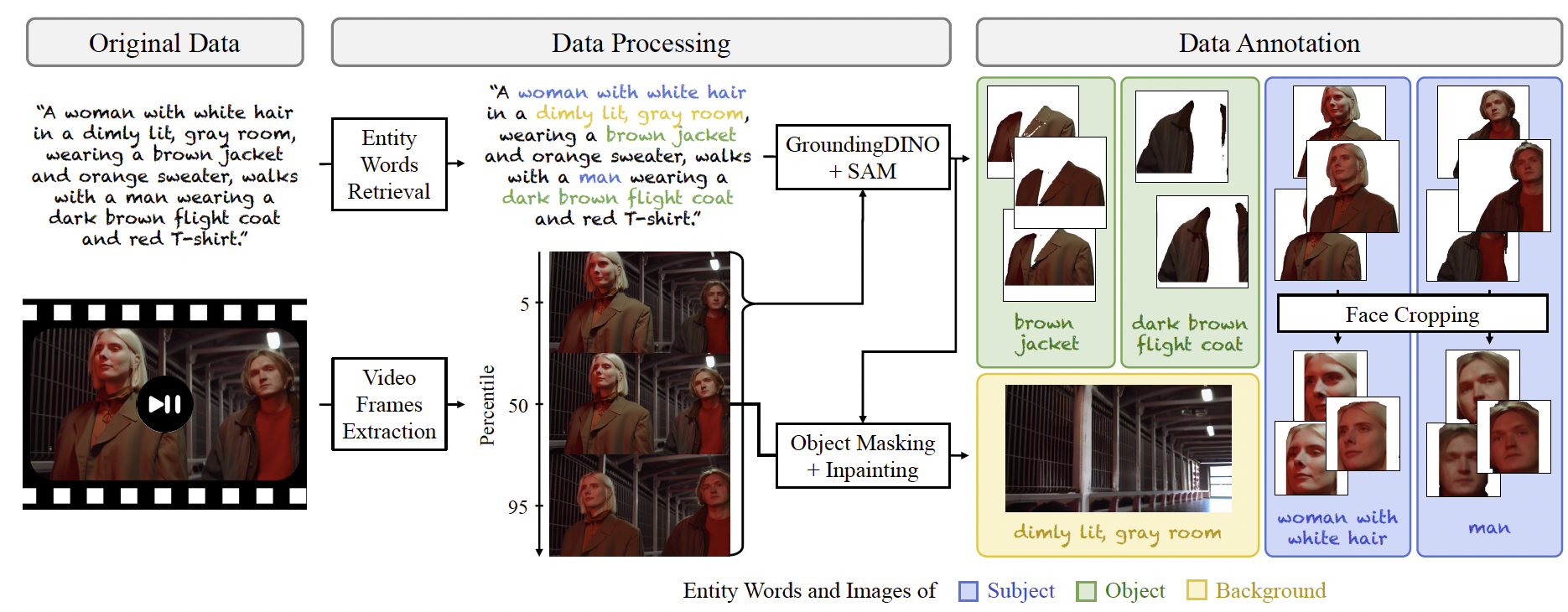
图2. 用于视频个性化的数据集收集流程。我们通过视频与字幕对构建训练数据集,流程分为三步。首先,从字幕中识别三类实体词:主体、物体和背景。接着,利用这些实体词在三帧选定的视频帧中定位并分割目标主体和物体。最后,通过去除中间帧中的主体和物体来提取一个干净的背景图像。
3.1. Dataset Collection
如图2所示,我们通过三个步骤来构建数据集。
提取实体词。为了实现多主体个性化,我们使用大型语言模型 31 从单个字幕中提取多个实体词。具体来说,我们将实体词分为三类:主体(例如,人类、动物)、物体(例如,汽车、夹克)和背景(例如,房间、海滩)。主体和物体应当在视频中清晰可见。接着,我们采用若干标准来过滤并提升训练数据集的质量。例如,我们排除任何主体实体词为复数形式的视频(如"一群人"、"几只狗"),以避免个性化中的歧义。另一个例子是,我们去除没有主体实体词的视频,因为这类视频的动态往往由无意义的镜头移动主导。更多细节见附录 A.2。
准备主体图像。接下来,我们从视频的开头、中间和结尾选择三帧(即位于 5%、50% 和 95% 百分位的位置)。这样做的动机是捕捉目标主体或物体在不同姿态和光照条件下的表现。随后,我们对每一帧应用 GroundingDINO 40 来检测边界框。这些边界框接着由 SAM 35 用于分割对应实体的掩码区域。此外,对于描绘人类的参考图像,我们应用人脸检测 74 提取人脸裁剪。
准备背景图像。最后,我们通过去除主体和物体来创建一个干净的背景图像。由于 SAM 35 偶尔会产生不精确的边界,我们在应用修复算法 56 之前对前景掩码进行膨胀处理。我们使用背景实体词作为正向提示,并使用 "任何人或任何物体、复杂图案和纹理" 作为负向提示。为了保证背景一致性,我们仅使用每个视频序列的中间帧。
3.2. Video Personalization Model
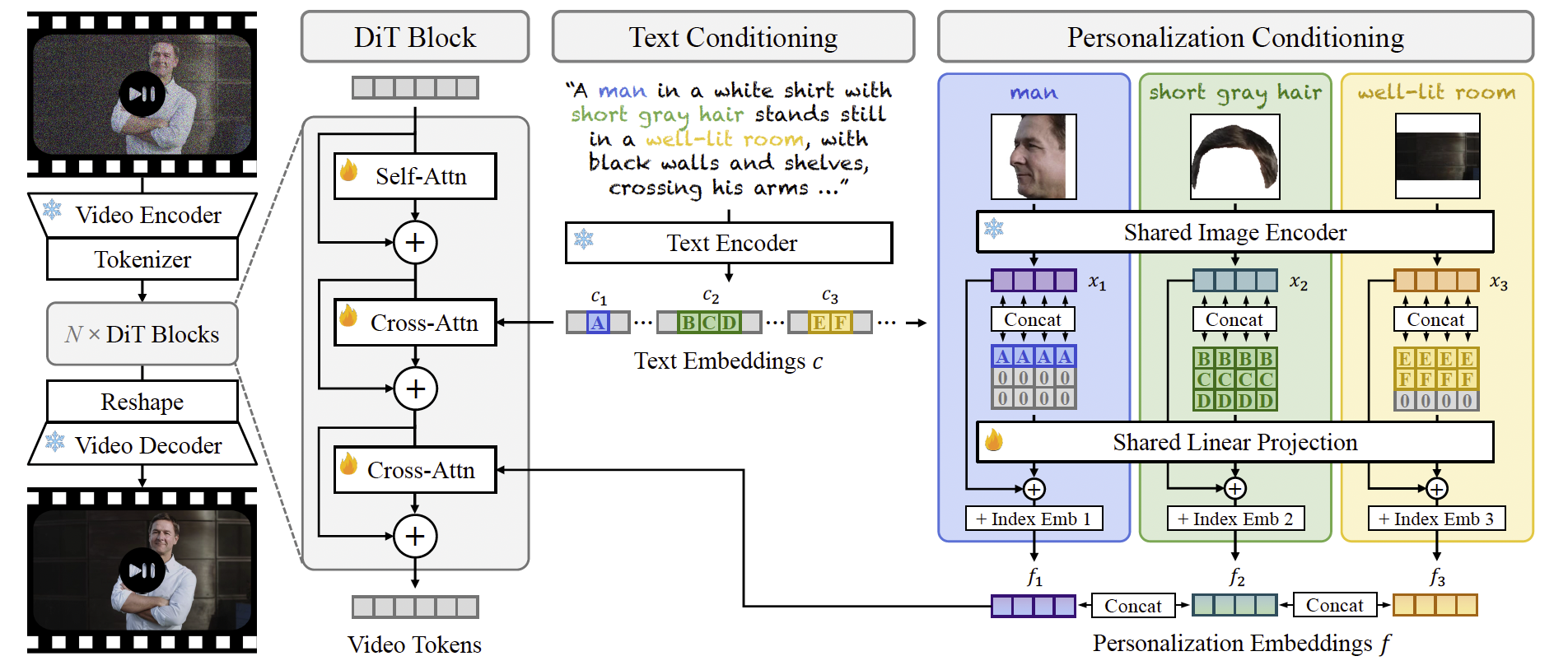
图3. 模型架构。我们的模型是一个潜在 DiT 53,其中我们首先将视频编码为视频 token,并在潜在空间中通过深层级联的 DiT 模块对其进行去噪。每个 DiT 模块都包含一个额外的交叉注意力操作,与个性化嵌入 f = Concat ( f 1 , ... , f n , ... , f N ) f = \text{Concat}(f_1, \ldots, f_n, \ldots, f_N) f=Concat(f1,...,fn,...,fN) 结合,其中 f n f_n fn 融合了参考图像 x n x_n xn 与对应实体词 c n c_n cn 的嵌入。图中的每个方块代表一个一维 token。
我们通过在文本提示、参考图像及其对应实体词作为条件下,对视频进行去噪来学习 Video Alchemist。
视频生成骨干网络。如图3所示,我们的模型是一个潜在扩散 Transformer (DiT) 53。首先,我们使用自编码器 84 将视频压缩为潜在表示,并通过分词器 34 将其编码为一维视频 token 序列。接着,我们加入高斯噪声以获得带噪样本,并根据 rectified flow 公式 39, 41 学习去噪网络。我们的网络是由多个 DiT 块组成的深层级联结构。与普通 DiT 设计不同,我们的模块支持内置个性化能力,通过结合来自文本和图像条件的信息来实现。我们的 DiT 块包含三层:一层多头自注意力 72,以及分别用于文本和个性化条件的两层多头交叉注意力。我们在自注意力中使用 RoPE 66 位置嵌入,因为它在视频 token 数量变化时依然有效,并使用 self-conditioning 11 来提升视觉质量。我们还采用 flash attention 15 和融合层归一化 49 来加速模型训练和推理。
图像与词语概念的绑定。对于多主体个性化,模型可以在不同主体条件下工作,每个主体由一个或多个参考图像表示。因此,提供文本 token 与图像 token 之间的绑定关系至关重要。如图6第二行所示,如果缺少这种绑定信息,模型往往会将图像条件应用到错误的主体上,例如把参考的人脸放到狗的身上。
我们通过个性化嵌入的形式提供绑定 f = Concat ( f 1 , ... , f n , ... , f N ) f = \text{Concat}(f_1, \ldots, f_n, \ldots, f_N) f=Concat(f1,...,fn,...,fN),其中 f n f_n fn 编码了参考图像和对应实体词的信息。这里, N N N 是参考图像的数量。具体来说,为了生成嵌入 f n f_n fn,我们首先将图像编码为图像 token x n ∈ R l × d x_n \in \mathbb{R}^{l \times d} xn∈Rl×d,使用一个共享的、冻结的图像编码器 50。其中, l l l 表示每个参考图像的 token 数量, d d d 表示每个 token 的维度。
接下来,我们从文本嵌入 c c c(由文本编码)中提取词 token c n c_n cn,并将 c n c_n cn 展平为一维嵌入。由于一个实体词的 token 数量可能不同,我们对词嵌入进行零填充或截断,以保持一致的长度。为了绑定图像和词 token,我们将展平后的词 token 复制 l l l 次,并在通道维度上与图像 token 连接。最后,我们将其传递给一个线性投影模块,应用与图像 token x n x_n xn 的残差连接,并添加一个可学习的图像索引嵌入,以区分来自不同图像的 token。来自同一图像的不同 token 将共享相同的图像索引嵌入。
个性化条件建模。个性化嵌入 f f f 随后用于计算与视频 token 的交叉注意力。虽然 IP-Adapter 85 使用单个解耦交叉注意力层同时处理文本和图像条件,但我们通过实验证明,在我们的场景中使用独立的交叉注意力层效果更佳。这可能是因为我们的多图像条件引入了更长的图像 token 序列。因此,如果在一个共享层中混合文本和图像 token,图像 token 会占主导,从而削弱与文本提示的对齐。
我们将模型训练分为两个阶段。在第一阶段,我们仅使用一个交叉注意力层进行文本条件训练。接着,我们引入额外的交叉注意力层用于个性化条件建模,并对整个模型进行微调和预热。模型训练的详细内容见附录 B。
3.3. Reducing Model Overfitting
我们通过使用选定和分割的帧作为条件,对训练视频进行去噪来学习 Video Alchemist。然而,这种方法往往导致过拟合,即模型更倾向于学习参考主体(ref)的光照、姿态、遮挡以及相机视角,而不是其身份。具体来说,我们发现:
• 如果 ref 是高分辨率的,模型会生成一个靠近相机的大型主体。
• 如果 ref 被遮挡,模型会生成遮挡目标主体的其他物体。
• 如果 ref 被裁剪,模型会将主体放置在边缘,导致其被视频边界裁剪。
• 模型经常复制 ref 中主体的姿态和光照条件。
• 如果多个 ref 表示相同主体但姿态相似,模型会生成一个几乎没有动作的主体。
这种过拟合通常会导致复制-粘贴效应,即模型直接将参考图像复制到视频中,而没有引入姿态和光照的变化。这一现象在基于重建的方法中很常见,例如 IP-Adapter 85,如图5所示。
为缓解这些问题,我们对参考图像应用数据增强。具体来说,我们使用下采样和高斯模糊来防止对图像分辨率的过拟合,使用颜色抖动和亮度调整来减轻对光照条件的过拟合,并使用随机水平翻转、图像剪切和旋转来削弱对主体姿态的过拟合。核心思想是引导模型关注主体的身份,而不是学习来自参考图像的无意信息泄漏。关于所提出图像增强的更多细节见附录 A.3。
4. Experiments
第4.1节介绍了 MSRVTT-Personalization,这是一个全面的个性化基准。第4.2节给出了与最新方法的定量和定性对比。第4.3节讨论了我们在模型训练和架构设计上的消融研究。附录A包含训练数据集和数据增强的细节。附录B包含模型架构、训练和推理的细节。最后,我们在附录C中展示了更多生成样例。
4.1. MSRVTT-Personalization Benchmark
现有方法 58, 78, 85, 88 使用参考图像与生成图像或视频之间的图像相似性 16, 50, 55 来评估主体保持。然而,这些指标在多主体情况下无效,因为图像级相似性无法聚焦于目标主体。为解决这一问题,我们引入 MSRVTT-Personalization,以提供更全面和准确的个性化任务评估。它支持多种条件场景,包括基于人脸裁剪、单个或多个主体,以及前景对象与背景的条件建模。
我们基于 MSRVTT 83 构建测试基准,并通过三个步骤处理数据集。首先,我们使用镜头边界检测算法 TransNetV2 65 将长视频分割为多个片段,并应用内部字幕生成算法为每个片段生成详细字幕。接着,我们按照第3.1节中的流程为每个视频-字幕对生成标注。最后,为保证数据质量,我们手动筛选符合以下标准的样本:
• 视频不是没有有意义主体运动的动画静帧。
• 视频不包含大量文字覆盖。
• 检索到的主体和物体覆盖视频中的所有主要主体和物体。
• 通过修复算法生成的背景图像成功移除了前景物体,且未生成新的物体。
为增加数据多样性,我们从每个长视频中选取一个片段,共收集了 2,130 个片段。图4展示了一个带标注的测试样本。
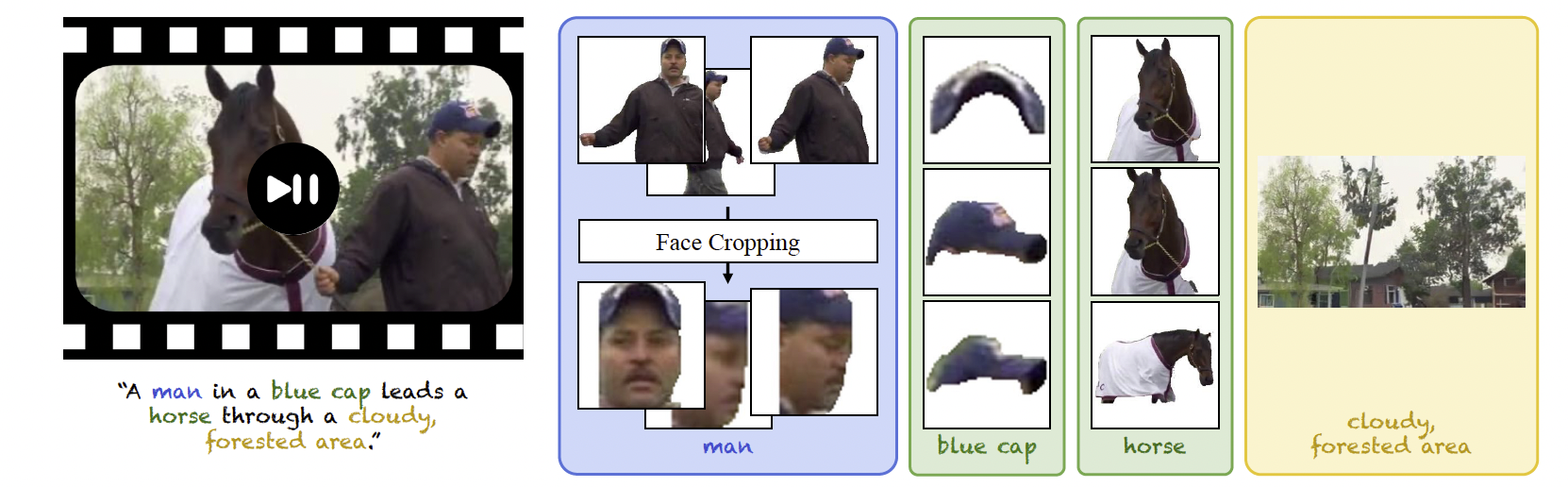
图4. MSRVTT-Personalization 中的测试样本。我们提出了一个全面的视频个性化基准。该基准支持多种模式,包括基于人脸的条件建模、单个或多个主体的条件建模,以及前景与背景的条件建模。
评估指标。一个理想的个性化视频输出应当与文本对齐,保持主体保真度,并展现自然的视频动态。因此,我们使用以下五个指标:
• 文本相似度 79:生成帧与文本的 CLIP ViT-L/14 55 特征之间的余弦相似度。用于衡量生成视频与文本提示的一致性。
• 视频相似度 19:生成帧与真实帧的 CLIP ViT-L/14 特征之间的平均余弦相似度。
• 主体相似度:参考图像与生成帧中分割出的主体之间的 DINO ViT-B/16 7 特征平均余弦相似度。我们使用 Grounding-DINO Swin-T 40 和 SAM ViT-B/16 35 来分割主体。
• 人脸相似度:参考人脸裁剪与生成的人脸裁剪之间的 ArcFace R100 16 特征平均余弦相似度。我们使用 YOLOv9-C 74 检测生成帧中的人脸。
• 动态程度 30:生成视频连续帧之间的光流幅值。我们使用 RAFT 67 计算光流。