生产环境的线程池参数该如何确定呢?(本篇带有自己的思考,所以可能有误,仅供参考,网上没有找到标准答案)
我的第一反应是套公式:

问题: 但是生产环境不止我的任务这个一个线程池在跑,会不会对其他业务的线程池造成影响呢?或者别的业务对我这个线程池造成影响呢?
解决方案:Springboot+Prometheus(时序序列数据库)+Micrometer+Grafana
下图是各个组件在整套方案的作用和角色:
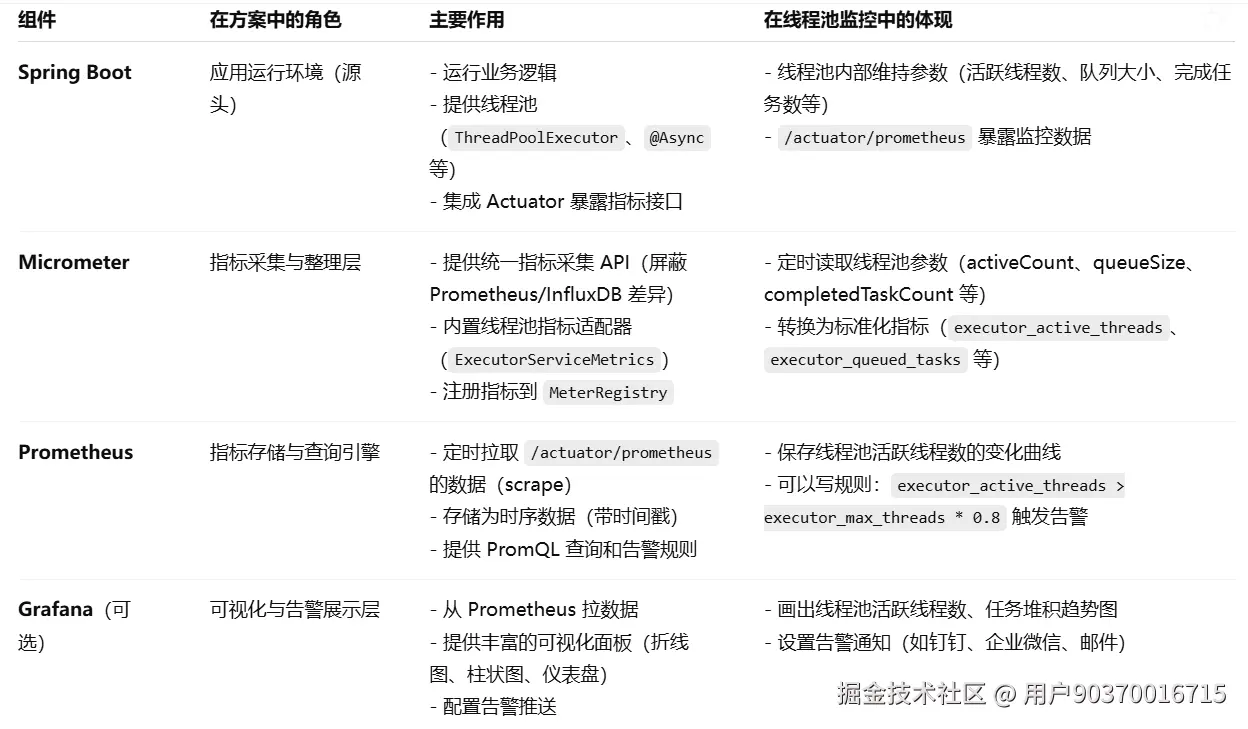
解释:Micrometer负责收集线程池的参数数据信息,将数据存储进Prometheus数据库,Prometheus是一个时序序列数据库,简单来说就是存储随时间变化的数据,Grafana是展示时序序列数据的可视化工具。用于具体观察线程池的参数状态。
具体观察哪些指标呢?如下图:
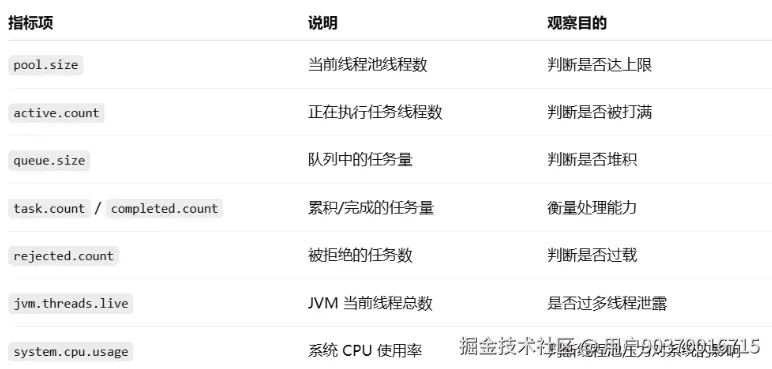
最后给出在观察时的具体场景和解决方案:
场景1:线程池任务被大量拒绝,日志中大量抛出RejectedExecutionException,Prometheus中rejected.count数指标飙升
解决方案: 增加maxPoolSize、queueCapacity、使用限流机制。
场景2:线程池活跃线程数长期=最大线程数
原因:1. 任务执行时间太长。 2. 峰值QPS太高。
解决方案:1.代码优化,降低任务执行时间。2.单个任务拆分,分布式执行。3.使用中间件削峰、限流。
场景3:线程池队列持续增加不降,queue.size不断上升且不下降
原因:处理速度<处理任务速度
解决方案:1.采用快失败策略+降级策略,快速响应,然后进行选择性重试。
2.扩容副本、打散并发,将让任务分散到各个不同的服务节点上执行。
3.在线程池之上加一层消息队列进行缓冲
场景4:线程数异常多、内存占用过高、频繁GC
现象:jvm.threads.live>1000。且持续上涨。
解决方案:1.限制maxpoolSize
场景5:上下文切换频繁、系统吞吐量降低
现象:CPU利用率高,但是业务反应慢。
解决方案:1.降低maxPoolSize(尤其非核心线程数)2. 更换队列。
最后给出生产环境线程池常见问题解决方案:

针对不同的场景,还需要使用不同的队列,这个下一篇整理。