Zookeeper
概述
Zookeeper可以监视HDFS系统的name node和data node,HBase也极度依赖zookeeper,因为zookeeper维护了HBase的源数据以及监控所有region server的健康状态,如果region server宕机会通知master 。它也可以避免脑裂(只有一个master大脑)。啊不免,通过分布式锁实现数据的一致性,YARN资源管理也依赖zookeeper,它为YARNresource manager提供节点选举服务。他还管理进入的消息队列。
总的来说,它可以实现任意节点更改,每个节点生效;以及通过分布式锁实现数据的一致性;避免脑裂,保证只出现一个HBase master;并且它保存了HBase的源数据,我要查询zookeeper就能知道当前哪些HBase的region server是活着的;通过watch机制监听zookeeper上某个数据节点的变化,当被监听的节点有变化时,它会主动推送通知给所有监听的客户端。
正是因为zookeeper如此强大,才能构建起如此稳定高效的分布式数据处理平台
特征:
保证系统一致性--为客户展示统一视图
可靠性--如果消息被所有服务器接受,会被所有服务器接受
实时性--a机子写入不会立刻在b展示出来
等待无关--执行快的不等慢的
原子性--成功或失败,没有中间状态
顺序性--
每个节点都装zookeeper,每个节点都有server,运行一个quorumpeermain,每次启动选择一个server作为leader(节点是单数以应用选举机制)。
Zookeeper角色
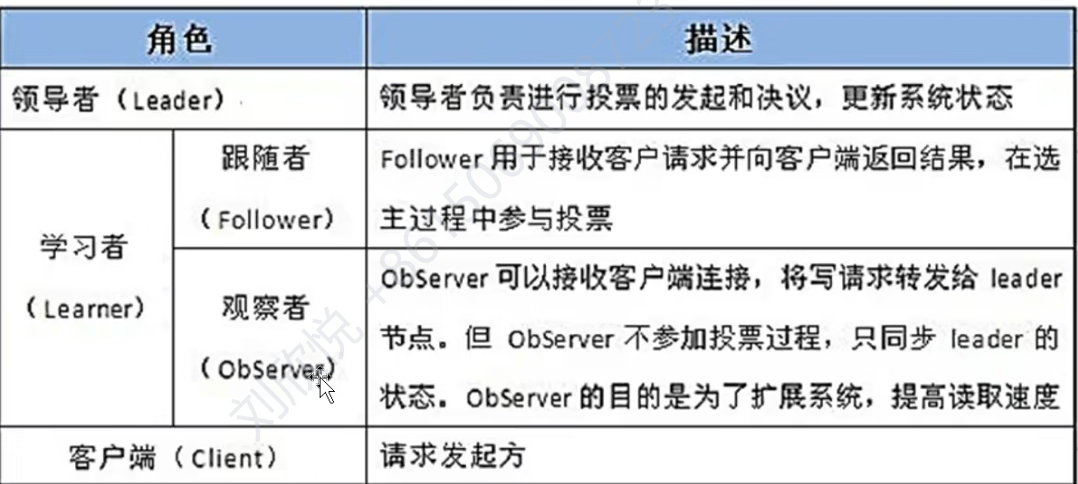
扩展时增加server,投票延迟大,影响性能,所以增加了observer。
应用场景:
在任何节点修改配置文件,其他节点会同步
心跳检测,namenode需要知道datanode状态,jobtracker需要知道tasktracker的状态
HBase--nosql数据库(not only sql)
表的特点:
大
列可以动态增加
面向列存储和管理
空列不占用空间,设计可以稀疏
每个单元数据可以有多个版本
数据类型都是字符串
行存储和列存储的对比
传统的关系型数据库是按行存储,比如mysql、oracle, 它的特点就是把一整行的数据放在一起,它在物理上是相邻的。这非常有利于需要频繁的增删、改查和读取整行数据的操作,比如你要查询一个用户的所有信息。那么你就只需要找到这一行的位置,效率很高。
想象一下你的表有100列,但是呢,你只需要查询所有人的年龄,这一列如果是按行存储,你必须要把每一行的所有的100列数据都从磁盘读出来,然后从中提取出年龄的列,这产生了非常大的I/O浪费,速度非常慢,但是列存储的话可以直接定位到年龄,这一列所在的物理存储块,跳过了其他99列不相关的数据,I/O效率很高
并且同一列的数据,它一般有相同的呃,这个数据类型呃,所以你对这一列保存的时候可以压缩,这样就节省了那个磁盘占用的空间。并且HBase它的数据是按列族存储的,可以在运行的时候动态的添加新的列,这样你就不用像关系型数据库那样执行alter table的命令。
逻辑存储
column family:列族
column:列
单元格:由 {RowKey, Column Family:Column Qualifier, Timestamp}唯一确定的存储单元,里面存储着具体的值(Value)
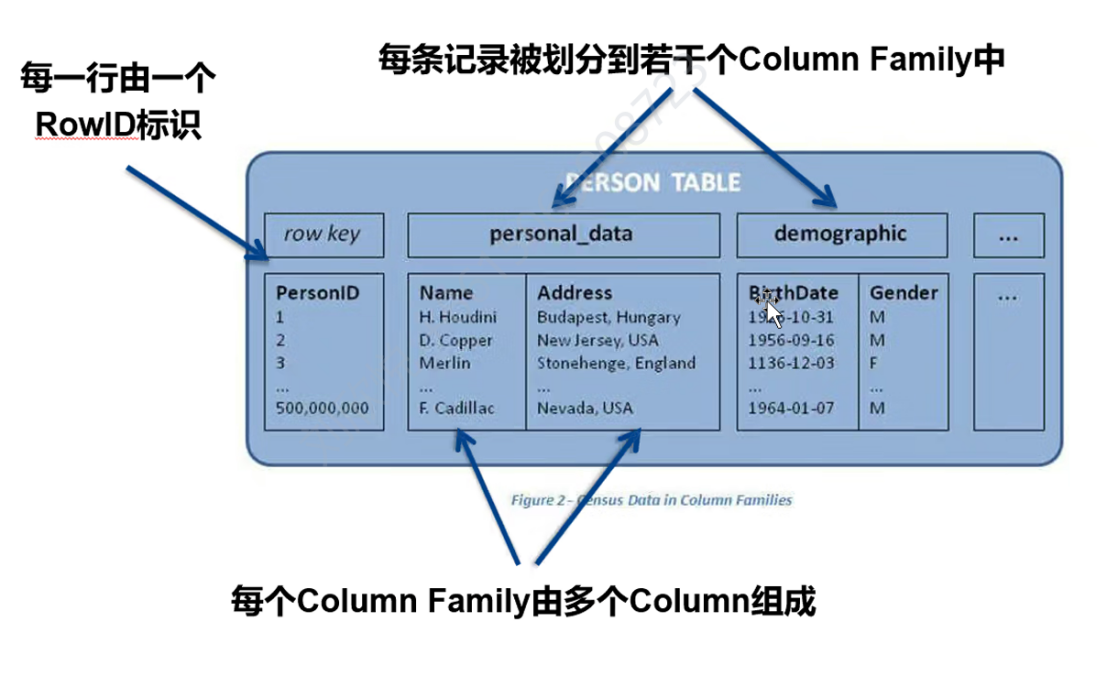
物理存储
横向切分不同的region,region太大会自动分裂,region是HBase的基本单位。
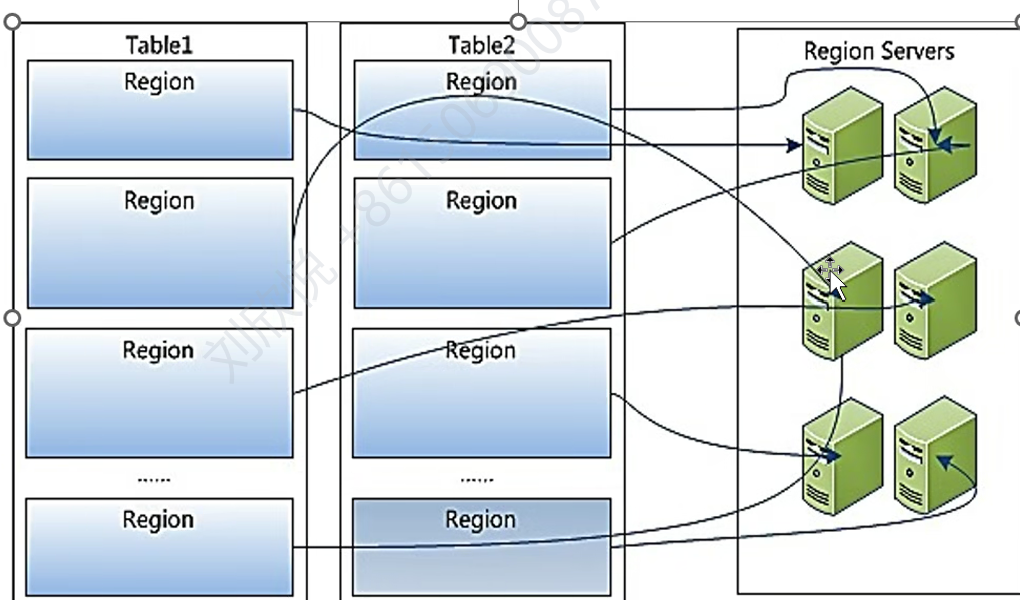
一个region被纵向切分成store,一个列族对应一个store。store中的memstore表是数据结构,通常是跳表,Hfile是实际存储文件。
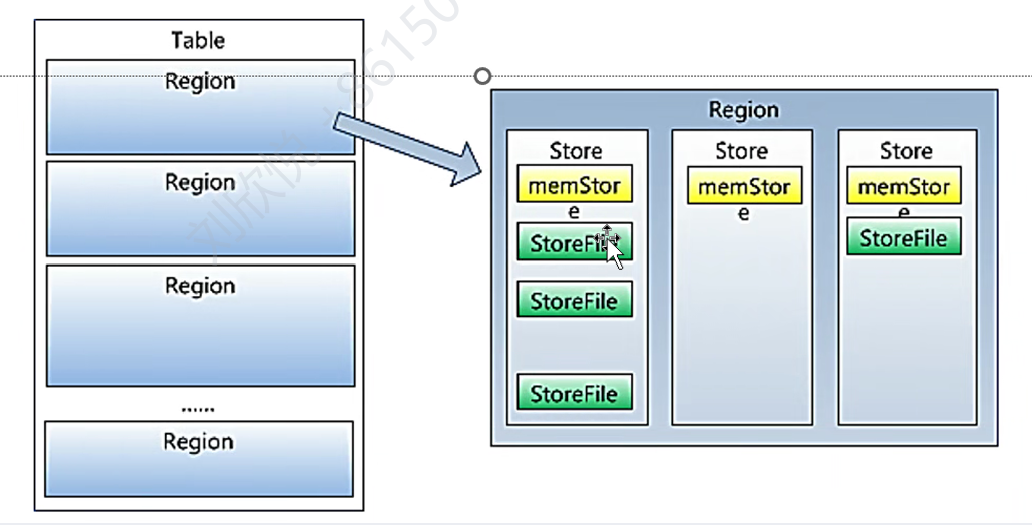
HBase架构
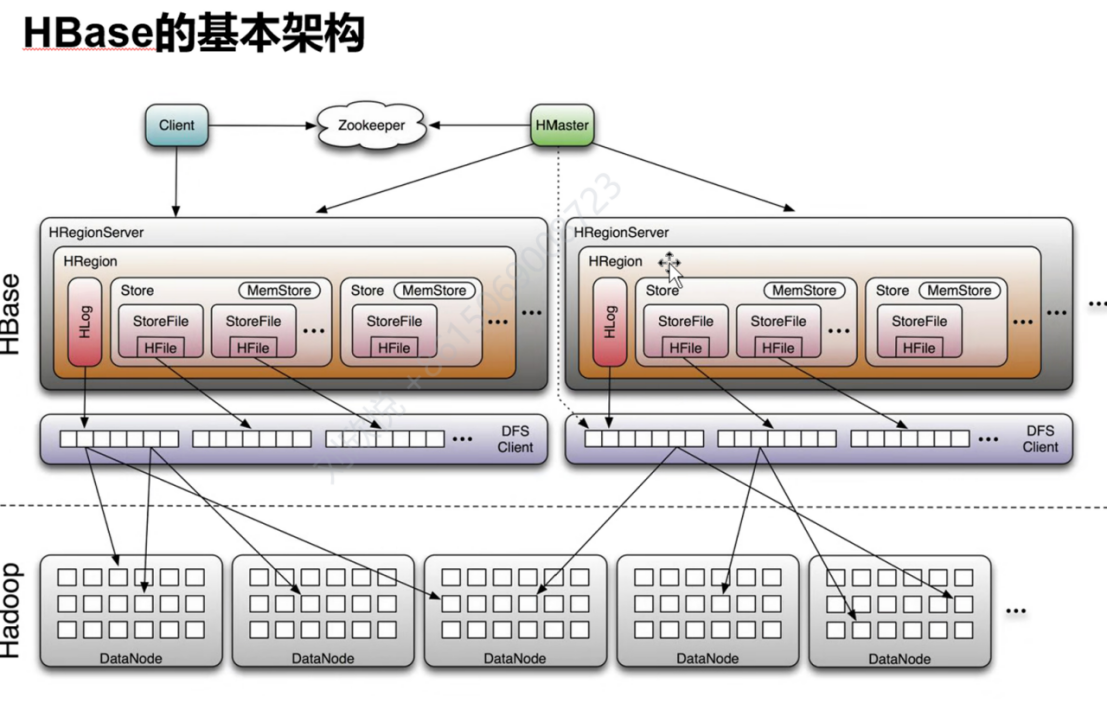
四个基本组件:
Client:访问HBase
Zookeeper:master和regionserver启动时会向zookeeper注册。保证只有一个master(防止脑裂),监控region server的心跳并实时通知master,存储region的寻址入口(实现了随机存取),存储HBase的元数据。
Master:给region server分配region,负责负载均衡。监听region server 的心跳。
region server:处理客户端的读写请求
zookeeper保证容错性:
Master崩溃,zookeeper重新选一个master,region server崩溃,zookeeper能监听到,然后master重新分配任务。
适用场景
如果你需要处理海量数据 、需要高可扩展性 、并且数据模型相对简单 (不需要复杂的JOIN操作和事务),那么HBase是一个非常好的选择。如果你需要处理复杂的关系、需要严格的ACID(原子性、一致性、隔离性、持久性)事务和强大的SQL查询能力 ,那么关系型数据库仍然是首选。
随机存取、大数据下高读写,操作简单的查询使用HBase
Sqoop
sql- to-hadoop ,传统关系型数据库到Hadoop的桥梁。将关系型数据库数据导入到HDFS、Hive、HBase。将数据库同步问题转换为map reduce作业。