if [type] == "tbl_api" 和 if [@metadata][input][id] == "jdbc_input_orders" 都是用于数据路由的常见模式,但它们在使用场景、语义清晰度和灵活性上有关键区别。
核心区别对比
| 特性 | if [type] == "tbl_api" |
if [@metadata][input][id] == "jdbc_input_orders" |
|---|---|---|
| 语义层级 | 业务语义 | 技术语义 |
| 定义内容 | "这是什么数据?" (e.g., 资产API数据、订单日志、用户行为) | "数据从哪里来的?" (e.g., 来自jdbc_input_orders这个输入块) |
| 字段位置 | 普通字段,会出现在输出中 | 元数据字段,不会出现在最终输出中 |
| 灵活性 | 高。与输入源解耦,一个输入可以产生多种type。 |
低。与输入源强绑定。 |
| 可读性 | 高。看配置就知道在处理什么业务数据。 | 低 。需要翻看input配置才知道jdbc_input_orders是什么。 |
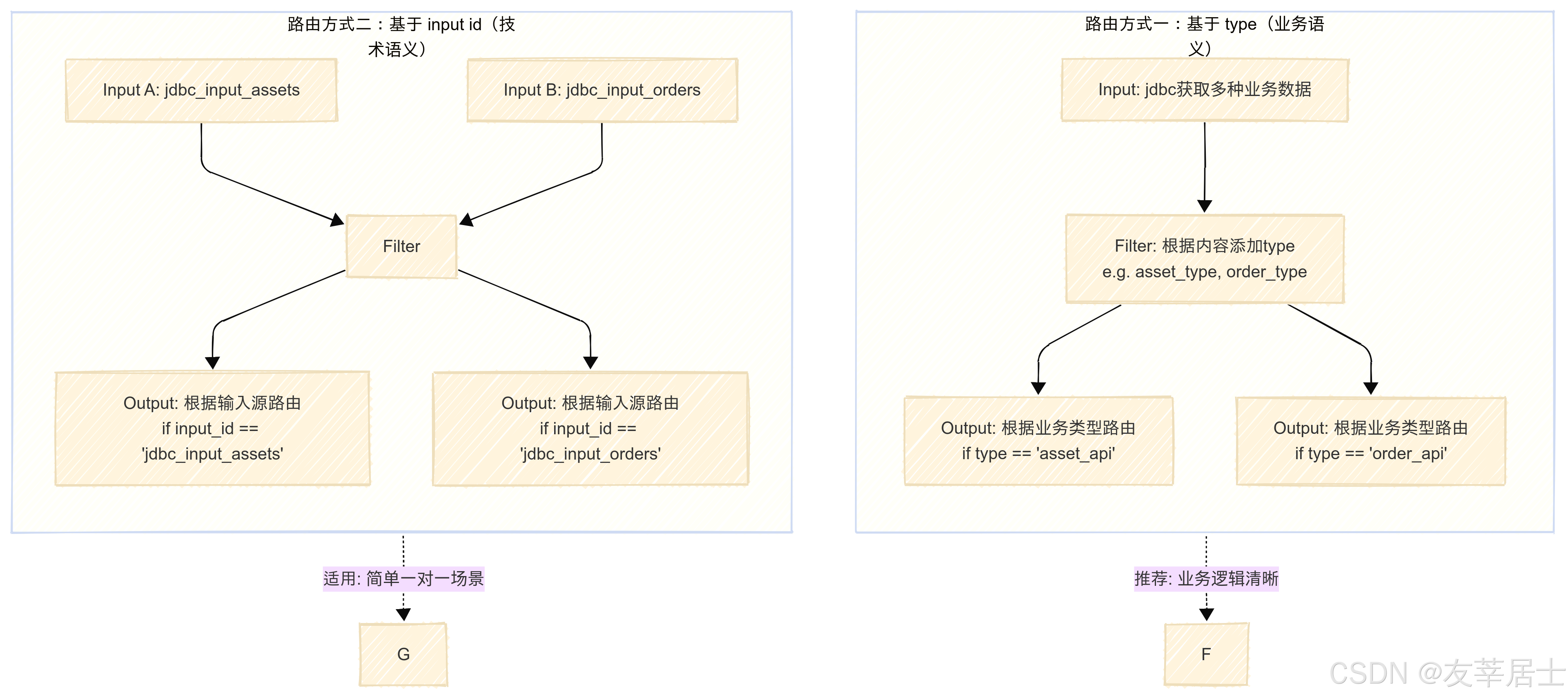
详细解释与示例
1. 基于 type (业务语义路由)
这种方式关注的是数据本身的业务含义 。一个输入源可以产生多种 type 的数据。
示例场景: 一个 JDBC 查询从一张大宽表中获取了多种类型的数据。
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://..."
statement => "SELECT asset_id, asset_name, type FROM assets" # 查询中包含一个`type`字段
# 这里没有设置固定的type,因为type由数据内容决定
}
}
filter {
# 根据数据库中`type`字段的值,为其设置Logstash的`type`标签
if [type] == "server" {
mutate { replace => { "type" => "tbl_api_server" } }
} else if [type] == "network" {
mutate { replace => { "type" => "tbl_api_network" } }
}
}
output {
# 输出根据业务类型路由到不同的Topic
if [type] == "asset_api_server" {
kafka { topic_id => "topic-servers" ... }
}
if [type] == "asset_api_network" {
kafka { topic_id => "topic-network-devices" ... }
}
}优点:非常灵活,逻辑基于业务数据本身,与输入源解耦。
2. 基于 [@metadata][input][id] (技术源路由)
这种方式关注的是数据的来源 。它直接与 input 块中定义的 id 绑定。
示例场景: 多个独立的 JDBC 查询,每个查询对应一个特定的 Topic。
input {
jdbc {
id => "jdbc_input_orders" # 技术ID
statement => "SELECT * FROM orders ..."
type => "any_type_here" # 这个type可能被忽略,因为output用input_id判断
}
jdbc {
id => "jdbc_input_users" # 技术ID
statement => "SELECT * FROM users ..."
}
}
output {
# 输出根据输入源的ID进行路由
if [@metadata][input][id] == "jdbc_input_orders" {
kafka { topic_id => "mysql-orders-topic" ... }
}
if [@metadata][input][id] == "jdbc_input_users" {
kafka { topic_id => "mysql-users-topic" ... }
}
}优点 :配置简单直接,适合一对一 的场景(一个输入源对应一个输出目标)。不需要在 filter 中做任何处理。
应该如何选择?
- 使用
if [type] == ...:- 你希望根据数据的业务内容或属性来决定其去向。
- 同一个输入源会产生多种需要区别对待的数据类型。
- 你希望配置文件的可读性更高,让人一眼就知道在处理什么业务数据。
- 使用
if [@metadata][input][id] == ...:- 管道设计是一个输入源严格对应一个输出目标。
- 数据路由决策只依赖于数据来自哪个技术输入源,而不关心其具体内容。
- 你不想在
filter中做任何额外的处理来标记数据。
结论:对于配置 if [type] == "tbl_api",它表明路由决策是基于数据的业务类型("资产API")做出的。这是一种更高级、更灵活的做法,因为它将数据的来源(Input)和数据的含义(Type)以及数据的去向(Output)进行了清晰的解耦,使得管道设计更加面向业务和可维护。