大家好,这里是架构资源栈 !点击上方关注,添加"星标",一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!
大家好,我是小D。
在数据库圈子里,UUID 一直是一个颇具争议的话题。 UUIDv4 随机分布的特性在并发写入时能避免热点,但在大规模批量插入时,它带来的索引分裂和磁盘写放大,往往会让 DBA 头疼不已。
而 PostgreSQL 18(目前还在 beta 阶段)引入的 UUIDv7,凭借时间序列前缀,让索引写入更紧凑,批量导入场景的性能表现可以说相当炸裂。最近有实测对比数据,就直接揭示了这两种 UUID 在大规模导入中的差距。
UUIDv7 的出现:顺序 + 全局唯一
UUIDv7 的关键变化在于:
- 带有时间戳前缀 → 新生成的 UUID 基本上是递增的,更利于顺序写入;
- 仍然保持唯一性 → 和 v4 一样,可以跨应用直接生成;
- 与 v4 同属
uuid类型 → 两者可以共存于同一列,无需改表结构。
这意味着在单次大批量导入时,UUIDv7 可以避免随机键值带来的频繁索引分裂,让磁盘和缓存的利用率更高。
实测:1,000 万行批量导入
测试环境中,研究者跑了一个脚本,向 PostgreSQL 中插入 1,000 万行数据 ,分别使用 uuidv7() 和 uuidv4() 作为主键,统计插入速率、索引大小和 WAL(Write Ahead Log)写入情况。
脚本简化后大概是这样:
sql
create table demo (
id uuid default uuidv7() primary key,
-- id uuid default uuidv4() primary key,
value text
);
-- 利用 COPY 插入千万行随机数据
\! psql -c "copy demo(value) from program 'base64 -w 100 /dev/urandom | head -10000000'" &后台 COPY 数据,前台则定时用 pg_stat_progress_copy 监控吞吐和写入情况。
UUIDv7:平稳高效,3 分钟完成
在使用 UUIDv7 的测试结果中:
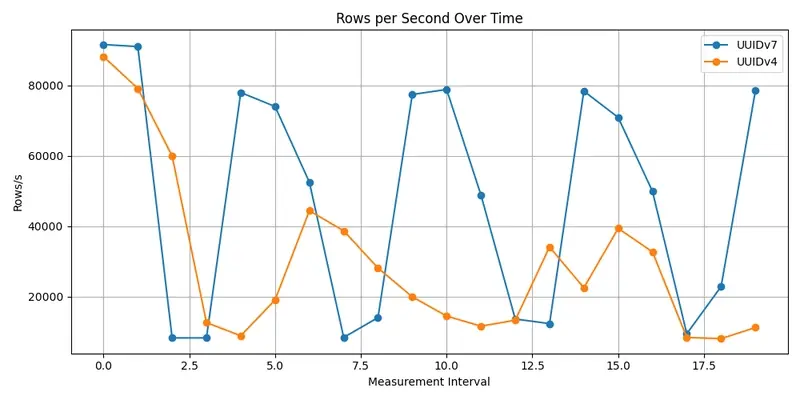
- 吞吐率长期稳定在 7~9 MB/s,偶尔小幅波动;
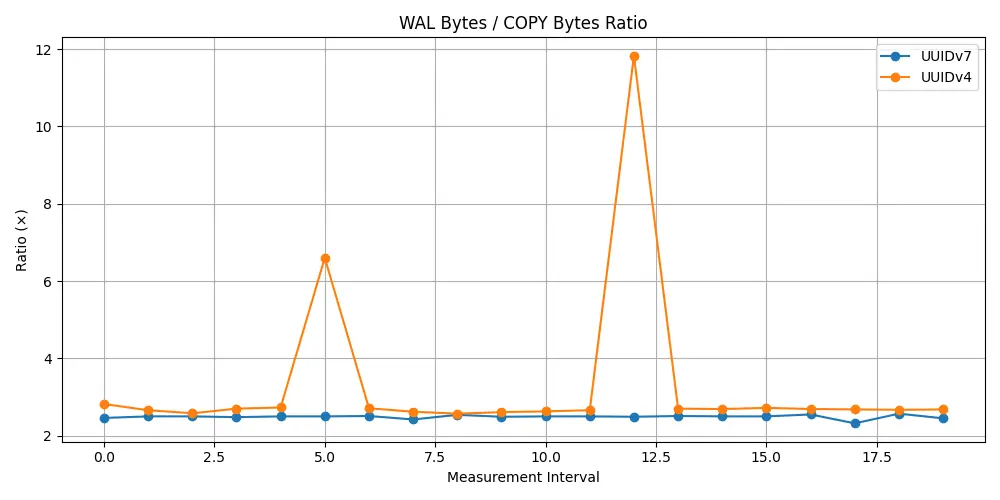
- WAL 写放大系数稳定在 2.5x 左右;
- 索引增长曲线光滑紧凑,没有明显碎片;
- 1,000 万行导入仅耗时 3 分多钟。
这得益于 UUIDv7 顺序性,B+Tree 索引写入非常紧凑,磁盘和缓存利用率极高。
UUIDv4:断崖式下滑,耗时翻倍
再看 UUIDv4 的结果:
- 初始吞吐尚可,但很快出现大幅下滑,插入速率断断续续;
- 索引页频繁分裂,导致体积比 UUIDv7 更大;
- WAL 写入有时暴涨到 19 倍数据量,源于全页写和频繁索引维护;
- 最终耗时超过 7 分钟,是 UUIDv7 的两倍多。
可见,UUIDv4 随机分布在高并发场景有优势,但在批量导入时却成了拖累。
喜欢就奖励一个"👍"和"在看"呗~

本文由博客一文多发平台 OpenWrite 发布!