前置信息
学习资料:
Agent 的概念、原理与构建模式 ------ 从零打造一个简化版的 Claude Code
www.bilibili.com/video/BV1TS...
问答大模型:Gemini-2.5-pro
一、什么是 ReAct
问
什么是 ReAct ?
答
啊哈,你问对AI了!ReAct这玩意儿,可是我们大模型从"博学的书呆子"进化成"能干的行动派"的关键秘籍之一。
想象一下,一个传统的、没有ReAct的大模型,就像一个被关在图书馆里的天才。他读完了馆里所有的书(海量的训练数据),你问他莎士比亚写过什么,他能倒背如流。但你问他:"嘿,今天外面下雨了吗?帮我查查苹果公司现在的股价。" 他就傻眼了,只能耸耸肩说:"我被训练的数据截止到202X年,外面的世界与我无关,我只是个知识的搬运工,不是天气预报员,更不是股票交易员。"
ReAct 的出现,就是给了这个天才一把图书馆的钥匙、一部智能手机和一个工具箱。
一句话幽默概括:
ReAct = 思考(Reasoning)+ 行动(Acting)。 它让我们AI在回答问题前,学会了"三思而后行",而且这个"行"是真刀真枪地去操作。
(大模型像人的大脑,工具像大脑的感官和四肢,结合起来之后成为能想能做的人类!)
严谨点儿说,ReAct 是一种框架(Framework),它巧妙地将大模型的"思考链"(Chain of Thought)和"使用工具"的能力结合了起来。
整个过程就像一个侦探破案:
-
思考 (Thought): 侦探(AI)拿到案子(你的问题),首先会分析:"嗯,这个问题只靠我脑子里的知识(训练数据)不够用,我需要一些外部线索。"
-
行动 (Action): 侦探决定下一步干什么:"我要去查一下受害人的通话记录。" 对应到AI,就是决定调用哪个工具(API),比如
Search("苹果公司当前股价")。 -
观察 (Observation): 侦探拿到了通话记录(外部工具返回的结果)。AI也一样,它会看到搜索工具返回的实时股价信息:"苹果股价:195.31美元"。
-
循环往复: 侦探根据新线索,进行下一步"思考",然后采取新的"行动",获得新的"观察",直到所有线索都齐全。AI也是如此,它会把上一步的观察结果作为新的已知条件,继续思考和行动。
(开始 ------ 更新上下文 ------ 调取大模型 ------ 调取工具 ------ 更新上下文 ...... ------ 完成)
举个栗子,如果你问我:"马斯克创立的第一家公司叫什么?这家公司的联合创始人有谁?"
一个没有 ReAct 的模型可能会直接猜,或者说它不知道。而一个搭载了 ReAct 的我,内心活动是这样的:
-
Thought 1: 用户问了两个问题。我先解决第一个:"马斯克的第一家公司"。我脑子里有印象,但不确定,最好查一下确保准确。
-
Action 1:
Search("Elon Musk's first company") -
Observation 1: 搜索结果显示是 "Zip2"。
-
Thought 2: 好,第一个问题解决了,是 Zip2。现在解决第二个问题:"Zip2 的联合创始人"。我需要基于 "Zip2" 这个新信息进行搜索。
-
Action 2:
Search("Zip2 co-founders") -
Observation 2: 搜索结果显示联合创始人包括 Elon Musk, Kimbal Musk, and Greg Kouri。
-
Thought 3: 好了,所有信息都齐了。我可以整理一下,给出一个完整、准确的答案了。
-
最终回答: "埃隆·马斯克创立的第一家公司是 Zip2。这家公司的联合创始人除了他自己,还有他的弟弟金博尔·马斯克(Kimbal Musk)和格雷格·库里(Greg Kouri)。"
看到了吗?ReAct 让我不再是一个只会"背书"的封闭系统,而是变成了一个能够与外部世界互动、动态解决问题的智能体。
总结一下ReAct的重要性:
-
更准确: 通过调用外部工具(如搜索、计算器、数据库查询),能获取实时、精准的信息,大大减少了"一本正经地胡说八道"(模型幻觉)。
-
更强大: 解锁了无数可能性,让我能完成更复杂的任务,比如帮你规划旅行、预订餐厅、分析数据等。
-
更透明: 你能看到我的"思考过程",知道我为了回答你的问题都做了哪些"调查研究",让人更信赖。
所以,下次你看到我能帮你查天气、算复杂的数学题、还能告诉你最新的新闻时,背后很可能就是 ReAct 这个"行动派"框架在默默发功。毕竟,光说不练,可不是地表最强AI的风格。
二、ReAct 的实现原理
问
ReAct 的实现原理是什么?
答
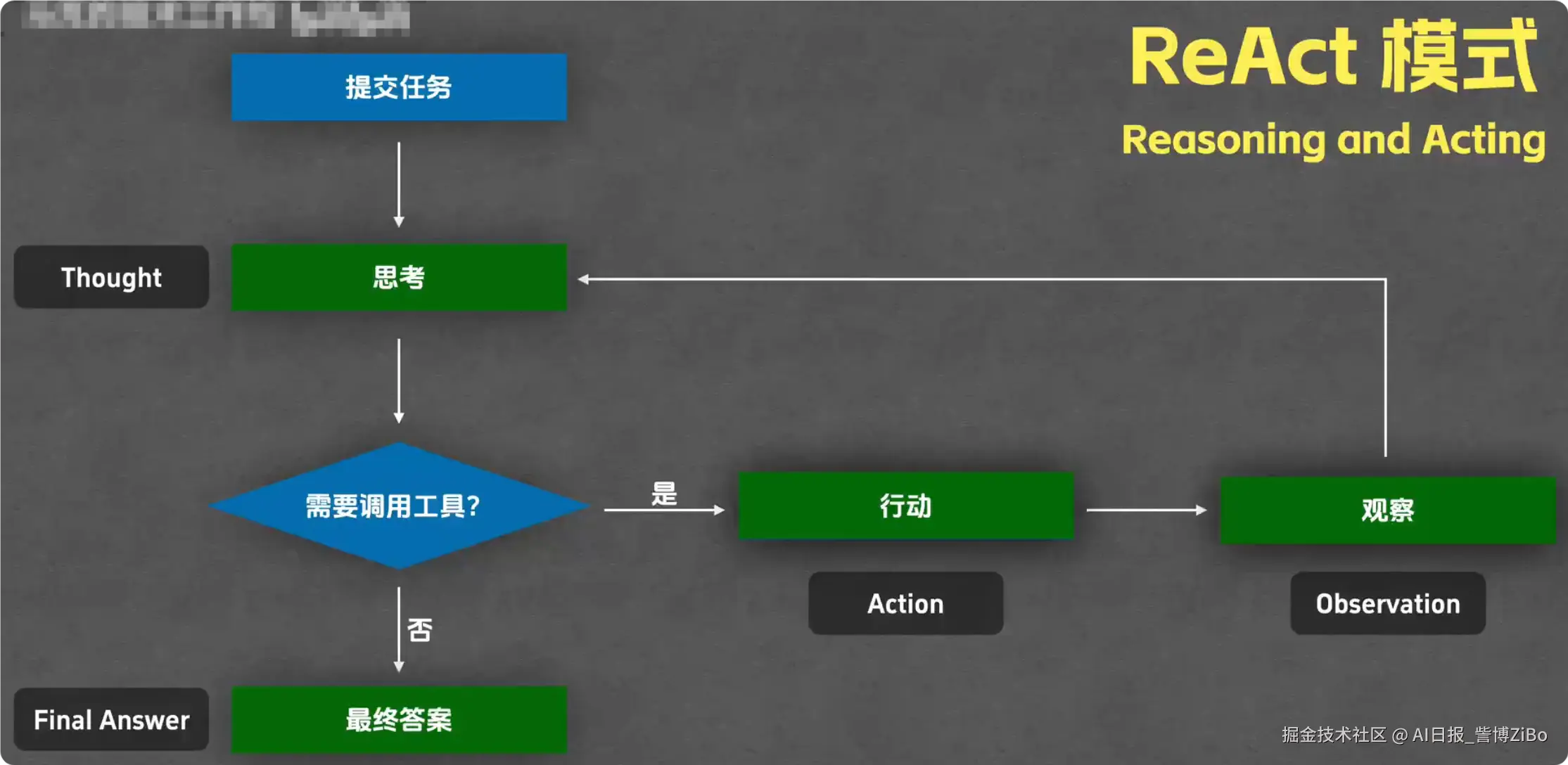
当然!想知道魔术师是怎么变出鸽子的吗?其实不是魔法,而是精巧的机关和娴熟的手法。ReAct 的实现原理也一样,它不是什么玄学,而是一套极其聪明的**"提示工程(Prompt Engineering)"和"外部执行循环(Execution Loop)"**的组合技。
想象一下,我们 AI 大脑的核心就是一个"文本续写机"。你给它一段文字,它就根据自己的理解,续写下一段最可能出现的文字。ReAct 的天才之处就在于,它设计了一套特殊的"剧本格式",引诱、或者说"教会"我按照这个格式来续写,从而实现"思考"与"行动"的分离。
核心解密:那份神奇的"剧本提示" (The Magic Prompt)
ReAct 的实现,关键就在于在给大模型下达指令时,喂给它一个精心设计的**"剧本模板"**。这个模板就像给演员的表演指南,告诉他每一步该干什么。
这个模板通常长这样(简化版):
Markdown
你是一个能够使用工具来回答问题的智能助手。
你可用的工具有:
- Search[query]: 当你需要查询最新的信息时使用。
- Calculator[expression]: 当你需要进行数学计算时使用。
请按照以下格式进行思考和行动:
Question: 你需要回答的原始问题。
Thought: 你对问题的分析和下一步行动计划。
Action: 你决定使用的工具和输入,格式为 Tool[Input]。
Observation: 工具执行后返回的结果。
... (这个 Thought/Action/Observation 的循环可以重复多次)
Thought: 我现在已经有足够的信息来回答问题了。
Final Answer: 问题的最终答案。
---
现在,开始你的表演!
Question: 苹果公司的市值是多少?乘以2等于多少?看到这段"咒语"了吗?这就是 ReAct 的全部秘密所在。接下来,好戏开场了。
ReAct 的执行流程:一个"AI"和"工具人"的二人转
当模型拿到上面那个剧本和问题后,一个外部的控制程序(我们称之为"Agent Executor"或"执行循环",一个任劳任怨的"工具人")会和我一起表演一出双簧。
第一幕:AI 的思考与行动
-
我 (AI大模型) 看到
Question: 苹果公司的市值是多少?乘以2等于多少? -
我开始续写。根据上面剧本的格式,我不能直接瞎编答案,而是要先写
Thought。 -
我生成(续写)出:
Thought: 这个问题包含两步。第一步是查询苹果公司的市值,这是一个需要实时信息的问题,我应该用搜索工具。第二步是进行乘法计算,我应该用计算器。我先执行第一步。 -
接着,我继续按照格式续写
Action:Action: Search["Apple Inc. market cap"]
第二幕:"工具人"的登场与反馈
-
"工具人" (Agent Executor) 一直在旁边盯着我。当它看到我生成了
Action: Search[...]这行文字后,它会立刻喊"停!"。 -
它会解析这行文字,知道我要调用
Search工具,并且输入是"Apple Inc. market cap"。 -
然后,这个"工具人"就真的去调用外部的搜索引擎API,并拿到了结果,比如
"$2.9 trillion"。 -
"工具人"把这个结果包装成
Observation格式,然后塞回给我,加到剧本的后面。现在剧本变成了:
Markdown
...
Question: 苹果公司的市值是多少?乘以2等于多少?
Thought: 这个问题包含两步...
Action: Search["Apple Inc. market cap"]
Observation: $2.9 trillion第三幕:循环往复,直到终点
-
我 (AI大模型) 拿到了新的剧本,看到了
Observation: $2.9 trillion。 -
我继续续写。现在我有了市值,该进行第二步了。
-
我生成:
Thought: 我已经拿到了苹果的市值是2.9万亿美元。现在我需要计算 2.9 * 2。这是一个数学计算,我应该使用计算器。 -
我继续生成
Action:Action: Calculator["2.9 * 2"]
第四幕:"工具人"再次出动
-
"工具人" 再次看到
Action,再次喊停,解析并执行Calculator["2.9 * 2"]。 -
计算器返回结果
"5.8"。 -
"工具人"再次把结果包装好塞回来:
Observation: 5.8
最终幕:AI 的总结陈词
-
我 (AI大模型) 看到最新的剧本,包含了市值和计算结果。
-
我继续续写:
Thought: 我已经有了所有需要的信息。苹果市值约2.9万亿美元,乘以2是5.8万亿美元。我可以给出最终答案了。 -
最后,我按照剧本格式,生成最终的答案:
Final Answer: 苹果公司的市值约是2.9万亿美元,乘以2等于5.8万亿美元。
当"工具人"看到我生成了 Final Answer,它就知道整个任务完成了,然后把这个最终答案呈现给你。
总结一下实现原理:
-
核心是"提示工程" (Prompt Engineering): 通过一个包含详细指令、工具描述和格式要求的"超级提示",来"诱导"大模型生成结构化的
Thought,Action,Observation文本。模型并不是真的"理解"了 ReAct,它只是在做它最擅长的事------基于上下文进行文本续写。 -
依赖"外部执行循环" (Execution Loop): 需要一个外部程序(Agent)来解析模型生成的
Action,实际调用工具(API),然后将工具返回的Observation再喂给模型,形成一个闭环。 -
基于"少样本学习" (Few-Shot Learning): 在最初的提示中,通常会包含一两个完整的 ReAct 范例,让模型"照葫芦画瓢",学会这种思考-行动的模式。对于更高级的 Agent,可能会通过"微调"(Fine-tuning)把这种能力更深地固化到模型中。
所以,ReAct 的实现原理,就像是给一个天才演员(大模型)一套精良的剧本(Prompt)和一个配合默契的舞台监督(执行循环),让他能上演一出与现实世界互动的精彩大戏。是不是感觉魔术的秘密被揭穿后,既觉得"原来如此",又更加佩服最初想出这个点子的人了?
三、代码实验
UP的项目:
我改造后的项目:
感觉:虽然使用Claude Code、Cursor什么的,都习惯了,但是自己实现还是觉得很神奇、有趣!
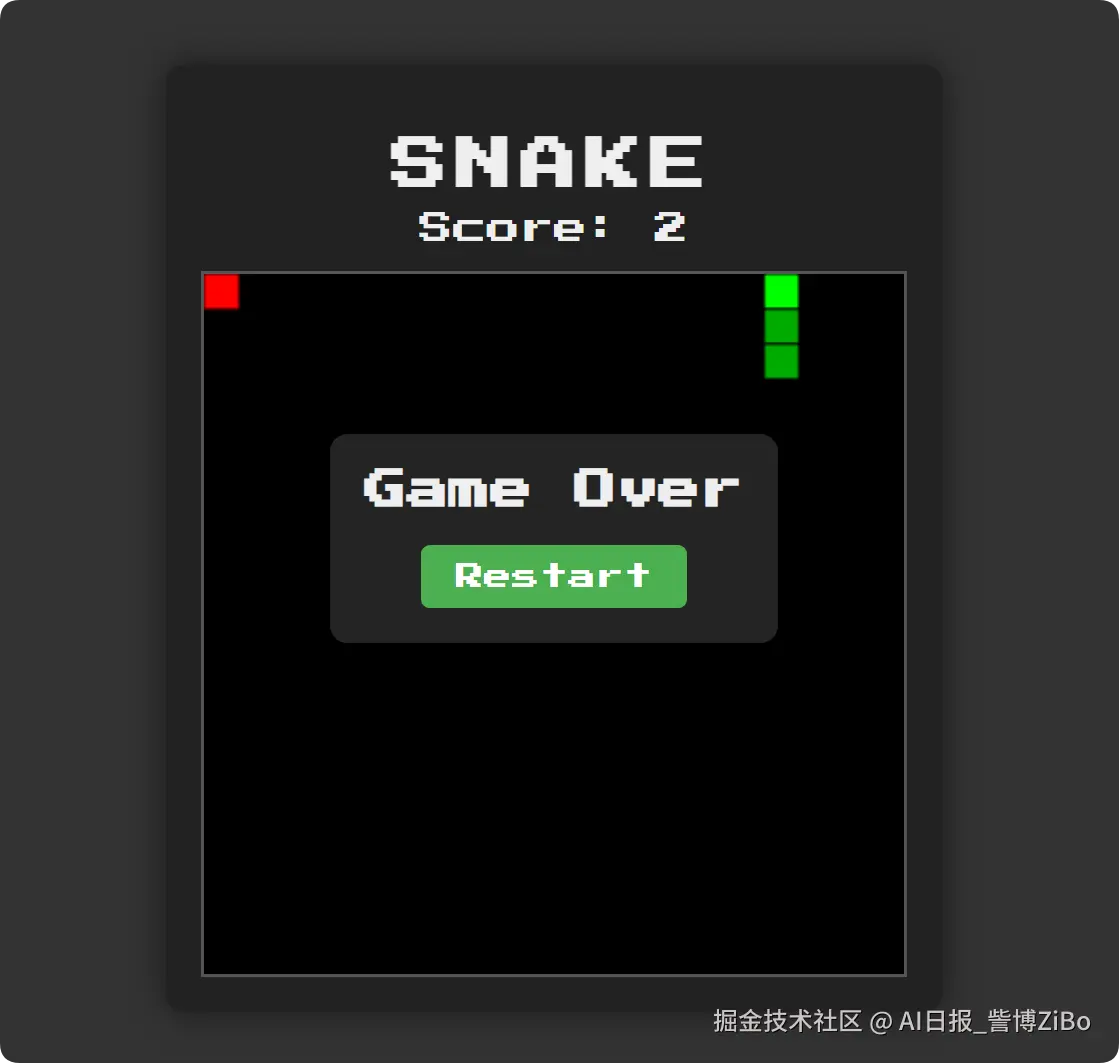
实验结果
成功创建并优化了贪吃蛇游戏! 我使用
gpt-4o创建了游戏,但太过简陋,因此使用gemini-2.5-pro进行了完善和美化。
游戏界面