注意:该项目只展示部分功能
1.开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
随着全球工业化进程的不断推进和经济发展水平的持续提升,世界各国对能源的需求量呈现出快速增长的态势。能源作为现代社会运行的基础动力,其消耗模式和结构变化直接影响着各国的经济发展策略和环境政策制定。当前,全球面临着能源安全、环境保护和可持续发展的多重挑战,传统化石燃料的大量使用导致温室气体排放持续增加,而可再生能源的发展程度在不同国家和地区存在显著差异。面对如此庞大且复杂的全球能源数据,传统的数据分析方法已经难以满足深度挖掘和全面分析的需求。大数据技术的兴起为处理这些海量、多维度的能源数据提供了新的技术路径,通过Spark和Hadoop等分布式计算框架,可以实现对全球能源消耗数据的高效处理和深入分析。在这样的技术背景和现实需求下,构建一套基于python+大数据的全球能源消耗量分析可视化系统具有了实际的应用价值和技术探索意义。
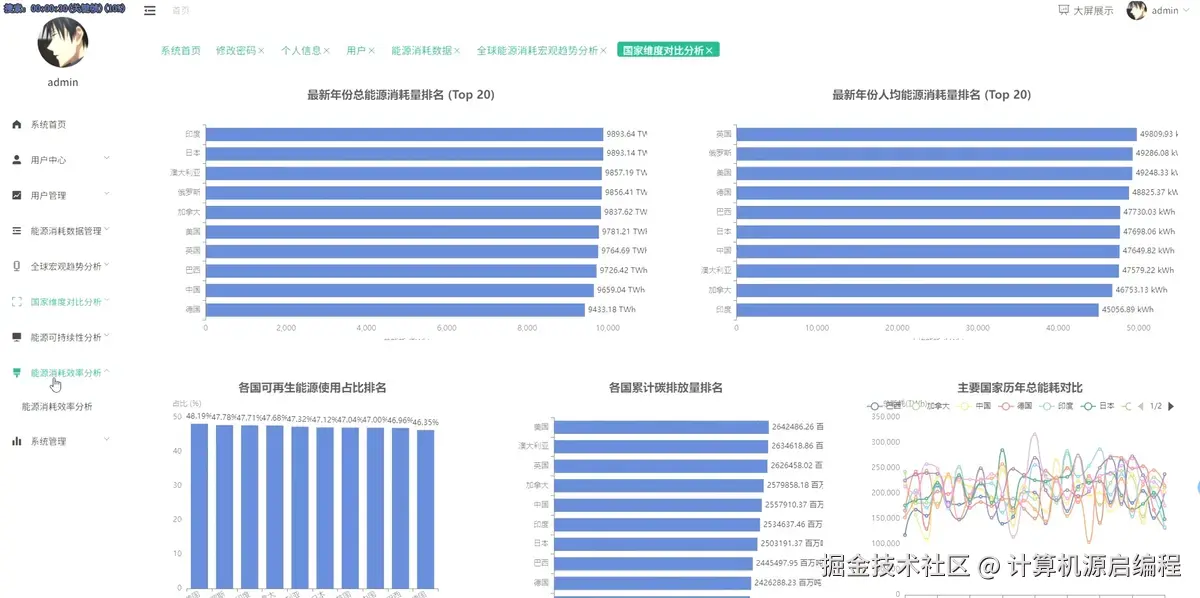
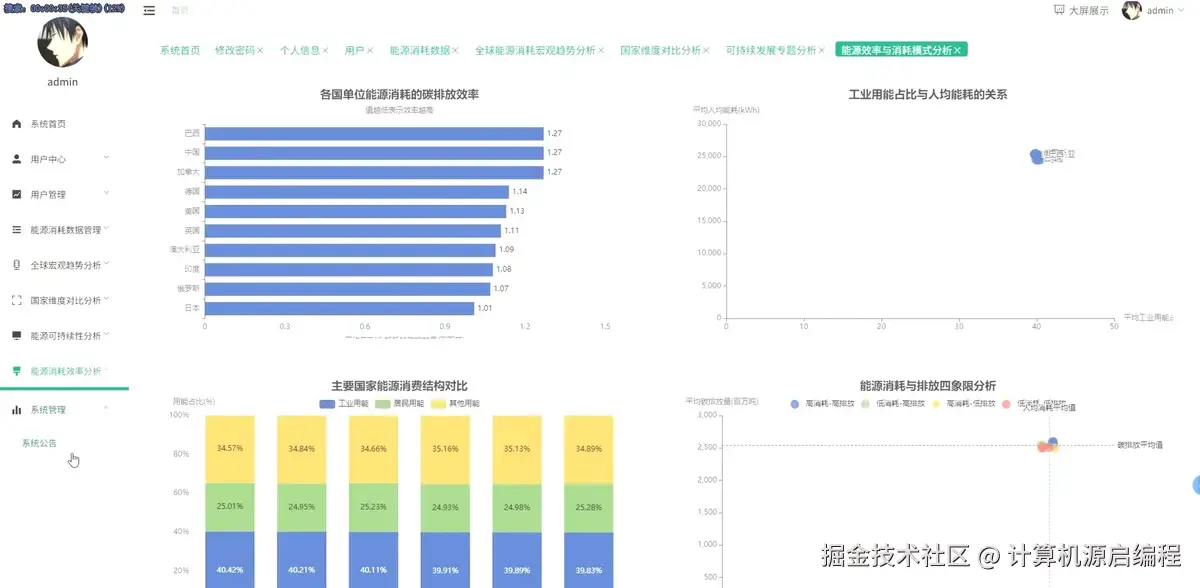
基于python+大数据的全球能源消耗量分析可视化系统是一套完整的大数据分析解决方案,专门针对全球范围内的能源消耗数据进行深度挖掘和直观展示。该系统采用Python作为核心开发语言,结合Spark分布式计算框架和Hadoop生态系统,能够高效处理海量的全球能源数据,包括各国历年总能源消耗量、人均能源使用量、可再生能源占比、化石燃料依赖度、碳排放量等关键指标。系统通过数据挖掘和机器学习算法,实现了四大核心分析维度:全球能源消耗宏观趋势分析、不同国家维度的能源状况横向对比、能源结构与可持续发展专题分析、以及能源效率与消耗模式分析。前端采用Vue框架构建响应式界面,集成Echarts图表库实现丰富的数据可视化效果,包括趋势图、排名对比图、相关性散点图和聚类分析图等多种图表类型,让复杂的能源数据以直观、交互式的方式呈现给用户。后端使用MySQL数据库存储处理后的分析结果,确保数据的持久化和快速查询。整个系统不仅展示了大数据技术在实际场景中的应用能力,更为全球能源政策制定、可持续发展研究和国际能源合作提供了有价值的数据支撑和决策参考。
3 系统展示
3.1 大屏页面
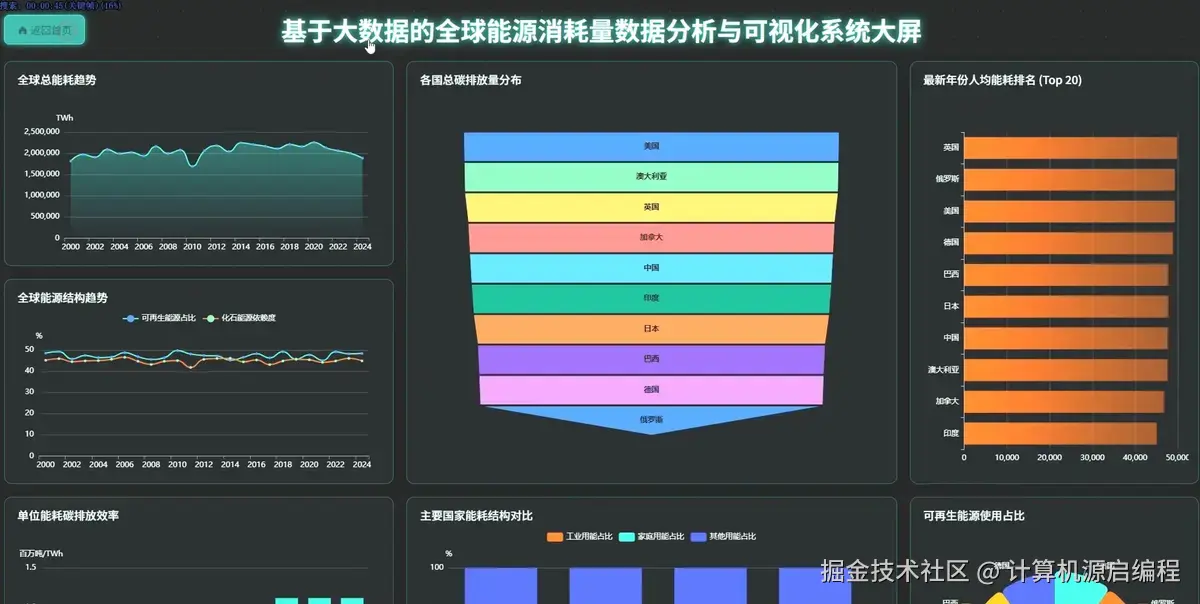
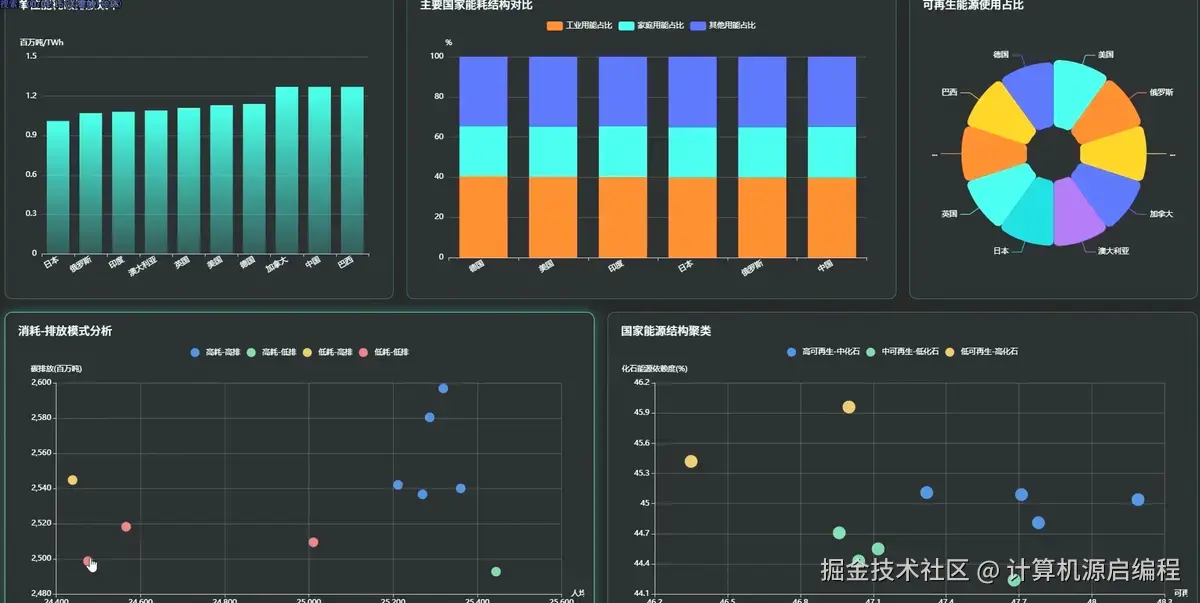
3.2 分析页面
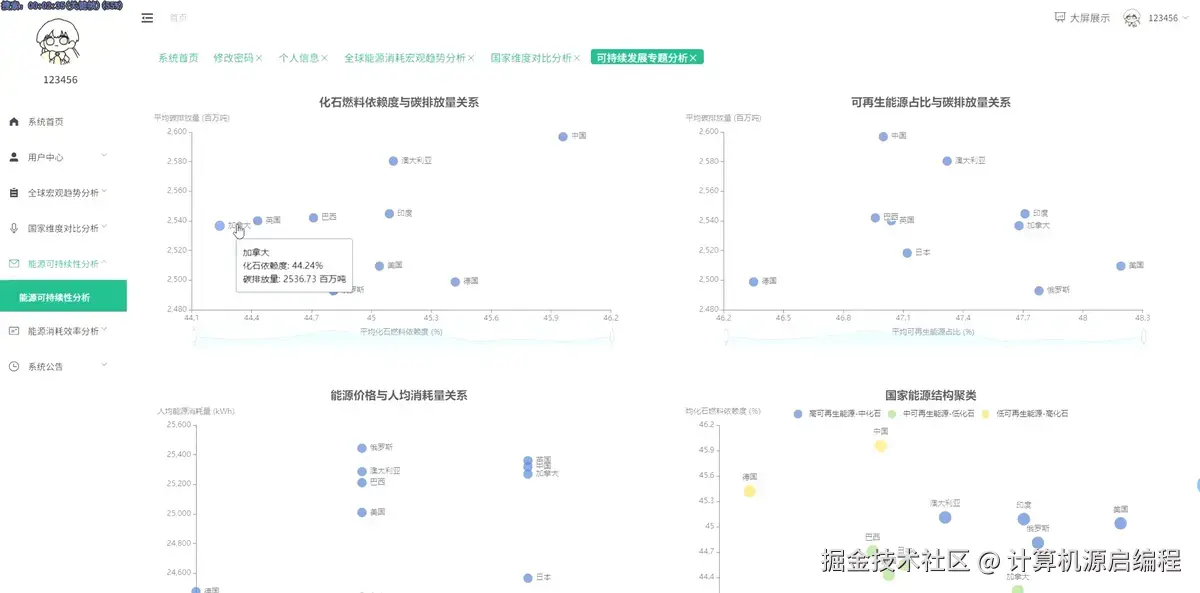
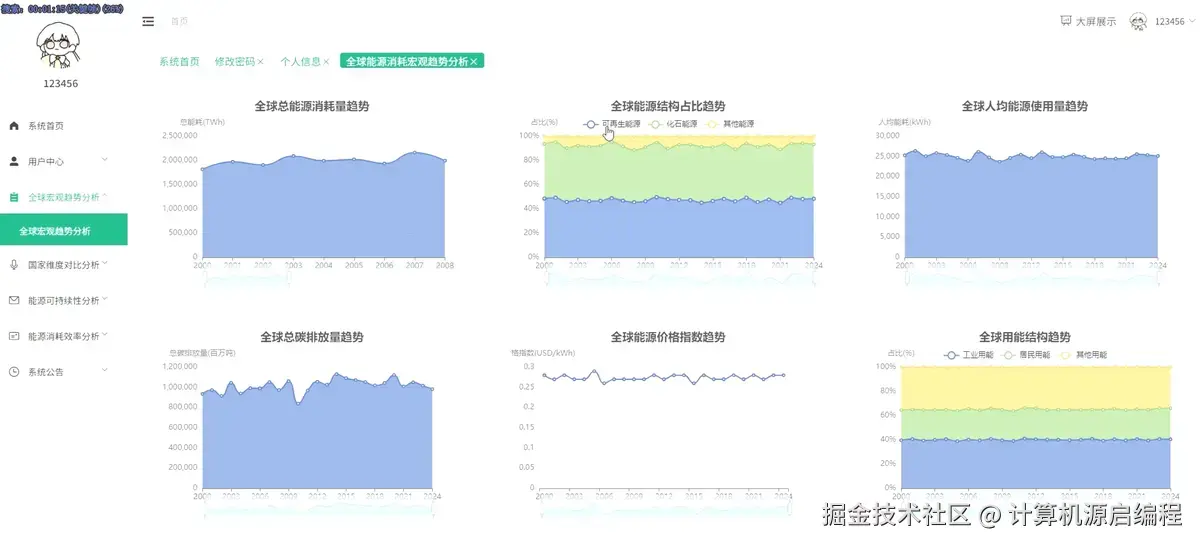
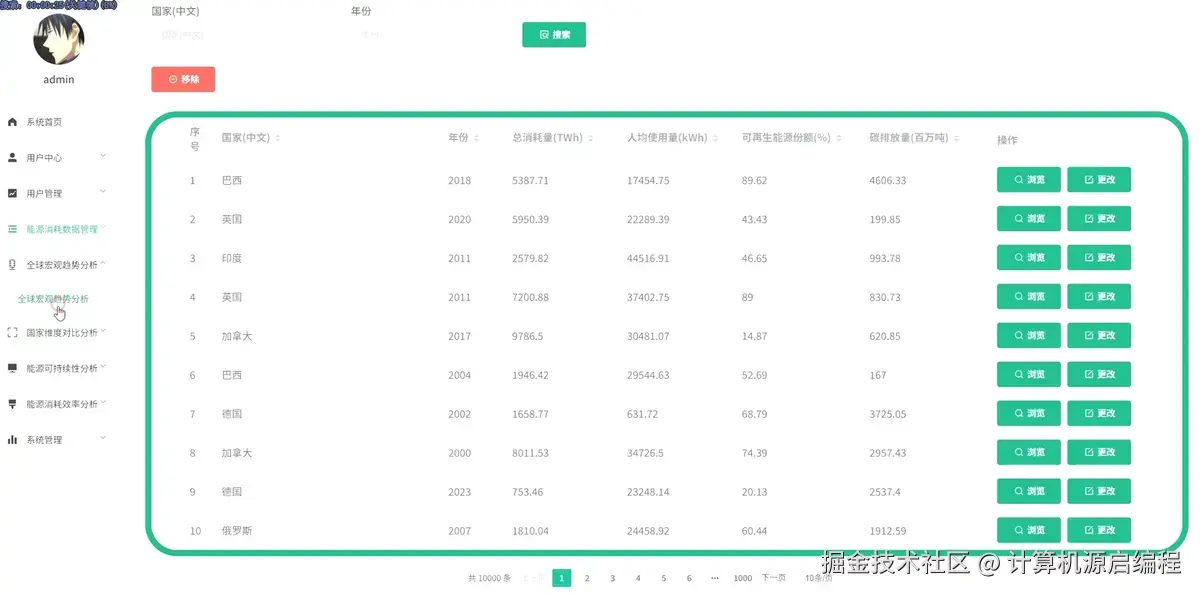
3.3 基础页面
4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型 【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析 基于Spark的全国饮品门店数据可视化分析大屏 基于Python与大数据技术的内向外向型性格行为特征挖掘与可视化系统 基于Spark与Echarts的全球二氧化碳数据可视化分析系统
5 部分功能代码
python
spark = SparkSession.builder.appName("GlobalEnergyAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def analyze_global_energy_trend():
energy_df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/energy_data/global_energy.csv")
energy_df = energy_df.filter(col("Total Energy Consumption (TWh)").isNotNull() & col("Year").isNotNull())
yearly_trend = energy_df.groupBy("Year").agg(
sum("Total Energy Consumption (TWh)").alias("total_consumption"),
avg("Renewable Energy Share (%)").alias("avg_renewable_share"),
avg("Fossil Fuel Dependency (%)").alias("avg_fossil_dependency"),
sum("Carbon Emissions (Million Tons)").alias("total_emissions"),
avg("Energy Price Index (USD/kWh)").alias("avg_price_index")
).orderBy("Year")
yearly_trend = yearly_trend.withColumn("renewable_growth_rate",
(col("avg_renewable_share") - lag("avg_renewable_share").over(Window.orderBy("Year"))) / lag("avg_renewable_share").over(Window.orderBy("Year")) * 100)
yearly_trend = yearly_trend.withColumn("emission_intensity",
col("total_emissions") / col("total_consumption"))
yearly_trend = yearly_trend.withColumn("energy_efficiency_score",
when(col("emission_intensity") < 0.5, 90)
.when(col("emission_intensity") < 1.0, 70)
.when(col("emission_intensity") < 1.5, 50)
.otherwise(30))
result_df = yearly_trend.select("Year", "total_consumption", "avg_renewable_share", "avg_fossil_dependency", "total_emissions", "renewable_growth_rate", "energy_efficiency_score").toPandas()
connection = mysql.connector.connect(host='localhost', database='energy_analysis', user='root', password='password')
cursor = connection.cursor()
cursor.execute("DELETE FROM global_energy_trends")
for index, row in result_df.iterrows():
insert_query = "INSERT INTO global_energy_trends (year, total_consumption, renewable_share, fossil_dependency, total_emissions, growth_rate, efficiency_score) VALUES (%s, %s, %s, %s, %s, %s, %s)"
cursor.execute(insert_query, tuple(row))
connection.commit()
cursor.close()
connection.close()
return result_df.to_dict('records')
def analyze_country_energy_ranking():
energy_df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/energy_data/global_energy.csv")
latest_year = energy_df.select(max("Year")).collect()[0][0]
latest_data = energy_df.filter(col("Year") == latest_year)
country_rankings = latest_data.select("Country", "Total Energy Consumption (TWh)", "Per Capita Energy Use (kWh)", "Renewable Energy Share (%)", "Carbon Emissions (Million Tons)")
consumption_rank = country_rankings.withColumn("consumption_rank", row_number().over(Window.orderBy(desc("Total Energy Consumption (TWh)"))))
per_capita_rank = country_rankings.withColumn("per_capita_rank", row_number().over(Window.orderBy(desc("Per Capita Energy Use (kWh)"))))
renewable_rank = country_rankings.withColumn("renewable_rank", row_number().over(Window.orderBy(desc("Renewable Energy Share (%)"))))
emission_rank = country_rankings.withColumn("emission_rank", row_number().over(Window.orderBy(desc("Carbon Emissions (Million Tons)"))))
comprehensive_ranking = country_rankings.withColumn("energy_consumption_score",
when(col("Total Energy Consumption (TWh)") > 5000, 100)
.when(col("Total Energy Consumption (TWh)") > 2000, 80)
.when(col("Total Energy Consumption (TWh)") > 1000, 60)
.when(col("Total Energy Consumption (TWh)") > 500, 40)
.otherwise(20))
comprehensive_ranking = comprehensive_ranking.withColumn("sustainability_score",
col("Renewable Energy Share (%)") * 0.7 + (100 - col("Fossil Fuel Dependency (%)")) * 0.3)
comprehensive_ranking = comprehensive_ranking.withColumn("efficiency_ratio",
col("Total Energy Consumption (TWh)") / col("Carbon Emissions (Million Tons)"))
final_ranking = comprehensive_ranking.select("Country", "Total Energy Consumption (TWh)", "Per Capita Energy Use (kWh)", "Renewable Energy Share (%)", "sustainability_score", "efficiency_ratio").orderBy(desc("Total Energy Consumption (TWh)")).limit(50)
result_df = final_ranking.toPandas()
connection = mysql.connector.connect(host='localhost', database='energy_analysis', user='root', password='password')
cursor = connection.cursor()
cursor.execute("DELETE FROM country_energy_rankings")
for index, row in result_df.iterrows():
insert_query = "INSERT INTO country_energy_rankings (country, total_consumption, per_capita_use, renewable_share, sustainability_score, efficiency_ratio, ranking_position) VALUES (%s, %s, %s, %s, %s, %s, %s)"
cursor.execute(insert_query, tuple(row) + (index + 1,))
connection.commit()
cursor.close()
connection.close()
return result_df.to_dict('records')
def analyze_energy_structure_clustering():
energy_df = spark.read.option("header", "true").option("inferSchema", "true").csv("hdfs://localhost:9000/energy_data/global_energy.csv")
country_avg_data = energy_df.groupBy("Country").agg(
avg("Renewable Energy Share (%)").alias("avg_renewable"),
avg("Fossil Fuel Dependency (%)").alias("avg_fossil"),
avg("Industrial Energy Use (%)").alias("avg_industrial"),
avg("Household Energy Use (%)").alias("avg_household"),
avg("Per Capita Energy Use (kWh)").alias("avg_per_capita")
).filter(col("avg_renewable").isNotNull() & col("avg_fossil").isNotNull())
assembler = VectorAssembler(inputCols=["avg_renewable", "avg_fossil", "avg_industrial", "avg_household"], outputCol="features")
feature_df = assembler.transform(country_avg_data)
kmeans = KMeans(k=4, seed=42, featuresCol="features", predictionCol="cluster")
model = kmeans.fit(feature_df)
clustered_df = model.transform(feature_df)
cluster_analysis = clustered_df.groupBy("cluster").agg(
count("Country").alias("country_count"),
avg("avg_renewable").alias("cluster_renewable"),
avg("avg_fossil").alias("cluster_fossil"),
avg("avg_per_capita").alias("cluster_per_capita")
)
clustered_with_labels = clustered_df.withColumn("cluster_type",
when(col("cluster") == 0, "Green Energy Leaders")
.when(col("cluster") == 1, "Fossil Fuel Dependent")
.when(col("cluster") == 2, "Balanced Energy Mix")
.otherwise("Transitioning Countries"))
clustered_with_labels = clustered_with_labels.withColumn("energy_transition_score",
col("avg_renewable") * 0.6 + (100 - col("avg_fossil")) * 0.4)
clustered_with_labels = clustered_with_labels.withColumn("development_level",
when(col("avg_per_capita") > 10000, "High")
.when(col("avg_per_capita") > 5000, "Medium")
.otherwise("Low"))
result_df = clustered_with_labels.select("Country", "cluster", "cluster_type", "avg_renewable", "avg_fossil", "energy_transition_score", "development_level").toPandas()
connection = mysql.connector.connect(host='localhost', database='energy_analysis', user='root', password='password')
cursor = connection.cursor()
cursor.execute("DELETE FROM energy_structure_clusters")
for index, row in result_df.iterrows():
insert_query = "INSERT INTO energy_structure_clusters (country, cluster_id, cluster_type, renewable_share, fossil_dependency, transition_score, development_level) VALUES (%s, %s, %s, %s, %s, %s, %s)"
cursor.execute(insert_query, tuple(row))
connection.commit()
cursor.close()
connection.close()
return result_df.to_dict('records')源码项目、定制开发、文档报告、PPT、代码答疑 希望和大家多多交流