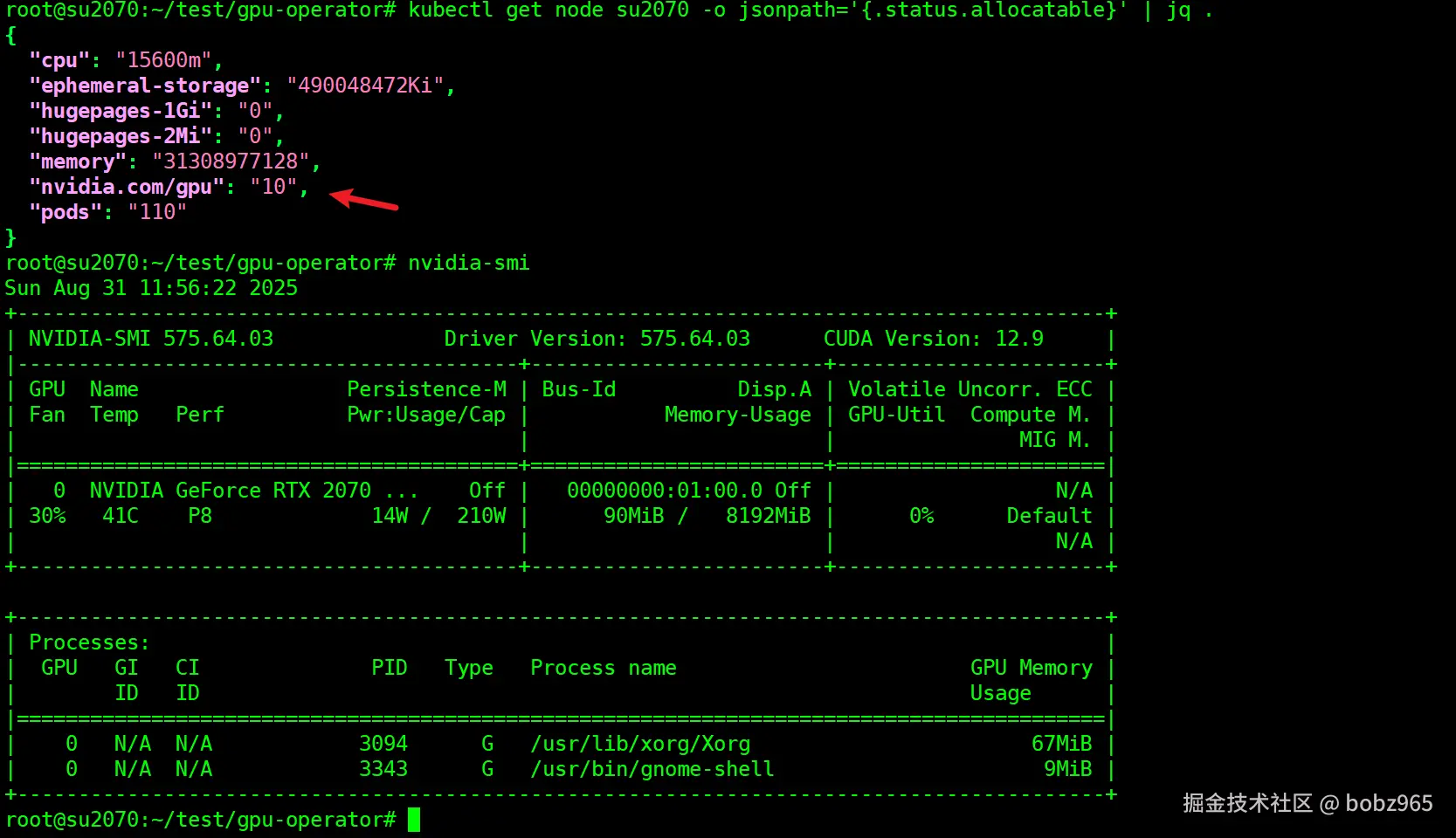
在 Kubernetes 集群中,"nvidia.com/gpu": "10" 表示节点 su2070 向集群报告的可分配 GPU 资源数量为 10 个。
不过,结合你提供的 nvidia-smi 输出可以发现,该节点实际只配备了 1 块 NVIDIA GeForce RTX 2070 显卡。这种数值不匹配通常是由以下原因导致的:
- GPU 资源配置问题:可能是通过 Kubernetes 设备插件(如 NVIDIA GPU Operator)配置时,误将 GPU 资源数量设置为 10。这通常与 GPU 分片、MIG(多实例 GPU)配置有关,但你的显卡(RTX 2070)并不支持 MIG 功能。
- 配置错误:可能是在安装 NVIDIA 设备插件时,通过配置参数(如 NVIDIA_VISIBLE_DEVICES 或自定义资源配置)错误地设置了可分配 GPU 数量。
- 插件版本或配置问题:NVIDIA GPU Operator 或相关设备插件可能存在配置错误,导致错误报告 GPU 数量。
要解决这个问题,建议检查:
- NVIDIA GPU Operator 的配置
- 节点上的设备插件配置
- 确认显卡是否支持分片或 MIG(RTX 2070 不支持)
正确配置后,nvidia.com/gpu 的值应与实际物理 GPU 数量一致(即应为 1)。