前言
传统的 Web 框架Spring MVC,通过阻塞式多线程处理每一个请求。每一个客户端连接都会占用一个线程:当请求到达时,系统从线程池中分配一个工作线程(worker 线程)负责处理,而这个线程会一直 "盯着" 任务,直到处理完成并返回结果后才会释放。
这种模式下,线程资源与连接数直接挂钩。比如面对 1000 个同时发来的 "查询商品库存" 请求,Spring MVC会调度 1000 个线程,每个线程单独处理一个请求。如果查询数据库平均耗时1秒,这 1 秒里,每个线程只能等待,其既不能接新请求,也不能干别的,只能等待查询完成。一旦线程池里的线程被耗尽,新请求就会排队甚至失败,这也就是高并发场景下传统框架 "扛不住" 的原因。
而 Spring5 所推出的 Spring-WebFlux,则是一套全新的异步非阻塞 Web 模块。它的核心是通过 "事件轮询(event looping)" 机制,来实现一个线程就能处理多个请求,从而降低连接的资源消耗。
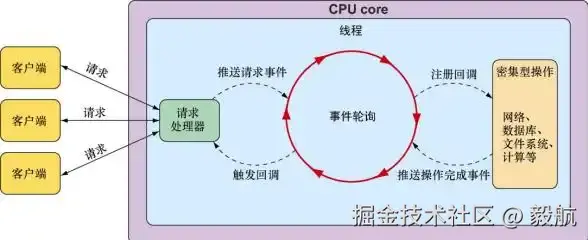
回到之前的例子:同样面对 1000 个查询请求,当使用异步WebFlux后,程序内部不再需要创建 1000 个线程,而是利用非阻塞特性实现线程复用。假设我们的CPU 核心数为4,对于此类I/O密集型请求,线程池数量通常维护到 8(I/O 密集型任务中,线程数一般为 CPU 核心数的 2 倍,刚好匹配大量等待 IO 时的线程复用需求)。
此时,仅需 8 个线程即可完成 1000 个请求的处理。事件轮询机制作为核心调度组件,会首先接收所有请求并完成注册,随后通过持续的事件监听机制检测各请求的后续操作是否就绪。
当某请求需要执行数据库操作时,线程不会进入阻塞等待状态,而是通过注册回调函数预设结果处理逻辑,随即转向处理下一个就绪任务;待数据库操作完成并返回结果后,事件轮询会触发回调流程,由空闲线程继续执行该请求的后续处理步骤。
在此过程中,线程始终处于可执行状态,避免了因等待I/O操作导致的资源闲置。因此,1000 个请求同样可在约 1 秒内完成处理,且全程不会因线程资源耗尽引发新请求的阻塞。
WebFlux相关API
知晓了WebFlux的异步机制后,接下来则对WebFlux相关的API进行一个简单介绍。
具体来看,WebFlux的 API 围绕响应式编程模型设计,核心依赖于 Reactor 库中的Mono和Flux两种类型:
Mono用于表示包含 0 个或 1 个元素的异步数据流(如单个用户信息查询结果);Flux用于表示包含 0 个或多个元素的异步数据流(如列表查询结果)。
一、创建型操作符
1. just(T...)
just操作可直接通过传入的元素创建一个响应式流。其中,Flux 可接收多个元素(0 个或多个),Mono 则仅能接收单个元素(若传入多个会报错,示例中Mono.just("A", "B", "C")为错误示范,正确应为Mono.just("A"))。
java
// 创建包含3个元素的Flux流(可正常运行)
Flux<String> flux = Flux.just("A", "B", "C");
// 正确示例:创建仅包含1个元素的Mono流
Mono<String> mono = Mono.just("A"); 2. fromIterable(Iterable<T>)
fromIterable、fromArray则分别将已有的Iterable类型集合(如List、Set),和数组转换为响应式流,自动遍历集合中的元素并发送到流中。适合需要处理已有数据集合的场景,避免手动逐个添加元素。
java
// fromIterable
List<Integer> list = Arrays.asList(1, 2, 3);
Flux<Integer> flux = Flux.fromIterable(list);
// fromArray
Integer[] arr = {10, 20, 30};
Flux<Integer> flux = Flux.fromArray(arr);
flux.subscribe(System.out::println);3. range(int start, int count)
range则适用于快速生成一段连续的整数流来构建测试用例。其中,第一个参数为起始值,第二个参数为元素个数。
java
Flux.range(1, 5).subscribe(System.out::println); // 输出 1~54. create(FluxSink<T>)
通过FluxSink对象可手动发送元素(next)、结束信号(complete)或错误信号(error),灵活控制流的产生过程。
该API适合用于从异步回调、事件监听中获取数据等场景。
java
// 手动创建流,通过sink发送元素并结束
Flux.create(sink -> {
sink.next("Hello"); // 发送第一个元素
sink.next("WebFlux"); // 发送第二个元素
sink.complete(); // 标记流结束(不再发送元素)
}).subscribe(System.out::println); // 输出:Hello WebFlux二、转换型操作符
1. map(Function<T, R>)
map的操作则主要对流中的每个元素执行指定的转换操作。即输入一个元素,输出一个转换后的元素,保持流的元素数量不变。适合简单的同步转换场景。
java
// 对流中每个字符串执行"转大写"操作
Flux<String> flux = Flux.just("apple", "banana")
.map(String::toUpperCase); // 调用String的toUpperCase()方法
flux.subscribe(System.out::println); // 输出:APPLE BANANA2. flatMap(Function<T, Publisher<R>>)
与map不同,flatMap 则接收一个元素T,返回一个新的响应式流Publisher<R>(如Flux<R>或Mono<R>)。 即整个过程是 "元素→流" 的映射,会将子流 "扁平化" 合并为一个新流,输出流的元素数量可能比输入流多(或少)。
java
// 将每个字符串按字符拆分,转换为包含单个字符的子流,再合并
Flux<String> flux = Flux.just("hello", "world")
.flatMap(s -> Flux.fromArray(s.split(""))); // 拆分后子流为 ["h","e","l","l","o"] 和 ["w","o","r","l","d"]
flux.subscribe(System.out::println);
// 可能输出:h w e o l r l l d(顺序不固定,因两个子流并行处理)举个更实际的例子,如 "一个订单包含多个商品,需要根据订单 ID 查询所有商品" 的场景(1 个订单→多个商品组成的流),或需要在转换中调用异步操作可使用flatMap来进行操作。
less
// 模拟"根据用户ID查询多个订单"的异步操作
Flux.just(1001, 1002) // 用户ID流
.flatMap(userId -> orderService.findOrdersByUserId(userId)) // 每个用户ID→订单流
.subscribe(order -> System.out.println("订单:" + order));3. concatMap(Function<T, Publisher<R>>)
与flatMap类似,concatMap则是将每个元素转换为子流后合并,但严格按照原元素的顺序处理子流(前一个子流完全处理完才会处理下一个),因此最终流的元素顺序与原元素对应的子流顺序一致。适合需要保证顺序的场景(如按顺序处理批量任务)。
java
// 同样拆分字符串为字符子流,但按原顺序合并
Flux<String> flux = Flux.just("hello", "world")
.concatMap(s -> Flux.fromArray(s.split(""))); // 先处理"hello"的子流,再处理"world"的子流
flux.subscribe(System.out::println);
// 固定输出:h e l l o w o r l d(严格遵循原元素顺序)三、过滤型操作符
1. filter(Predicate<T>)
ini
java
Flux<Integer> flux = Flux.range(1, 10).filter(i -> i % 2 == 0);
flux.subscribe(System.out::println);2. distinct()
对流中所有元素进行去重处理,保留首次出现的元素,后续重复元素会被过滤。
scss
java
深色版本
Flux.just(1, 2, 2, 3).distinct().subscribe(System.out::println);3. limitRate(int rate)
控制流从上游数据源获取元素的速率,每次向上游请求 rate 个元素,处理完后再请求下一批,避免一次性加载过多数据导致内存压力(类似 "分批拉取")。常用于流中元素数量极大的场景(如处理百万级数据),平衡内存占用与处理效率。
java
// 生成1~100的整数流,每次从上游获取10个元素后再继续请求
Flux.range(1, 100)
.limitRate(10).subscribe(System.out::println);
// 内部过程:先请求1~10,处理完后再请求11~20,直到所有元素处理完毕四、错误处理操作符
1. onErrorReturn(T fallback)
当流中发生错误(如抛出异常)时,会立即终止原错误流,并返回一个预设的默认值作为流的最终结果,避免错误直接传递到订阅者导致程序中断。
java
// 模拟一个直接抛出异常的流,出错时返回默认值0
Flux<Integer> flux = Flux.error(new RuntimeException("Oops!"))
.onErrorReturn(0); // 异常发生时,用0作为替代结果
flux.subscribe(System.out::println); // 输出:0(而非抛出异常)2. doOnError(Consumer<Throwable>)
当流中发生错误时,会触发传入的消费函数(Consumer),可用于记录错误日志、发送告警等 "副作用操作"。
java
// 模拟一个抛出异常的流,监听错误并打印信息
Flux.error(new RuntimeException("Oops!"))
.doOnError(e -> System.out.println("Error occurred: " + e.getMessage())) // 错误发生时执行打印
.subscribe(
data -> System.out.println("Data: " + data), // 正常数据处理(此处不会执行)
error -> System.out.println("Subscriber caught error") // 订阅者仍会收到错误
);
// 输出:
// Error occurred: Oops!
// Subscriber caught error五、时间控制操作符
1. delayElements(Duration duration)
delayElements主要让流中的每个元素都延迟指定时间后再发射,相当于给每个元素的发送增加一个统一的 "等待期"。
java
// 生成1~3的整数流,每个元素延迟1秒后发送
Flux.range(1, 3).delayElements(Duration.ofSeconds(1))
.subscribe(System.out::println); // 依次间隔1秒输出:1、2、3
Thread.sleep(5000); // 主线程休眠5秒,防止程序提前退出(否则看不到完整输出)2. timeout(Duration timeout)
timeout主要为流设置超时阈值,若流在指定时间内没有发射新元素(或未完成),则会触发超时错误(TimeoutException)。适合需要限制操作响应时间的场景(如接口调用超时控制)。
java
// 生成1~3的整数流,每个元素延迟500毫秒发送,同时设置超时时间为300毫秒
Flux.range(1, 3)
.delayElements(Duration.ofMillis(500)) // 元素发送间隔500ms
.timeout(Duration.ofMillis(300)) // 超过300ms未收到新元素则超时
.subscribe(
System.out::println, // 正常元素处理(此处第一个元素就会超时,不会执行)
Throwable::printStackTrace // 捕获并打印超时异常
);
Thread.sleep(2000); // 主线程休眠,确保异常能被捕获
// 输出:TimeoutException(因第一个元素需500ms发送,超过300ms超时阈值)六、订阅操作符
1. subscribe(Consumer<T>)
subscribe是响应式流的 "启动开关"------ 只有调用该方法,流才会开始发射元素。此重载方法接收一个消费函数(Consumer),用于处理流中发射的每个元素,是最基础的订阅方式。
java
// 创建包含"A"、"B"的流,订阅并打印每个元素
Flux.just("A", "B").subscribe(System.out::println);
// 输出:A(处理第一个元素)、B(处理第二个元素)
// 注:若不调用subscribe,流不会执行任何操作2. doOnNext(Consumer<T>)
在流中的每个元素被发射到订阅者之前,触发指定的消费函数(如日志记录、数据预处理等),但不会改变元素本身或流的结构。
java
// 生成1~3的整数流,发射前打印提示,再将元素发送给订阅者
Flux.range(1, 3)
.doOnNext(i -> System.out.println("Before emit: " + i)) // 发射前执行:打印提示
.subscribe(System.out::println); // 订阅者接收并打印元素
// 输出:
// Before emit: 1 → 发射前操作
// 1 → 订阅者处理
// Before emit: 2
// 2
// Before emit: 3
// 33. doOnComplete(Runnable)
流正常结束(所有元素发射完毕且无错误)时,触发指定的无参任务(Runnable),可用于执行流结束后的收尾操作(如释放资源、打印完成日志等)。
java
// 创建包含1、2的流,完成时打印"Done",并订阅(无需处理元素,仅触发完成回调)
Flux.just(1, 2)
.doOnComplete(() -> System.out.println("Done")) // 流正常结束时执行
.subscribe(); // 订阅启动流
// 输出:Done(当1和2都发射完毕后,触发完成回调)更多操作可参考如下表格:
| 操作符 | 类型 | 描述 |
|---|---|---|
just, fromIterable, empty, range, generate, create |
创建 | 构建流 |
map, flatMap, concatMap, switchMap, buffer, window |
转换 | 映射或拆分 |
filter, take, skip, distinct, limitRate |
过滤 | 控制元素 |
mergeWith, concatWith, zipWith, combineLatest |
组合 | 合并流 |
onErrorResume, onErrorReturn, doOnError |
错误处理 | 异常捕获 |
delayElements, timeout |
时间控制 | 延迟/超时 |
defaultIfEmpty, hasElement, all, any |
条件逻辑 | 判断 |
reduce, collect, count |
聚合统计 | 计算 |
subscribe, doOnNext, doOnComplete |
副作用 | 监听 |
log, checkpoint |
日志 | 调试 |
调用实践
在深入剖析完WebFlux相关 API,对其异步非阻塞特性及响应式编程模型有了清晰认知后,为进一步巩固理解并探索其实践边界,我们将借助Trae搭建一款基于WebFlux的远程调用框架。
框架整体调用逻辑如下:
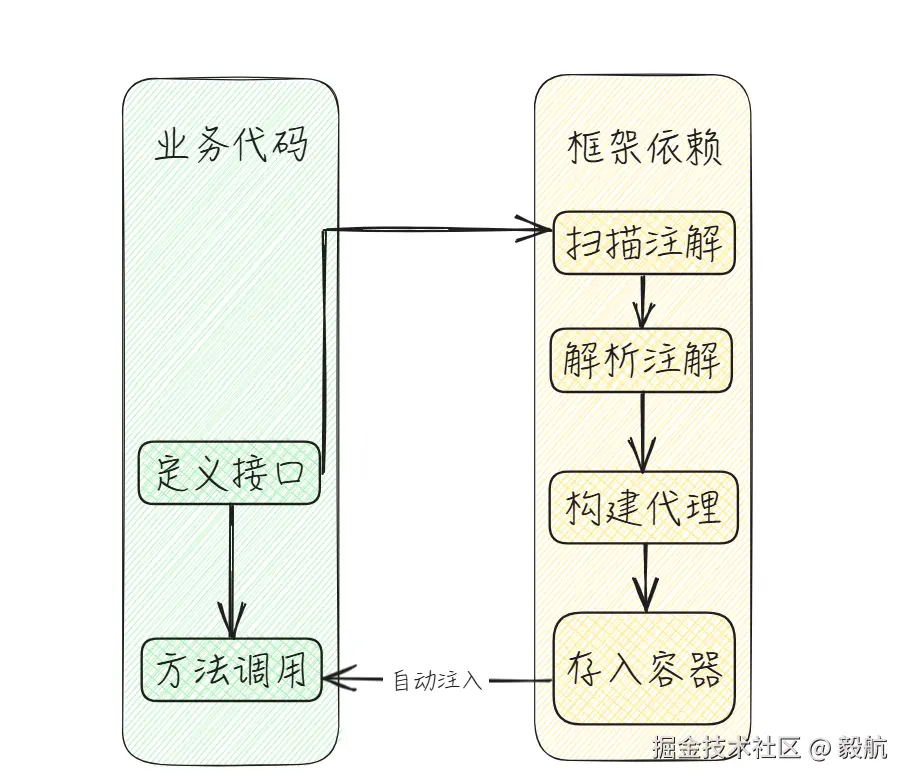
在设计过程中,我们主要借鉴@FeignClient远程调用的原理,首先定义一个@FeignWebFlux用以标注到接口上,然后我们的框架自动解析标有@FeignWebFlux的注解,并生成代理类,进而底层通过WebFlux来实现对服务的远程调用。
我们整个项目结构如下:
web-flux-remote-client:定义远程调用注解,并完成相关注解代理类的构建client-consumer: 客户端消费者client-provider: 客户端服务提供者
注解构建
依据我们之前描述,我们首先需要定义一个@FeignWebFlux的注解,此处我们借助Trae来实现。
此处,Trae的思考过程还是比较完善的,其对@FeignClient注解的理解基本是到位的,给出的代码也是比较详细的,但其中的fallback,fallbackFactory等其实我们本次并不需要,所以对于其给出的代码,我们优化后代码如下。此次,我们仅保留url相关配置。
java
package org.webflux.remote.client.annotation;
import java.lang.annotation.*;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface FeignWebFlux {
/**
* 直接指定服务URL,优先级高于value
*/
String url() default "";
/**
* 所有方法的基础路径前缀
*/
String path() default "";
}在完成基础注解定以后,如果想实现对标有@FeignWebFlux的类实现代理,则需要我们扫描其对应包路径,而为了实现这一逻辑,通常我们会定义一个@Enablexxx的注解,然后借助 ImportBeanDefinitionRegistrar这一扩展点来实现。
java
package org.webflux.remote.client.annotation;
import org.springframework.context.annotation.Import;
import org.webflux.remote.client.register.FeignWebFluxRegistrar;
import java.lang.annotation.*;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import(FeignWebFluxRegistrar.class) // 导入扫描注册器
public @interface EnableFeignWevFluxClients {
String[] basePackages() default {};
}在EnableFeignWevFluxClients注解内容,我们参照自动注入的原理,通过@Import注入我们自定义的Bean扫描器。
java
public class FeignWebFluxRegistrar implements ImportBeanDefinitionRegistrar, EnvironmentAware{
private Environment environment;
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
// 1. 获取@EnableFeignWevFluxClients(扫描路径)
String[] basePackages = (String[]) importingClassMetadata.getAnnotationAttributes(EnableFeignWevFluxClients.class.getName())
.get("basePackages");
if (basePackages.length == 0) {
// 默认扫描启动类所在包
String defaultPackage = ClassUtils.getPackageName(importingClassMetadata.getClassName());
basePackages = new String[]{defaultPackage};
}
// 2. 扫描指定包下所有标注@WebFluxClient的接口
ClassPathScanningCandidateComponentProvider scanner = this.getScanner();
scanner.addIncludeFilter(new AnnotationTypeFilter(FeignWebFlux.class)); // 只扫描带@WebFluxClient的接口
for (String basePackage : basePackages) {
Set<BeanDefinition> candidateComponents = scanner.findCandidateComponents(basePackage);
for (BeanDefinition beanDefinition : candidateComponents) {
if (beanDefinition instanceof AnnotatedBeanDefinition) {
AnnotatedBeanDefinition annotatedBeanDefinition = (AnnotatedBeanDefinition) beanDefinition;
AnnotationMetadata metadata = annotatedBeanDefinition.getMetadata();
// 只处理接口
if (metadata.isInterface()) {
registerFeignClient(registry, metadata);
}
}
}
}
}
protected ClassPathScanningCandidateComponentProvider getScanner() {
return new ClassPathScanningCandidateComponentProvider(false, this.environment) {
@Override
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
boolean isCandidate = false;
if (beanDefinition.getMetadata().isIndependent() && !beanDefinition.getMetadata().isAnnotation()) {
isCandidate = true;
}
return isCandidate;
}
};
}
// 注册FeignWebFlxu客户端(通过工厂Bean生成代理)
private void registerFeignClient(BeanDefinitionRegistry registry, AnnotationMetadata metadata) {
String className = metadata.getClassName();
// 构建工厂Bean的定义:FeignWebFluxClientFactoryBean
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition(FeignWebFluxClientFactoryBean.class);
builder.addPropertyValue("type", className); // 接口类型
// 注册BeanDefinition(Bean名称为接口全类名)
registry.registerBeanDefinition(className, builder.getBeanDefinition());
}
@Override
public void setEnvironment(Environment environment) {
this.environment = environment;
}
}远程调用工具构建
我们此处所定义的@FeignWebFlux其会接收到远程调用的地址信息,在接收到地址信息后,我们底层则WebClient来实现远程服务调用。
java
public class WebClientRestHandler implements RestHandler {
private WebClient webClient;
@Override
public void init(ServerInfo serverInfo) {
this.webClient = WebClient.create(serverInfo.getUrl());
}
@Override
public Object invokeRest(MethodInfo methodInfo) {
// 参数校验
if (methodInfo == null) {
return Mono.error(new IllegalArgumentException("MethodInfo must not be null"));
}
if (methodInfo.getHttpMethod() == null) {
return Mono.error(new IllegalArgumentException("HttpMethod must not be null"));
}
if (methodInfo.getUrl() == null || methodInfo.getUrl().trim().isEmpty()) {
return Mono.error(new IllegalArgumentException("Url must not be empty"));
}
checkWebClientInitialized();
WebClient.RequestBodyUriSpec methodSpec = webClient.method(methodInfo.getHttpMethod());
// 构建URI(支持路径参数和查询参数)
methodSpec.uri(uriBuilder -> {
if (methodInfo.getParams() != null && !methodInfo.getParams().isEmpty()) {
return uriBuilder.path(methodInfo.getUrl())
.build(methodInfo.getParams());
} else {
return uriBuilder.path(methodInfo.getUrl())
.build();
}
});
// // 构建URI(支持路径参数和查询参数)
// methodSpec.uri(uriBuilder -> {
// // 处理路径参数
// if (methodInfo.getParams() != null) {
// uriBuilder = uriBuilder.path(methodInfo.getUrl()).build(methodInfo.getParams());
// } else {
// uriBuilder = uriBuilder.path(methodInfo.getUrl());
// }
// // 处理查询参数(如果MethodInfo支持)
// if (methodInfo.getQueryParams() != null && !methodInfo.getQueryParams().isEmpty()) {
// methodInfo.getQueryParams().forEach(uriBuilder::queryParam);
// }
// return uriBuilder.build();
// });
// 设置请求体
WebClient.ResponseSpec responseSpec;
if (methodInfo.getBody() != null) {
responseSpec = methodSpec
.contentType(MediaType.APPLICATION_JSON)
.body(methodInfo.getBody(), methodInfo.getBodyElementType())
.accept(MediaType.APPLICATION_JSON)
.retrieve();
} else {
responseSpec = methodSpec
.accept(MediaType.APPLICATION_JSON)
.retrieve();
}
// 处理HTTP错误状态码
responseSpec = responseSpec.onStatus(HttpStatus::isError, clientResponse ->
clientResponse.bodyToMono(String.class)
.flatMap(errorBody -> Mono.error(
new WebClientResponseException(
clientResponse.statusCode().value(),
"Request failed with status code: " + clientResponse.statusCode(),
clientResponse.headers().asHttpHeaders(),
errorBody.getBytes(),
null
)
))
);
// 处理响应类型并统一异常处理
if (methodInfo.isReturnFlux()) {
return responseSpec
.bodyToFlux(methodInfo.getReturnElementType())
.onErrorResume(e -> Flux.error(convertException(e)));
} else {
return responseSpec
.bodyToMono(methodInfo.getReturnElementType())
.onErrorResume(e -> Mono.error(convertException(e)));
}
}
// 异常转换辅助方法
private Throwable convertException(Throwable e) {
if (e instanceof WebClientResponseException) {
return e;
}
return new RuntimeException("Remote service invocation failed: " + e.getMessage(), e);
}
// WebClient初始化检查
private void checkWebClientInitialized() {
if (this.webClient == null) {
this.webClient = WebClient.builder().build();
}
}
}此处值得注意的是,Trae在构建代码时,出现了两个问题
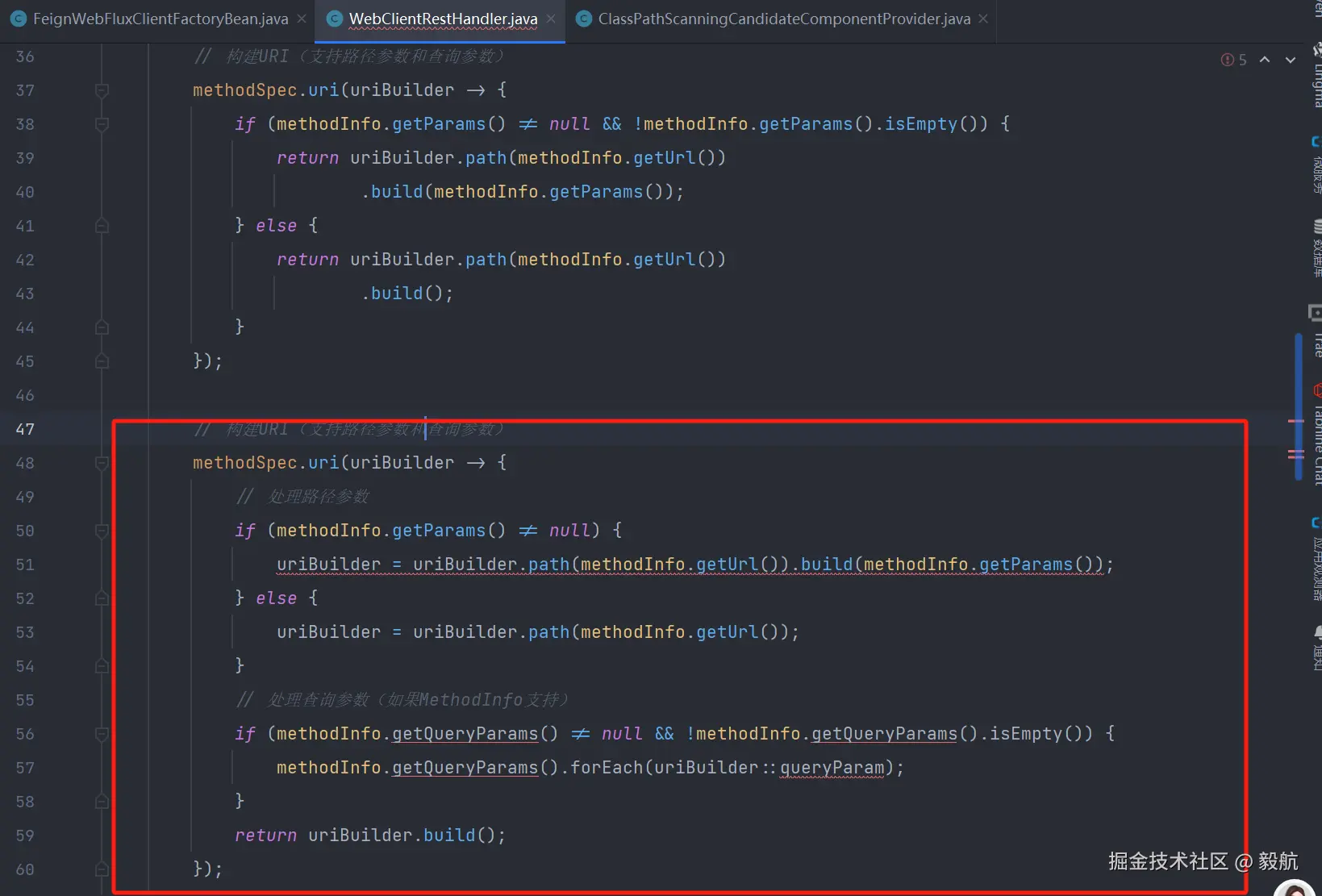
问题1:在使用UriBuilder参数时,其中的build方法方法其实是会返回URL的类型,对于返回的URL则不能继续在进行构建,所以代码47行会报错。
问题2: Trae在构建代码时,对于已经提供形参的方法,其貌似并不会读取形参中的变量信息,而是会根据自己的思考,假设其中有某些变量,这一点需要多轮对话来解决。
代理构建
实现了注解的以及底层网络调用的构建,下一步则是对于@FeignWebFlux注解所标注类代理的构建。
java
public class JdkDynamicAopProxy implements ProxyCreator{
RestHandler restHandler = new WebClientRestHandler();
@Override
public Object createProxy(Class<?> type) {
// 抽取服务器信息
ServerInfo serverInfo = extractServerInfo(type);
log.info("serverInfo :{}", serverInfo);
// 初始化服务器信息(webClient)
restHandler.init(serverInfo);
return Proxy.newProxyInstance(this.getClass().getClassLoader(), new Class[]{type}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 抽取所有请求信息封装到 MethodInfo 对象
MethodInfo methodInfo = extractMethodInfo(method, args);
log.info("methodInfo :{}", methodInfo);
// 调用Rest客户端 处理请求
return restHandler.invokeRest(methodInfo);
}
// .... 省略其他代码此处,借助JDK的动态代理,生成对应的代理来,然后借助之前我们构建的WebClientRestHandler完成远程调用。
详细代码可参考:https://gitee.com/ThanksCode/webflux-remote-client
总结
我们首先对WebFlux的出现背景进行了剖析,接着对WebFlux中常用的Api进行了总结。
在此基础上,我们仿照@Fegin构建一个自定义的@FeignWebFlux注解,自定义了一套异步调用注解,以加深对WebFlux以及Fegin原理的理解。