一、为什么要有string类
其实在C语言阶段我们学过char类型,所以在当时我们认为字符串就是多个char,而且在<string.h>中我们学习了一大堆strcpy、strlen等函数的使用和实现,这还不够用吗?只能说确实在当时符合我们的需求,但是对于我们的面向对象OOP来说,C的字符串和函数操作其实根本可以说没什么关联。string类中有char*数组来管理数据,并且有一系列方法,比如像是length和size都与strllen类似,除了这种函数,还有运算符重载的\[\],<<,>>等更符合面向对象,使用起来更加方便。
string类基本上和容器相似,可以说就是字符类型的容器。
二、标准库的string类
由于这是我们学习的第一个STL的容器,所以大致讲一下怎么学习:对于整个STL来说,我们学习里面的东西就要做到三个境界,第一个境界:会用STL;第二个境界:会模拟实现STL;第三个境界:能给STL增加内容;当然,我们现在只需要做到前两个阶段,一个是会用,一个是了解原理,用起来更加得心应手。至于最后一个境界,等自己真的非常nb再实现。
对于第一个境界,我们需要读标准库中关于string类的一系列函数,毕竟用string类的重点就是会用常用函数。包括但不仅限于构造、析构、push、pop等。
1.学习对象

还是在Reference - C++ Reference这个网站,我们要学的就是第一行的string,这个string类里存储的就是我们学习的char类型,至于几个string类的区别,就不多讲了。

使用string类需要包含头文件<string>,如果平常学习的情况下也得展开命名空间。
其实底层来说string类也是一个模板的实现,只不过可以看出来string类型存储的就是char。
多的不说,其实大致意思就是,string类可以用来实现字符串,并且支持STL中容器一样的接口。
2.string类对象构造和析构函数
①构造函数
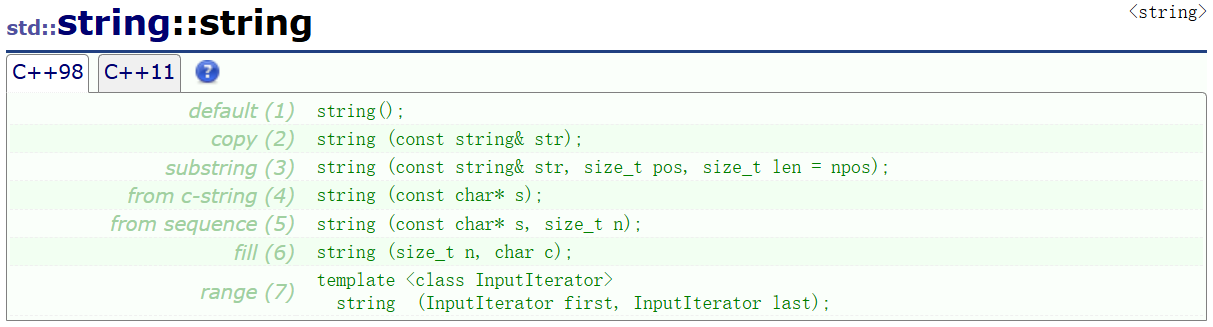
- 第一个构造函数是无参的默认构造函数,只是创建了个string的对象,不存储任何数据
- 第二个构造函数是拷贝构造函数,因为参数的类型是string,用一个已经存在的对象初始化另一个对象
- 第三个构造函数前写着substring,第一个参数还是string类型的参数,这个函数实际上是截取这个str字符串,从哪开始,多长用后两个参数规定

这个稍微复杂一点,就单独拿出来说一说。
第一个参数还是一个string类型的字符串,只不过拷贝的是一部分,copies the portion,从pos开始,持续多长呢,持续len这个参数的长度。
括号里面的意思是如果传的字符串相比于要求的len不够长,或者len非常大,那就从pos位置直接全部拷贝。

后半句将string::npos翻译成非常大的原因是,size_t代表无符号整数,就按照32位操作系统,那么size_t就是4个字节。
-1原码是10000000 00000000 00000000 00000001
反码就是11111111 11111111 11111111 11111110
补码就是11111111 11111111 11111111 11111111
而将这个补码赋值给size_t类型,很明显就是无符号整型所能存储的最大值。
这个数值是:

哪个字符串能让你拷贝42亿快43亿的长度,所以就将这个默认长度定义为无限长,也就是如果不传拷贝多长,默认直接拷贝到字符串末尾。
- 第四个函数是通过常量指针的方式访问并拷贝字符串,至于写个from C-string很简单,因为我们C语言管理字符串的方式基本上可以说都是数组,也就是通过指针来处理
- 第五个函数,光看参数其实屁都看不出来,所以还是详解

读几遍,根据语法分析,那就是拷贝s指向的字符串,拷贝前n个字符。
- 第六个函数前写的fill,简单来说就是填充

将字符串初始化为用字符c连续填充n个。
当然,第一次学,基本一个一个看了,其它的就不再学,但是也不要求全部掌握,重点需要掌握:
|------------------------------|-----------------------|
| string() (重点) | 构造空的string类对象,即空字符串 |
| string(const char* s) (重点) | 用C-string来构造string类对象 |
| string(size_t n, char c) | string类对象中包含n个字符c |
| string(const string&s) (重点) | 拷贝构造函数 |
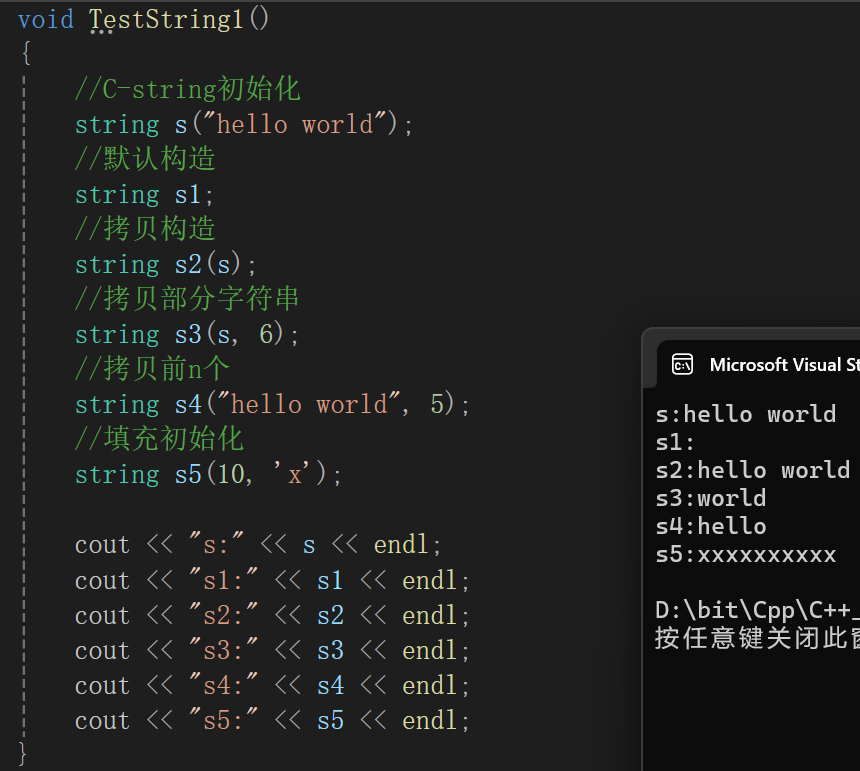
测试上面弄过的所有构造函数:
cpp
void TestString1()
{
//C-string初始化
string s("hello world");
//默认构造
string s1;
//拷贝构造
string s2(s);
//拷贝部分字符串
string s3(s, 6);
//拷贝前n个
string s4("hello world", 5);
//填充初始化
string s5(10, 'x');
cout << "s:" << s << endl;
cout << "s1:" << s1 << endl;
cout << "s2:" << s2 << endl;
cout << "s3:" << s3 << endl;
cout << "s4:" << s4 << endl;
cout << "s5:" << s5 << endl;
}
int main()
{
TestString1();
return 0;
}
毋庸置疑。
②析构函数
只要出了作用域自动调用,也就是说不用管析构的事,只管构造和使用即可。
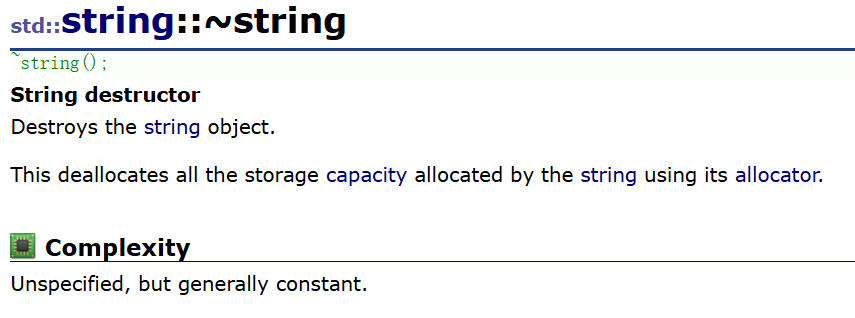
我还是想提一下库里面这个复杂度这句话啥意思,unspecified没有指定的,没有具体说明的,后半句又说但是基本上不变。简单点说就是复杂度没有说就是多少,但是基本什么情况下复杂度都是一样的,也就是说,析构一万个string对象和一个,所用时间基本也差不了多少,很稳定。
③operator= 重载
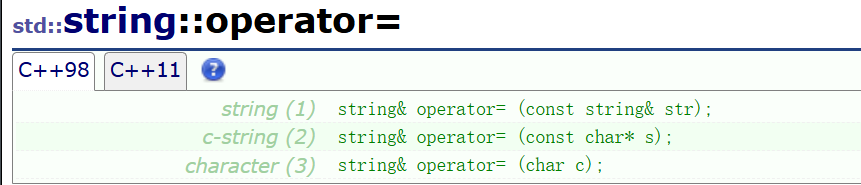
可以赋string对象,可以赋常量字符串,可以赋字符。
刚学过构造函数,这就不多介绍了。
3.string类对象访问与遍历函数
①operator \[\]重载
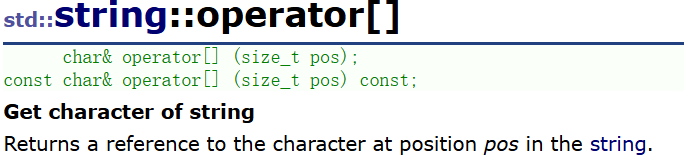
给下标,最后返回pos位置的字符的引用,所以用来访问和遍历都是可以的。当然,const版本的重载用于const字符串,因为毕竟有的字符串就是常量字符串,如果只有第一行的重载,那么访问const对象就会权限的扩大,不过用起来不说个啥。
用类似于字符数组的访问方式就可以访问string对象。

也可以改变:
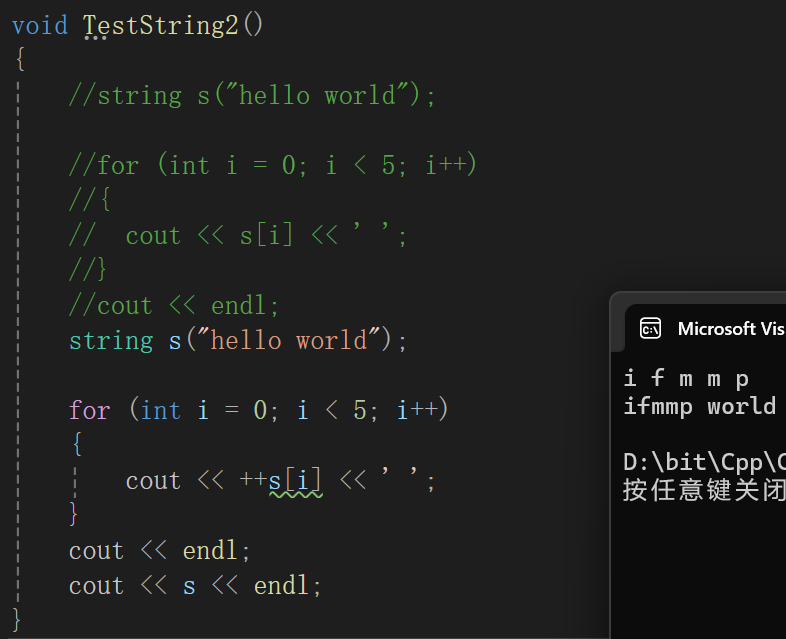
底层存的ASCII码,就当成ASCII码++就行。
没啥可多讲的,当成字符数组用就行,只要不破坏const。
②使用迭代器访问
interator迭代器
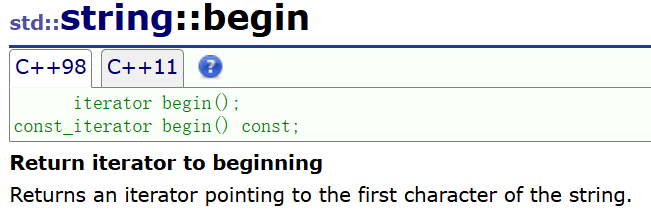

目前阶段就把这俩玩意类比指针来用,但是迭代器可不一定是指针。
一般来说迭代器是这么用的[begin,end),原因很简单:
 end的介绍中指明,end所指的元素是最后一个有效元素的下一个元素,它说的是theoretical,是人话就是其实本来按说你给的容器里不可能有这元素,end指向的是内存上的下一个元素,逻辑上没有这个元素。
end的介绍中指明,end所指的元素是最后一个有效元素的下一个元素,它说的是theoretical,是人话就是其实本来按说你给的容器里不可能有这元素,end指向的是内存上的下一个元素,逻辑上没有这个元素。
这也就是为什么说迭代器用的时候是左闭右开的,并且容易知道,容器的接口都是类似的,只要有这次的经验,以后再用就非常方便了。
测试代码:
cpp
void TestString2()
{
//string s("hello world");
//for (int i = 0; i < 5; i++)
//{
// cout << s[i] << ' ';
//}
//cout << endl;
//[] + 下标
string s("hello world");
for (int i = 0; i < 5; i++)
{
cout << ++s[i] << ' ';
}
cout << endl;
cout << s << endl;
//迭代器
string::iterator it1 = s.begin();
while (it1 != s.end())
{
(*it1)--;
it1++;
}
cout << s << endl;
}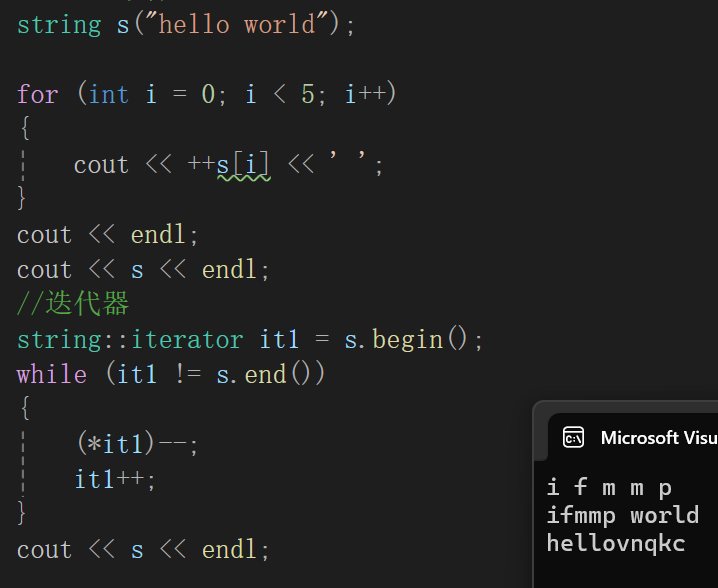
为了展现出迭代器确实也可以用来访问和修改,在上面用\[\]+下标++修改的前提下用迭代器遍历--,可以看到hello被还原。
这里的重点就是iterator是string类中的类,需要实例化对象才能使用,初始化为begin函数,而且begin函数是在string类中定义的,至于while条件用的就是迭代器使用左闭右开的道理。
迭代器是所有容器主流遍历和修改的方式,目前阶段只能说带着背的心去看待,毕竟这玩意牵扯到内部类,而且这个内部类接收的还是外部类函数的返回值,只能先记住。
另外对于这个string类的迭代器我还得再强调一下,我上面已经强调过了,begin指向的是数据开始位置,end指向的是有效数据的下一个位置,原理大概与数组的下标理解方式差不多,数组下标早已说过,为什么说数组第一个元素是0访问这么反人类的事,因为\[\]+下标实质上是*(指针+偏移量),所以才会有0,size - 1这个区间,这里size个数据你只能最多访问到size -1 ,而这里最后的end你不是也访问不到嘛。
再来就是看一下指向:
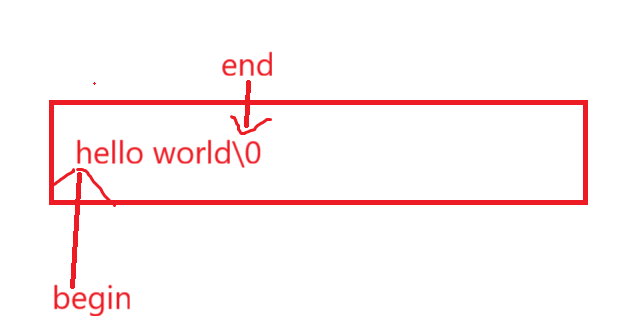
如果end指向\0,那么刚好就能把所有的字符串有效元素访问完又不遗漏,简单来说\0不是作为字符串结束的标志嘛,就不算他是有效元素了,end指向的是有效元素后第一个元素,自然就是指向\0了。
③范围for C++11开始支持的语法
auto关键字
在正式用范围for来遍历的前,还得补充一下C++11中auto的知识:
- auto可以代替int、char等定义变量,在编译时编译器会根据初始化内容推导出变量类型
很简单,int double啥的咋弄,你就咋弄就行:

auto估计取得就是automatic,对于程序员来说,确实自动识别了,毕竟编译器代人受过嘛。
- 同一行声明多个变量时,必须保证这些变量都是同一个类型,否则会编译报错。因为本质上编译器会根据第一个值推导出来类型再定义同行其它变量,如果不一致,难道还指望编译器再来个隐式类型转换吗

- auto不能用来声明数组

- auto类型不能做函数参数,可以做函数返回值,但是需要谨慎使用
- auto和auto*都可以代表指针,但是如果是引用的话就必须加&

看了这么多auto,多少应该看出来点门道了,这个auto就是读初始化内容是啥类型的,然后缺啥补啥。
但是对于引用来说,不能这么干,毕竟用引用传值的情况多的是:
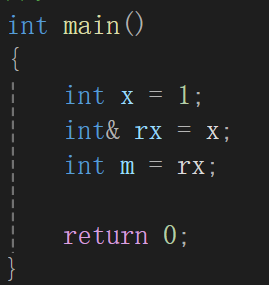
用引用赋值没啥毛病,如果改为auto道理也是一样的:

所以要是引用你可就得明确写出来引用:

范围for
好的,有了auto关键字就方便了,范围for还可以遍历数组,先用数组见识一下:
cpp
int main()
{
int arr[] = { 1,2,3,4,5 };
//C语言常用遍历数组手段
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
cout << arr[i] << ' ';
}
cout << endl;
//范围for遍历数组
//自动传数组arr2的值给e
//自动迭代
//自动判断结束
for (auto e : arr)
{
cout << e << ' ';
}
cout << endl;
return 0;
}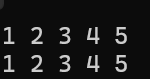
结果很简单。
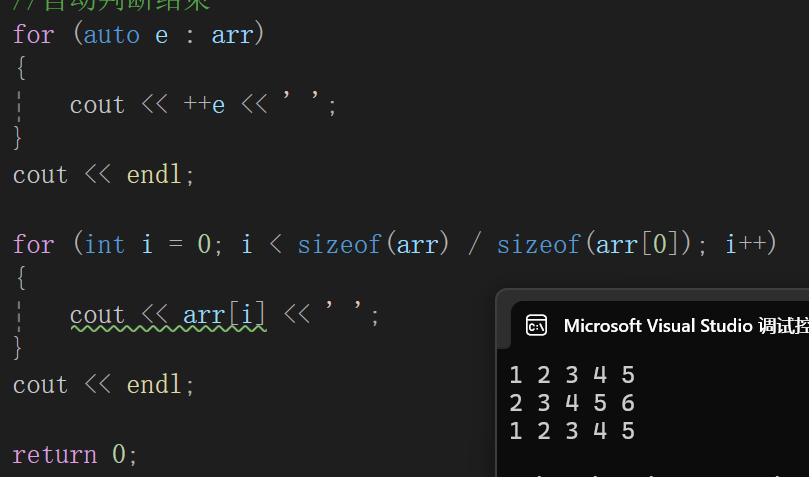
另外,底层这玩意可以说是换成迭代器,也就是每次相当于用迭代器把*it赋值给e,也就是auto e = *it,所以这段代码可以说是不触及原数组的根基:
cpp
int main()
{
int arr[] = { 1,2,3,4,5 };
//C语言常用遍历数组手段
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
cout << arr[i] << ' ';
}
cout << endl;
//范围for遍历数组
//自动传数组arr2的值给e
//自动迭代
//自动判断结束
for (auto e : arr)
{
cout << ++e << ' ';
}
cout << endl;
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
cout << arr[i] << ' ';
}
cout << endl;
return 0;
}
学习了引用,而且是auto的引用以后,这个事就好说了,直接把参数改成引用就完了:

最后再提一下,类型只要能对应的上就行,比如这里改为:
cpp
for (int& e : arr)
{
cout << ++e << ' ';
}
cout << endl;但是一般能顺手的事,谁愿意动脑子,所以范围for一般和auto就是绑的。
见识一下范围for遍历string类:
cpp
void TestString2()
{
//string s("hello world");
//for (int i = 0; i < 5; i++)
//{
// cout << s[i] << ' ';
//}
//cout << endl;
//[] + 下标
string s("hello world");
for (int i = 0; i < 5; i++)
{
cout << ++s[i] << ' ';
}
cout << endl;
cout << s << endl;
//迭代器
string::iterator it1 = s.begin();
while (it1 != s.end())
{
(*it1)--;
it1++;
}
cout << s << endl;
//范围for
for (auto& e : s)
{
cout << ++e;
}
cout << endl;
}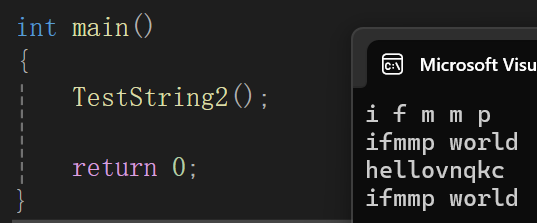
加了个范围for引用++,就把迭代器的--抵消了,符合预期。
4.string类对象的迭代器
迭代器的意义之一已经说过了,那就是用于多个容器的遍历和修改。
对于string的迭代器,毕竟这是我们STL学的第一个容器吧可以说是,所以还是把库里面的过一过:
①迭代器重载
有这么多迭代器,当然,都是成对的,那些end更像是哨兵位,预示着遍历的末尾。
重点我还是想说一下函数重载的问题,const版本的迭代器怎么理解?
const_iterator可不是const iterator,把这个看清基本就能懂了,为什么这么说呢?
const iterator等于限制住了迭代器的指向,上面我们把迭代器当成类似于指针用的东西,指针如果不能移动,那还要它干鸡毛。
const_iterator重点是让iterator指向的内容不能变,基于此这两个版本的迭代器就可以理解了:
cpp
void TestString3()
{
string s1("123456");
const string s2("123456");
string::iterator it1 = s1.begin();
while (it1 != s1.end())
{
cout << ++(*it1) << ' ';
it1++;
}
cout << endl;
//string::iterator it2 = s2.begin();
string::const_iterator it2 = s2.begin();
while (it2 != s2.end())
{
//(*it2)++;
cout << *it2 << ' ';
it2++;
}
cout << endl;
}
int main()
{
//TestString2();
TestString3();
return 0;
}

②反向迭代器
reverse iterator,怎么说呢这玩意,重载还是跟普通迭代器一样,一个非const版本的,一个const版本的,所以不再展示。
重点就在于反向这个玩意,简单来说:
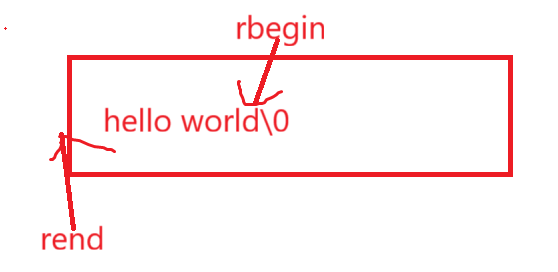
就好像古代字和现代字的语序一样,古代字比如说对联的横批之类的都是从右到左写的,反向迭代器也是如此,rbegin指向的是\0前的元素,rend指向的是第一个元素前的位置,而且:
cpp
void TestString3()
{
string s1("123456");
const string s2("123456");
string::iterator it1 = s1.begin();
while (it1 != s1.end())
{
cout << ++(*it1) << ' ';
it1++;
}
cout << endl;
//string::iterator it2 = s2.begin();
string::const_iterator it2 = s2.begin();
while (it2 != s2.end())
{
//(*it2)++;
cout << *it2 << ' ';
it2++;
}
cout << endl;
string::reverse_iterator rit1 = s1.rbegin();
while (rit1 != s1.rend())
{
cout << *rit1 << ' ';
rit1++;
}
cout << endl;
}
主要连++的方向都认为是从右到左了,因为s1和反向遍历的s1分别是第一行和第三行,这个需要注意,再来就是调反向迭代器要用reverse_iterator实例化对象接收返回值。
③cbegin/cend和crbegin/crend
这两组点一下就行了:
cbegin这一对其实返回值还是const_iterator,但是上面我们写的用begin返回个const对象可能不是那么好看吧可以说是,反正实现const就行了。
crbegin这组更不用多说:

看一眼就不用多说了。
④迭代器的意义
为啥要费劲讲这么多这个迭代器呢?
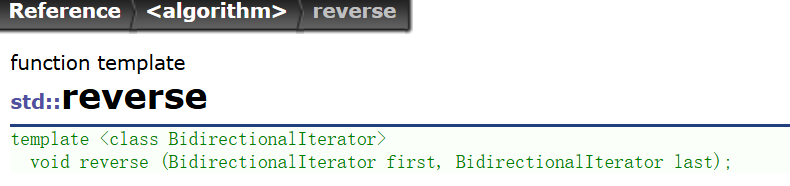
上图是算法这个头文件里的一个函数,这个函数的两个参数就是迭代器的起始和末尾,其实也很好理解,reverse这个方法要的就是区间嘛。
也就是说除了用来遍历和修改以外,迭代器还可以使算法脱离底层结构,与底层结构解耦。
怎么说呢,因为这个算法其实是一个函数模板,可以说你传什么类型的迭代器,他就会创建出来什么函数去reverse,而这个算法实际上可以针对多个容器,可不是说跟你C语言阶段写的swap函数一样,类型不对就炸了,其实这里就可以说是模板最好的体现。
算法可以说是独立出来的一个模块,想不到什么好的修饰了,说难听点,就像是厕所的纸一样,放到那谁都能用,当然,这么说有点恶心,或者说是共享单车之类的吧,这些玩意可不是看人下菜碟啊。
5.string类对象的容量操作

讲的时候不按顺序讲。
①size
返回字符串的有效字符长度。
其实这个函数可以说是非常经典的了,我们用C语言学习数据结构的时候,基本上每一个数据结构都会扯上size,有效数据个数嘛。
经典用法:
cpp
void TestString4()
{
string s1("hello world");
for (int i = 0; i < s1.size(); i++)
{
cout << s1[i] << ' ';
}
cout << endl;
}②length
返回字符串的有效字符长度
其实这个函数跟size可以说是一模一样,就这么说吧,底层实现原理都完全一样,那为什么还要有length的存在呢?
这个可以说就有点历史遗留问题的锅了,如果将string归为容器的话,string可以说是STL第一个容器了,字符串你说有效元素个数用长度length起名有啥问题,但是后来什么vector、list都有了,它们的有效元素个数的接口都是size,那所以string就多加了size去保证接口一致,为啥这个length还不删呢?
道理很简单,语法的增加容易,删减可就不那么容易了,就比如你在出size这个函数前就写了一个超级大的程序,运行的好好的,你后续版本不兼容length了,导致我的程序出现了一系列的bug,谁担当的起,所以一般语法都是向前兼容的,也就是以前的功能还能继续用,只不过新加了点功能而已。
③max_size
标准库对返回值的介绍就是返回字符串能到达的最大长度,但是实际上这个接口是无意义的。
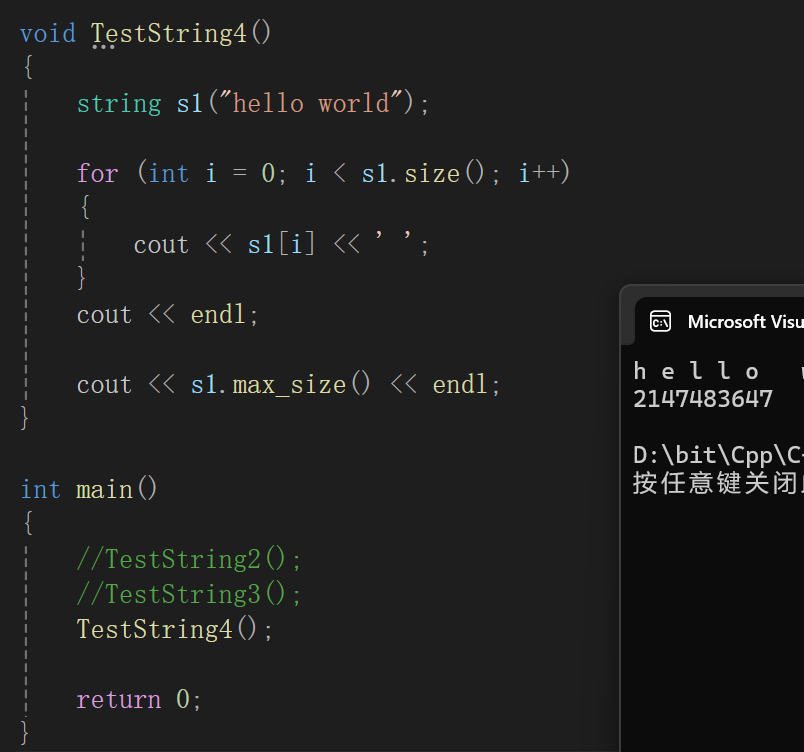
我就问你,一个21亿多的数据,21亿多的字符,一个字符一个字节的话,基本上两个G的内存了,这可是32位下算的啊,32位基本上也就4个G的内存,这么算起来的话,一半多内存都得用来在栈区上创建这个字符,但是实际上堆区上哪弄两个多G,所以还是少白日做梦了,因此这个mac_size接口可以说没屁用。
④capacity
返回空间总大小
我们自定义类型的对象不就是在堆区上申请的嘛,看看此次开辟内存空间大小总是合理的。
强调:
size和capacity的返回值均不包含\0,其实不包含也说的过去,包含也说的过去,STL设计者没包含咱们用的时候注意一下就行。
重点就是内存的开辟,下面写段代码使得内存开辟清晰可见,当然,不同平台怎么扩,扩多少,我们不多说,不同编译器的行为,不同版本的编译器都是说不准的。
cpp
void TestString4()
{
string s1("hello world");
for (int i = 0; i < s1.size(); i++)
{
cout << s1[i] << ' ';
}
cout << endl;
cout << s1.max_size() << endl;
cout << s1.capacity() << endl;
string s2;
int old = s2.capacity();
cout << "capacity:" << old << endl;
for (int i = 0; i < 100; i++)
{
s2.push_back('x');
if (s2.capacity() != old)
{
cout << "capacity:" << s2.capacity() << endl;
old = s2.capacity();
}
}
}
直接说结论:除了第一次,后面都是1.5倍扩容,当然,由于不都是偶数,有时候1.5倍扩肯定存在取整,大致就是这么多倍数。
⑤clear
清空所有有效字符

没啥可多说的
⑥empty
判断字符串是否为空串,是返回empty,否返回false
也没啥可说的,也不测试代码了。
⑦shrink_to_fit

这个函数是用来缩容的,即你觉得开辟的空间太大了,索性减少点。
因为正常情况下是不会随便缩容的:

为了体现缩容随便加点字符,一般不缩容的原因其实也好说,C语言阶段我们写顺序表或者栈(底层用顺序表实现),写pop方法可不是真的把存起来的数据删去了,而是直接size--,访问不到就算了,这里底层基本也是这样的道理。
而在前面学内存管理时我们已经多次见识过了,不要对一块空间多次释放,不要从开辟的内存中间释放内存,所以缩容缩容,其实是开辟一段fit的内存大小,再复制剩下的有效数据,最后释放源内存空间,这样看来这个缩容的代价其实还是挺大的,所以一般不缩容。
其实这个缩容基本上用的是时间换空间的思想。
⑧reserve
为字符串预留空间

先来看测试代码,很明显,调用reserve后发生了扩容,但是为什么扩容的capacity比我们给的参数大呢?
读读标准库可以得知:

它会有行为给你扩到n的大小,但是也可能会更大,底层总归会存在内存对齐之类的问题,所以扩的刚刚好还是更大,取决于环境。
另外,reserve也可用来缩容,但是缩容的行为是不具有强制性的non-binding。
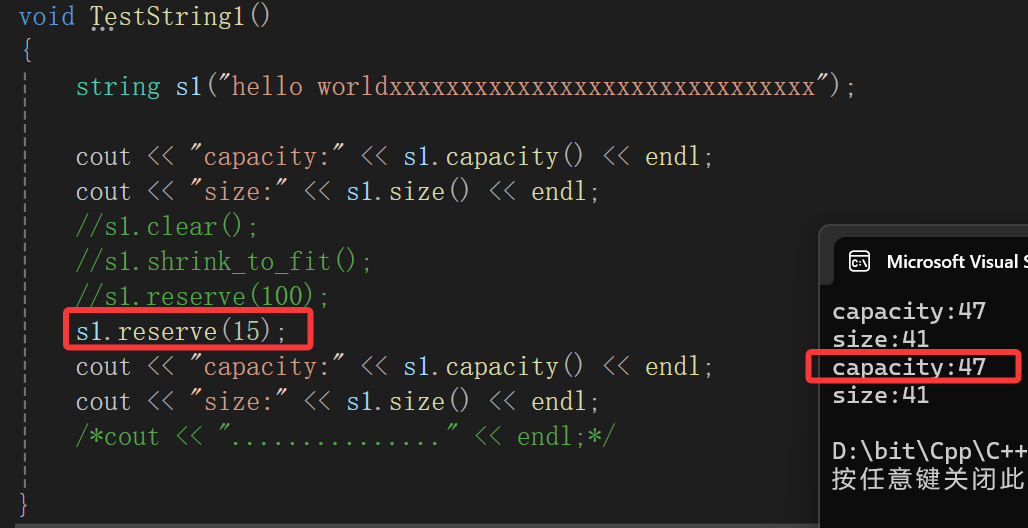
不可能说丢弃有效数据去缩到更小的空间的,真想缩容就用shrink那个方法去。
这个函数最大最大的优点就是避免频繁的扩容,因为我们有realloc的经验,扩容这个事可不是一蹴而就的,有的时候如果原地盘扩张不够的话,那么就需要开辟新空间-复制-释放原空间。有了reserve以后,可以给一个数字,可能到时候开的比你给的数字大,但是绝对会让你够用,避免频繁扩容才是最大的优点。
⑨resize
resize修改有效数据size(如果需要也会修改capacity)
这次先读文档吧,情况有点小复杂:

改变string的长度到我们给的n个字符,当然,这个修改的是size有效数据个数。
如果n<size,string length就是size嘛,那么就会缩至前n个字符,remove是删,删去第n个字符后的所有字符;
如果n > size,那么现在就会在string后插入足够的字符直到使size达到n,当然,这个字符可以用过第二个参数来指定尾插什么字符,如果不指定字符,那将会用第一个重载函数,假如没有指定字符,就用value-initialized char,值是第一个的字符,值是第一个的不就是0嘛,等于用\0去填充去了。
测试代码:
cpp
void TestString2()
{
string s1("123456");
cout << s1 << endl;
cout << "capacity:" << s1.capacity() << endl;
cout << "size:" << s1.size() << endl;
//n > capacity > size
s1.resize(40, 'x');
cout << s1 << endl;
cout << "capacity:" << s1.capacity() << endl;
cout << "size:" << s1.size() << endl;
//capacity > n > size
s1.resize(45, 'x');
cout << s1 << endl;
cout << "capacity:" << s1.capacity() << endl;
cout << "size:" << s1.size() << endl;
//size < n
s1.resize(6, 'x');
cout << s1 << endl;
cout << "capacity:" << s1.capacity() << endl;
cout << "size:" << s1.size() << endl;
}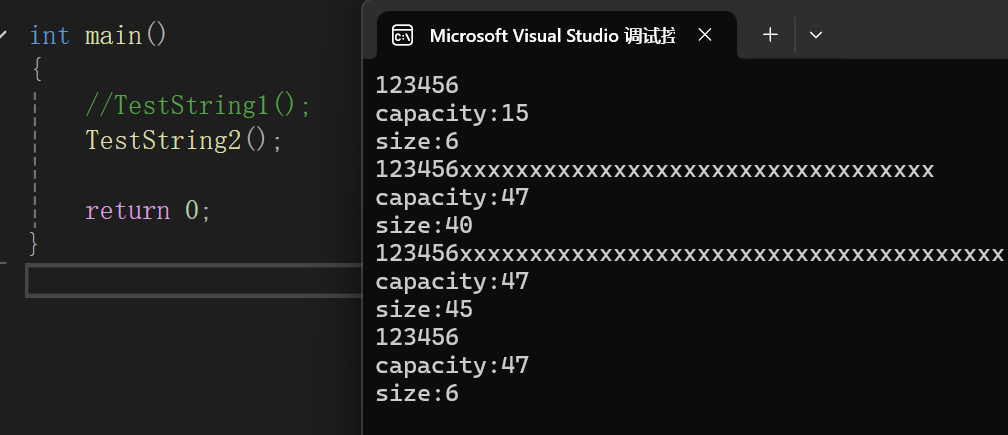
再次首先,如果要达到目标size,capacity不够用就会扩容去,如果够用就只扩size;n < size也是实打实的会从头缩,只要前n个。
6.string类对象的元素访问操作
①operator \[\]重载
已经见识过了,访问pos位置的数据,可修改对象还能修改。
当然,不能越界,越界直接报错:
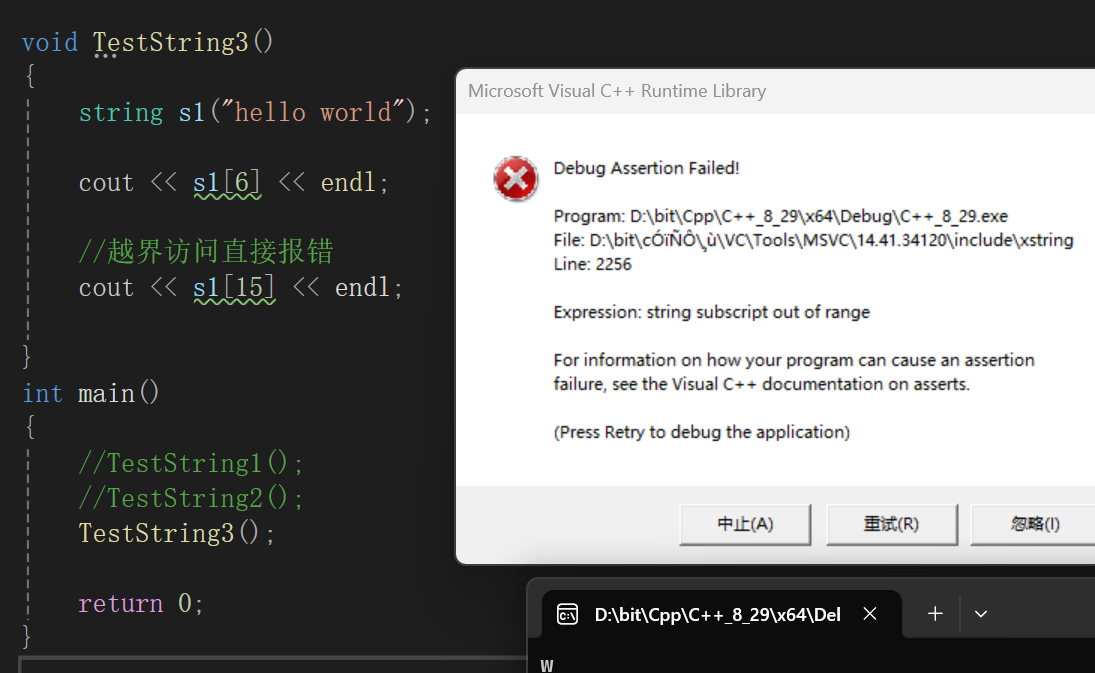
很明显可以看到,如果越界直接会报错,这也算是STL的先进之处,正常我们写一个数组越界访问都跟洒洒水一样:
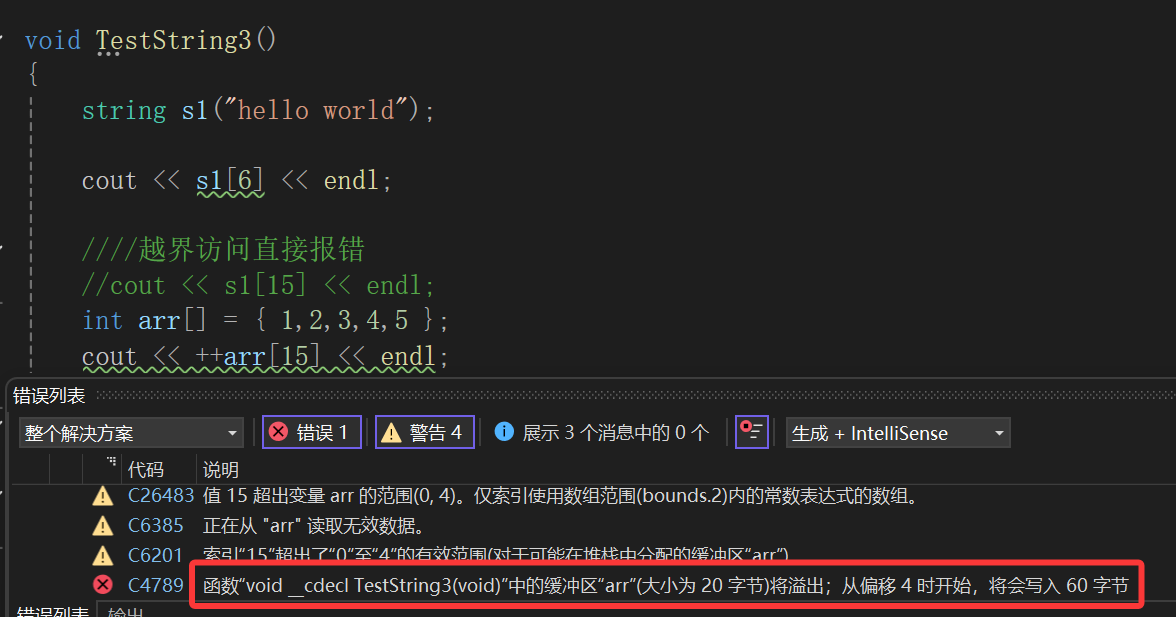
这玩意纯让编译器检查出来了,错误的代码还让它运行,可以说非常失败了。
其实string这个越界能检查出来其实道理很简单,\[\]是运算符重载,其实底层是函数,比如:
char& operator\[\](size_t pos)
{
assert(pos < _size)
//...
}
其实也没多高级,大概就这样。
②at
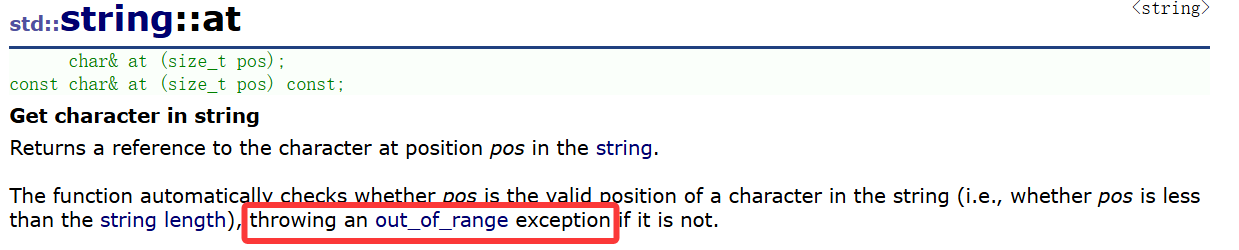
道理跟\[\]差不多,只不过一个是运算符一个是函数调用,至于区别也就是\[\]如果越界那么将会暴力assert直接中断程序运行,如果at越界那将会抛出异常:
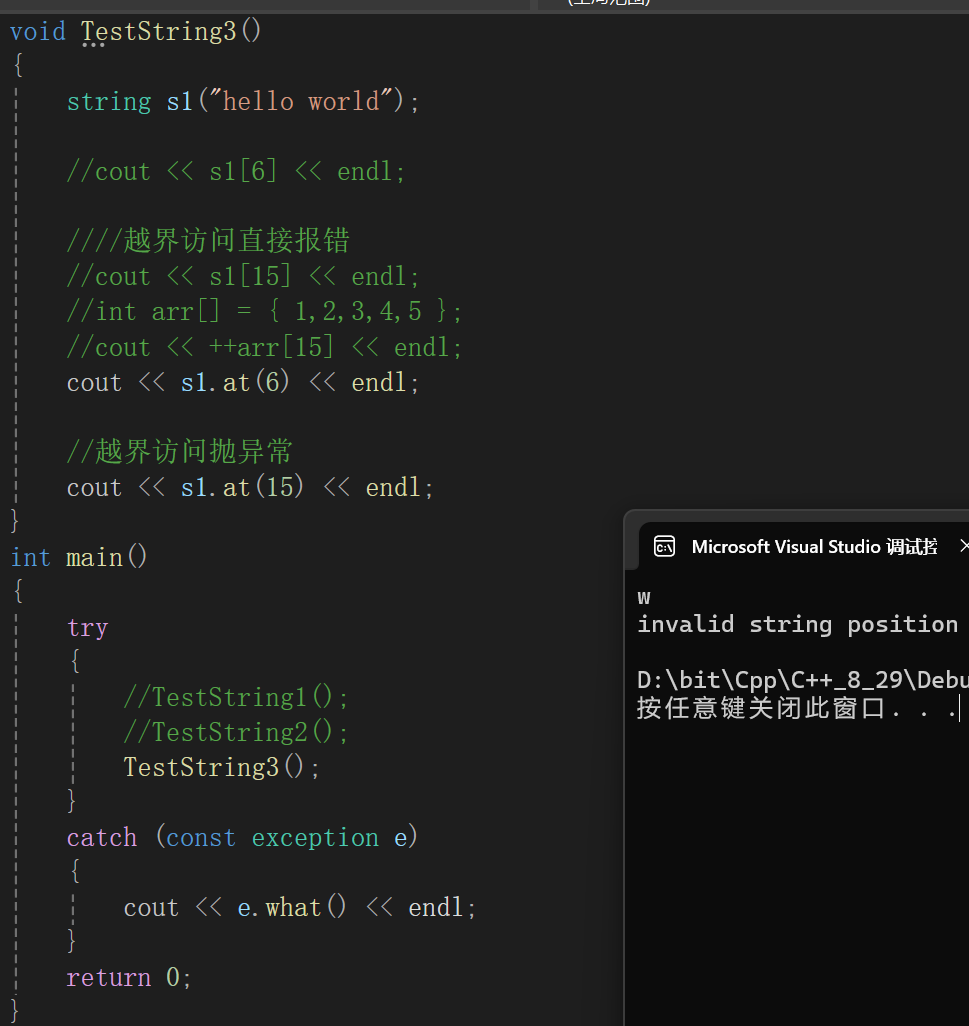
抛异常这玩意我也不懂,但是抄一抄还是会的,反正目前阶段知道at访问如果越界那么就抛异常就行。
③front和back
这俩玩意不用说啥,一个返回首元素,一个返回尾元素。

hello world返回h和d
7.string类对象的修改操作
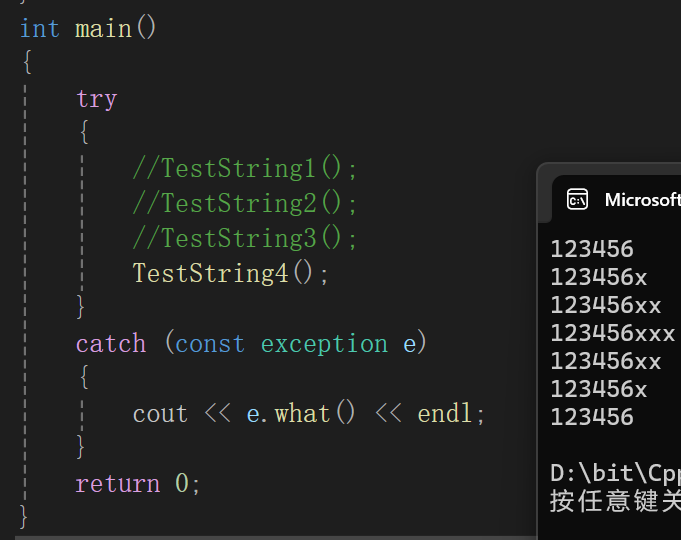
①push_back和pop_back
这俩见得太多了,老熟人也没啥可多讲的。
cpp
void TestString4()
{
string s1("123456");
cout << s1 << endl;
s1.push_back('x');
cout << s1 << endl;
s1.push_back('x');
cout << s1 << endl;
s1.push_back('x');
cout << s1 << endl;
s1.pop_back();
cout << s1 << endl;
s1.pop_back();
cout << s1 << endl;
s1.pop_back();
cout << s1 << endl;
}
不用多解释。
②append
append有追加附加的意思。
再加上文档:
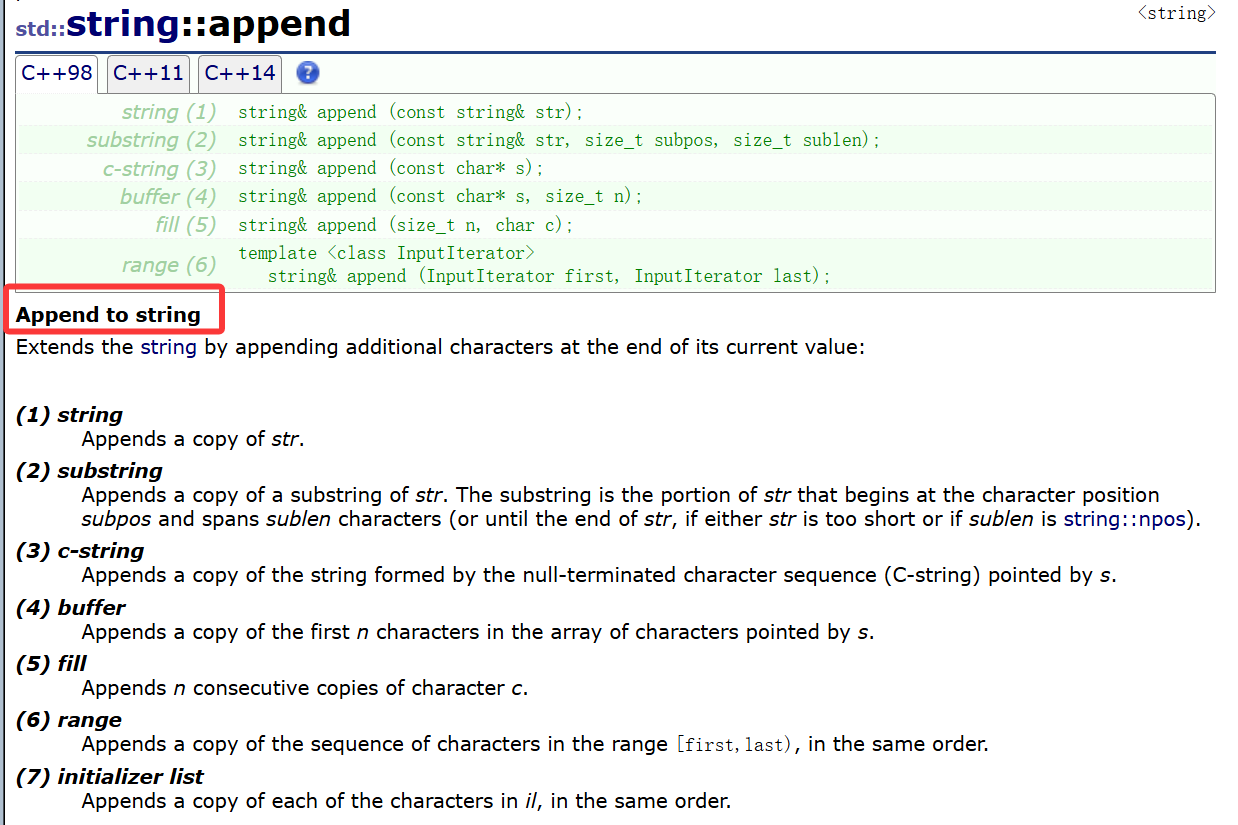
很明显,用于追加字符串。
C语言阶段我们倒是有追加的函数,比如strcat,但是这玩意也没少用,只能传des和src两个指针,哪里有上面这么自由。
当然,其实也不用细讲,打眼一看,基本上跟构造函数传参差不多,传一个string对象追加了;传string对象指定区间追加了;传常量字符串了;传常量字符串前n个了;用n个char c组成的字符串追加;还有迭代器。
cpp
void TestString5()
{
string s1("hello world");
string s2("I love C++");
s1.push_back(' ');
s1.append(s2);
cout << s1 << endl;
s1.push_back(' ');
s1.append(s2,7,3);
cout << s1 << endl;
s1.push_back(' ');
s1.append("program");
cout << s1 << endl;
s1.push_back(' ');
s1.append("program",3);
cout << s1 << endl;
s1.push_back(' ');
s1.append(10,'x');
cout << s1 << endl;
}不必多说。
③operator+=重载
但是实际上我们追加字符串可能更喜欢用这个运算符。因为看起来非常生动形象用起来一般也很舒服:
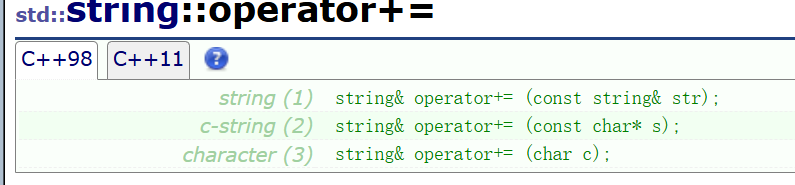
传string对象,传常量字符串,传字符。
可以说只要不是指定追加,用这个玩意就够了:
cpp
void TestString6()
{
string s1("hello world");
string s2("I love C++");
s1 += s2;
cout << s1 << endl;
s1 += "program";
cout << s1 << endl;
s1 += ' ';
s1 += 'x';
cout << s1 << endl;
}
④assign
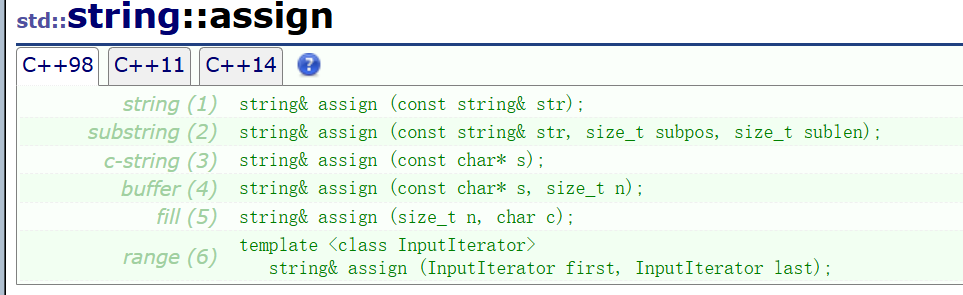
怎么说呢,写这么多函数重载看的人头疼,大概用途还得看下面的一小句:

assign有分配任命指派的意思,很明显,读读这句话就是assign这个函数就是赋值来的,所以也不展示了,参数和构造函数也差不多,而且一般我们赋值更喜欢用更形象的=。
⑤insert和erase
指定位置的插入和删除


懒得废话了,看看参数基本差不多,还是那几套,只不过下面多了几个可以传迭代器的参数形式。
insert不多说,下面看测试代码就行;erase迭代器那俩看看就行,一般咱肯定传下标多舒服,毕竟迭代器相当于复杂化实现下标了。
重点是第一行,如果不指定位置,那么就从起始位置开始删除;如果不指定长度,那就直接删完,npos上面见识过嘛,超级大的一个数,也就是不传参基本效果相当于clear了。
测试代码:
cpp
void TestString7()
{
string s1("hello world");
string s2(" love C++");
s1 += s2;
cout << s1 << endl;
s1.insert(11, " I");
cout << s1 << endl;
s1.insert(0, "xx:");
s1.erase(0, 3);
cout << s1 << endl;
s1.erase();
}
这对函数悠着点用吧,我们C语言实现的时候,这俩玩意最要命了,比如顺序表,底层是数组嘛,所以尾部的插入和删除操作老简单了,但是头部你插入得检查内存够不够了,得全体后移了,最后才能插入;删除也是这个道理,删一个后面的全部得前移。就算实现STL的人再nb难道它能不遍历
就实现吗,所以复杂度还是O(n),这就是为啥不细讲,这玩意用的少,真用那参数一看就清楚,解析也不用看,知道有个这对方法就行。
⑥replace
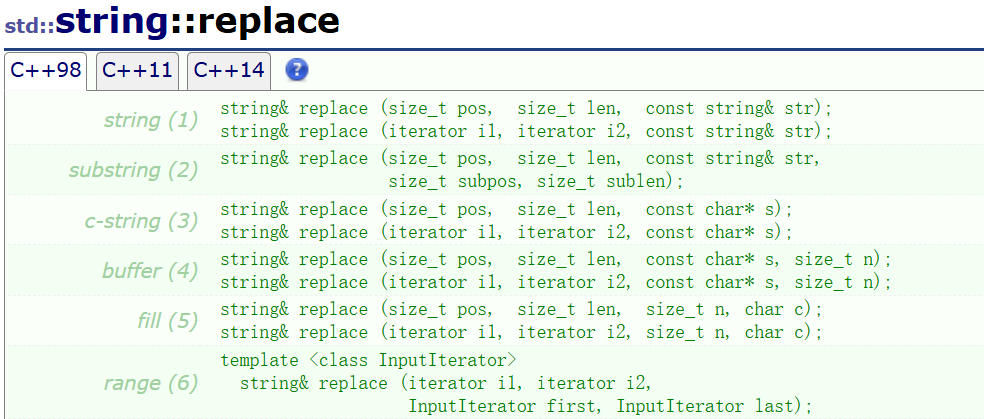
这玩意真是搞得人头疼,参数麻烦的一匹,随便见识一个就行了:
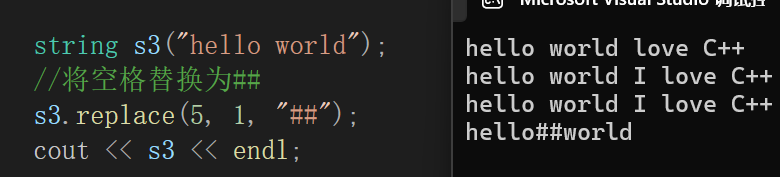
怎么说呢,这个玩意用起来倒是挺舒服的,但是实际上类比insert和erase,如果你要在头部替换一个字符变两个字符,那么很显然,你总得先腾出来两个字符的位置吧,不然不用被替换的数据也可能被覆盖,也就类似于insert和erase的后移前移,牵一发而动全身啊,这么搞来不还是O(n),超级麻烦的。
8.string类对象其它相关操作
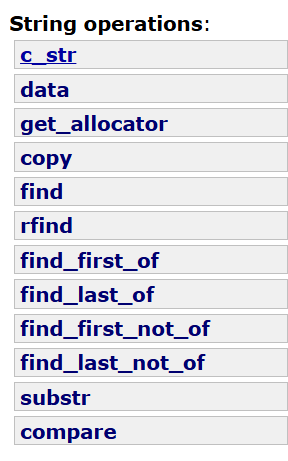
还是会跳着讲,不可能说全部学。
①c_str

学这个玩意真是费劲啊,我读这个句子读了好几遍才勉强弄懂啥意思。
返回一个const char*的指针,这个指针指向的数组里面是一个C字符串,什么叫C字符串呢?null-teminated,以\0结尾的字符串;最后说明represeting the current value of string object,大概率说的就是这个指针的值就是string这个对象底层的值。
现在我们理解就是,底层大概率是这样的:

等于这个函数返回的是这个对象的_str指针。
要这玩意有啥用呢?我们不已经有string类了嘛。
可能存在这样的情况:
假如读文档呢,目前我们掌握的接口还是C的吧:

对于这个玩意你如果传string类给第一个参数,难道它能认识吗:
人家根本认识你传的是啥,所以这个时候用一下c_str这个函数问题就迎刃而解了,当然,为了代码更合理一点,还是稍微补充补充写完:
cpp
void TestString8()
{
string filename("test.cpp");
FILE* pf = fopen(filename.c_str(), "r");
if (pf == nullptr)
{
perror("fopen fail!");
exit(1);
}
char ch = fgetc(pf);
while (ch != EOF)
{
cout << ch;
ch = fgetc(pf);
}
}这样轻轻松松的就读完了整个文件,除了有的接口的交叉:
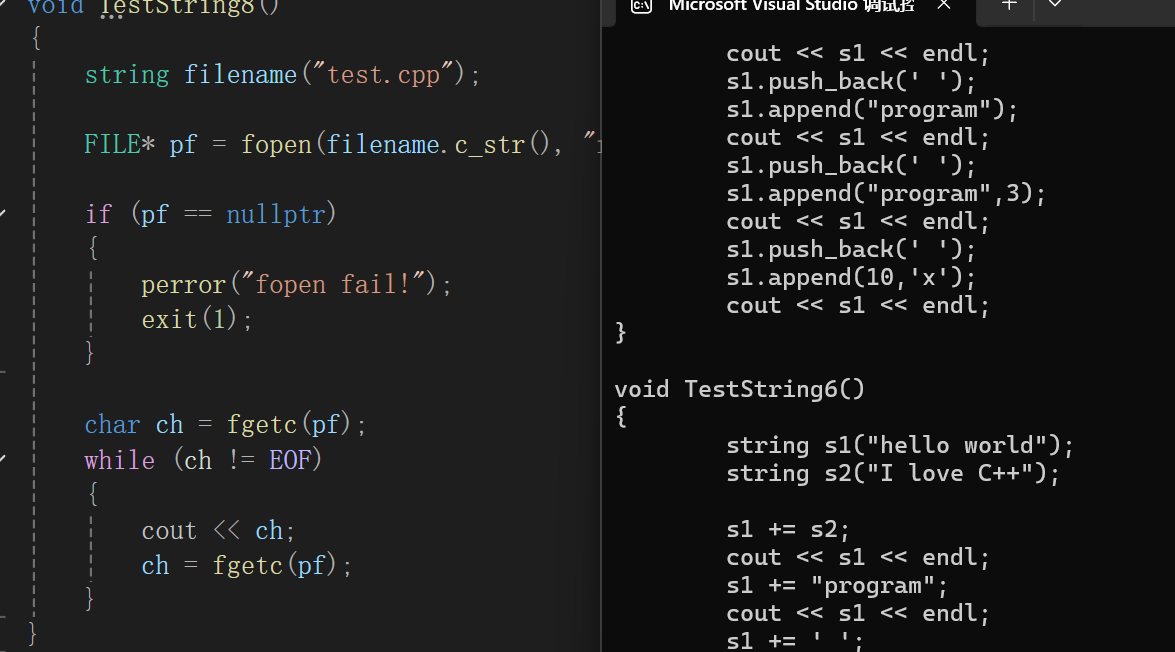
自己写代码读自己,有点照镜子的感觉了。
②data
有了c_str以后就不再多说
明显可以看到返回值都是一样的,都是返回底层的char*指针。
为啥有俩接口大概率还是历史原因,就像length和size一样,即使先来后到,也要向前兼顾。
③get_allocator
这个allocator一般来说就是内存池,啥玩意叫内存池呢,举一个很容易理解的例子:
假如家里管钱的就是妈妈,除了妈妈以外还有爸爸,妹妹和你,妹妹是个小学生,你是个大学生。那么在这种情况下,假如说爸爸是个妻管严,每一笔钱都得经过妈妈的手还得弄清原因;;而妹妹呢,上小学每天车接车送,一般情况下也花不了个钱,就算要钱情况也很少;最后就是你,你是一个标标准准的大学生,假如每个月不给你生活费,如果你想要钱,只能找妈妈要,那么非常麻烦,比如你要买一瓶牢大,四块钱,当然现在可能都涨到五块了;吃顿火锅一人四五十六七十;骑个共享车2块起步......可以看到对于大学生这种不在妈妈身边又经常有开销的情况,如果每一笔消费都找内存要,那可以说麻烦死了,所以一般都会给个几千块生活费。
为什么举这个例子呢?
爸爸就好像栈区申请的内存一样,栈区申请的随用随要而且一般都是哪个函数栈帧的创建,局部变量的创建,非常清楚;妹妹就想静态区和常量区一样,创建的全局变量和常量一整个项目相比于其它都很少,内存开辟不频繁;而你这个大学生就像堆区一样,STL的每个对象以及一系列操作都要从堆区频繁的申请和释放内存,那么我问你,如果能够创造出来一块内存专门划给堆区用,你用的内存都从这块申请和释放,那么是不是可以提高提高效率呢?这块内存就是内存池。
基本每个容器都有内存池:


多的不再举例了,反正容器和内存池基本都是绑定的。
当然,了解什么是内存池就行,因为道理很简单,一般来说谁会拉出来内存池这个对象,咋地,你还能对这玩意干啥,修修补补吗?
人家只是创造出来了,万一谁能用就用,我们只需要知道有个这方法就行。
④copy
用于从string对象中选择一部分字符串copy出来

第一个参数是你把复制的字符串放到哪,这个char* s可以理解为开辟好的等着存字符串的内存空间;len是弄多长,pos是从哪开始,默认从头开始。
返回这个字符串有多长。
直接借用库里面的例子讲解:
cpp
int main()
{
char buffer[20];
string str("Test string...");
size_t length = str.copy(buffer, 6, 5);
buffer[length] = '\0';
cout << "buffer contains: " << buffer << '\n';
return 0;
}首先创建了个数组,准备接受copy的内容,而后很明显,copy str里的string,而返回值刚好被用来去补\0。
输出不用说了:

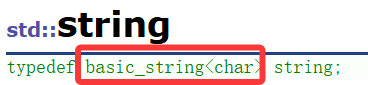
⑤substr

一般我们复制用substr的多,最后根据参数直接创建一个新的string对象。
而且这个参数先pos后len其实也很符合我们传参习惯。
⑥find和rfind
find函数是用来查找

可以从string对象中查找string对象、常量字符串、字符等。
pos是从string对象的哪里开始找。
其它默认直接查找到末尾,如果用n的话就只查前n个字符。

返回的是查找到的是第一个匹配的字符或字符串的下标。如果没找到匹配的,就返回npos,见得多了,这玩意非常大,如果返回这个,说明下标超级大,实际上不可能有这么长的串,也就代表没找到的意思。
rfind道理跟find相同,只不过头顶个r,代表reverse的意思,它会倒着找:

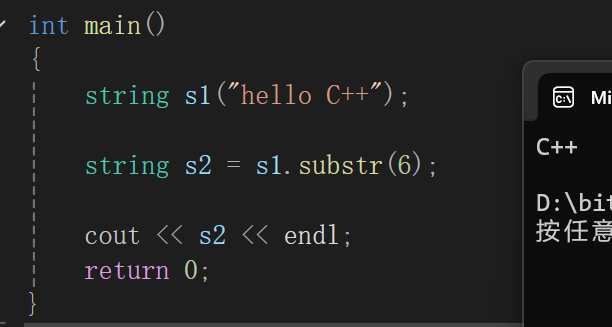
写一段代码来测试find的性能,场景就是提取文件后缀:
cpp
string findsuffix(string s)
{
size_t pos = s.find('.');
if (pos != string::npos)
{
return s.substr(pos + 1);
}
else
{
//return string();
return "";
}
}
int main()
{
string s1("test.cpp");
string s2("map.txt");
string s3("fly");
string s4("li.exe");
cout << findsuffix(s1) << endl;
cout << findsuffix(s2) << endl;
cout << findsuffix(s3) << endl;
cout << findsuffix(s4) << endl;
return 0;
}利用的是pos查找到 .,pos+1开始就都是要的后缀了。
有几个点:
第一,用npos代表没找到的情况,npos的意义了解了,没了解:

公共的静态变量,所以直接用类域访问就行。
第二如果没找到的情况,返回的第一行是一个未初始化的匿名对象,这个好理解空串嘛;返回的第二行用""代替了,我自己也是没转过来弯,其实相当于用默认构造隐式类型转换,隐式类型转换后拷贝构造,不过一般编译器会优化成直接构造个空串。
测试没啥毛病。
另外再补充一下这段代码,因为还是会有这样的文件:
很明显这样的话,只能查找到第一个点,从而:
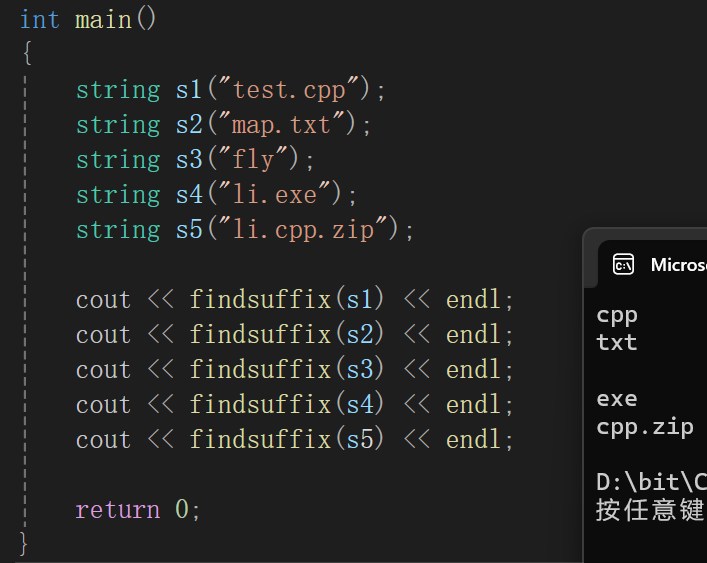
所以真的想要找到真正的后缀,直接:
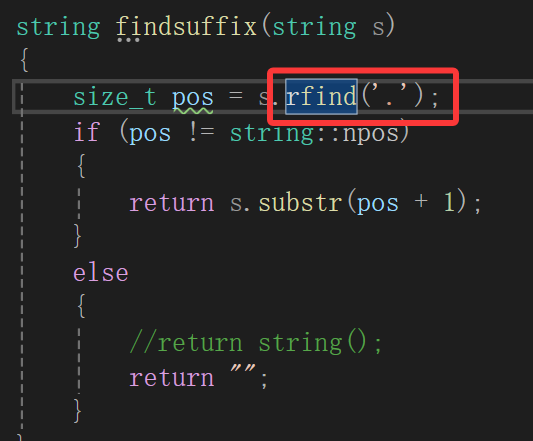
一测试:
非常完美。
⑦find_first_of、find_last_of、find_first_not_of、find_last_not_of
这四个设计的太早,其实按照我们现在看来,基本上只需要find和rfind就够了。
但是还是稍微介绍介绍:
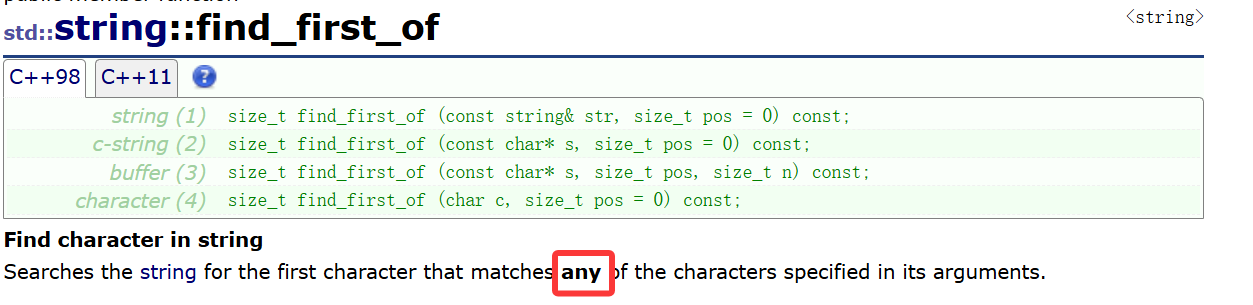
严格来说这玩意叫个find_any其实更好理解,接口和find完全一样,直接给段库里的代码来理解:
cpp
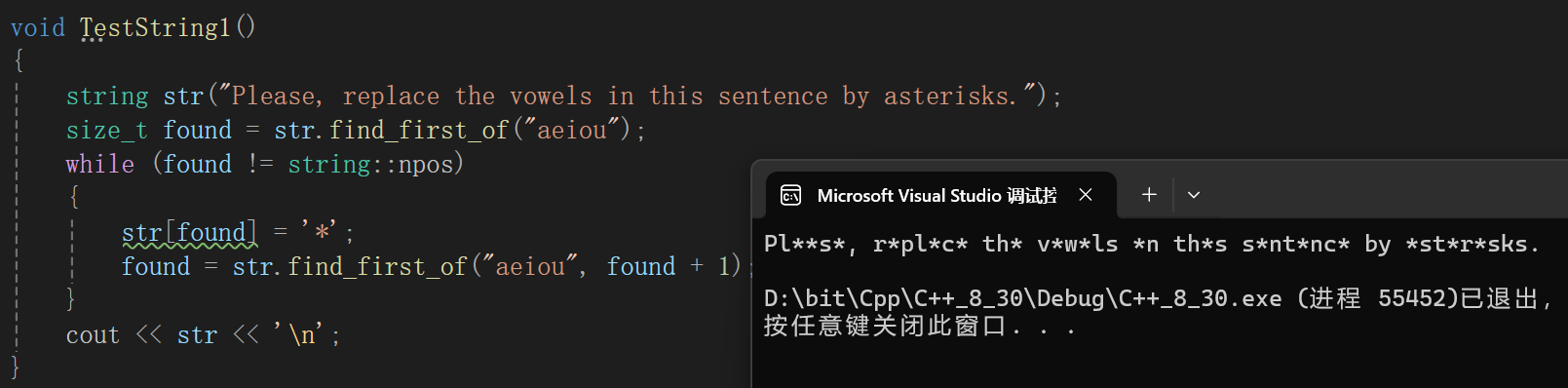
void TestString1()
{
string str("Please, replace the vowels in this sentence by asterisks.");
size_t found = str.find_first_of("aeiou");
while (found != string::npos)
{
str[found] = '*';
found = str.find_first_of("aeiou", found + 1);
}
cout << str << '\n';
}简单来说,就是给的参数是个字符串或者string对象嘛,只要是能匹配上的,比如说please的ea e,都返回下标,循环里就是利用这一点,不断的将已经检查过的过滤,并将匹配的换成*,其实很好理解。
lastof就是倒着找:
cpp
string str("Please, replace the vowels in this sentence by asterisks.");
size_t found = str.find_last_of("aeiou");
while (found != string::npos)
{
str[found] = '*';
found = str.find_last_of("aeiou", found + 1);
}
cout << str << '\n';
最终结果跟first of一样,只不过遍历的顺序不一样。
first_not_of就是除了提供的字符串中的字符都能匹配:
cpp
string str("Please, replace the vowels in this sentence by asterisks.");
size_t found = str.find_first_not_of("aeiou");
while (found != string::npos)
{
str[found] = '*';
found = str.find_first_not_of("aeiou", found + 1);
}
cout << str << '\n';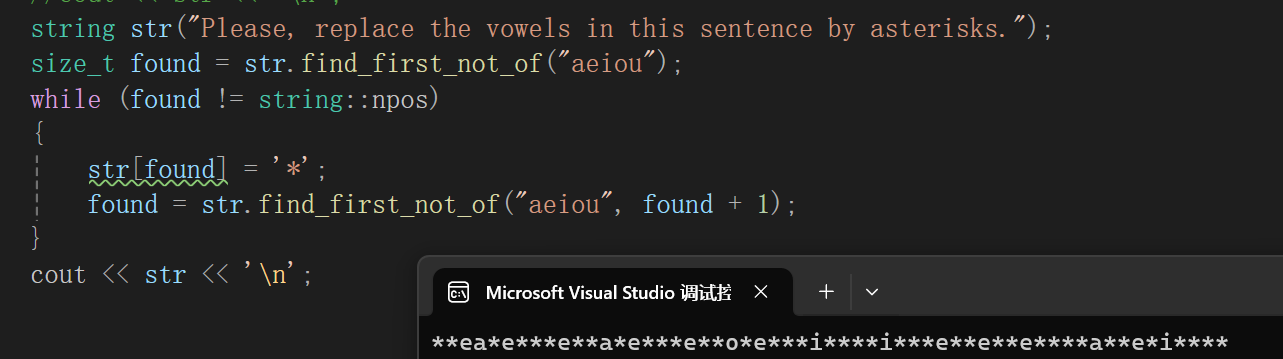
last not of不用解释了,相当于反着匹配不在字符串中的字符。
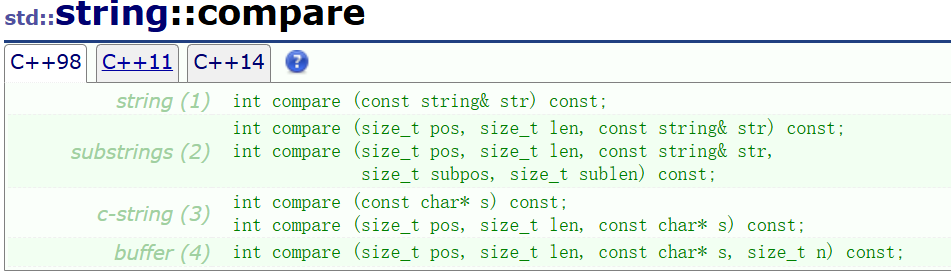
⑧compare
了解有这个算法,有场景需要用的不记得再来查表即可。
其中,比较大小的逻辑与strcmp相似,都是比较不同的字符的ASCII码值,如果两个字符串前n个完全相同,则更长的字符串更大。
至于参数可以跟string类对象比可以和常量字符串相比,而且都可限制大小。
返回值类型与strcmp相似:

9.string类对象非成员函数
非成员函数一般都是为了第一个参数不是强制的string类对象的this指针而设计的。
①operator+
成员函数有operator+=,+=重点是将已有的string类字符串后追加个你给的参数。
而operator+重点是计算出来两字符串相加到底是什么:
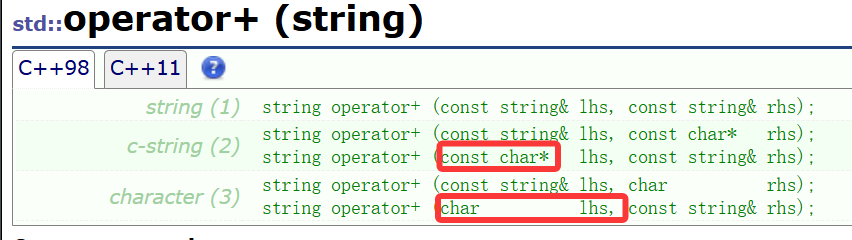
只在乎最后+的结果并返回到一个string对象里,为了重载能够将所有情况包括,特别是我圈起来的重载,所以就弄成非成员函数了。
②逻辑运算符重载

还是说,重点就是为了第一个参数可以填const char*,这样可以包括更多情况,一般情况下这些逻辑运算符都是比较ASCII码值来比较大小。
③<<和>>
流插入流提取不用多说,毕竟这俩玩意就用就完了,你还管它那么多
④swap
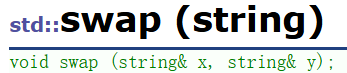
拿过来看一眼就行,真不用讲啥
⑤getline
现在简单叙述一下,到时候搞道OJ题做,用用就知道到底啥意义了。
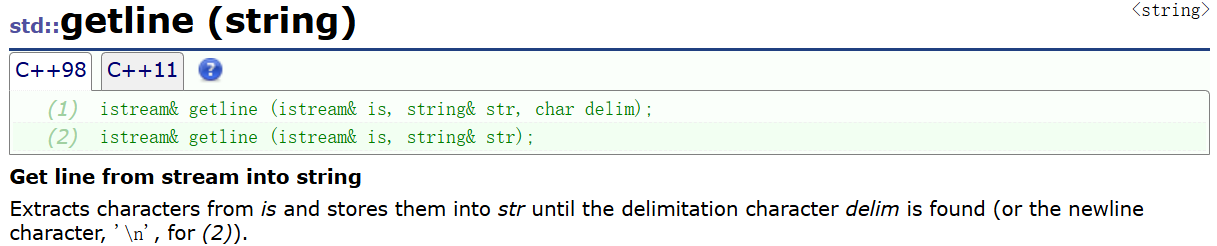
提取流,也就是提取输入的字符。第一个版本是需要传输入流cin和接收字符串的str,以及delim
也就是第一个版本有来处有去处,还有到底碰见什么字符停止读取。
第二个版本就等于你如果不给分界符那就以\n为分界符。
主要是防止这种情况:
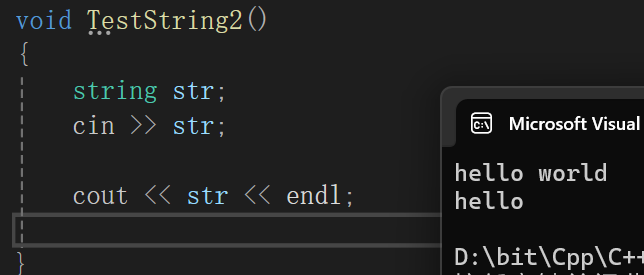
你其实是想往str里输入个hello world,但是cin(其实scanf也有这样的问题),不读空格,如果读到空格就认为这就是读的内容的分界符,就会截断,如果再搞个对象:
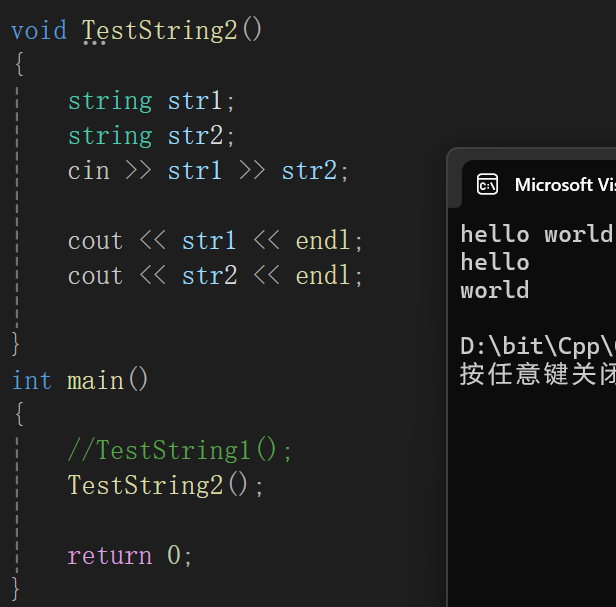
自然就都接收了,但是有时候我们不知道到底中间有多少个对象,也就不知道到底得创建多少个对象才能接收完,所以把空格变为非分界符就很重要了。
只能读到hello,其实我们是不想让这样的情况发生,所以最好调一下getline:
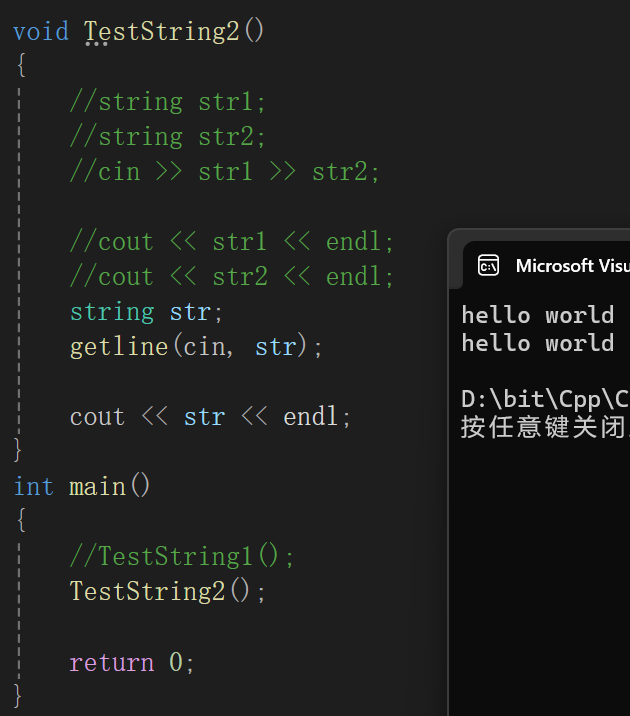
看起来就好像是cin的数据,按照\n为分界符给到str里。
特别强调
这些东西可不要说死记硬。首先讲解就能看出来,有的非常重要,有的大概知道有这个接口就行,到时候如果真的有场景用那就用,想不起来就查文档;其次就是即使有的非常重要,比如find了insert等等,增删查改注定很重要嘛,但是你可不能说每天看一遍,跟干啥一样,用的多了,或者说OJ题用的多了自然就掌握了,死记硬背还是会忘的。