Transformer
参考链接:https://cloud.tencent.com/developer/article/2398361
https://cloud.tencent.com/developer/article/2400095
1)原理详解
Transformer:通常Attention会与传统的模型配合起来使用,但Google的一篇论文《Attention Is All You Need》中提出只需要注意力就可以完成传统模型所能完成的任务,从而摆脱传统模型对于长程依赖无能为力的问题并使得模型可以并行化,并基于此提出Transformer模型。
Transformer架构
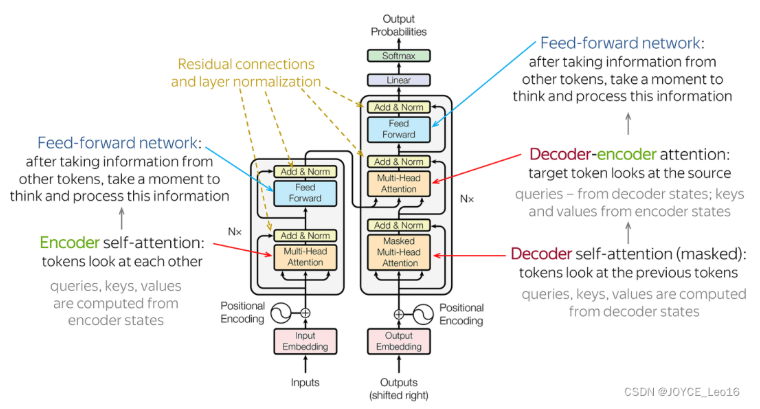
主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。
输入部分:
- 源文本嵌入层:将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
- 位置编码器:为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
- 目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
编码器部分:
- 由N个编码器堆叠而成。
- 每个编码器层由两个子层连接结构组成:第一个子层是一个多头注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
解码器部分:
- 由N个解码器层堆叠而成。
- 每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
输出部分:
- 线性层:将解码器输出的向量转换为最终的输出维度。
- Softmax层:将线性层的输出转换为概率分布,以便进行最终的预测。
2)从零开始实现 Transformer
参考链接:https://www.zhihu.com/tardis/bd/art/603243890?source_id=1001
实现Transformer模型需要从核心组件开始逐步构建,重点关注注意力机制、编码器-解码器架构和训练流程。以下基于常见实践(如PyTorch框架)提供关键步骤和代码框架,侧重可读性和可扩展性。
模型核心组件包括输入表示、注意力机制和编码器-解码器结构。
Transformer的输入表示
Transformer中单词的输入表示由单词Embedding和位置Embedding(Positional Encoding)相加得到。
输入表示需处理词嵌入和位置编码:词嵌入将输入序列转换为向量,位置编码添加序列顺序信息以解决Transformer对位置不敏感的问题,通常使用正弦/余弦函数生成固定编码。
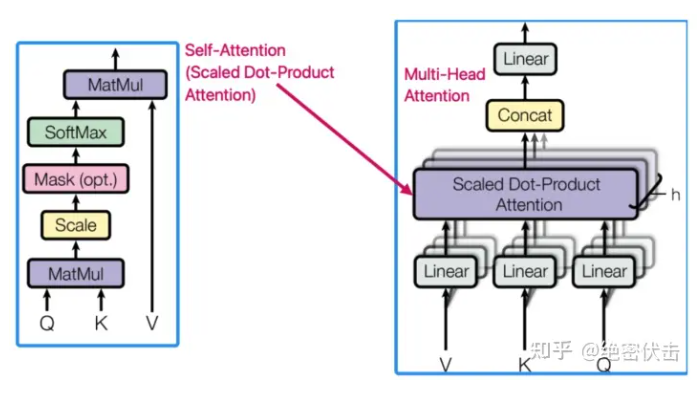
Multi-Head Attention
多头注意力机制是核心,它允许模型并行关注不同位置的信息,计算过程包括查询(Q)、键(K)、值(V)矩阵的线性变换,然后通过缩放点积计算注意力权重,多头设计通过分组独立计算增强表达能力。Multi-Head Attention是由多个Self-Attention组合形成的,下图是论文中Multi-Head Attention的结构图。
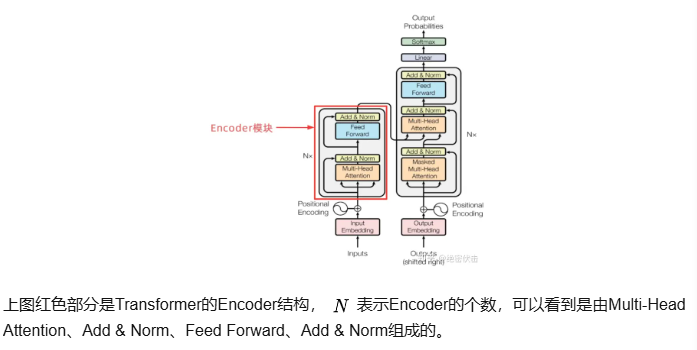
编码器-解码器结构
编码器由多个相同层堆叠而成,每层包含多头自注意力子层和前馈神经网络子层,通过残差连接和层归一化稳定训练;
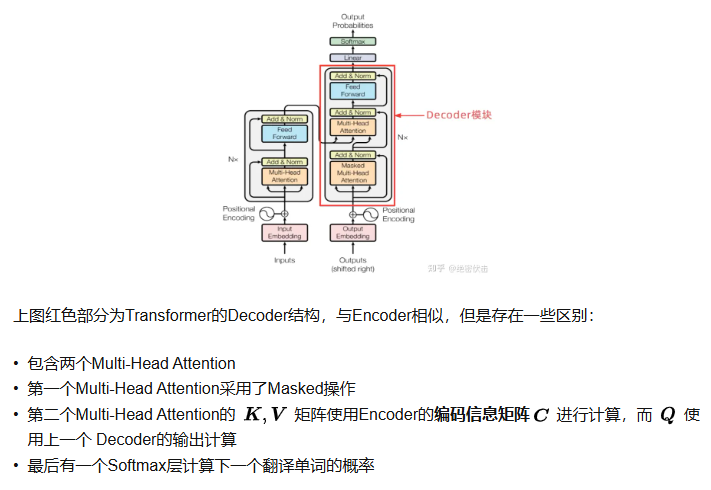
解码器结构类似但增加编码器-解码器注意力层并使用因果掩码确保自回归生成。
代码实现框架以PyTorch为例,简化关键组件。 以下为简化版代码框架,实际实现需扩展细节如位置编码和正规化:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=512):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1), :]
class Transformer(nn.Module):
def __init__(self, vocab_size, d_model=512, nhead=8, num_layers=6, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model)
encoder_layer = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers)
decoder_layer = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout, batch_first=True)
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
src_embed = self.embedding(src) * (self.d_model ** 0.5)
src_embed = self.pos_encoder(src_embed)
tgt_embed = self.embedding(tgt) * (self.d_model ** 0.5)
tgt_embed = self.pos_encoder(tgt_embed)
enc_out = self.transformer_encoder(src_embed, src_mask)
dec_out = self.transformer_decoder(tgt_embed, enc_out, tgt_mask)
return self.fc_out(dec_out)训练流程涉及数据准备、损失计算和优化。 需要准备序列数据,处理序列数据通常涉及数据预处理、特征提取和模型训练等步骤。以下是一个基于Transformer模型的序列数据处理流程示例,包括数据预处理、模型定义和训练代码。
- 自定义数据集类SequenceDataset处理序列数据,支持滑动窗口提取输入输出对
- TransformerModel定义包含嵌入层、Transformer编码器和全连接层
- preprocess_data函数实现数据预处理,返回DataLoader对象
- train函数封装训练循环,支持多轮迭代和损失计算
- 主函数示例使用正弦波数据训练模型,展示完整流程
- 代码支持自定义序列长度、模型参数和优化器设置
- 使用PyTorch实现,适合处理时间序列、文本等序列数据
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import numpy as np
# 自定义数据集类
class SequenceDataset(Dataset):
def __init__(self, data, seq_length):
self.data = data
self.seq_length = seq_length
def __len__(self):
return len(self.data) - self.seq_length
def __getitem__(self, idx):
return self.data[idx:idx+self.seq_length], self.data[idx+self.seq_length]
# Transformer模型定义
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, d_model, nhead, num_layers):
super(TransformerModel, self).__init__()
self.embedding = nn.Linear(input_dim, d_model)
self.transformer = nn.Transformer(d_model, nhead, num_layers)
self.fc = nn.Linear(d_model, output_dim)
def forward(self, src, tgt):
src = self.embedding(src)
tgt = self.embedding(tgt)
output = self.transformer(src, tgt)
return self.fc(output)
# 数据预处理
def preprocess_data(data, seq_length):
dataset = SequenceDataset(data, seq_length)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
return dataloader
# 训练函数
def train(model, dataloader, criterion, optimizer, epochs=10):
model.train()
for epoch in range(epochs):
for src, tgt in dataloader:
optimizer.zero_grad()
output = model(src, tgt)
loss = criterion(output, tgt)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
# 主函数
if __name__ == "__main__":
# 示例数据
data = np.sin(np.linspace(0, 100, 1000))
dataloader = preprocess_data(data, seq_length=10)
# 模型参数
input_dim = 1
output_dim = 1
d_model = 64
nhead = 8
num_layers = 2
# 模型初始化
model = TransformerModel(input_dim, output_dim, d_model, nhead, num_layers)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
train(model, dataloader, criterion, optimizer)