目录
1.前言
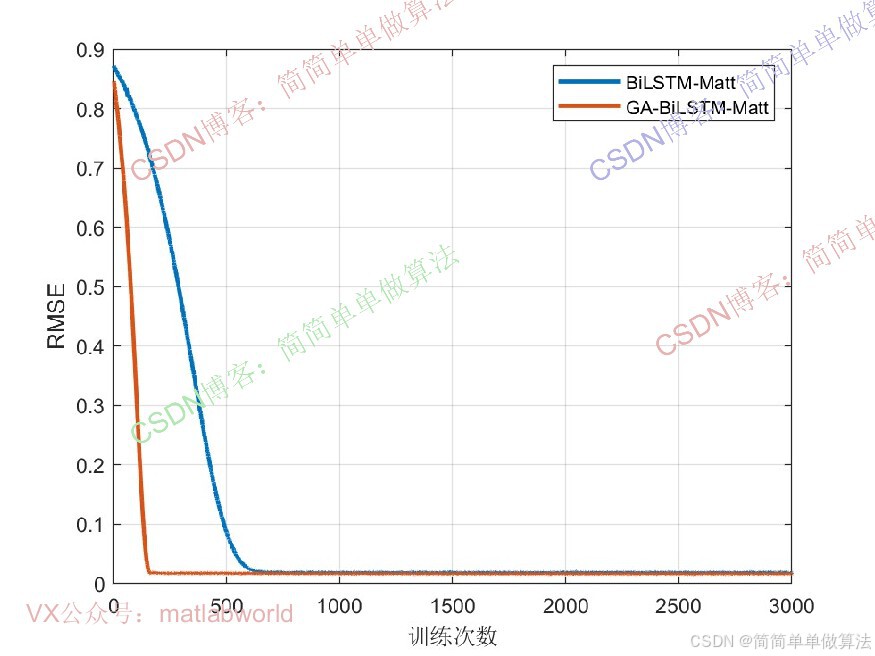
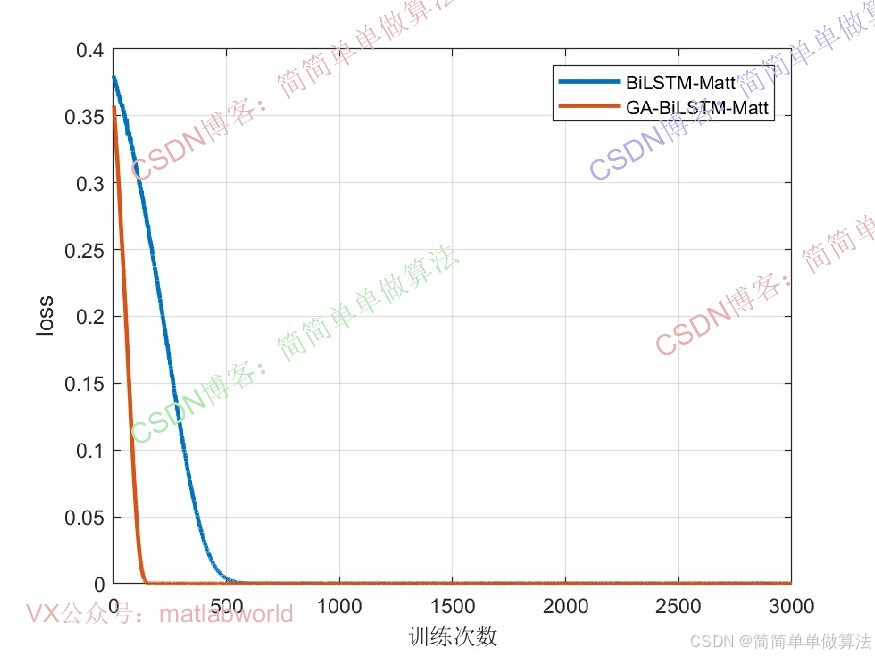
时间序列预测是机器学习领域的重要任务,广泛应用于气象预报、金融走势分析、工业设备故障预警等场景。传统时间序列模型(如 ARIMA、单 LSTM)在处理长序列依赖、捕捉多尺度特征时存在局限性,而双向LSTM(BiLSTM) 可同时利用历史与未来上下文信息,多头注意力(Multi-Head Attention) 能聚焦关键时间步特征,二者融合的BiLSTM-MATT算法有效解决了上述问题,成为当前高精度时间序列预测的主流方案之一。
2.算法运行效果图预览
(完整程序运行后无水印)

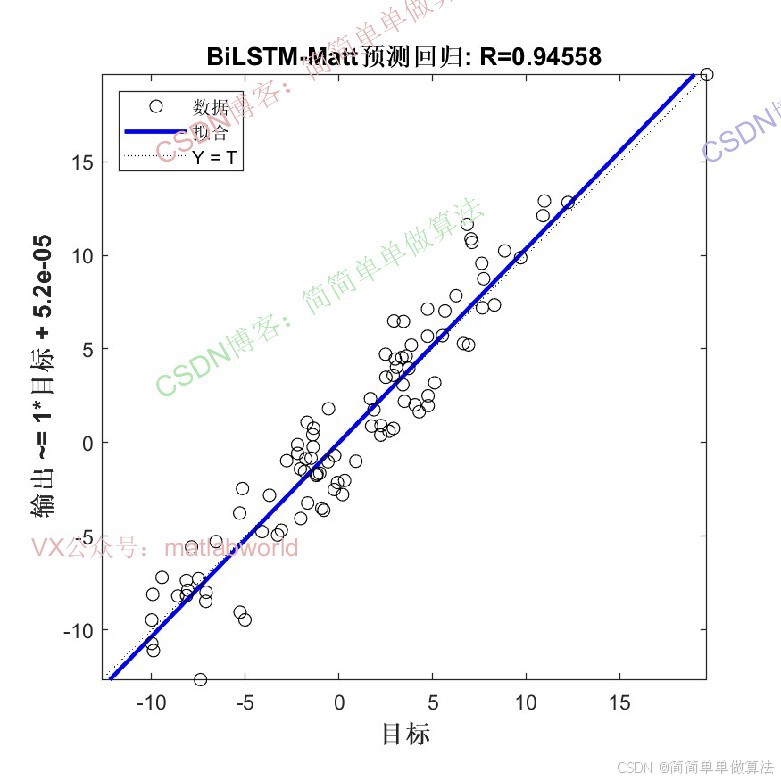
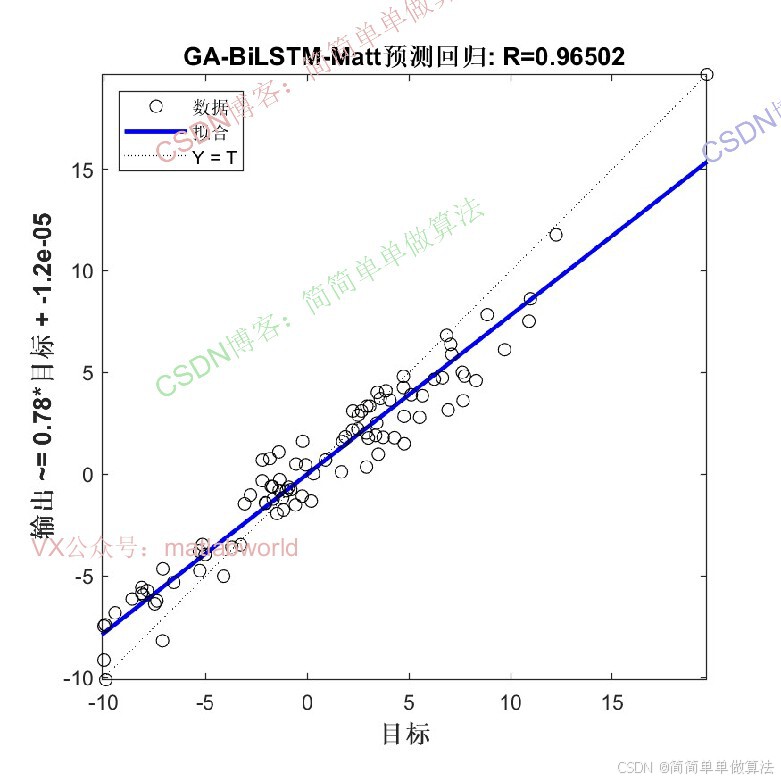
3.算法运行软件版本
Matlab2024b(推荐)或者matlab2022a
4.部分核心程序
(完整版代码包含中文注释和操作步骤视频)
[V,I] = min(JJ);
X = phen1(I,:);
LR = X(1);
numHiddenUnits = floor(X(2))+1;% 定义隐藏层中LSTM单元的数量
%CNN-GRU-ATT
layers = func_model2(Dim,Dimo,numHiddenUnits);
%设置
%迭代次数
%学习率为0.001
options = trainingOptions('adam', ...
'MaxEpochs', 3000, ...
'InitialLearnRate', LR, ...
'LearnRateSchedule', 'piecewise', ...
'LearnRateDropFactor', 0.1, ...
'LearnRateDropPeriod', 1000, ...
'Shuffle', 'every-epoch', ...
'Plots', 'training-progress', ...
'Verbose', false);
%训练
[Net,INFO] = trainNetwork(Nsp_train2, NTsp_train, layers, options);
%数据预测
Dpre1 = predict(Net, Nsp_train2);
Dpre2 = predict(Net, Nsp_test2);
%归一化还原
T_sim1=Dpre1*Vmax2;
T_sim2=Dpre2*Vmax2;
Tat_train=Tat_train-mean(Tat_train);
T_sim1=T_sim1-mean(T_sim1);
Tmax1 = max(Tat_train);
Tmax2 = max(T_sim1);
T_sim1=Tmax1*T_sim1/Tmax2;
Tat_test=Tat_test-mean(Tat_test);
T_sim2=T_sim2-mean(T_sim2);
T2max1 = max(Tat_test);
T2max2 = max(T_sim2);
T_sim2=T2max1*T_sim2/T2max2;
%网络结构
analyzeNetwork(Net)
figure
subplot(211);
plot(1: Num1, Tat_train,'-bs',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.0,0.0]);
hold on
plot(1: Num1, T_sim1,'g',...
'LineWidth',2,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.9,0.0]);
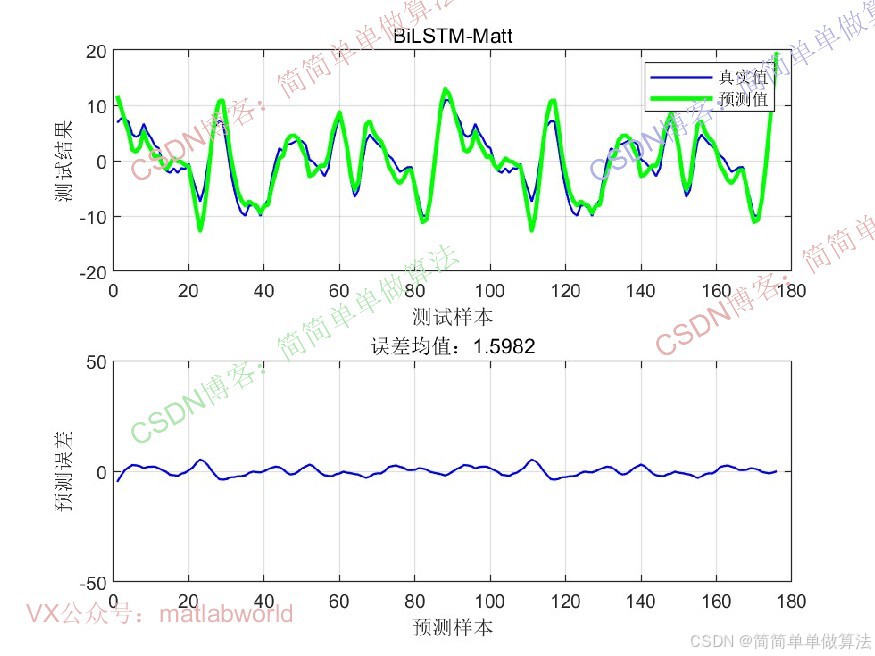
legend('真实值', '预测值')
xlabel('预测样本')
ylabel('预测结果')
grid on
subplot(212);
plot(1: Num1, Tat_train-T_sim1','-bs',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.0,0.0]);
xlabel('预测样本')
ylabel('预测误差')
grid on
ylim([-50,50]);
figure
subplot(211);
plot(1: Num2, Tat_test,'-bs',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.0,0.0]);
hold on
plot(1: Num2, T_sim2,'g',...
'LineWidth',2,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.9,0.0]);
legend('真实值', '预测值')
xlabel('测试样本')
ylabel('测试结果')
grid on
subplot(212);
plot(1: Num2, Tat_test-T_sim2','-bs',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.0,0.0]);
xlabel('预测样本')
ylabel('预测误差')
grid on
ylim([-50,50]);
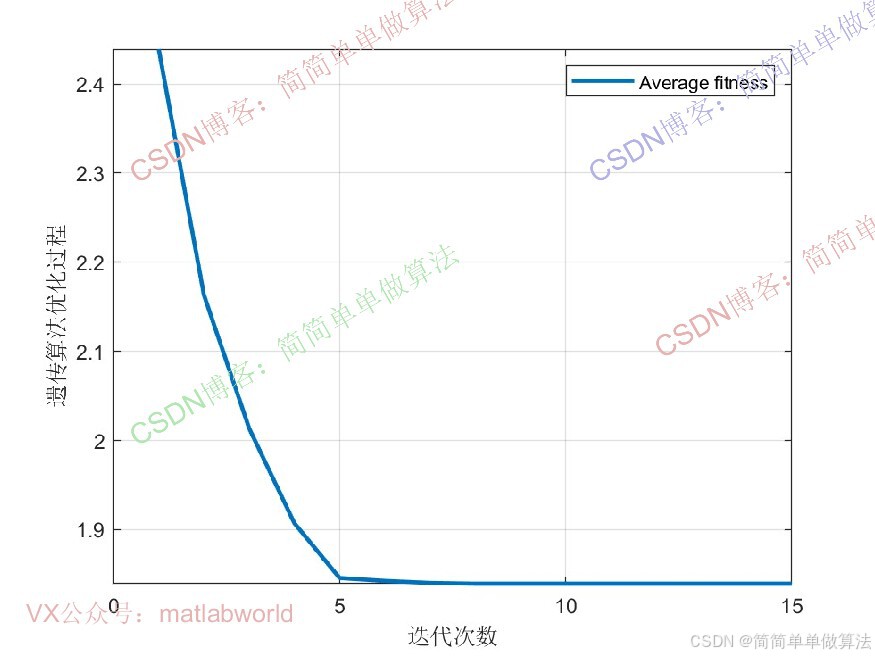
2295.算法仿真参数
MAXGEN = 15;
NIND = 10;
Nums = 2;
Chrom = crtbp(NIND,Nums*10);
%sh
Areas = [];
for i = 1:1
Areas = [Areas,[0.00001;0.001]];% 整体学习率
end
for i = 1:1
Areas = [Areas,[2;12]];% BILSTM层数
end6.算法理论概述
传统单向LSTM仅能从历史到未来(左→右)处理序列,无法利用"未来"上下文(如预测第t步时,无法参考t+1、t+2步的信息),而BiLSTM通过并行部署"正向LSTM"与"反向LSTM",将双向信息融合为统一的时序特征表示,具体原理如下:

BiLSTM虽能捕捉双向依赖,但对所有时间步的隐藏状态 "一视同仁",无法突出对预测结果更重要的关键时间步。 而BiLSTM-MATT的核心是"BiLSTM提取双向时序特征→多头注意力聚焦关键特征→全连接层输出预测结果",其架构流程如下:

多头注意力层是算法的"特征筛选器",通过并行计算h个注意力头,捕捉不同维度的关键时间步特征,其实现分为"单头注意力计算"和"多头融合"两步。
7.参考文献
1程熙晔,马旭恒,杨帆,等.基于BiLSTM和多头注意力机制的超短期电力负荷预测J.农村电气化, 2024(12):41-45.DOI:10.13882/j.cnki.ncdqh.2410A032.
2田源,高树国,邢超,等.基于多头注意力机制和TCN-BiLSTM的IGBT剩余寿命预测方法J.电气工程学报, 2025(3).
8.算法完整程序工程
OOOOO
OOO
O