前言
笔者使用过kafka处理通知,但是未系统学习kafka,因此认真学习一遍《Kafka核心技术与实战》这门课程。课程作者也是《Apache Kafka实战》这本书的作者。
00 开篇词 为什么要学习Kafka?
专栏的知识体系
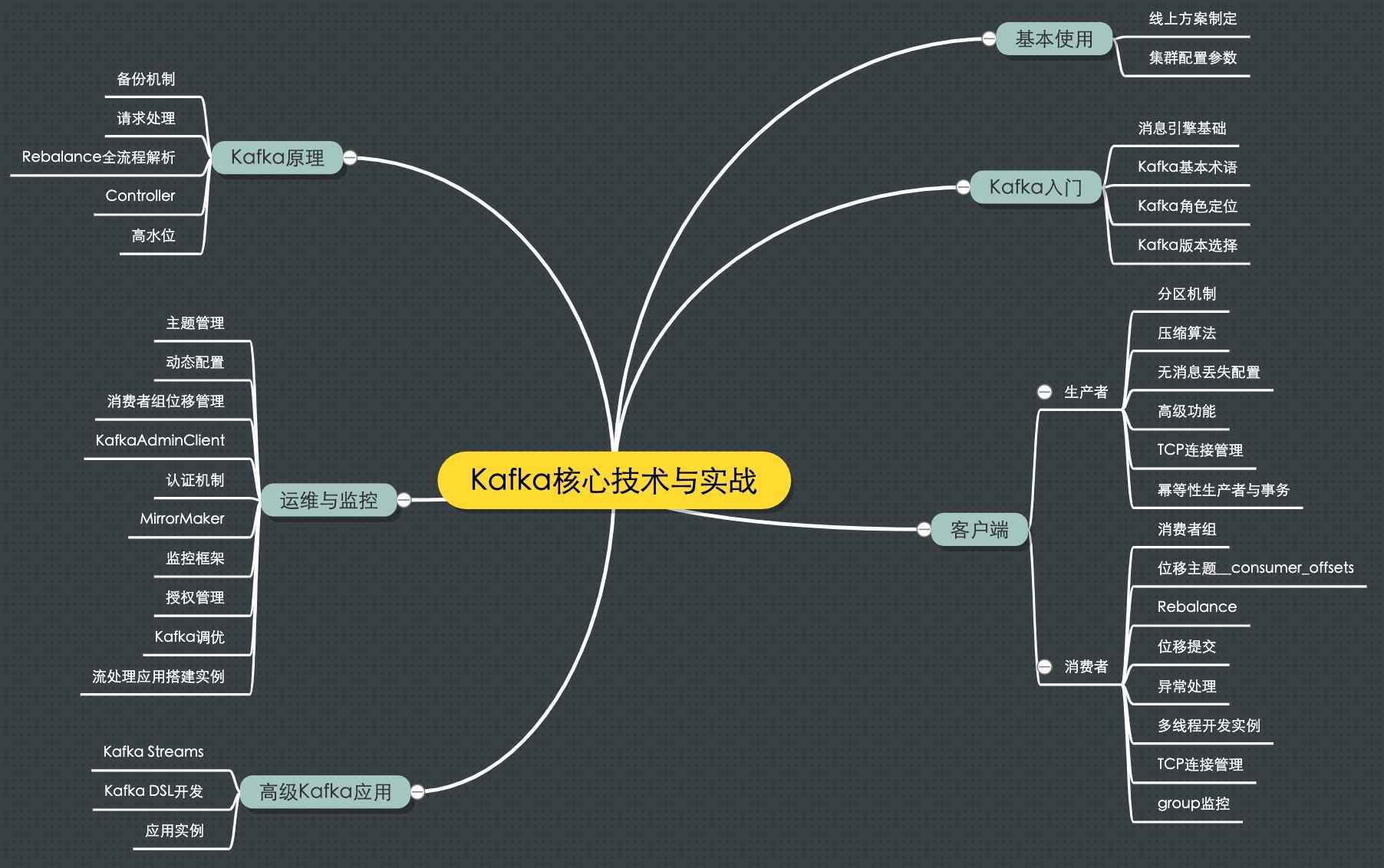
- 专栏的第一部分我会介绍消息引擎这类系统大致的原理和用途,以及作为优秀消息引擎代表的Kafka在这方面的表现。
- 第二部分则重点探讨Kafka如何用于生产环境,特别是线上环境方案的制定。
- 在第三部分中我会陪你一起学习Kafka客户端的方方面面,既有生产者的实操讲解也有消费者的原理剖析,你一定不要错过。
- 第四部分会着重介绍Kafka最核心的设计原理,包括Controller的设计机制、请求处理全流程解析等。
- 第五部分则涵盖Kafka运维与监控的内容,想获得高效运维Kafka集群以及有效监控Kafka的实战经验?我必当倾囊相助!
- 最后一个部分我会简单介绍一下Kafka流处理组件Kafka Streams的实战应用,希望能让你认识一个不太一样的Kafka。
01 消息引擎系统ABC
聪明人也要下死功夫。
在2015年那会儿,我花了将近1年的时间阅读Kafka源代码,期间多次想要放弃。你要知道阅读将近50万行源码是多么痛的领悟。我还记得当初为了手写源代码注释,自己写满了一个厚厚的笔记本。不过幸运的是我坚持了下来,之前的所有努力也没有白费,以至于后面写书、写极客时间专栏就变成了一件件水到渠成的事情。
Apache Kafka是一款开源的消息引擎系统。。通俗来讲,就是系统A发送消息给消息引擎系统,系统B从消息引擎系统中读取A发送的消息。
消息引擎系统要设定具体的传输协议,即我用什么方法把消息传输出去,常见的方法有2种:点对点模型;发布/订阅模型。Kafka同时支持这两种消息引擎模型。
系统A不能直接发送消息给系统B,中间还要隔一个消息引擎呢,是为了"削峰填谷"。
02 一篇文章带你快速搞定Kafka术语
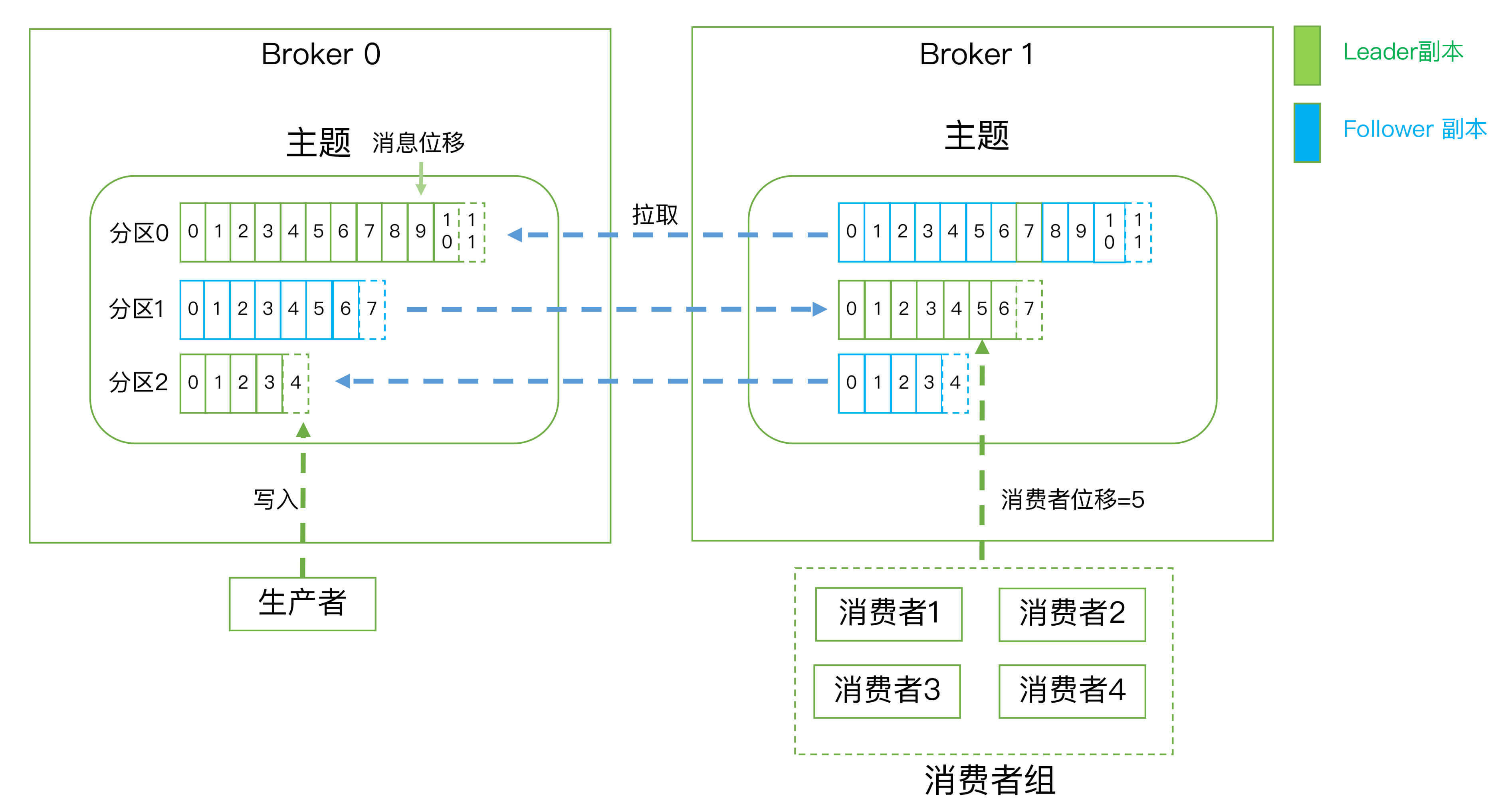
kafka实现高可用的手段:broker分布式部署、备份机制、重平衡。
Kafka定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)。前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。当然了,你可能知道在很多其他系统中追随者副本是可以对外提供服务的,比如MySQL的从库是可以处理读操作的,但是在Kafka中追随者副本不会对外提供服务。
副本的工作机制也很简单:生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
什么是伸缩性呢?我们拿副本来说,虽然现在有了领导者副本和追随者副本,但倘若领导者副本积累了太多的数据以至于单台Broker机器都无法容纳了,此时应该怎么办呢?一个很自然的想法就是,能否把数据分割成多份保存在不同的Broker上?如果你就是这么想的,那么恭喜你,Kafka就是这么设计的。
Kafka中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区0中,要么在分区1中。如你所见,Kafka的分区编号是从0开始的,如果Topic有100个分区,那么它们的分区号就是从0到99。
刚才提到的副本如何与这里的分区联系在一起呢?实际上,副本是在分区这个层级定义的。每个分区下可以配置若干个副本,其中只能有1个领导者副本和N-1个追随者副本。生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从0开始,假设一个生产者向一个空分区写入了10条消息,那么这10条消息的位移依次是0、1、2、......、9。
至此我们能够完整地串联起kafka的三层消息架构:
- 第一层是主题层(Topic),每个主题可以配置M个分区,而每个分区又可以配置N个副本。
- 第二层是分区层(Partition),每个分区的N个副本中只能有一个充当领导者角色,对外提供服务;其他N - 1个副本是追随者副本,只能提供数据冗余之用。
- 第三层是消息层(Record),分区中包含若干条消息,每条消息的位移从0开始,一次递增。
Kafka Broker是如何持久化数据的?总的来说,Kafka使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机I/O操作,改为性能较好的顺序I/O写操作,这也是实现Kafka高吞吐量特性的一个重要手段。
为避免耗尽所有的磁盘空间,Kafka必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在Kafka底层,一个日志有进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
术语总结
- 消息:Record。Kafka是消息引擎嘛,这里的消息就是指Kafka处理的主要对象。
- 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
- 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
- 消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
- 副本:Replica。Kafka中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
- 生产者:Producer。向主题发布新消息的应用程序。
- 消费者:Consumer。从主题订阅新消息的应用程序。
- 消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
- 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
- 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance是Kafka消费者端实现高可用的重要手段。
03 Kafka只是消息引擎系统吗?
Kafka在设计之初就旨在提供三个方面的特性:
- 提供一套API实现生产者和消费者;
- 降低网络传输和磁盘存储开销;
- 实现高伸缩性架构。
Kafka流处理框架地位 。Kafka与其他主流大数据流式计算框架相比,优势有两点:更容易实现端到端的正确性;它自己对于流式计算的定位。
Apache Kafka是消息引擎系统,也是一个分布式流处理平台。除此之外,Kafka还能够被用作分布式存储系统(了解即可,无实际运用)。
04 我应该选择哪种Kafka?
- Apache Kafka,是开发人数最多、版本迭代速度最快的Kafka。如果你仅仅需要一个消息引擎系统抑或是简单的流处理应用场景,同时需要对系统有较大把控度,那么我推荐你使用Apache Kafka。
- Confluent Kafka,目前分为免费版和企业版两种。企业版提供了很多功能,最有用的当属跨数据中心备份和集群监控了。如果你需要用到Kafka的一些高级特性,那么推荐你使用Confluent Kafka。
- CDH/HDP Kafka,如果你需要快速地搭建消息引擎系统,或者你需要搭建的是多框架构成的数据平台且Kafka只是其中一个组件,那么我推荐你使用这些大数据云公司提供的Kafka。
05 聊聊Kafka的版本号
- 0.7版本:只提供了最基础的消息队列功能。
- 0.8版本:引入了副本机制,至此Kafka成为了一个真正意义上完备的分布式高可靠消息队列解决方案。
- 0.9.0.0版本:增加了基础的安全认证/权限功能;使用Java重写了新版本消费者API;引入了Kafka Connect组件。
- 0.10.0.0版本:引入了Kafka Streams,正式升级成分布式流处理平台。
- 0.11.0.0版本:提供了幂等性ProducerAPI以及事务API;对Kafka消息格式做了重构。
- 1.0和2.0版本:主要还是KafkaStreams的各种改进。