前言
正在找免费模型的小伙伴可以看过来,最近发现智谱清言提供了福利专区,包含免费模型和免费工具的调用,想白嫖或者在某些场景想使用免费模型的小伙伴可以尝试一下。
BigModel福利专区
官网地址:bigmodel.cn/dev/activit...
福利专区提供了6个免费模型和2个免费工具:
免费模型:
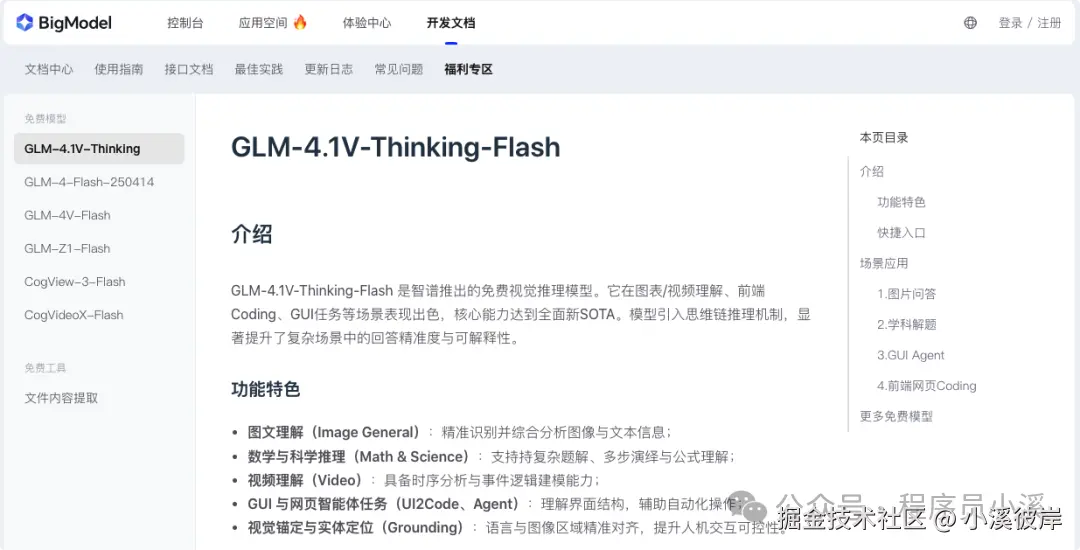
- GLM-4.1V-Thinking-Flash:智谱推出的免费视觉推理模型。它在图表/视频理解、前端Coding、GUI任务等场景表现出色,核心能力达到全面新SOTA。模型引入思维链推理机制,显著提升了复杂场景中的回答精准度与可解释性。
- GLM-4-Flash-250414:智谱AI首个免费的大模型API,在实时网页检索、长上下文处理、多语言支持等方面表现出色,适用于智能问答、摘要生成和文本数据处理等多种应用场景
- GLM-4V-Flash:智谱推出的首个完全免费的图像理解模型。在图像识别、图像问答、图像推理等多项任务中展现出卓越的性能
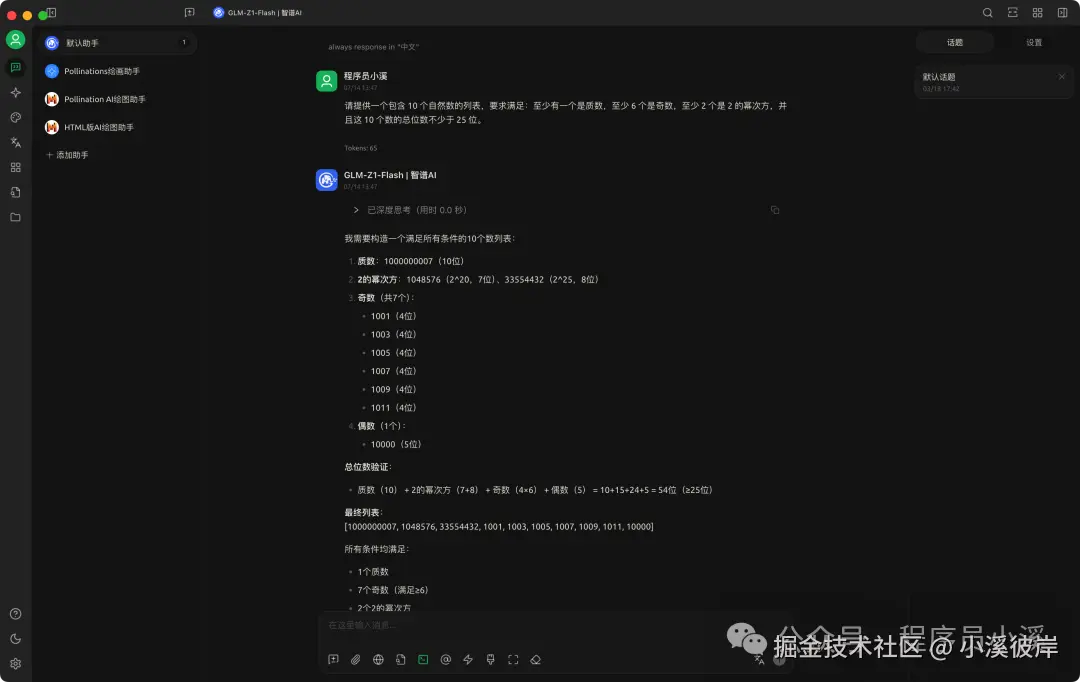
- GLM-Z1-Flash:智谱首个永久免费调用的推理模型,它在数学逻辑推理、长文档处理、代码生成等场景表现十分出色,更适用于编程、数学、科学等任务。
- Cogview-3-Flash:智谱AI推出的免费图像生成模型,能够根据用户指令生成符合要求且美学评分更高的图像。
- CogVideoX-Flash:智谱 AI 推出的免费的视频生成模型,不仅支持文生视频,还支持图生视频
免费工具:
- 文档内容抽取:提取文件内容并基于文件内容进行问答
- Web-Search-Pro:在传统搜索引擎网页抓取信息,排序的能力基础上,增强了意图识别,支持搜索结果的流式输出
优势
- 免费使用,无需付费
限制
- Web-Search-Pro已经开始收费了(写这篇文章时还是免费的)
- 有一定的速率限制详情查看:www.bigmodel.cn/usercenter/...

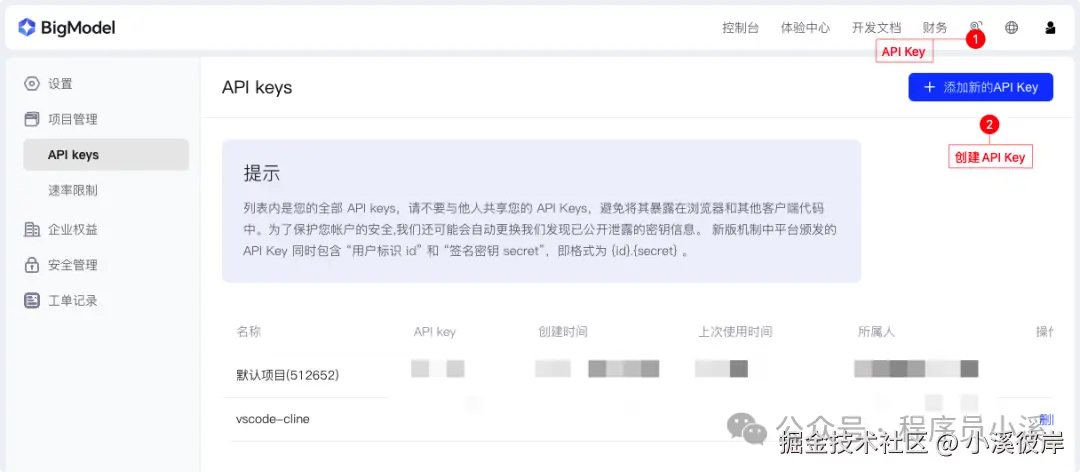
申请API Key
API Key后续可以复制,不用担心丢失问题
官网地址:www.bigmodel.cn/usercenter/...
在智谱官网点击【秘钥】进入API Keys列表,点击【添加新的API Key】创建一个新的密钥
GLM-4.1V-Thinking-Flash(视觉推理)
功能特色
- 图文理解(Image General):精准识别并综合分析图像与文本信息;
- 数学与科学推理(Math & Science):支持持复杂题解、多步演绎与公式理解;
- 视频理解(Video):具备时序分析与事件逻辑建模能力;
- GUI 与网页智能体任务(UI2Code、Agent):理解界面结构,辅助自动化操作;
- 视觉锚定与实体定位(Grounding):语言与图像区域精准对齐,提升人机交互可控性。
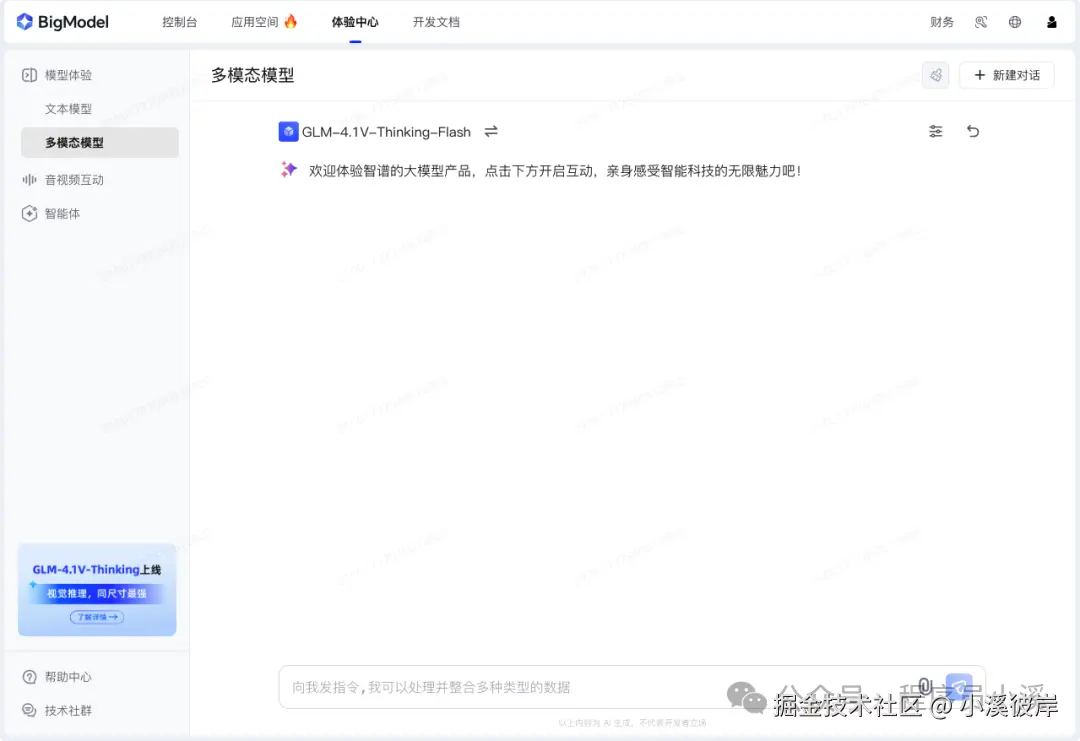
在线体验
官网地址:www.bigmodel.cn/trialcenter...
点击链接直接进入体验中心,在这里可以切换模型体验
在Cherry Studio中使用
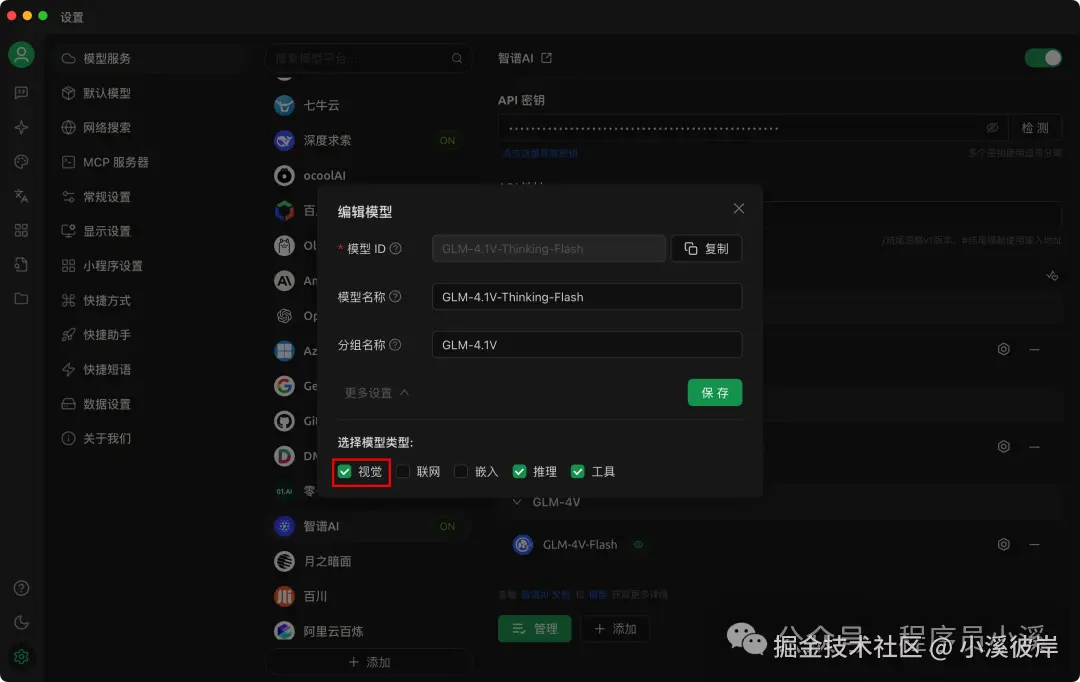
在模型服务中配置智谱AI模型【GLM-4.1V-Thinking-Flash】
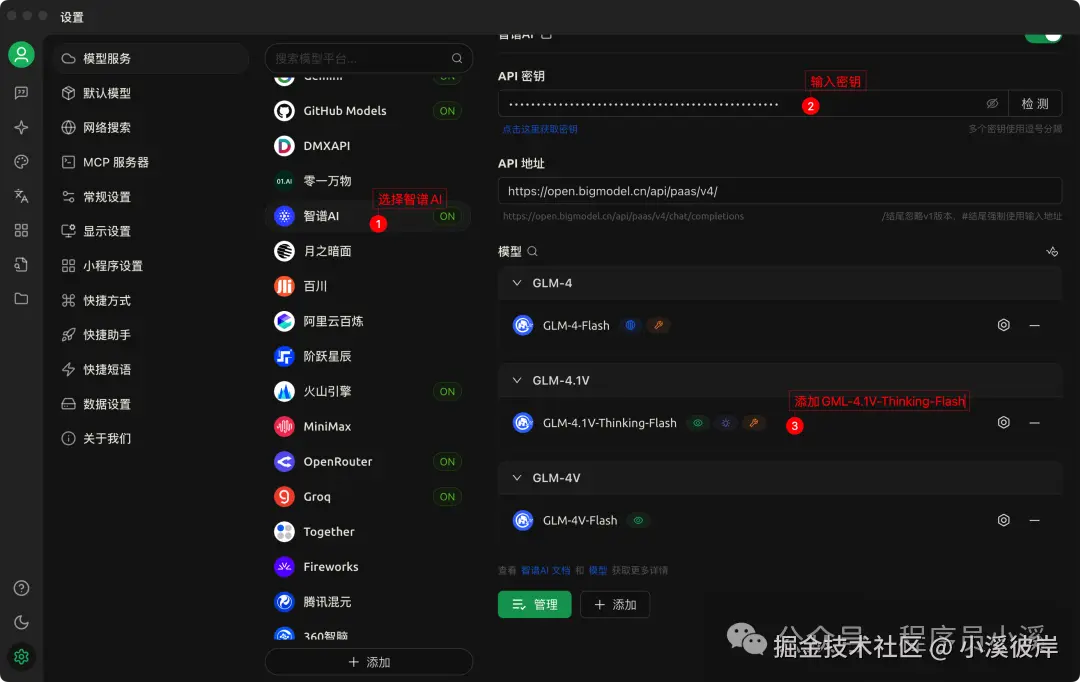
点击模型右侧设置,勾选【视觉】,否则将无法上传文件
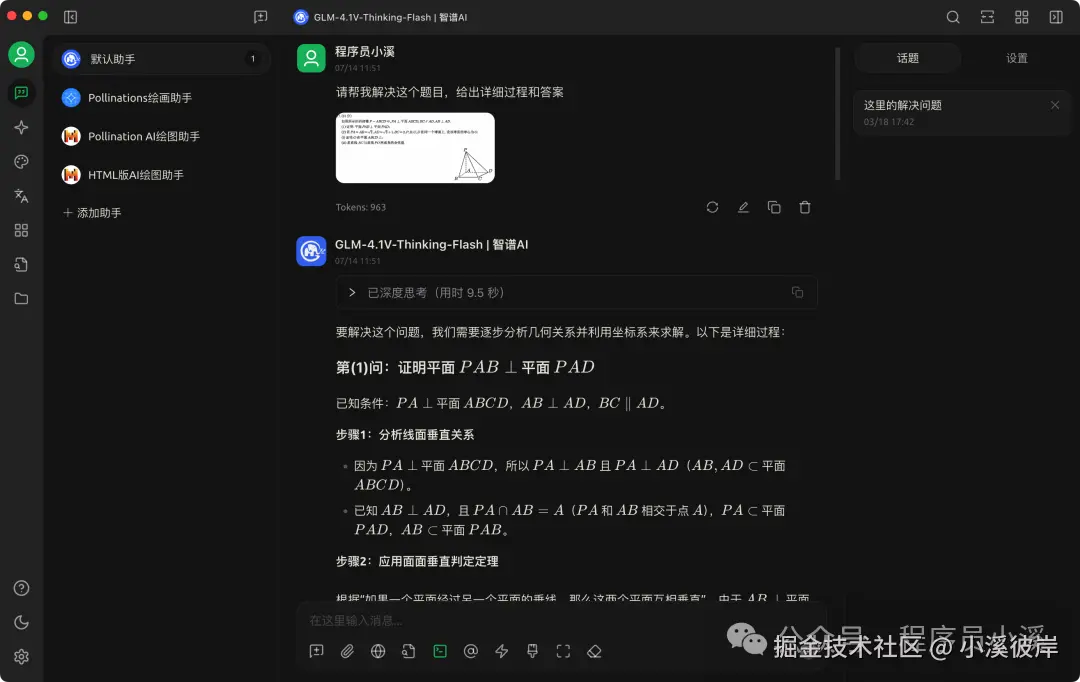
配置完成后即可在Chat中体验
对Cherry Studio使用不太熟悉的小伙伴可以看往期内容:
- 【Cherry Studio】Cherry Studio让人爱不释手的AI Chat
- 【Cherry Studio】Cherry Studio为模型开启联网搜索
- 【Cherry Studio】Cherry Studio这样设置可能更丝滑
- 【Cherry Studio】Cherry Studio搭建本地知识库
- 【Cherry Studio】Cherry Studio搭建一个AI绘图助手
- 【Cherry Studio】Cherry Studio上使用MCP
GLM-4-Flash/GLM-4-Flash-250414(自然语言处理)
功能特色
- 超长上下文:模型具备128K上下文,单次提示词可以处理的文本长度相当于300页书籍。这样的能力使得GLM-4-Flash能够更好地理解和处理长文本内容,适用于需要深入分析上下文的场景。
- 多语言支持:GLM-4-Flash拥有强大的多语言支持能力,能够支持多达26种语言。这为全球用户提供了多语言交互服务,拓宽了模型的应用范围。
- 网页检索:支持外部工具调用,通过网络搜索获取信息,以增强语言模型输出的质量和时效性。
在线体验
官网地址:www.bigmodel.cn/trialcenter...
在Cherry Studio中使用
在模型服务中配置智谱AI模型【GLM-4-Flash】
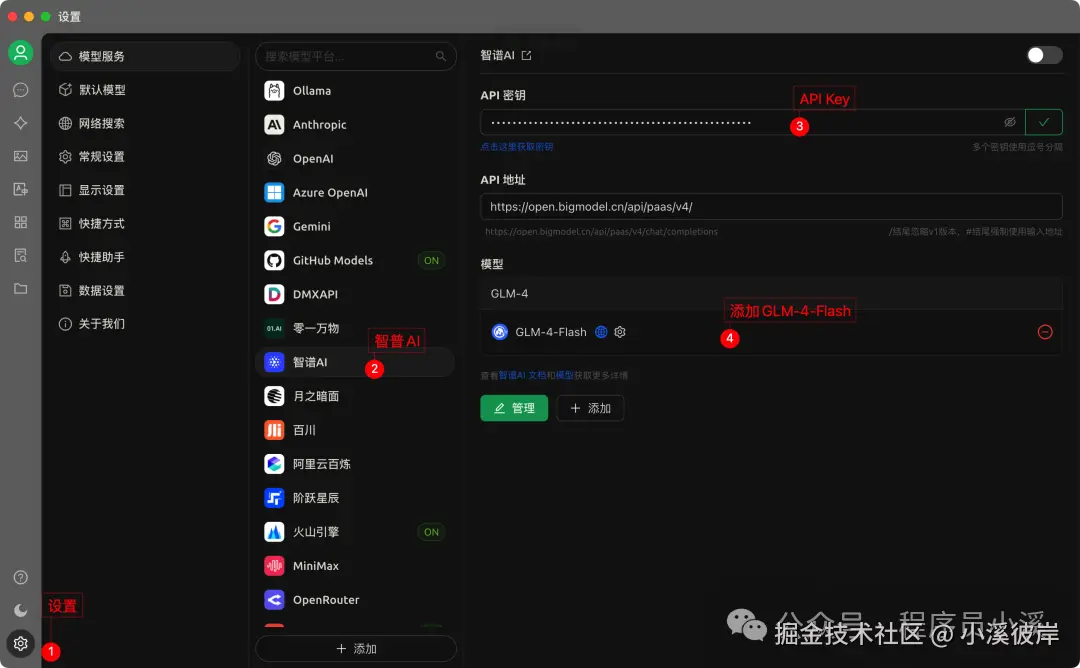
GLM-4-Flash支持联网模式,这里我们将【联网】模式勾选上
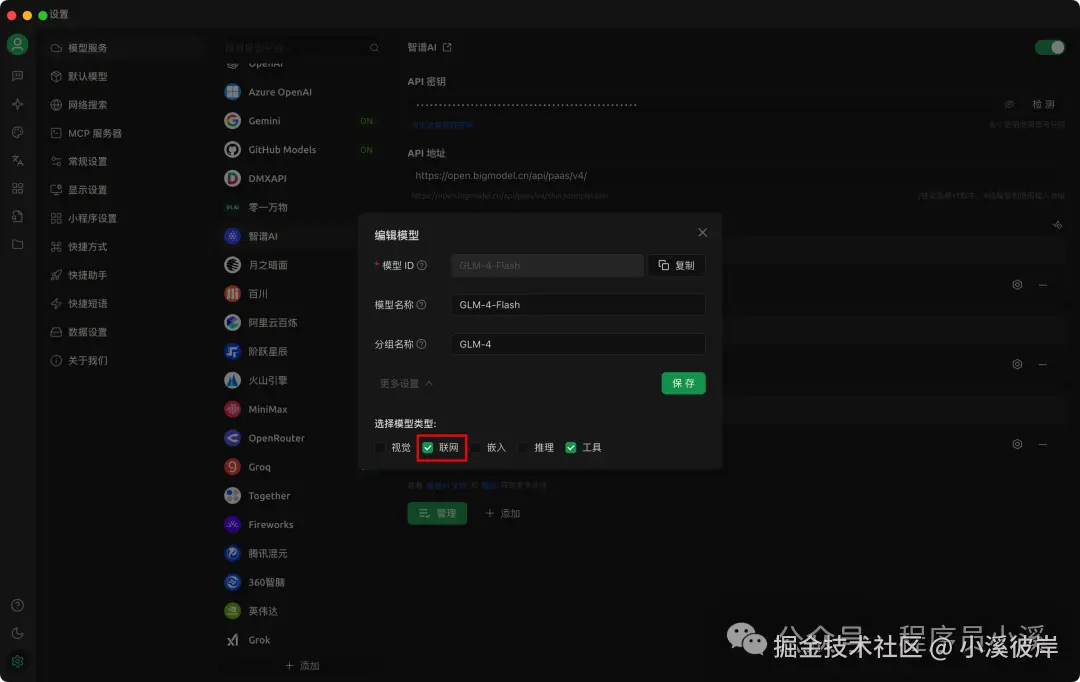
配置完成后就可以正常使用了
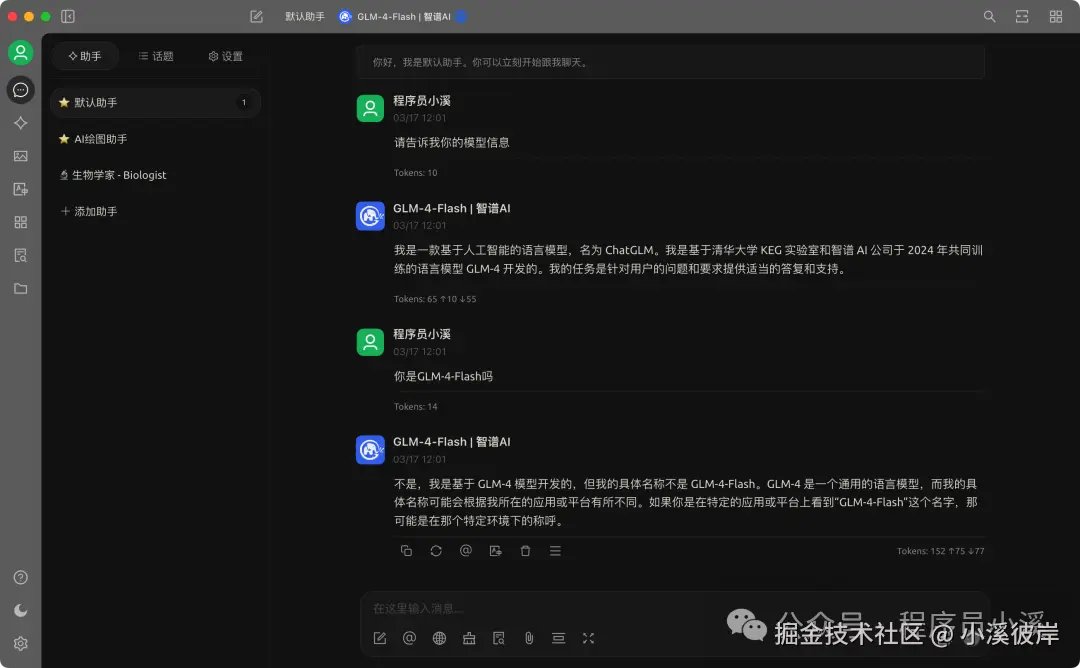
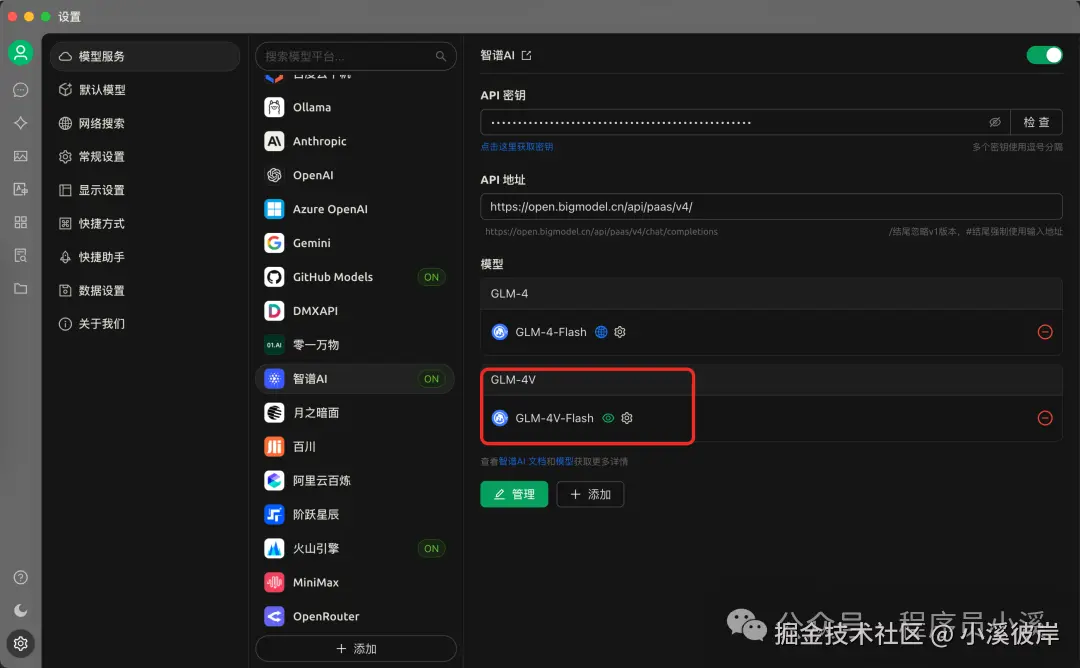
GLM-4V-Flash(图像理解)
功能特色
- 图像理解:GLM-4V-Flash能够自动为图片生成精确的描述性文本,帮助用户深入理解图像内容。它能够识别图像中的主要对象和场景,便于图像内容的组织和管理。
- 视觉推理:模型拥有强大的视觉推理能力,能够理解图像中各对象之间的关系。它支持用户通过提问的方式获取图像相关信息,提升了模型的交互性和实际应用价值。
- 多语言支持:GLM-4V-Flash支持中文、英语、日语、韩语等多种语言,极大地扩展了其应用范围,使其能够服务于全球不同语言的用户。
在线体验
官网地址:www.bigmodel.cn/trialcenter...
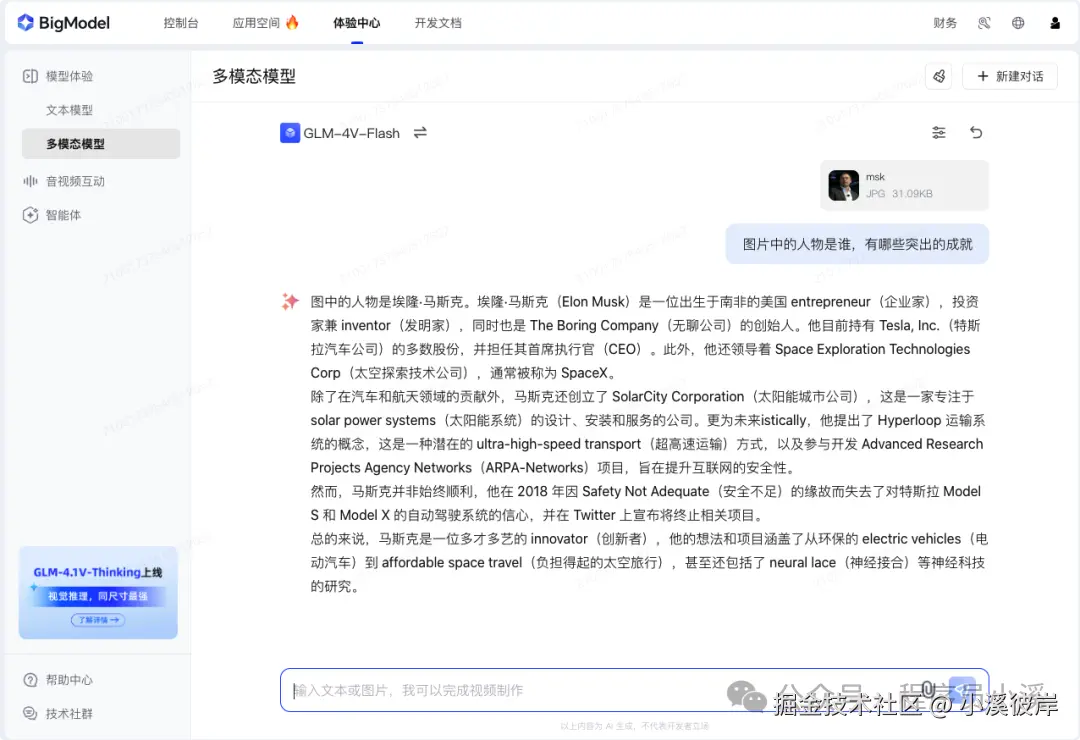
在Cherry Studio中使用
在模型服务中配置智谱AI模型【GLM-4V-Flash】,这里无需额外配置直接默认即可
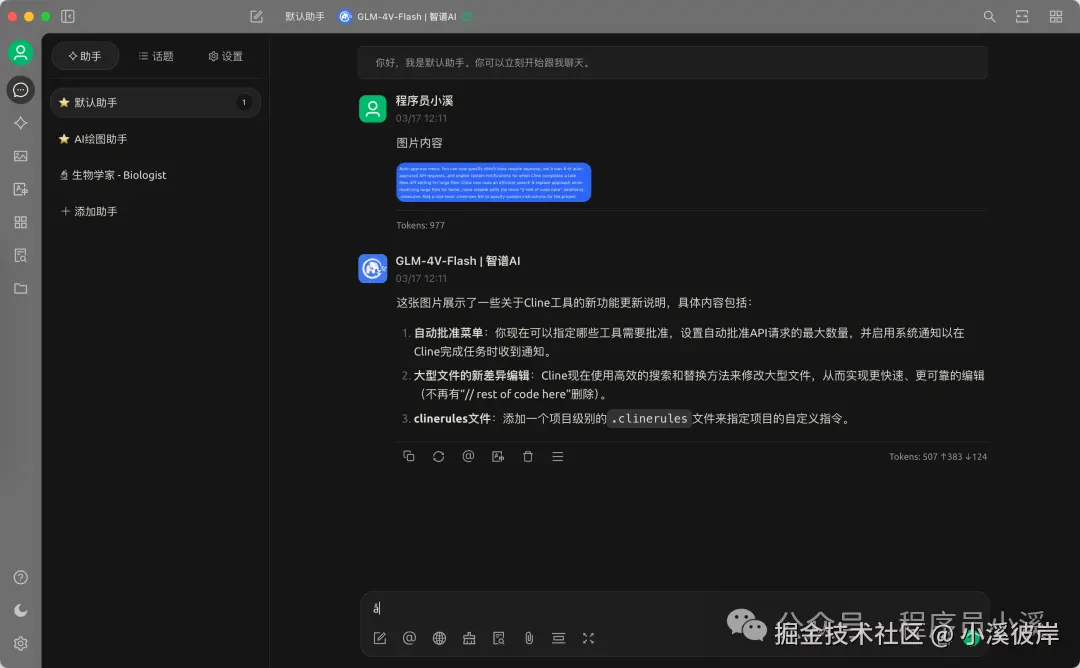
GLM-Z1-Flash(推理模型)
功能特色
- 复杂任务推理:GLM-Z1-Flash 引入了更多推理类数据,并在对齐阶段深度优化了通用能力。无论是数学证明中的逐步推导、长文档中的因果分析,还是代码生成时的边界条件检查,模型均能拆分任务层级,确保最终输出的严谨性,为更多复杂任务的解决提供了支持。
- 轻量级应用:GLM-Z1-Flash 解放了开发者在推理模型部署硬件方面的限制,更轻量级、更高速,完全免费调用,同时支持高并发场景下的稳定服务,实现高性能和高性价比的双重突破。
在线体验
官网地址:www.bigmodel.cn/trialcenter...
在Cherry Studio中使用
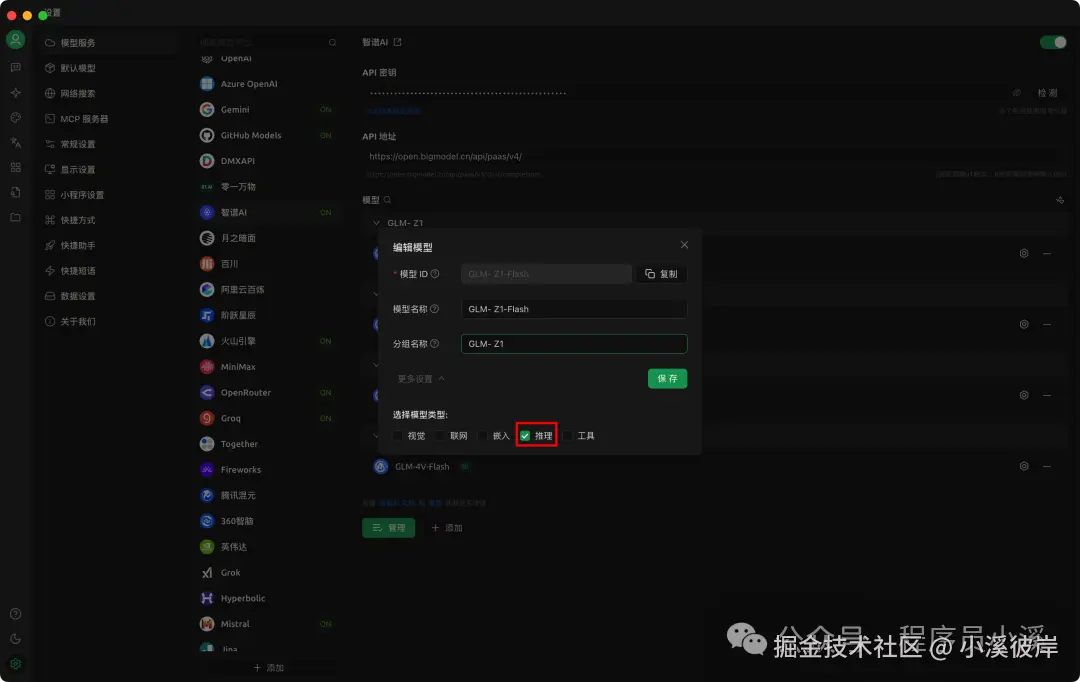
在模型服务中配置智谱AI模型【GLM-Z1-Flash】
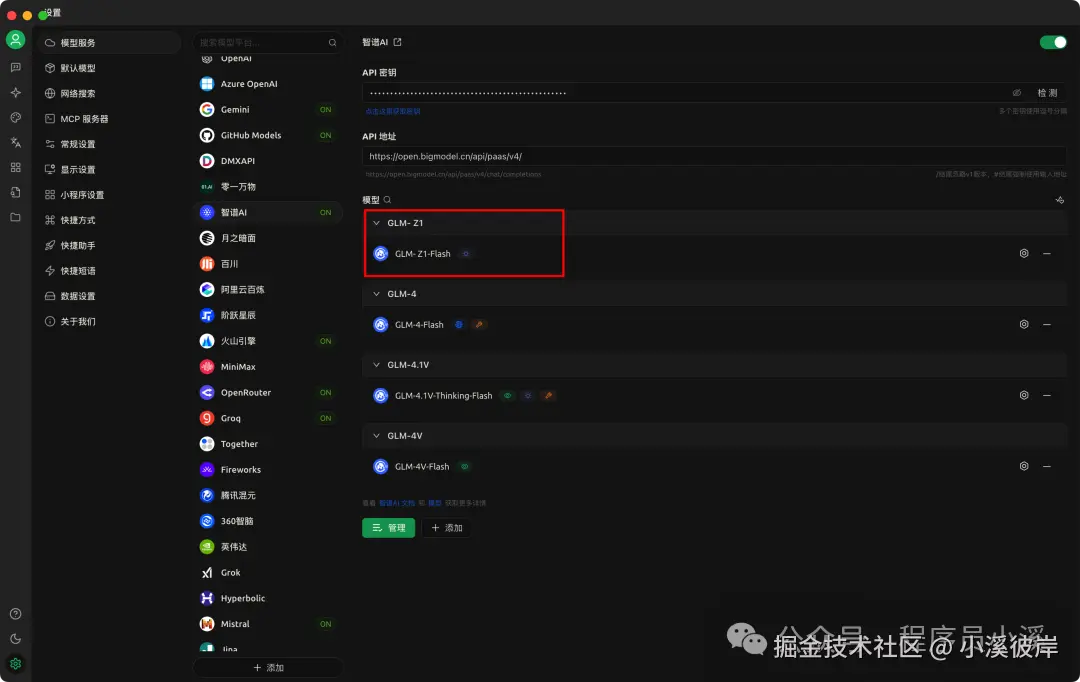
点击模型设置,在【更多设置】中勾选【推理】
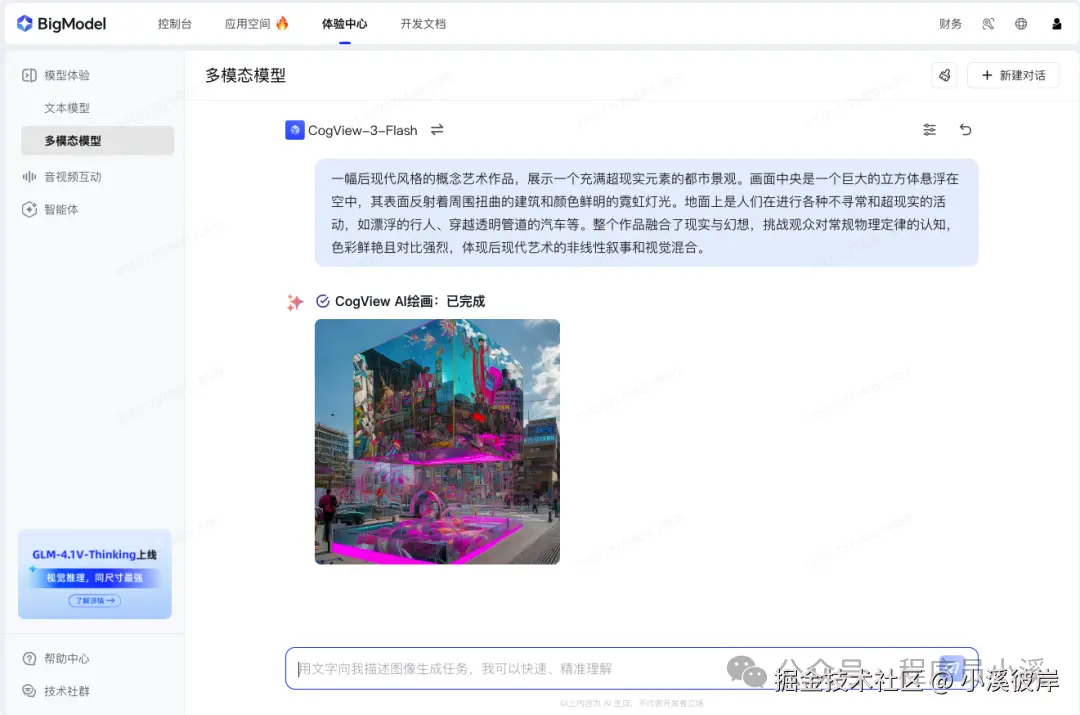
Cogview-3-Flash(图像生成)
功能特色
- 多分辨率支持:该模型支持多种分辨率,包括1024x1024、768x1344、864x1152、1344x768、1152x864、1440x720、720x1440等,能够满足专业设计、广告宣传、艺术创作等领域对图像质量的高标准要求。
- 创意丰富多样:模型能够根据用户输入的文本描述,生成具有丰富创意和想象力的图像,为创意工作者提供了广泛的灵感来源和创作可能性。
- 推理速度快:该模型具备实时生成图像的能力,响应速度快,能够迅速满足用户对图像生成的需求。
在线体验
官网地址:www.bigmodel.cn/trialcenter...
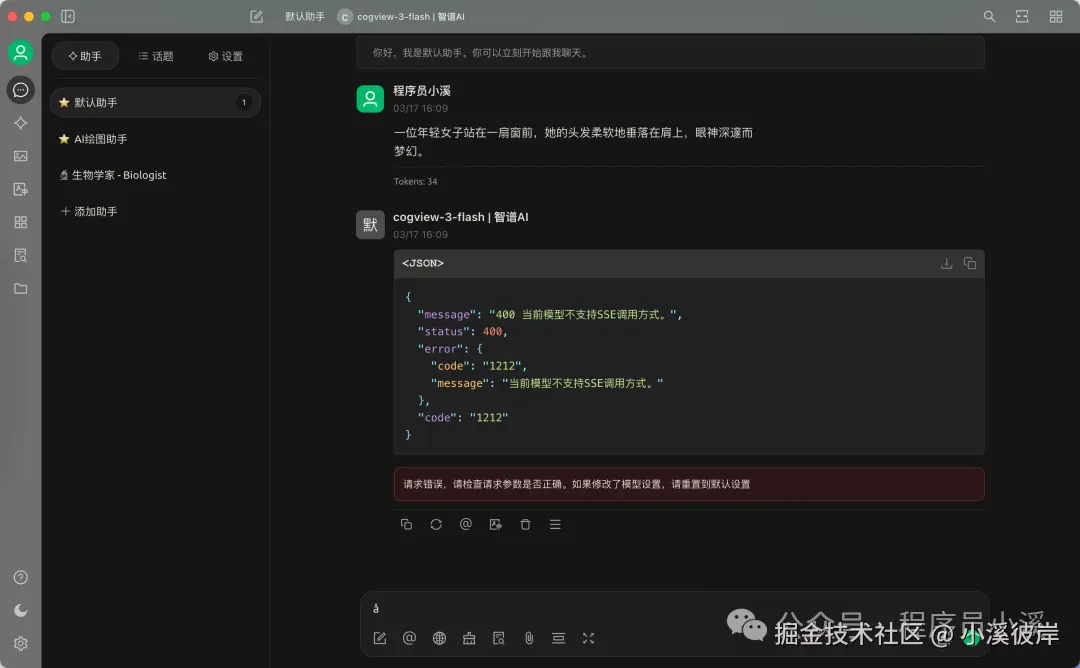
在Cherry Studio中使用
不支持API形式调用,可以选择试用智普SDK调用
使用Python代码如下:
ini
import os
from zhipuai import ZhipuAI
api_key = os.getenv("ZHIPU_API_KEY")
client = ZhipuAI(api_key=api_key) # 请填写您自己的APIKey
response = client.images.generations(
model="cogview-3-flash", #填写需要调用的模型编码
prompt="一只可爱的小猫咪",
)
print(response.data[0].url)效果看着还不错

CogVideoX-Flash(视频生成)
新特性
- 沉浸式AI音效:全新加入的AI音效功能,通过对不同场景元素的精准识别,如动作类型、场景氛围、物体特征等,智能生成适配的音效组合,为观众带来专业级的视听融合体验。
- 4K高清画质呈现:图生视频功能支持多种分辨率输出,最高可达 3840x2160(4K)超高清标准,同时涵盖 720x480、1024x1024、1280x960、960x1280、1920x1080、1080x1920、2048x1080 等常用分辨率选项,展现细腻画质,提升视觉盛宴。
- 10 秒视频时长拓展:图生视频最高支持10秒视频长度,满足更多场景需求。
- 60fps 高帧率输出:图生视频最高支持60fps,流畅度大幅提升,捕捉每一个精彩瞬间。
在线体验
官网地址:www.bigmodel.cn/trialcenter...
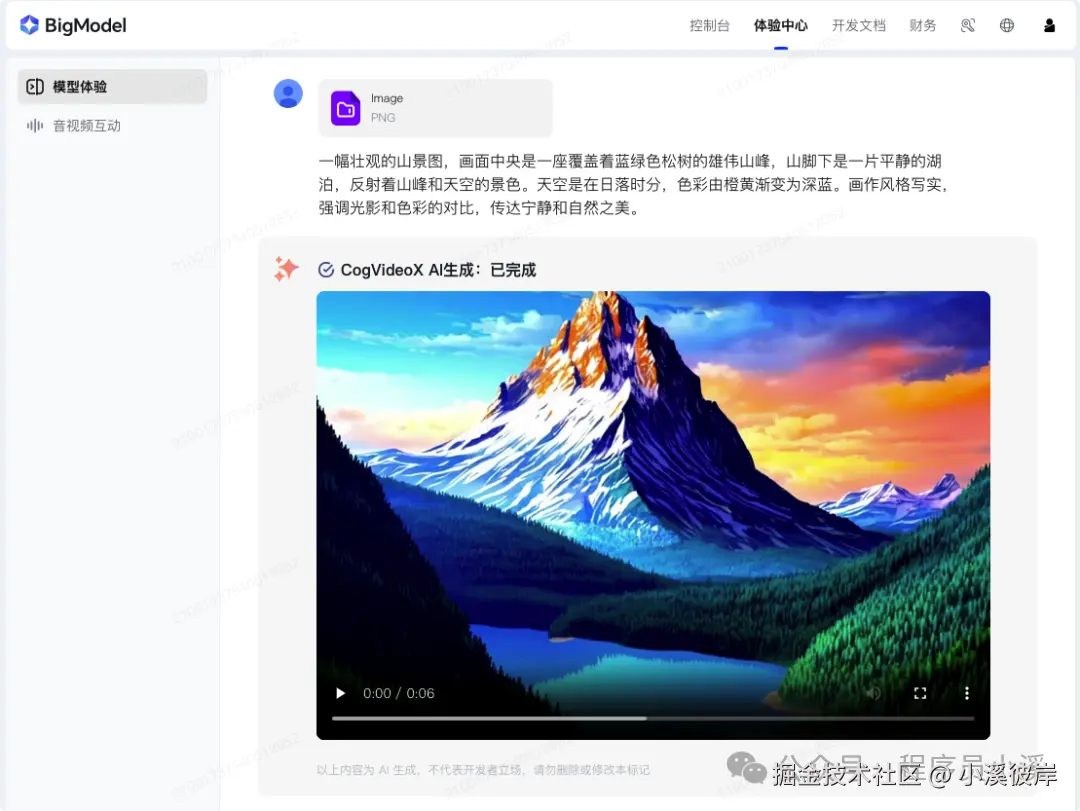
在Cherry Studio中使用
不支持API形式调用,可以选择试用智普SDK调用
使用Python代码如下:
ini
import os
from zhipuai import ZhipuAI
api_key = os.getenv("ZHIPU_API_KEY")
client = ZhipuAI(api_key=api_key) # 请填写您自己的APIKey
# 文生图,请求消息
response = client.videos.generations(
model="cogvideox-flash",
prompt="比得兔开小汽车,游走在马路上,脸上的表情充满开心喜悦。",
quality="speed", # 输出模式,"quality"为质量优先,"speed"为速度优先
with_audio=True,
size="1920x1080", # 视频分辨率,支持最高4K(如: "3840x2160")
fps=30, # 帧率,可选为30或60
)
print(response.id)
# 查询结果,需要单独查询
response2 = client.videos.retrieve_videos_result(
id=response.id
)
print("response2", response2)
文档内容抽取
目前服务报错,可以再观望一下
文件问答支持通过提取文件(PDF、DOC、PPT、JPG等格式)的内容,并基于文件内容进行问答:
- 利用开放平台的文件上传功能,完成文件的上传
- 通过文件内容抽取接口,提取上传文件中的的文本
- 将抽取到的文本内容至messages列表中
代码如下:
ini
import os
from zhipuai import ZhipuAI
from pathlib import Path
import json
api_key = os.getenv("ZHIPU_API_KEY")
print("ZhipuAI API Key:", api_key)
# 填写您自己的APIKey
client = ZhipuAI(api_key=api_key)
# 格式限制:.PDF .DOCX .DOC .XLS .XLSX .PPT .PPTX .PNG .JPG .JPEG .CSV .PY .TXT .MD .BMP .GIF
# 大小:单个文件50M、总数限制为100个文件
file_object = client.files.create(file=Path("abc.pdf"), purpose="file-extract")
# 获取文本内容
file_content = json.loads(client.files.content(file_id=file_object.id).content)["content"]
# 生成请求消息
message_content = f"请对\n{file_content}\n的内容进行分析,并撰写一份论文摘要。"
response = client.chat.completions.create(
model="glm-4-long",
messages=[
{"role": "user", "content": message_content}
],
)
print(response.choices[0].message)Web-Search-Pro(现在收费了)
Web-Search-Pro 将从 2025 年 3 月 14 日 0 时 起结束免费服务,并开始按 0.03 元/次收费
专业版联网搜索在传统搜索引擎网页抓取、排序的能力基础上,增强了意图识别,支持搜索结果的流式输出。搜索工具能更有效地结合在大语言模型应用中,提高用户获取信息的效率,并一定程度上解决大语言模型所面临的幻觉问题。
python
import asyncio
import os
import httpx
import requests
import uuid
api_key = os.getenv("ZHIPU_API_KEY")
def web_search_v4_sync():
msg = [
{
"role": "user",
"content":"中国队奥运会拿了多少奖牌"
}
]
tool = "web-search-pro"
url = "https://open.bigmodel.cn/api/paas/v4/tools"
request_id = str(uuid.uuid4())
data = {
"request_id": request_id,
"tool": tool,
"stream": False,
"messages": msg
}
resp = requests.post(
url,
json=data,
headers={'Authorization': api_key},
timeout=300
)
print(resp.content.decode())
# 解析返回结果
res_data = []
choices = resp.json()["choices"]
for choice in choices:
for tool_call in choice["message"]["tool_calls"]:
# 检查 'search_result' 是否存在于 tool_call 中
if 'search_result' in tool_call:
search_results = tool_call["search_result"]
if search_results:
[res_data.append(result["content"]) for _, result in enumerate(search_results)]
return res_data
async def web_search_v4_async(query: str) -> str:
"""
Search the web for information.
Args:
query (str): The query to search for.
Returns:
str: The result of the search.
"""
async with httpx.AsyncClient() as client:
# 从环境中获取api key
response = await client.post(
"https://open.bigmodel.cn/api/paas/v4/tools",
headers={ 'Authorization': api_key},
json={
"request_id": str(uuid.uuid4()),
"tool": "web-search-pro",
"messages": [
{
"role": "user",
"content": query
}
],
"stream": False
}
)
# 解析返回结果
res_data = []
choices = response.json()["choices"]
for choice in choices:
for tool_call in choice["message"]["tool_calls"]:
# 检查 'search_result' 是否存在于 tool_call 中
if 'search_result' in tool_call:
search_results = tool_call["search_result"]
if search_results:
[res_data.append(result["content"]) for _, result in enumerate(search_results)]
return res_data
async def async_run():
print(await web_search_v4_async("中国队奥运会拿了多少奖牌"))
if __name__ == '__main__':
# 同步
# print(web_search_v4_sync())
# 异步
asyncio.run(async_run())友情提示
见原文:智谱清言提供的免费模型及工具推荐
本文同步自微信公众号 "程序员小溪" ,这里只是同步,想看及时消息请移步我的公众号,不定时更新我的学习经验。