背景
ClickHouse 介绍
ClickHouse 由 Yandex 于 2016 年开源,是一款高性能列式 OLAP 数据库。凭借列式存储、向量化执行和高压缩率,它在日志分析、广告投放、金融风控等场景中表现突出。ClickHouse 的高性能来自 MergeTree 表引擎族的分区与索引设计,查询和后台合并能并行处理,结合分片与副本的原生分布式架构,在 PB 级数据下依然能保持毫秒级响应。
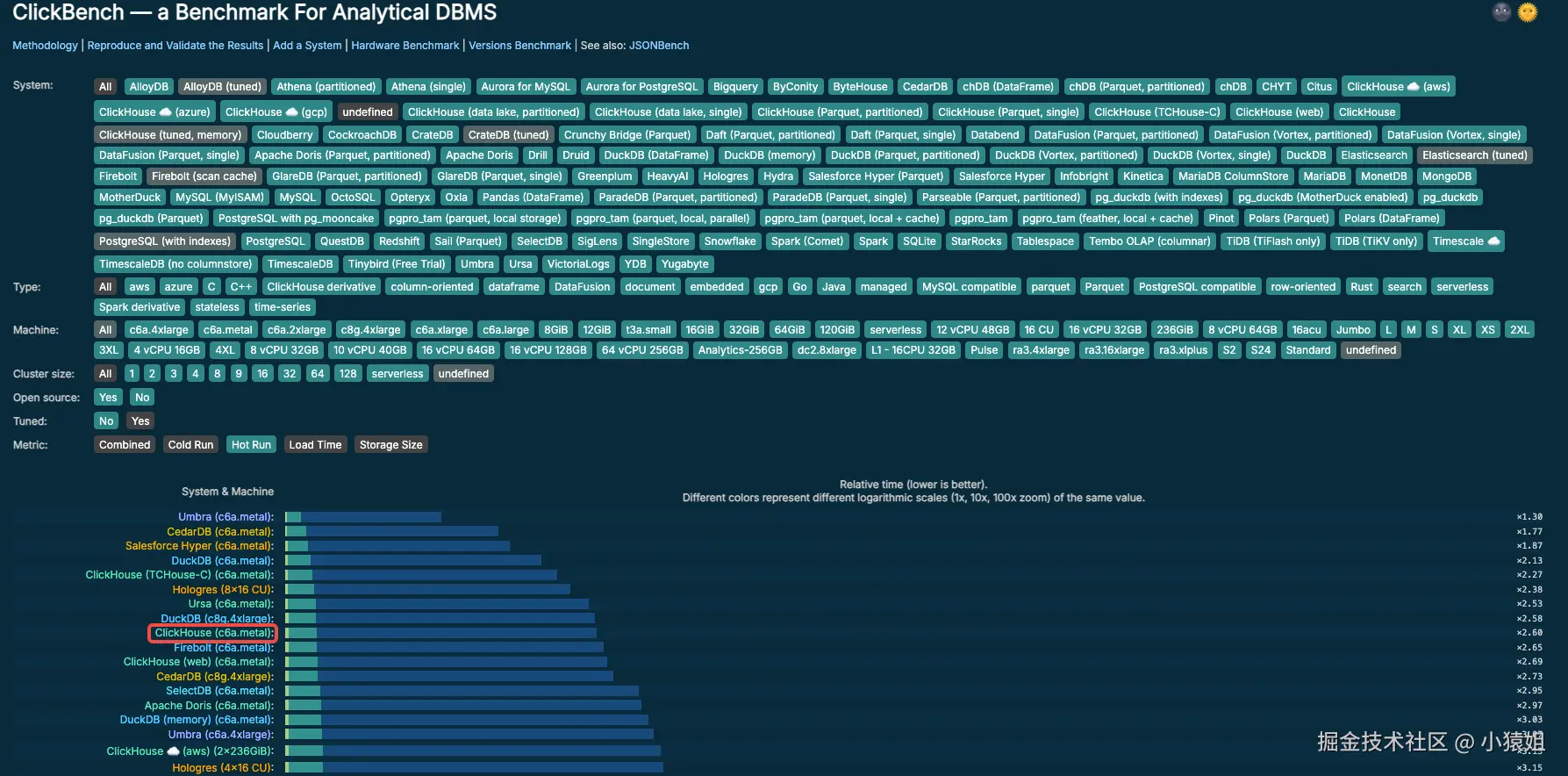
然而,极致性能的背后是较高的运维复杂度。许多团队在实践中发现,将 ClickHouse 部署到企业级生产环境并非易事,主要挑战集中在:
- 分布式架构复杂性:分片、副本规划,Keeper/ZooKeeper 元数据一致性管理
- 运维门槛高:参数配置繁琐、扩缩容与故障恢复依赖人工干预
- 性能调优困难:参数体系庞杂、资源协调复杂、查询优化需持续迭代
ClickHouse 的容器化之路,远不止于用 StatefulSet 进行简单的实例封装。这种方式无法根除集群管理、数据可靠性等固有的运维难题。
ClickHouse Operator
要在生产环境用好 ClickHouse,将复杂的运维知识转化为自动化能力是关键,K8s Operator 就能提供这个能力,它通过将集群配置、扩缩容、故障恢复等操作标准化和自动化,极大地减少了人工接入。
在 ClickHouse 生态中,目前社区最活跃的方案是 Altinity ClickHouse Operator。它通过定制 CRD 实现了 ClickHouse 集群的声明式管理,涵盖用户与配置管理、扩缩容、版本升级、与 Prometheus 的监控集成等功能。
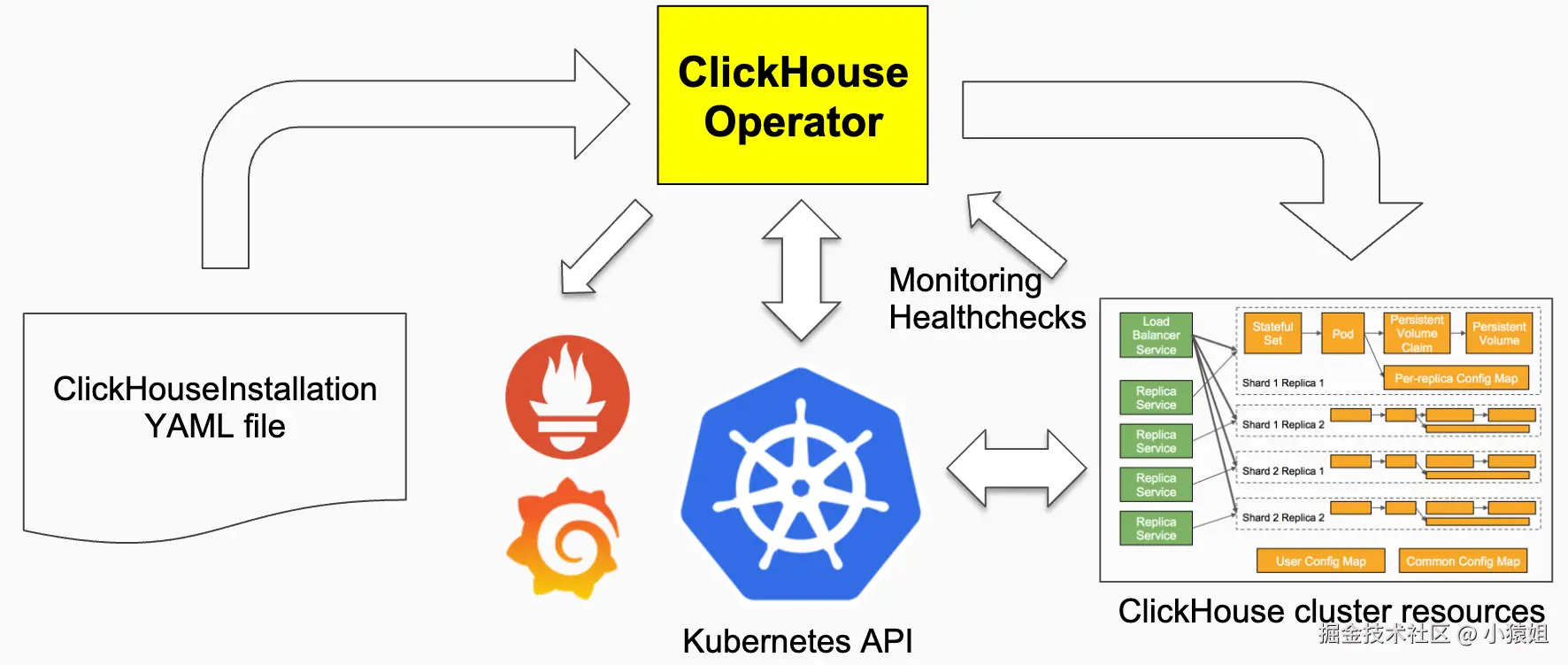
Altinity Operator 在 ClickHouse 领域非常成熟,能够深入支持 ClickHouse 的各种特性与配置。不过,由于它是一种专注于 ClickHouse 的垂直方案,如果团队需要同时管理多种数据库,就可能面临工具栈割裂、运维方式不统一的问题。
KubeBlocks 介绍
KubeBlocks 也是一个 K8s Operator,提供了一个面向不同数据库引擎的通用 API,通过定义[ClusterDefinition](https://kubeblocks.io/docs/preview/user_docs/references/api-reference/cluster#apps.kubeblocks.io/v1.ClusterDefinition)、[ComponentDefinition](https://kubeblocks.io/docs/preview/user_docs/references/api-reference/cluster#apps.kubeblocks.io/v1.ComponentDefinition)、[ShardingDefinition](https://kubeblocks.io/docs/preview/user_docs/references/api-reference/cluster#apps.kubeblocks.io/v1.ShardingDefinition)、[ComponentVersion](https://kubeblocks.io/docs/preview/user_docs/references/api-reference/cluster#apps.kubeblocks.io/v1.ComponentVersion)等 CRD,将数据库集群抽象化,使用户能够像"搭积木"一样灵活组合和运维。
在 ClickHouse 场景下,KubeBlocks 提供了开箱即用的能力,包括:
- 集群的高可用部署与自动选主
- 分片与副本的全生命周期管理
- 内置备份与恢复机制
- 与 Prometheus/Grafana 集成的监控与告警
- 弹性扩缩容与滚动升级
通过这些能力,用户无需编写复杂的运维脚本,也不必学习 ClickHouse 专用 Operator 的使用方式,而是可以直接通过 KubeBlocks 统一的 API,在 K8s 上获得生产级的 ClickHouse 集群治理体验。
横向对比
KubeBlocks 和 Altinity ClickHouse Operator 的架构设计体现了两种不同的工程理念。
- Altinity ClickHouse Operator 采用垂直集成的设计模式。它将 ClickHouse 的运维逻辑封装在单一的
ClickHouseInstallationCRD 中,通过深度绑定实现对 ClickHouse 生态的精细控制,适合专门管理 ClickHouse 集群的各种场景 - KubeBlocks 则采用水平抽象的设计模式。核心是统一的 Cluster API,并通过 ComponentDefinition 和 Addon 机制实现数据库引擎的可插拔支持。相比 StatefulSet,KubeBlocks 设计了专门的 InstanceSet 来管理有状态工作负载。InstanceSet 不只是 StatefulSet 的替代品,而是在此基础上的增强:它具备 Pod 角色感知、支持灵活定义分片/副本拓扑,并能实现并行滚动更新与故障自愈,从而赋予数据库运维更高的自治能力。 这种设计让运维团队能够用统一的接口管理异构数据库环境,显著降低学习成本和运维复杂度。
ClickHouse Addon 实现
本节介绍 ClickHouse 集群管理、高可用、参数配置、备份恢复等能力在 KubeBlocks 1.0 API 的实现。我们基于 KubeBlocks 的搭积木理念,拆分了 ClickHouse 和 ClickHouse Keeper 两个 Component,为 ClickHouse Addon 实现了基本的生产可用的能力。
集群管理
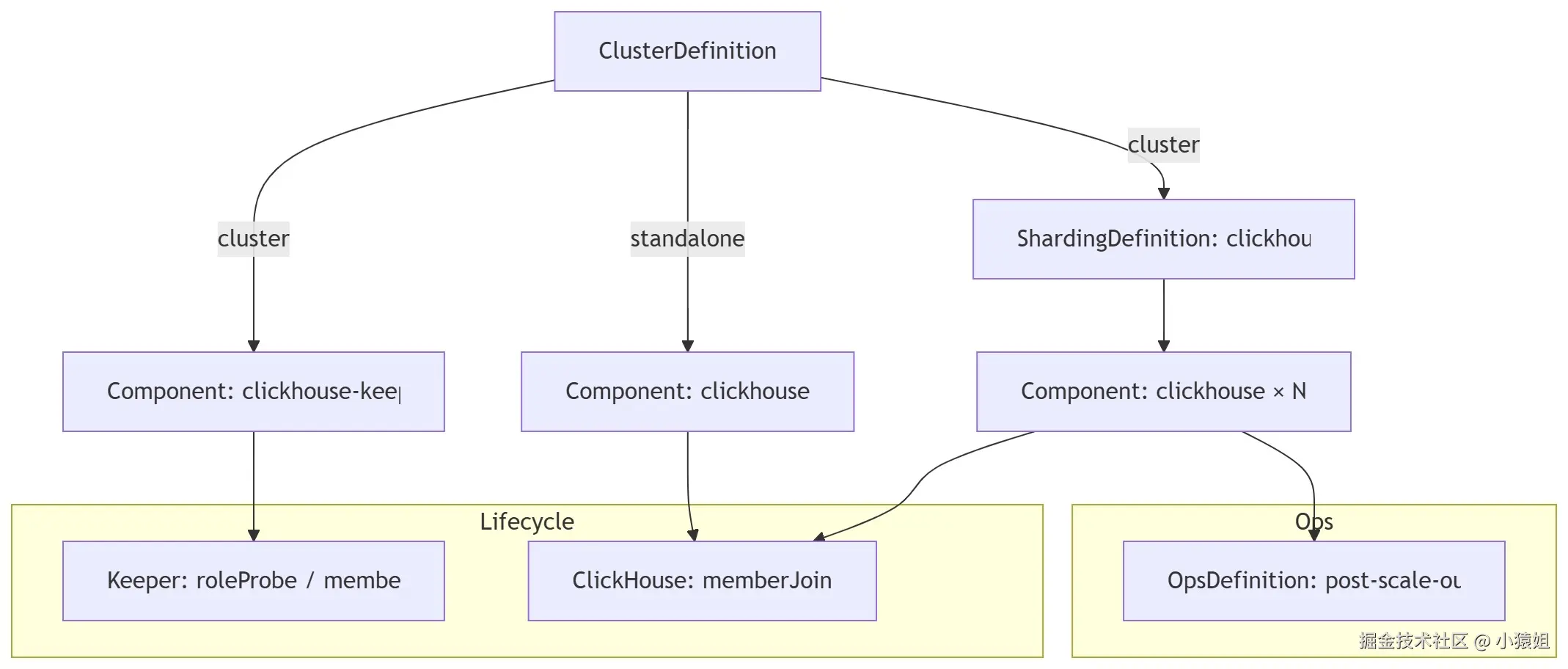
ClickHouse 集群的生命周期管理与运维主要涵盖以下对象与职责如下:
- ClusterDefinition:定义拓扑模式与组件编排
- standalone 模式:仅包含 clickhouse component
- cluster 模式:包含 clickhouse-keeper component 与 clickhouse sharding,通过定义顺序保证先创建 ClickHouse Keeper,随后并发创建 ClickHouse 的各分片
- ShardingDefinition:关联 clickhouse component,限定分片上下限并设置并行的创建/更新策略,用于在扩缩容与拓扑变更时并行推进分片操作
- ComponentVersion:声明支持的版本与镜像的映射关系
- ComponentDefinition(clickhouse/clickhouse-keeper):精确定义组件形态与生命周期管理
- Services:暴露服务端口,包括 ClickHouse 查询端口、ClickHouse 与 ClickHouse Keeper 之间的互联端口、metrics 采集端口,ClickHouse Keeper 组件还额外暴露 Raft 成员通信的端口
- Volumes/ConfigMap:挂载数据卷与配置模板(包括 ClickHouse service/user/client 的 XML 配置文件),脚本通过 ConfigMap 挂载到容器内部
- SystemAccounts:内置 admin 账号,Secret 由 KubeBlocks 生成并注入为环境变量供容器使用
- TLS:可选启用,统一证书挂载路径,并联动端口与TLS配置
- LifecycleActions:
- ClickHouse:实现 memberJoin(新副本加入时复制数据库与表元数据)
- ClickHouse Keeper:实现 roleProbe/switchover/memberJoin/memberLeave(角色探测、主备切换与成员增删)
- Runtime/Entrypoint:容器入口分别为 bootstrap-server.sh 与 bootstrap-keeper.sh,确保按约定初始化,并监听ConfigMap对应容器内配置文件的改动
- Vars:注册端口、TLS 状态、分片/副本 FQDN 列表、集群名称、副本数等环境变量,用于动态渲染配置项,如
remote_servers和macros(shard/replica)等
在这一切的背后,InstanceSet 是真正驱动编排的核心。ClickHouse 与 Keeper 组件都依赖它来保证分片与副本的有序部署与自动恢复,使扩缩容、滚动升级等生命周期操作能够按照角色和拓扑关系正确推进。
当这些"积木"拼装起来时,一个具备自治能力的 ClickHouse 集群便初具雏形。
Sharding 与 Replica
我们如果要进一步讨论 ClickHouse 拓扑结构,就不得不先从 ClickHouse 的表引擎说起。ClickHouse 的表引擎大致可以分为三个种类:
MergeTree引擎族:将数据存储在本地磁盘或外部存储,采用类似 LSM-Tree 的原理,后台任务持续合并有序数据块,支持列式存储、分区、排序、稀疏主键索引等特性。- ReplicatedMergeTree:通过 Keeper 维护表元数据与复制队列,在副本间同步数据分片(part)、合并操作(merge)和变更操作(mutation),保证数据一致性
- 变体:基于 MergeTree 的数据组织能力,提供不同的聚合/去重语义
- ReplacingMergeTree:按主键去重,新版本覆盖旧版本
- SummingMergeTree:对指定列执行求和聚合
- AggregatingMergeTree:存储预聚合函数状态,用于物化视图
- ......
- 特殊用途引擎:
- Distributed:逻辑分布式表,负责查询路由与并行执行,通常与本地 MergeTree 表配合使用(Local+Distributed 双表模式)
- View:视图引擎,数据存储在内存中
- 虚拟表引擎:用于访问外部数据源,如 MySQL/PostgreSQL 等
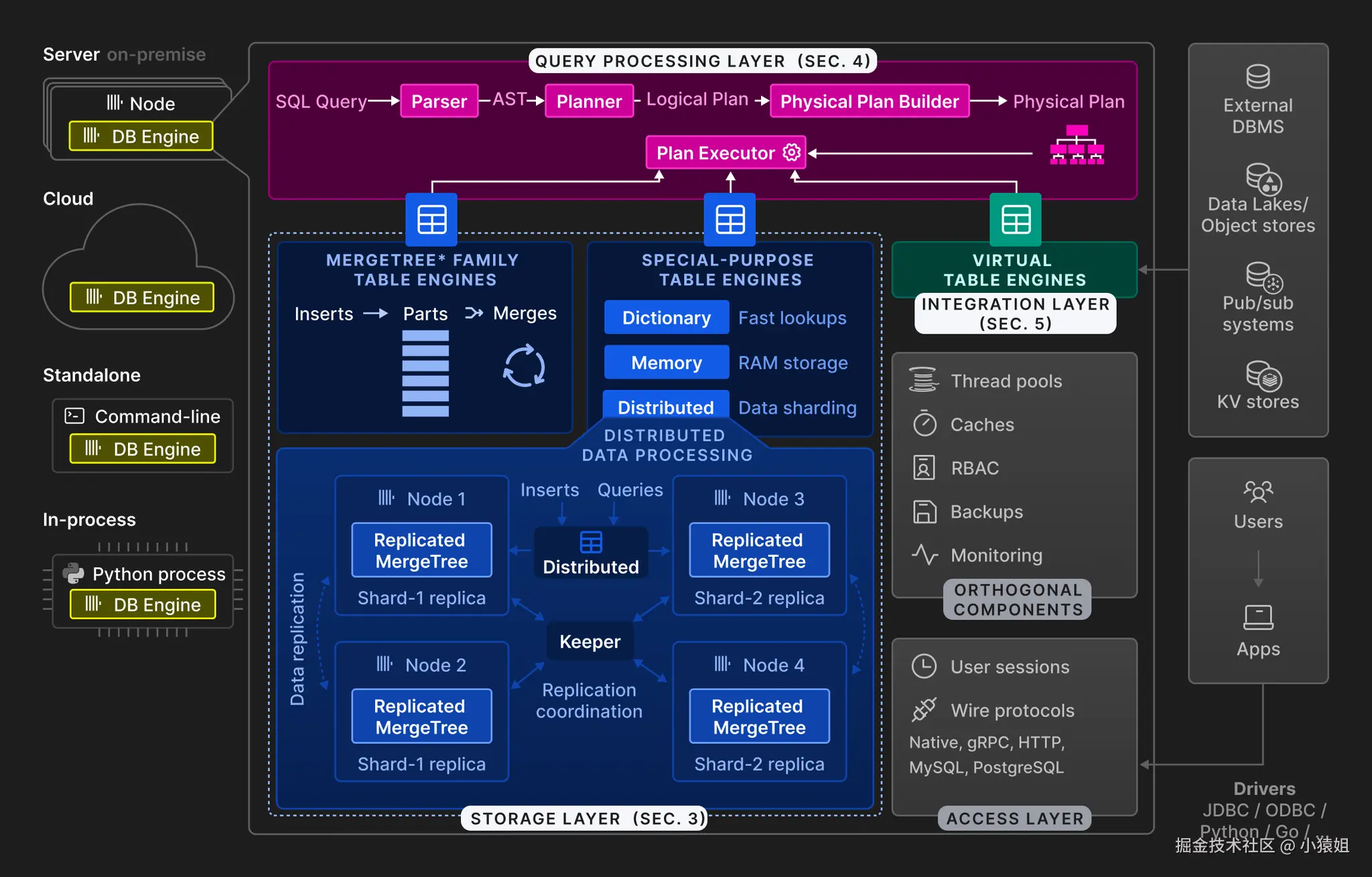
在实际的使用中,ReplicatedMergeTree 和 Distributed 是比较常用的表引擎组合,它们的配合使用体现了 ClickHouse 的分布式架构设计:
- ReplicatedMergeTree 实现副本级别的数据复制,基于配置文件中定义的集群拓扑创建复制表,数据写入时会自动同步到同一分片内的所有副本,确保数据一致性和高可用性
- Distributed 作为分片级别的路由,通常与本地 ReplicatedMergeTree 表配合,形成"本地表+分布式表"的双层架构。Distributed 表负责将查询和写入请求路由到不同分片的本地表,各分片间的数据互不重叠,实现水平分片扩展
执行 DDL 操作时,使用 ON CLUSTER <clusterName> 可将语句自动分发到集群内的所有节点。在 KubeBlocks 的实现中,集群名称通过环境变量 INIT_CLUSTER_NAME 动态注入,如下面 Go 模板片段所示:
XML
<remote_servers>
<{{ .INIT_CLUSTER_NAME }}>
{{- range $key, $value := . }}
{{- if and (hasPrefix "ALL_SHARDS_POD_FQDN_LIST" $key) (ne $value "") }}
<shard>
<internal_replication>true</internal_replication>
{{- range $_, $host := splitList "," $value }}
<replica>
<host>{{ $host }}</host>
{{- if eq (index $ "TLS_ENABLED") "true" }}
<port replace="replace" from_env="CLICKHOUSE_TCP_SECURE_PORT"/>
<secure>1</secure>
{{- else }}
<port replace="replace" from_env="CLICKHOUSE_TCP_PORT"/>
{{- end }}
<user from_env="CLICKHOUSE_ADMIN_USER"></user>
<password from_env="CLICKHOUSE_ADMIN_PASSWORD"></password>
</replica>
{{- end }}
</shard>
{{- end }}
{{- end }}
</{{ .INIT_CLUSTER_NAME }}>
</remote_servers>高可用
ClickHouse 的高可用能力主要通过 KubeBlocks 的 LifecycleActions 接口实现。例如,Switchover 动作可以在 ClickHouse Keeper Leader 节点需要下线时执行自定义脚本进行主节点切换,确保服务连续性。
此外,KubeBlocks 还提供了 OpsDefinition 来处理节点故障场景。当 Pod 迁移到其他节点后,系统会自动从存活节点获取并重建数据库和表结构,简化物理机宕机后的集群恢复流程。
LifecycleActions
LifecycleActions 用于定义 ClickHouse 和 ClickHouse Keeper 两个 Component 在不同生命周期所需执行的动作。
由于 ClickHouse 通常采用 Shared-Nothing 架构(用户也可通过配置 S3 存储插件改为 Shared-Disk 架构),并依赖 Keeper 进行元数据管理,因此 ClickHouse 组件本身需要定义的 LifecycleActions 相对较少。
而 ClickHouse Keeper 作为基于 Raft 协议的分布式协调服务,需要额外定义与集群共识状态相关的LifecycleActions,以确保在节点变更时能够正确维护 Raft 成员之间的一致性。
ClickHouse Member Join
ClickHouse 的水平扩容分为副本扩容和分片扩容两种模式,核心是复制表结构,对于 ReplicatedMergeTree 引擎族的表,还会通过复制机制自动补齐历史数据。
- 副本扩容流程:
- 源节点选择:通过环境变量选取首个正常服务的副本作为同步源
- 数据库同步:枚举 system.databases(排除 system/INFORMATION_SCHEMA),使用
SHOW CREATE DATABASE ... FORMAT TabSeparatedRaw生成 DDL,在新副本执行并校验创建成功 - 表结构同步:从
system.tables读取表信息database, name, uuid,按dependencies_table逆序创建,确保依赖关系正确;自动跳过内部表(名称包含.inner_id.或.inner.)
- 分片扩容流程:与副本扩容类似,区别在于会从不同分片中选择实例作为数据库和表结构的同步源
Keeper Member Join
ClickHouse Keeper 是 Raft-based 的分布式协调服务,水平扩容需要按照 NuRaft (C++ Raft 库)的规范把新 Pod 作为 participant 加入 Raft 集群,并进入 follower/observer 状态。
- Leader 发现:从
CH_KEEPER_POD_FQDN_LIST中排除新成员后探测 Leader,若无 Leader 则直接失败 - 节点标识:从 Pod 名称中提取序号(ordinal),计算
server_id = ordinal + 1(Pod 序号 + 1),验证配置中已包含该 FQDN(KubeBlocks 为每个 Pod 自动生成稳定唯一的 DNS 名称) - 集群加入:执行
reconfig add "server.<id>=<fqdn>:<raft_port>;participant;1" - 状态验证:通过
get '/keeper/config'确认新 FQDN 出现在配置中,且新成员角色为 follower/observer
Keeper Member Leave
节点退出以 get '/keeper/config'查询结果中不再包含退出节点的 FQDN 为准:
- 找到 leader 节点,获取退出者的
server_id,若配置中不存在该成员,幂等返回 - 执行
reconfig remove <server_id>,校验配置不再包含该 FQDN Keeper Role Probe
使用 Keeper 提供的四字命令(4LW)srvr 查询节点角色 leader/follower/observer(standalone 视作 leader)。
Keeper Switchover
Switchover 是有状态服务的主动切主机制,用于在 Leader 计划下线时快速选主,缩短 RTO:
- 角色校验:若当前实例非 Leader,直接退出(KubeBlocks Operator 确保仅在 Leader上触发)
- 候选确定:获取当前配置并确定候选节点,若未指定则选取任意 participant
- 优先级调整:将候选节点优先级设为 8,其余设为 1(通过
reconfig add <base_config;priority>调整选主优先级) - 切主执行:移除当前 Leader,轮询等待候选节点成为新 Leader,最后将原 Leader 以优先级 1 加回 Keeper 集群
参数配置
KubeBlocks 1.0 API 提供了两种配置管理方式:ComponentDefinition 的 config controller 和 parameter controller。前者为默认模式,若在组件定义中设置 externalManaged: true 并配置 ParamConfigRenderer,则由 parameter controller 接管配置变更。ClickHouse Addon使用的是后者,以进行更加精细的配置管理。
- 配置模板:ClickHouse 与 Keeper 通过模板变量动态渲染端口、TLS、remote_servers/zookeeper、prometheus、openSSL/grpc 等配置项
- 参数约束:通过 ParametersDefinition + CUE 校验规则声明参数类型、取值范围和不可变项(如端口、listen_host、macros 等)
- 配置渲染:ParamConfigRenderer 将配置文件注册为渲染目标,在水平扩缩容和分片扩缩容时自动触发重渲染,确保拓扑变化后配置一致性
下面的代码块为 clickhouse ComponentDefinition 中定义的配置信息,externalManaged: true 即使用 parameter controller 进行配置管理
YAML
configs:
- name: clickhouse-tpl
template: {{ include "clickhouse.configurationTplName" . }}
volumeName: config
namespace: {{ .Release.Namespace }}
externalManaged: true
- name: clickhouse-user-tpl
template: {{ include "clickhouse.userTplName" . }}
volumeName: user-config
namespace: {{ .Release.Namespace }}
externalManaged: true
- name: clickhouse-client-tpl
template: {{ include "clickhouse.clientTplName" . }}
volumeName: client-config
namespace: {{ .Release.Namespace }}
restartOnFileChange: falseParamConfigRenderer 可以定义配置文件的类型,定义触发重渲染的事件,并且绑定一组 ParametersDefinition(用于精细化控制参数渲染的范围和取值约束)
YAML
apiVersion: parameters.kubeblocks.io/v1alpha1
kind: ParamConfigRenderer
spec:
componentDef: clickhouse-1.0.1-beta.0
configs:
- fileFormatConfig:
format: xml
name: user.xml
templateName: clickhouse-user-tpl
- fileFormatConfig:
format: xml
name: 00_default_overrides.xml
reRenderResourceTypes:
- hscale
- shardingHScale
templateName: clickhouse-tpl
parametersDefs:
- clickhouse-user-pd
- clickhouse-config-pd备份恢复
ClickHouse Addon 集成 Altinity clickhouse-backup 开源工具,提供全量/增量备份恢复能力。对于 Cluster 形态部署的 ClickHouse,在备份恢复的过程中,KubeBlocks Operator 选取每个分片的首个 Pod 执行备份恢复操作。
备份策略:每个分片独立备份完整的 schema、rbac、data,在 S3 存储中生成与分片数量对应的备份条目。
恢复流程:
- Schema 恢复:基于 ReplicatedMergeTree 复制路径约束({layer}/{shard}/{replica})和 macros 配置,不使用 ON CLUSTER 分发 DDL,而是针对每个分片单独恢复表结构
- 数据恢复:依据 KubeBlocks 提供的环境变量中的分片内部 FQDN 列表,选择每个分片的首个 Pod 恢复 data 和 rbac
- 副本同步:通过 ClickHouse ReplicatedMergeTree 引擎的复制机制,将数据自动分发到分片内其他副本
RBAC 同步机制 :clickhouse-backup 恢复 RBAC 时依赖 user_directories.replicated.zookeeper_path 配置,使用 Keeper 作为用户权限数据的分布式存储,确保权限信息在集群内自动同步:
XML
<clickhouse>
<user_directories>
<replicated>
<!-- Keeper-based replicated user directory -->
<zookeeper_path>/clickhouse/access</zookeeper_path>
</replicated>
</user_directories>
</clickhouse>实战环节
安装 KubeBlocks 1.0 的步骤略。
部署集群
Bash
# 添加 Helm 仓库
helm repo add kubeblocks https://apecloud.github.io/helm-charts
helm repo update
# 安装 ClickHouse addon
helm install clickhouse kubeblocks/clickhouse --version 1.0.1
# 创建 ClickHouse 集群(3 分片 × 2 副本 + 3 副本 Keeper)
helm install ch-cluster kubeblocks/clickhouse-cluster \
--version 1.0.1-beta.0 \
--set shards=3 \
--set replicas=2 \
--set keeper.replicas=3
感兴趣的读者可以参考 github.com/apecloud/ku...
总结和展望
通过本文的介绍,我们展示了 KubeBlocks 在 ClickHouse 云原生化方面的完整解决方案。
在现代 OLAP 领域竞争日趋激烈的背景下,DuckDB 等新兴引擎在特定场景的性能表现已经超越 ClickHouse。然而,在企业级分布式数据处理场景中,ClickHouse 凭借其成熟的分布式架构、丰富的表引擎种类和强大的查询优化能力,仍然具有不可替代的价值。云原生化改造是 ClickHouse 降低运维门槛、提升易用性的重要手段。
KubeBlocks 作为面向有状态服务的开源 Kubernetes Operator,通过标准化的声明式 API 将复杂的数据库运维任务抽象化。其统一的集群管理模式、灵活的组件编排能力,以及对 ClickHouse Keeper 高可用、分片管理、参数配置、备份恢复等核心场景的深度支持,为企业提供了生产级的 ClickHouse 云原生解决方案。
未来我们希望在更多生产场景中验证和优化 KubeBlocks for ClickHouse,也欢迎大家在社区一起交流和贡献。