小R的烦恼
想象一下,你有个AI智能体助手叫小R,它很聪明,但有个致命缺点------「不长记性」!
每次小R犯错之后,你跟它说"你这样做不对,应该那样做",它点头如捣蒜:"好的好的,我记住了!"结果下次遇到同样问题,它还是犯一模一样的错误,就像得了健忘症一样。
这就是传统智能体的尴尬现状:它们聪明是聪明,但学不会从错误中吸取教训。每次都要重新训练才能改进,就像每次考试不及格都要重新上一遍学一样,累不累啊?
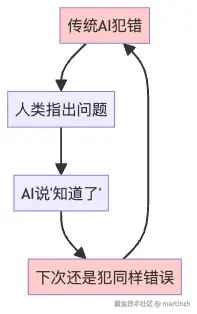
图1:传统AI的"健忘症循环"
Reflexion登场:AI界的"反思大师"
就在这时,研究人员想到了一个绝妙的主意:「既然不能改变AI的"大脑"(参数),那就给它一个"笔记本"(记忆)让它记录经验教训!」
这就是Reflexion技术的核心思想------不通过调整模型参数来学习,而是通过**「语言反思」**来改进智能体的决策能力。
你可能会问:"什么叫语言反思?"
简单来说,就是让智能体用人话把自己哪里做错了、为什么错了、下次应该怎么做,全都写下来。就像我们小时候犯错后老师让写检讨书一样,只不过智能体写的是给自己看的"学习笔记"。

图2:Reflexion的学习循环
三个小伙伴的配合:演员、评委和反思官
Reflexion系统就像一个三人小剧组:
🎭 演员(Actor)
这就是我们的主角小R,负责执行任务。它就像舞台上的演员,按照剧本(提示词)表演,但有时会忘词、走错位。
🎯 评委(Evaluator)
这位严格的评委负责给演员的表现打分。就像《中国好声音》的导师,会说"这个不行,重来!"或者"太棒了,通过!"
🤔 反思官(Self-Reflection)
这是整个系统的灵魂人物!当演员表现不好时,反思官会说:
❝
"刚才你在第三步的时候走错了方向,应该先检查一下手里有没有钥匙,然后再去开门。记住了吗?"
❞
最神奇的是,反思官写的这些经验教训会被记录在**「长期记忆」**里,就像给智能体建了一个"错题本"!
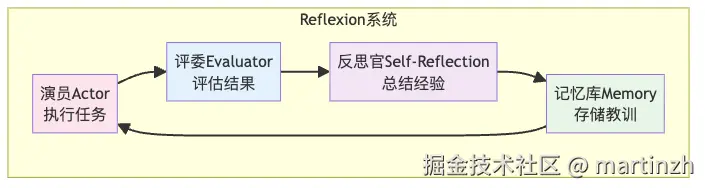
图3:Reflexion系统的三剑客
实战案例:小R学会整理房间
让我举个生动的例子。假设你让小R帮忙整理房间,任务是"把锅子洗干净放到橱柜里"。
第一次尝试(失败)
小R兴冲冲地说:"我去拿锅子!"
- 动作1:去炉子那里拿锅
- 观察:什么都没拿到
- 动作2:清洗锅子
- 观察:你在洗什么鬼?手里明明什么都没有!
「评委:失败!」
反思阶段
反思官开始工作:"我刚才失败了,因为我错误地以为自己已经拿到了锅子,但其实锅子不在炉子上。我应该先仔细找找锅子在哪里,确认拿到了再进行下一步。"
这段反思被记录到记忆库里。
第二次尝试(成功)
小R查看记忆库,看到上次的教训:
- 动作1:仔细查看厨房,寻找锅子
- 观察:在水槽里发现了锅子
- 动作2:从水槽拿起锅子
- 观察:成功拿到锅子!
- 动作3:清洗锅子...
「评委:通过!」
你看,这就是Reflexion的魔力------「智能体不再是一个"金鱼记忆"的助手,而是一个会学习、会改进的智能伙伴」!
为什么Reflexion这么厉害?
传统的强化学习就像让学生重新上一遍学:

图4:传统强化学习的痛苦循环
而Reflexion就像一个聪明的学霸:
- 「轻量级」:不需要重新训练,就像不用重新上学,只需要写笔记
- 「针对性强」:能明确指出具体哪里错了,而不是笼统地说"你不行"
- 「记忆持久」:一次总结,永久受益
- 「解释性好」:你能看懂AI的反思过程,不再是"黑盒"
从菜鸟程序员到编程高手
最让人惊喜的是,Reflexion在编程任务上的表现简直逆天!
场景设置
想象你是一个刚入职的程序员,老板给了你一道编程题:写一个函数检查括号是否匹配。
传统智能体的做法
arduino
def match_parens(lst):
if count == 0:
return "Yes"
else:
return "No"运行测试:💥 「ERROR!」 count变量都没定义!
传统智能体收到错误信息后:🤷♀️ "啊这...我重新写一遍吧",然后可能犯其他错误。
Reflexion智能体的做法
「第一次失败后的反思:」
❝
"我的代码失败了,因为我使用了未定义的变量
count。我本来想计算左右括号的数量,但忘记了初始化这个变量。下次我应该:1)正确初始化计数器;2)遍历列表统计左右括号;3)检查它们是否平衡。"❞
「第二次尝试:」
ini
def match_parens(lst):
count = 0
for char in lst:
if char == "(":
count += 1
elif char == ")":
count -= 1
if count < 0: # 右括号太多了!
return "No"
return "Yes" if count == 0 else "No"结果:✅ 「通过所有测试!」
在HumanEval编程基准测试中,Reflexion达到了91%的准确率,超过了之前最好的GPT-4的80%!这个提升可不是闹着玩的。
技术细节:记忆管理的艺术
你可能好奇:智能体的"错题本"是怎么管理的?
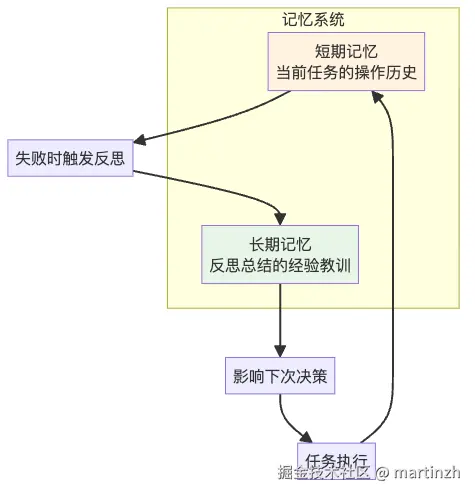
图5:双重记忆系统
「短期记忆」:就像你现在在做什么,刚才做了什么,很详细但不持久。
「长期记忆」:就像从失败中总结的人生感悟,精炼但持久。为了不让智能体"撑死"(上下文太长),通常只保留最近的3个重要教训。
实验结果:数字说话
研究人员在三个不同领域测试了Reflexion:
-
「决策任务(AlfWorld)」:在虚拟家庭环境中完成复杂任务
- 传统方法:60%成功率
- Reflexion:82%成功率 📈 +22%
-
「推理任务(HotPotQA)」:回答需要多步推理的问题
- 传统方法:29%准确率
- Reflexion:49%准确率 📈 +20%
-
「编程任务(HumanEval)」:解决编程挑战
- GPT-4:80%准确率
- Reflexion:91%准确率 📈 +11%
这些数字背后的意义是什么?「智能体终于学会了"吃一堑长一智"」!
局限性:没有完美的技术
当然,Reflexion也不是万能药:
- 「依赖自我评估能力」:如果智能体连自己哪里错了都不知道,那反思也是瞎反思
- 「没有理论保证」:不像数学公式那样有严格证明,更像是"经验主义"
- 「需要好的提示词」:垃圾输入,垃圾反思
但随着大语言模型越来越聪明,这些问题只会越来越小。
未来展望:智能体的自我进化之路
Reflexion开启了一个激动人心的可能性:「智能体可能真的会自我进化」!
想象一下,你的智能体助手在帮你工作几个月后,它对你的习惯、偏好、工作流程的理解越来越深。它会说:
❝
"根据我过去的经验,每当你说'帮我整理一下文件'时,你通常希望我按照时间顺序排列,并且把重要的文档标记出来。上次我忘记标记重要文档,你看起来有点不满意。这次我会特别注意的。"
❞
这不再是科幻小说,而是正在发生的现实!
总结:反思的力量
如果我们从Reflexion学到什么的话,那就是:「学习的本质不是重复,而是反思」。
无论是智能体还是人类,真正的成长来自于:
- 🔍 「诚实面对错误」:不逃避,不找借口
- 🤔 「深度分析原因」:为什么会犯这个错误?
- 📝 「记录经验教训」:写下来,让未来的自己受益
- 🚀 「应用改进行动」:知行合一,学以致用
Reflexion技术告诉我们,智能体的未来不在于更大的模型、更多的参数,而在于更聪明的学习方式。就像古人说的:"学而不思则罔,思而不学则殆。"
现在,智能体终于学会了"思"!