上周五下午 3 点 17 分,正在公司吭哧吭哧加班,突然看到 DeepSeek 官网弹出消息提醒:
🌈
"3B 参数的 OCR 模型,10 倍压缩,97% 精度,开源。"
作为一名 AI 博主,这么重要的模型那必须得尝尝鲜测试下了!要知道 GPT-4V 处理一页 PDF 得吃掉上千 Token,钱包直接破防。结果 DeepSeek-OCR 说:"兄弟,我只要你的十分之一 Token 数量!"
它到底怎么做到的?
那 DeepSeek 最新的 OCR 模型是如何做到能够使用少量视觉 token 就完成了海量文本压缩的?这主要得益于它的两个强大核心组件:DeepEncoder 和 DeepSeek3B-MoE 解码器!今天我们就来详细剖析下这两样组件是啥以及都有什么能力!
++1. 双塔结构------SAM 抠细节,CLIP 看全局++
DeepEncoder 这玩意儿像个双头怪:
- SAM-base(80M):窗口注意力,专门抠局部,高分辨率也不爆显存。
- CLIP-large(300M):全局注意力,扫一眼就知道这是化学式还是饼图。
中间夹一个 16× 卷积压缩层,两步 stride=2 的卷积,把 4096 个 patch token 直接砍到 256 个。简单粗暴,效果拔群。
++2. 五种分辨率模式------从 Tiny 到 Gundam++
| 模式 | 分辨率 | 输出 Token | 适用场景 |
|---|---|---|---|
| Tiny | 512×512 | 64 | 手机端实时拍 |
| Small | 640×640 | 100 | 轻量服务器 |
| Base | 1024×1024 | 256 | 默认,平衡 |
| Large | 1280×1280 | 400 | 高清扫描 |
| Gundam | 动态 | 自适应 | 超大图分块 |
++3. MoE 解码器------570M 激活参数,省钱又省显存++
解码器用 DeepSeek-3B-MoE-A570M,每次只激活 570M 参数。公式长这样:
翻译成人话:把 256 个视觉 Token 翻译成几千个文本 Token,但算力只花 570M 的份。
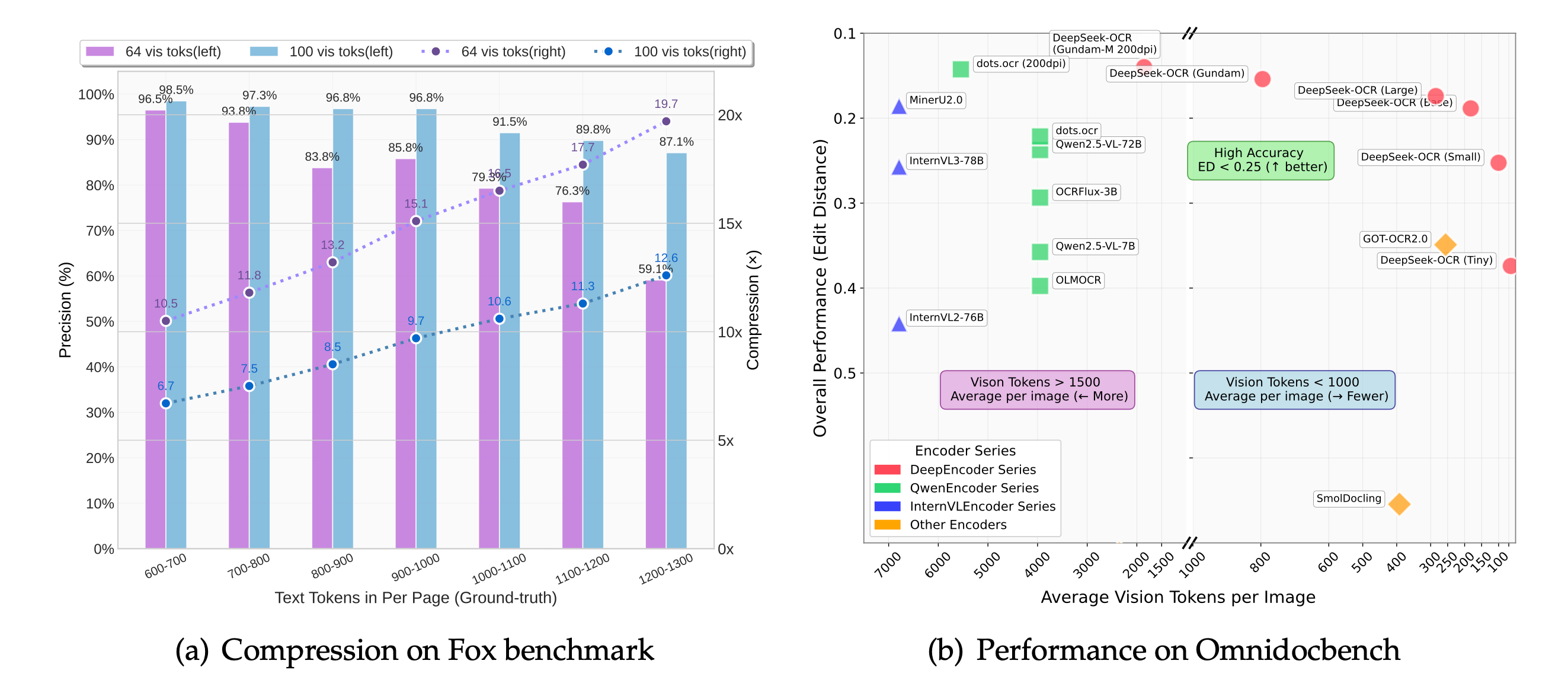
实测数据------真的没吹牛
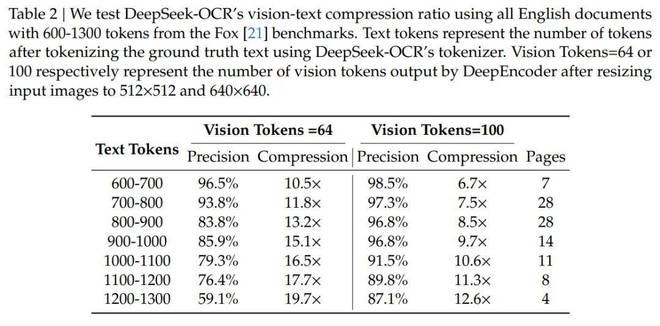
● 10 倍压缩:OCR 精度 97%,跟原版几乎没差。
● 20 倍压缩:还能剩 60% 准确率,应急够用。
● 单卡 A100-40G:一天干 20 万页 PDF,生产队驴都没它能打。
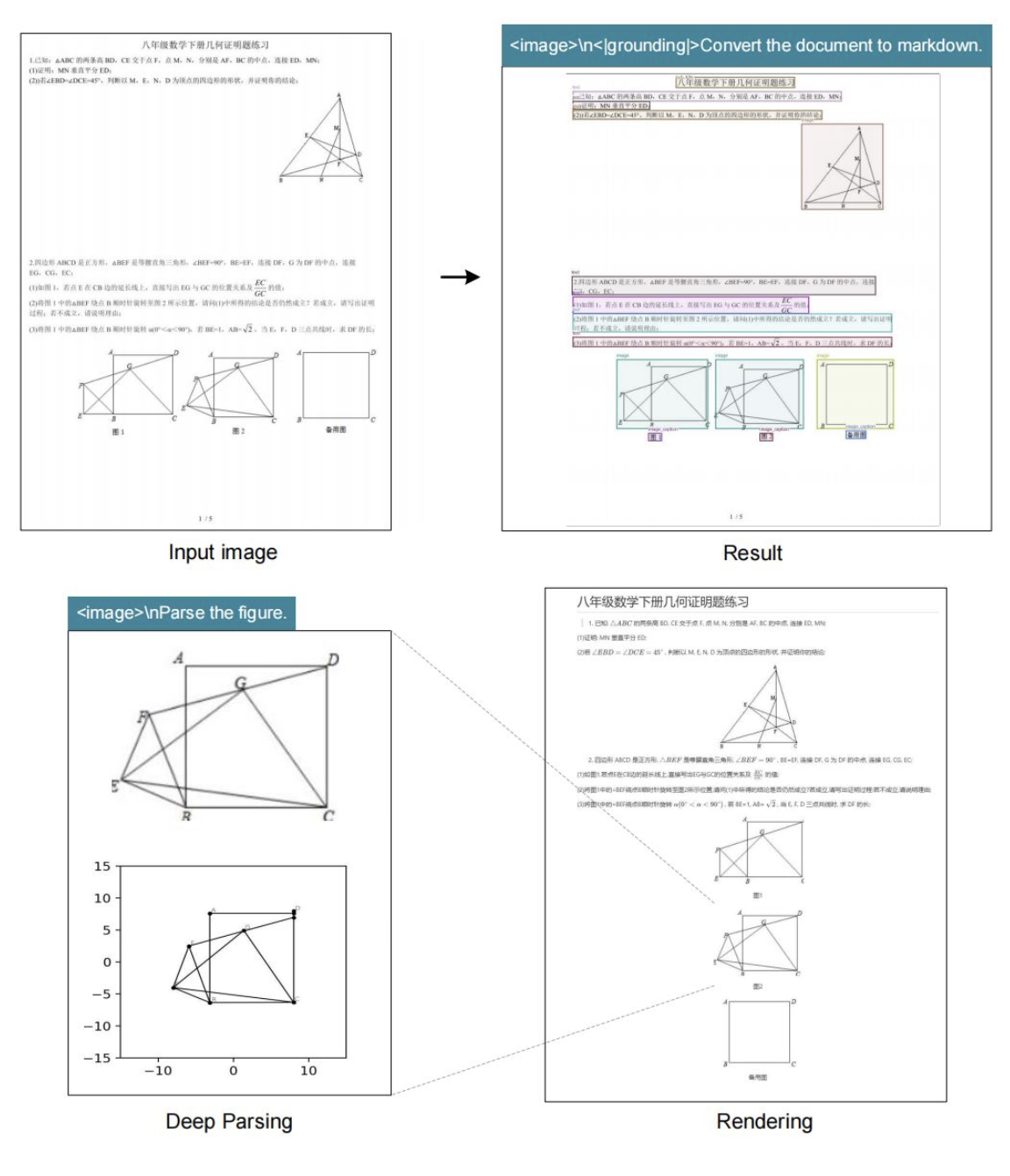
它能干啥?
++1. 学术狗福音------化学公式、数学符号一键转 LaTeX++
🌈
"之前我用 Mathpix 转公式,一页 3 美元,现在直接本地跑,钱包回血。"
🌈------ 某 985 研二学生,昨晚刚跑完 500 页论文
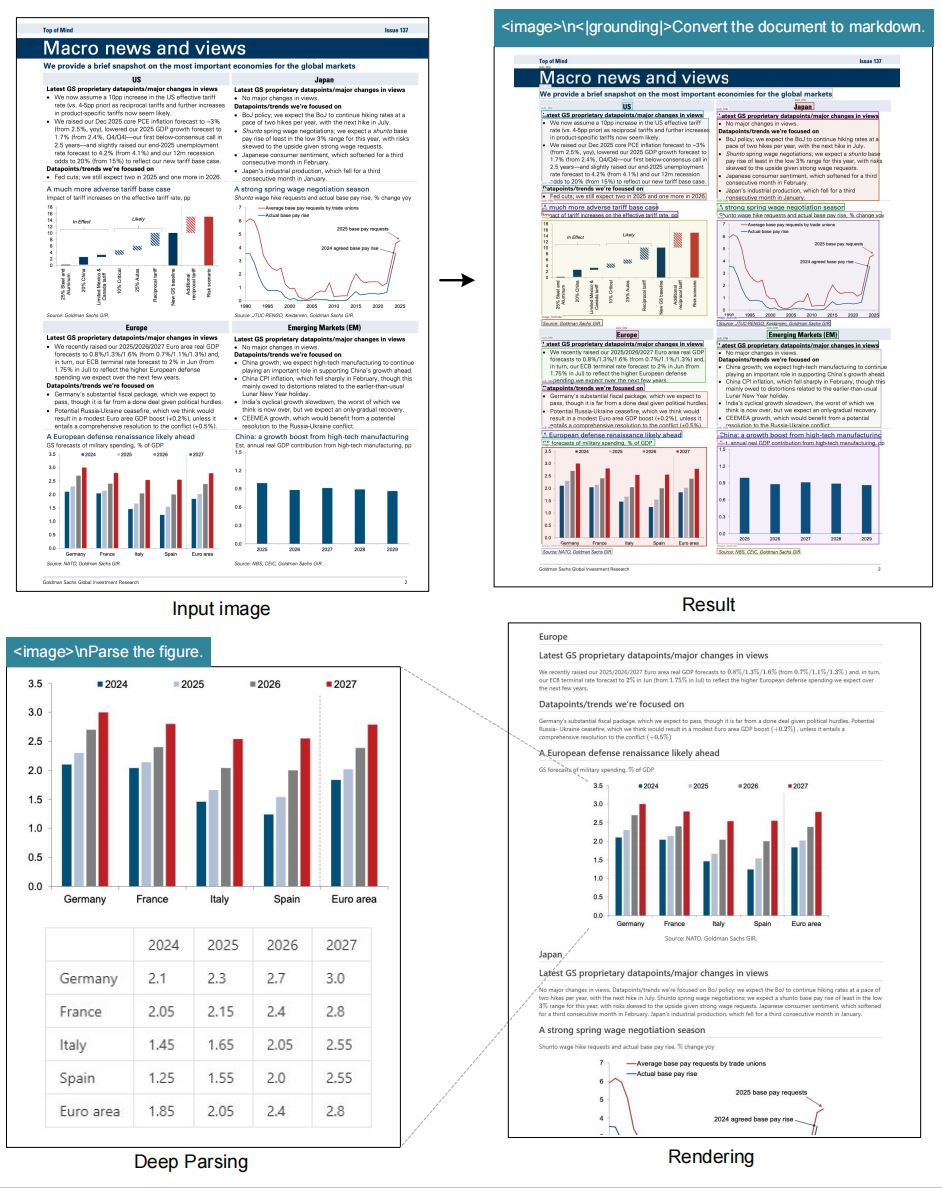
++2. 企业数字化------合同、报表秒变可搜索文本++
某跨国律所上周上线,一天扫完 10 年历史合同,老板一下又节省了上万的人工成本!
++3. 多语言地狱------僧伽罗文、阿拉伯文都不虚++
官方数据:支持识别 100 种语言 ,包括中文、英文、阿拉伯文、僧伽罗文......
实测阿拉伯语 PDF,连从右往左的排版都没翻车。

怎么玩?
++GitHub 一把梭++
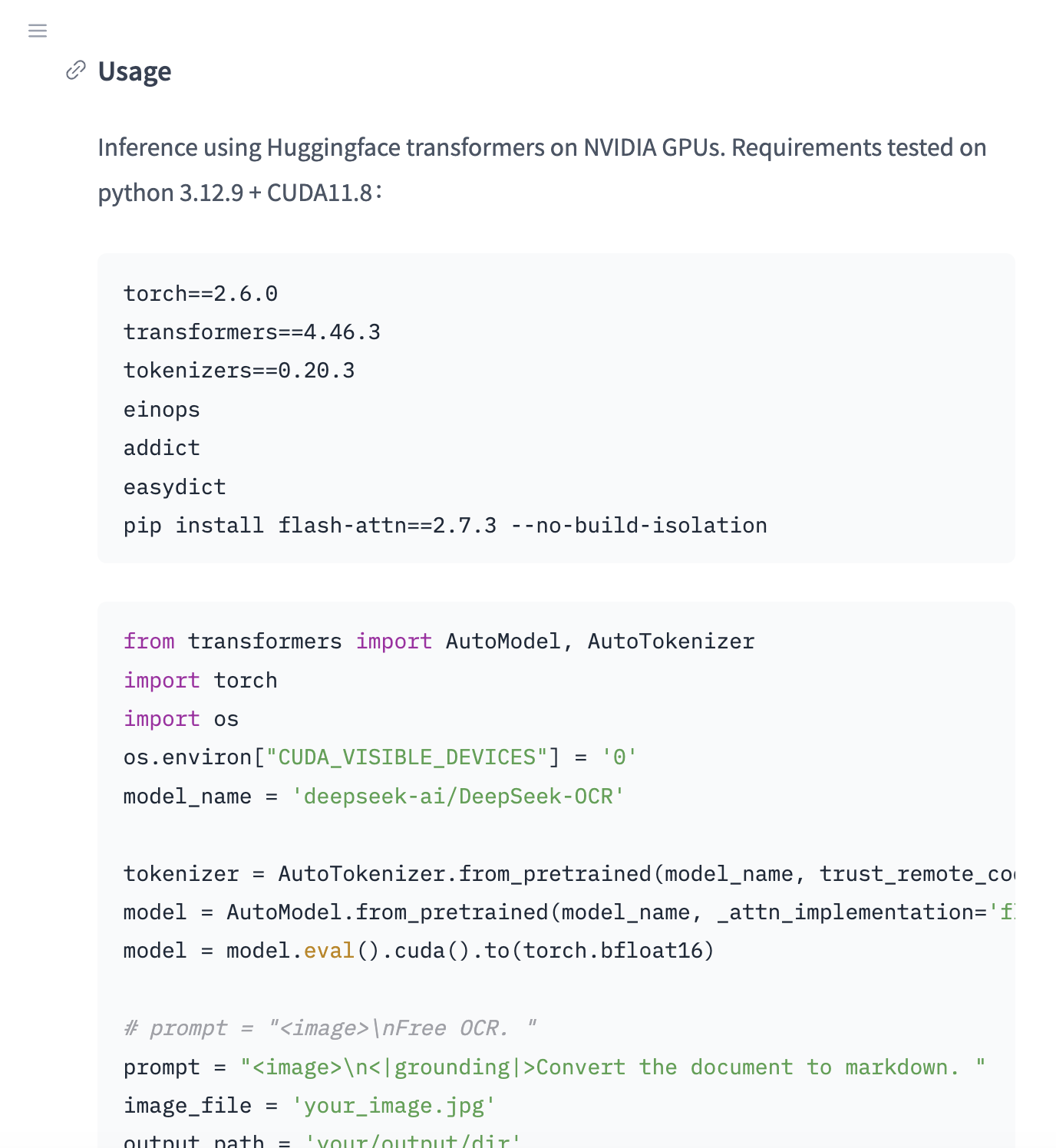
`git clone https://github.com/deepseek-ai/DeepSeek-OCR
pip install -r requirements.txt
python demo.py --image your.pdf --output out.md
`++HuggingFace 两行代码搞定++
从 HuggingFace 看,下载完工程后只需要执行以下两行代码,即可快速上手使用!
`from deepseek_ocr import DeepSeekOCR
model = DeepSeekOCR.from_pretrained("deepseek-ai/DeepSeek-OCR")
out = model.predict("paper.png", prompt="Convert to markdown.")
`最后说两句
说白了,DeepSeek-OCR 就是给长文本处理 装上了涡轮增压 ------
同样的内容,别人烧 1000 Token,你只要 100 个,而且识别的精度还更高。
毕竟谁不想省钱又省显存呢?
想本地部署的可以从以下仓库区下载源码,官网附带了详细部署教程
GitHub 仓库:https://github.com/deepseek-ai/DeepSeek-OCR
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-OCR