
OpenLineage 是一个用于元数据和血缘采集的开放标准,专为在作业运行时动态采集数据而设计。它通过统一的命名策略定义了由作业(Job)、运行实例(Run)和数据集(Dataset) 组成的通用模型,并通过可扩展的Facets机制对这些实体进行元数据增强。
该项目是 LF AI & Data 基金会的毕业级项目,处于活跃开发阶段,欢迎社区贡献。
在 Spark 中使用 OpenLineage
改编自 Michael Collado 的博文
本指南基于早期版本的集成开发,可能需要根据最新版本进行调整。
将 OpenLineage 添加到 Spark 非常简单,这得益于 Spark 的 SparkListener 接口。OpenLineage 通过实现 SparkListener 并收集 Spark 应用程序内部执行的作业信息来与 Spark 集成。要激活监听器,请将以下属性添加到集群的 spark-defaults.conf 文件中的 Spark 配置中,或者通过 spark-submit 命令将它们添加到特定作业的提交中:
shell
spark.jars.packages io.openlineage:openlineage-spark:{{PREPROCESSOR:OPENLINEAGE_VERSION}}
spark.extraListeners io.openlineage.spark.agent.OpenLineageSparkListener激活后,监听器需要知道将血缘事件报告到哪里以及作业的命名空间。将以下附加配置行添加到 spark-defaults.conf 文件或 Spark 提交脚本中:
shell
spark.openlineage.transport.url {your.openlineage.host}
spark.openlineage.transport.type {your.openlineage.transport.type}
spark.openlineage.namespace {your.openlineage.namespace}使用 OpenLineage 运行 Spark
前提条件
- Docker Desktop
- git
- Google Cloud Service 账户
- Google Cloud Service 账户 JSON 密钥文件
注意:你的 Google Cloud 账户应拥有 BigQuery 的访问权限以及对你的 GCS 存储桶的读写权限。建议为你的密钥文件起一个容易记住的名称(bq-spark-demo.json)。最后,如果使用 macOS Monterey (macOS 12),则需要通过禁用 AirPlay 接收器释放端口 5000。
使用说明
克隆 OpenLineage 项目,导航到 spark 目录,并为你的 Google Cloud Service 凭据创建一个目录:
shell
git clone https://github.com/OpenLineage/OpenLineage
cd integration/spark
mkdir -p docker/notebooks/gcs将你的 Google Cloud Service 凭据文件复制到该目录中,然后运行:
shell
docker-compose up这将启动一个带有 Spark 的 Jupyter notebook,以及一个已安装的 Marquez API 端点,用于报告血缘。一旦 notebook 服务器启动并运行,你应在日志中看到如下内容:
shell
notebook_1 | [I 21:43:39.014 NotebookApp] Jupyter Notebook 6.4.4 is running at:
notebook_1 | [I 21:43:39.014 NotebookApp] http://082cb836f1ec:8888/?token=507af3cf9c22f627f6c5211d6861fe0804d9f7b19a93ca48
notebook_1 | [I 21:43:39.014 NotebookApp] or http://127.0.0.1:8888/?token=507af3cf9c22f627f6c5211d6861fe0804d9f7b19a93ca48
notebook_1 | [I 21:43:39.015 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).从你自己的日志中复制以 127.0.0.1 作为主机名的 URL(令牌将与此不同)并将其粘贴到浏览器窗口中。你应该会看到一个空白的 Jupyter notebook 环境,准备就绪。
点击 notebooks 目录,然后点击 New 按钮创建一个新的 Python 3 notebook。
在窗口的第一个单元格中粘贴以下文本。更新 GCP 项目和存储桶名称以及服务账户凭据文件,然后运行代码:
python
from pyspark.sql import SparkSession
import urllib.request
# 下载 BigQuery 和 GCS 的依赖项
gc_jars = ['https://repo1.maven.org/maven2/com/google/cloud/bigdataoss/gcs-connector/hadoop3-2.1.1/gcs-connector-hadoop3-2.1.1-shaded.jar',
'https://repo1.maven.org/maven2/com/google/cloud/bigdataoss/bigquery-connector/hadoop3-1.2.0/bigquery-connector-hadoop3-1.2.0-shaded.jar',
'https://repo1.maven.org/maven2/com/google/cloud/spark/spark-bigquery-with-dependencies_2.12/0.22.2/spark-bigquery-with-dependencies_2.12-0.22.2.jar']
files = [urllib.request.urlretrieve(url)[0] for url in gc_jars]
# 设置为你自己的项目和存储桶
project_id = 'bq-openlineage-spark-demo'
gcs_bucket = 'bq-openlineage-spark-demo-bucket'
credentials_file = '/home/jovyan/notebooks/gcs/bq-spark-demo.json'
spark = (SparkSession.builder.master('local').appName('openlineage_spark_test')
.config('spark.jars', ",".join(files))
# 安装并设置 OpenLineage 监听器
.config('spark.jars.packages', 'io.openlineage:openlineage-spark:{{PREPROCESSOR:OPENLINEAGE_VERSION}}')
.config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener')
.config('spark.openlineage.transport.url', 'http://marquez-api:5000')
.config('spark.openlineage.transport.type', 'http')
.config('spark.openlineage.namespace', 'spark_integration')
# 配置 Google 凭据和项目 ID
.config('spark.executorEnv.GCS_PROJECT_ID', project_id)
.config('spark.executorEnv.GOOGLE_APPLICATION_CREDENTIALS', '/home/jovyan/notebooks/gcs/bq-spark-demo.json')
.config('spark.hadoop.google.cloud.auth.service.account.enable', 'true')
.config('spark.hadoop.google.cloud.auth.service.account.json.keyfile', credentials_file)
.config('spark.hadoop.fs.gs.impl', 'com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem')
.config('spark.hadoop.fs.AbstractFileSystem.gs.impl', 'com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS')
.config("spark.hadoop.fs.gs.project.id", project_id)
.getOrCreate())以上内容大部分是用于在 notebook 环境中安装 BigQuery 和 GCS 库的样板代码。这还设置了配置参数,告诉库使用哪个 GCP 项目以及如何与 Google 进行身份验证。特定于 OpenLineage 的参数是已提到的四个:spark.jars.packages、spark.extraListeners、spark.openlineage.host、spark.openlineage.namespace。在此,主机已配置为由 Docker 启动的 marquez-api 容器。
配置好 OpenLineage 后,是时候获取一些数据了。以下代码用两个 COVID-19 公共数据集的数据填充 Spark DataFrame。在 notebook 中创建一个新单元格并粘贴以下内容:
python
from pyspark.sql.functions import expr, col
mask_use = spark.read.format('bigquery') \
.option('parentProject', project_id) \
.option('table', 'bigquery-public-data:covid19_nyt.mask_use_by_county') \
.load() \
.select(expr("always + frequently").alias("frequent"),
expr("never + rarely").alias("rare"),
"county_fips_code")
opendata = spark.read.format('bigquery') \
.option('parentProject', project_id) \
.option('table', 'bigquery-public-data.covid19_open_data.covid19_open_data') \
.load() \
.filter("country_name == 'United States of America'") \
.filter("date == '2021-10-31'") \
.select("location_key",
expr('cumulative_deceased/(population/100000)').alias('deaths_per_100k'),
expr('cumulative_persons_fully_vaccinated/(population - population_age_00_09)').alias('vaccination_rate'),
col('subregion2_code').alias('county_fips_code'))
joined = mask_use.join(opendata, 'county_fips_code')
joined.write.mode('overwrite').parquet(f'gs://{gcs_bucket}/demodata/covid_deaths_and_mask_usage/')以上内容的一些背景:covid19_open_data 表被过滤为仅包含 2021 年 10 月 31 日的美国数据。deaths_per_100k 数据点使用现有的 cumulative_deceased 和 population 列计算,vaccination_rate 使用总人口减去 9 岁以下人口计算,因为当时他们没有资格接种疫苗。对于 mask_use_by_county 数据,"rarely" 和 "never" 数据合并为一个数字,"frequently" 和 "always" 也是如此。然后存储来自两个数据集的选定列。
现在,在 notebook 中添加一个单元格并粘贴此行:
python
spark.read.parquet(f'gs://{gcs_bucket}/demodata/covid_deaths_and_mask_usage/').count()notebook 应打印警告和堆栈跟踪(可能是调试语句),然后返回总共 3142 条记录。
现在管道已运行,可用于血缘收集。
与 OpenLineage 仓库一起提供的 docker-compose.yml 文件仅包括 Jupyter notebook 和 Marquez API。为了直观地探索血缘,请启动 Marquez web 项目。在不终止现有 docker 容器的情况下,在新终端中运行以下命令:
shell
docker run --network spark_default -p 3000:3000 -e MARQUEZ_HOST=marquez-api -e MARQUEZ_PORT=5000 -e WEB_PORT=3000 --link marquez-api:marquez-api marquezproject/marquez-web:0.19.1接下来,打开新的浏览器标签页并导航到 http://localhost:3000,其外观应如下所示:

注意:spark_integration 命名空间是自动选择的,因为没有其他命名空间可用。UI 的作业页面上列出了三个作业。它们都以 openlineage_spark_test 开头,这是在构建 notebook 的第一个单元格时传递给 SparkSession 的 appName。每个查询执行或 RDD 操作都表示为一个不同的作业,操作的名称附加到应用程序名称以形成作业名称。点击 openlineage_spark_test.execute_insert_into_hadoop_fs_relation_command 节点会调出我们 notebook 的血缘图:
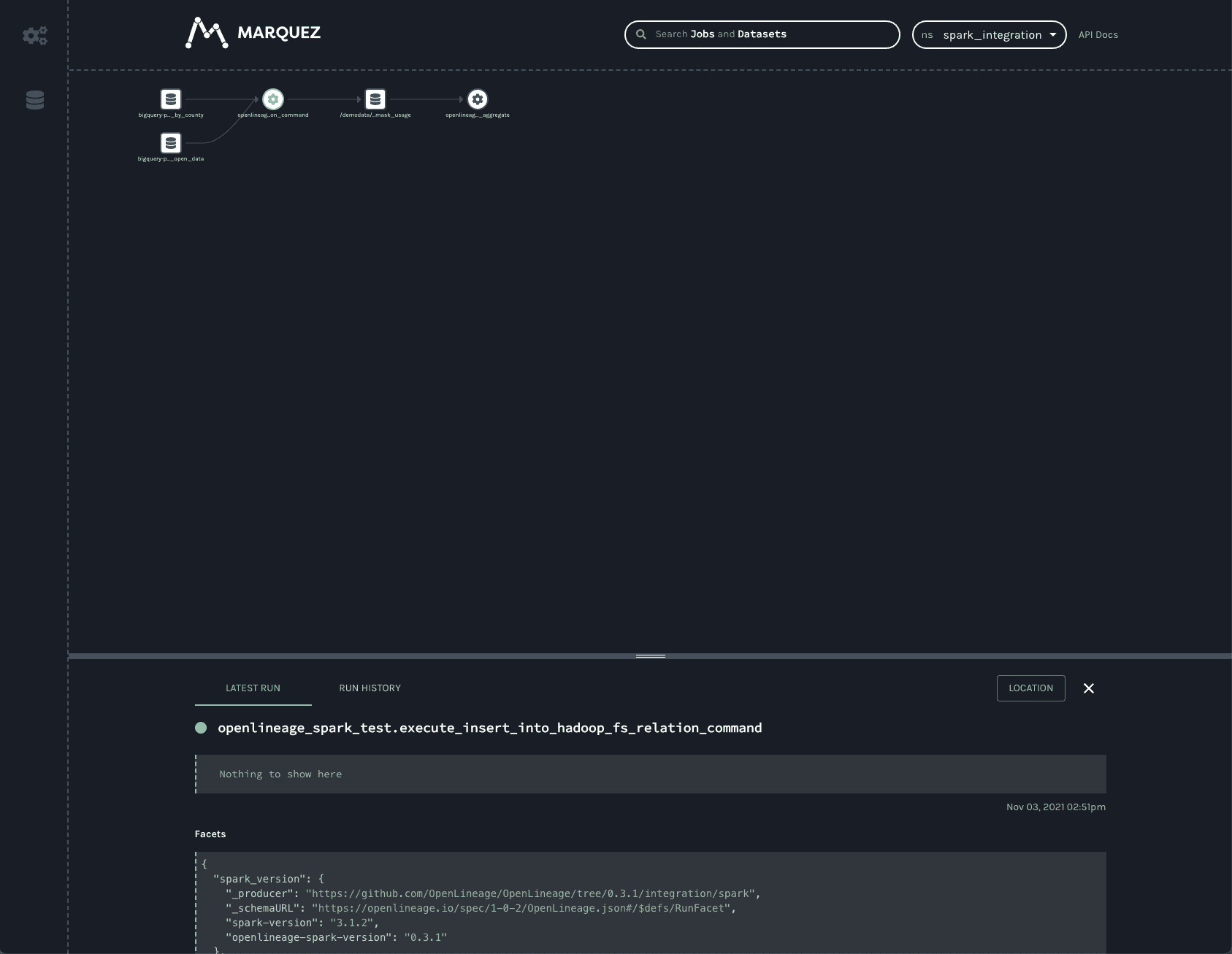
该图显示 openlineage_spark_test.execute_insert_into_hadoop_fs_relation_command 作业从两个输入数据集 bigquery-public-data.covid19_nyt.mask_use_by_county 和 bigquery-public-data.covid19_open_data.covid19_open_data 读取,并写入第三个数据集 /demodata/covid_deaths_and_mask_usage。该第三个数据集的命名空间缺失,但完全限定名称为 gs://<your_bucket>/demodata/covid_deaths_and_mask_usage。
底部栏显示从 Spark 作业收集的一些有趣数据。向上拖动栏可展开视图以便更仔细地查看。
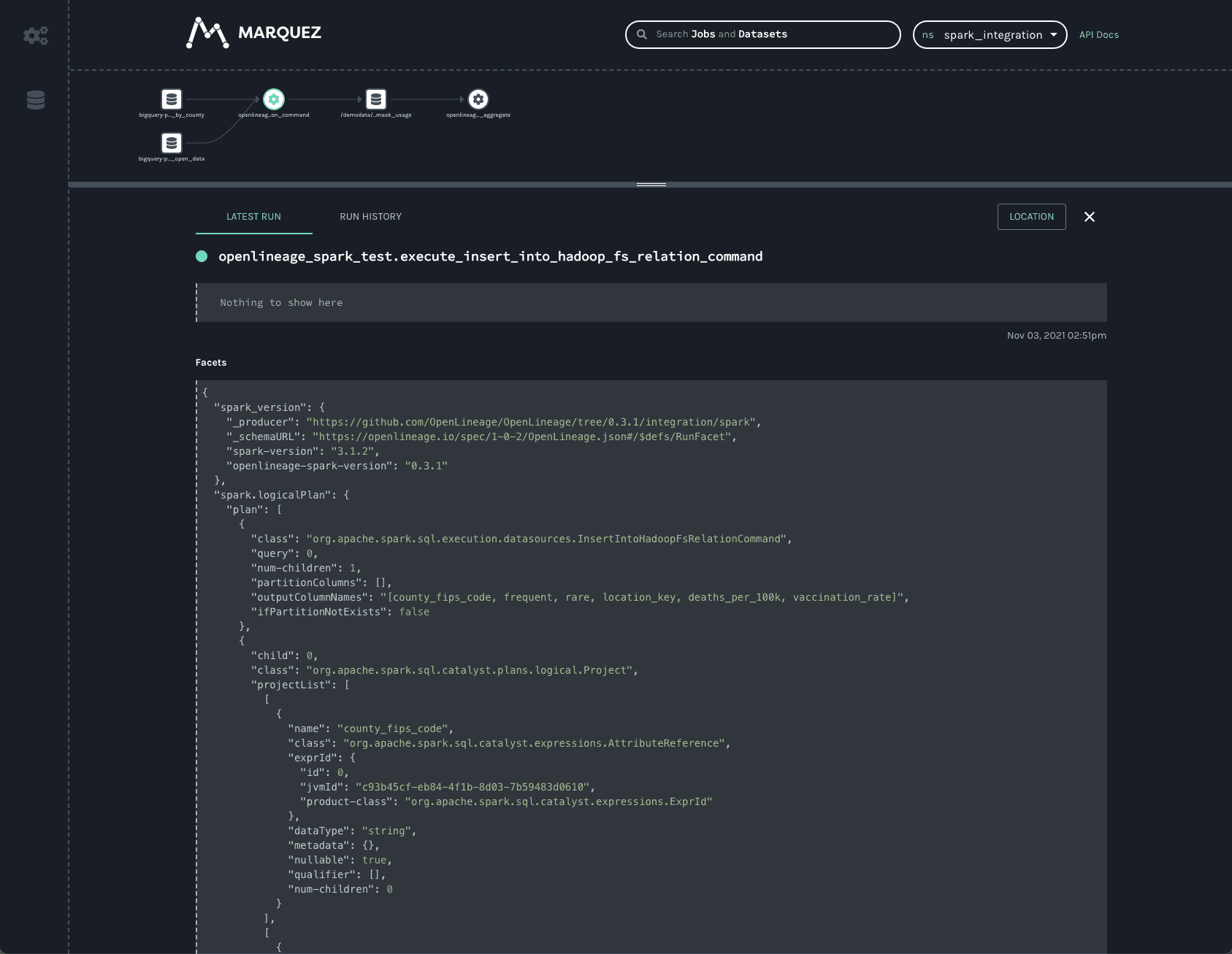
从 Spark 作业始终收集的两个切面是 spark_version 和 spark.logicalPlan。第一个仅报告执行 Spark 的版本以及 openlineage-spark 库的版本。这有助于调试作业运行。
第二个切面是作业运行时 Spark 报告的序列化优化 LogicalPlan。Spark 的查询优化会对查询作业的执行时间和效率产生巨大影响。跟踪查询计划如何随时间变化可以显著帮助调试生产环境中的慢查询或 OutOfMemory 错误。
点击第一个 BigQuery 数据集可提供有关数据的信息:
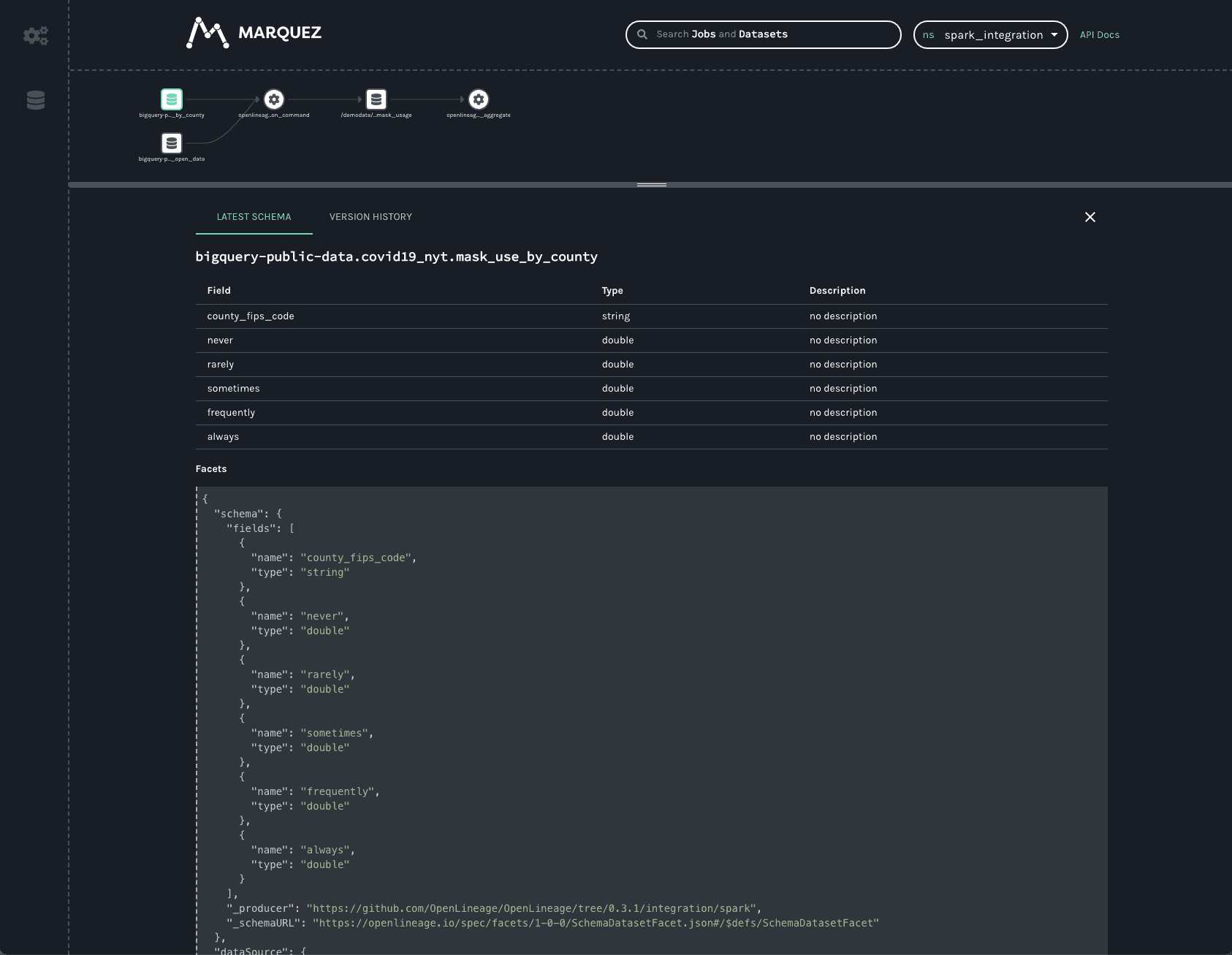
可以看到数据集的架构以及数据源。
关于写入 GCS 的数据集的类似信息也可用:
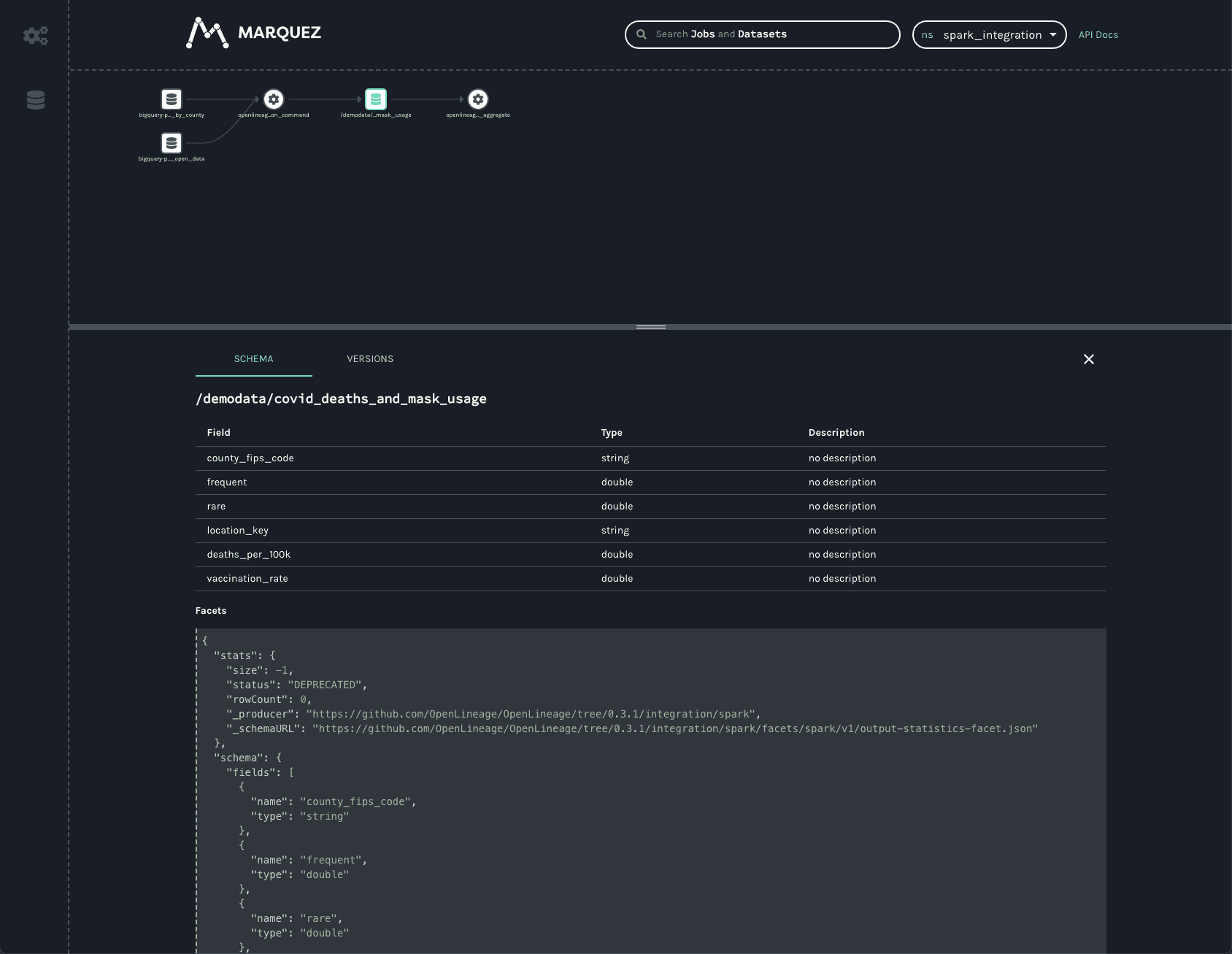
与 BigQuery 数据集一样,可以看到输出架构和数据源------在此情况下为 gs:// 方案和写入的存储桶名称。
除了架构之外,还可以看到统计切面,报告输出记录数和字节数为 -1。
底部栏上的 VERSIONS 标签会显示多个版本(如果有的话)(此处不是这种情况)。点击版本会显示相同架构和统计切面,但它们特定于所选版本。
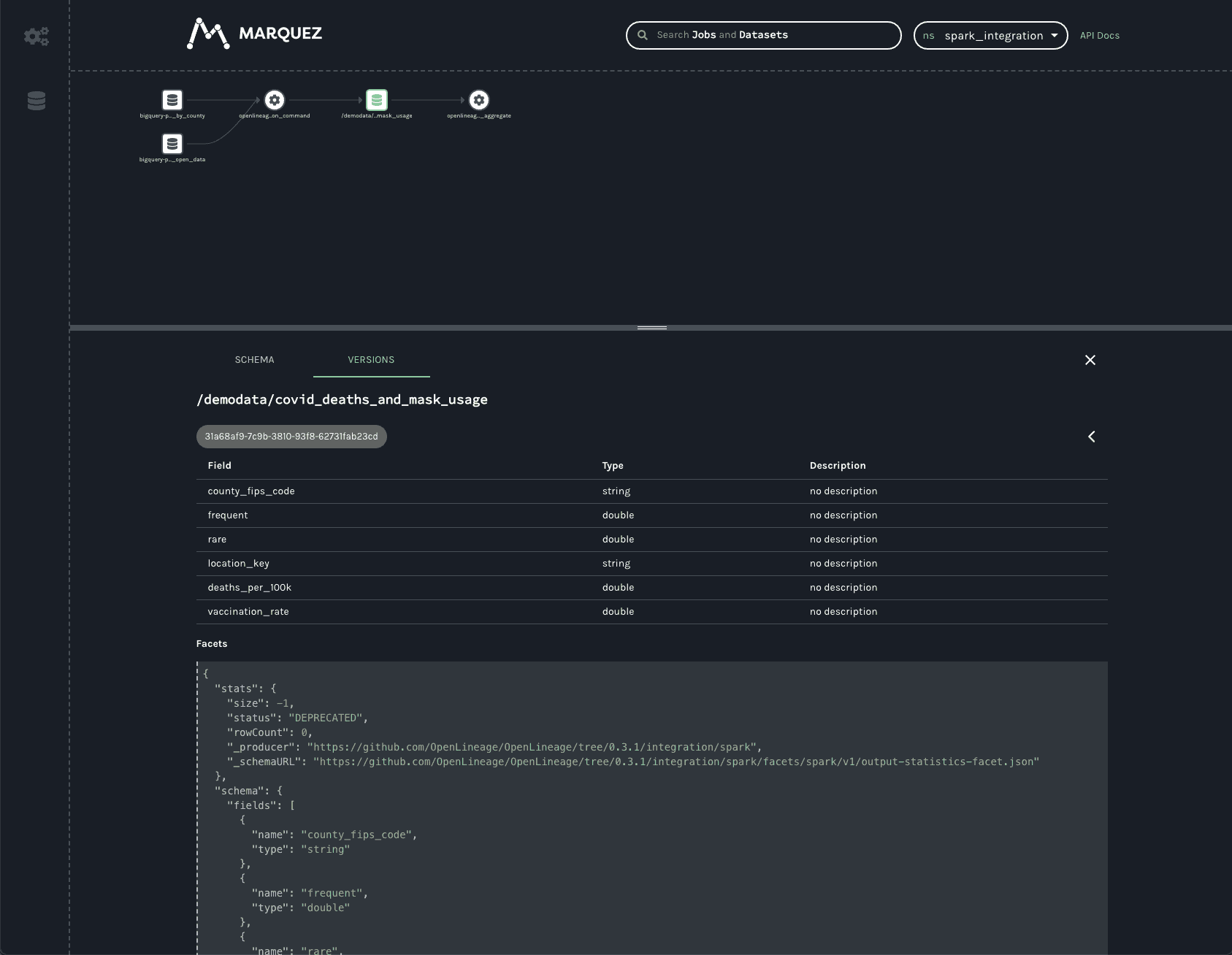
在生产环境中,此数据集将有许多版本,因为每次作业运行时都会创建数据集的新版本。这允许跟踪统计和架构随时间的变化,有助于调试慢作业或数据质量问题以及作业失败。
UI 中的最终作业是 HashAggregate 作业。这表示末尾调用的 count() 方法以显示数据集中的记录数。这可以很容易地是 toPandas() 调用或读取和处理该数据的其他作业------也许将输出存回 GCS 或更新 Postgres 数据库,发布新模型等。无论输出存储在何处,OpenLineage 集成都允许查看整个血缘图,统一对象存储、关系数据库和更传统数据仓库中的数据集。
结论
OpenLineage 的 Spark 集成为用户提供了对存储在 S3、GCS 和 Azure Blob Storage 等对象存储以及 BigQuery 和 Postgres 等关系数据库中的数据集图的洞察。现在支持 Spark 3.1,OpenLineage 在 Databricks、EMR 和 Dataproc 集群等更多环境中提供可见性。
风险提示与免责声明
本文内容基于公开信息研究整理,不构成任何形式的投资建议。历史表现不应作为未来收益保证,市场存在不可预见的波动风险。投资者需结合自身财务状况及风险承受能力独立决策,并自行承担交易结果。作者及发布方不对任何依据本文操作导致的损失承担法律责任。市场有风险,投资须谨慎。