
OpenLineage 是一个用于元数据和血缘采集的开放标准,专为在作业运行时动态采集数据而设计。它通过统一的命名策略定义了由作业(Job)、运行实例(Run)和数据集(Dataset) 组成的通用模型,并通过可扩展的Facets机制对这些实体进行元数据增强。
该项目是 LF AI & Data 基金会的毕业级项目,处于活跃开发阶段,欢迎社区贡献。
Apache Spark
该集成已知适用于最新 Spark 版本以及其他 Apache Spark 3.*。如需获取受支持版本的最新信息,请查看此处。
该集成通过 OpenLineageSparkListener 使用 SparkListener 接口,提供全面的监控方案。 它会监听 SparkContext 发出的事件,提取与作业和数据集相关的元数据,并利用 RDD 和 DataFrame 的依赖图。方法可有效从各种数据源收集信息,包括文件系统源(如 S3 和 GCS)、JDBC 后端以及 Redshift 和 BigQuery 等数据仓库。
使用 Jupyter 快速入门
Quickstart with Jupyter
如果您已安装 Docker Desktop 和 git,体验 Spark 集成将非常简单。
若您使用 macOS Monterey (macOS 12),开始前需先释放 5000 端口,方法为关闭 AirPlay Receiver。
在工作空间克隆 OpenLineage 项目:
bash
git clone https://github.com/OpenLineage/OpenLineage进入 spark 集成目录($OPENLINEAGE_ROOT/integration/spark)并执行:
bash
docker-compose up该命令将启动 Marquez(作为 OpenLineage 客户端)与 Jupyter Spark notebook,均运行于 localhost:8888。
启动后,notebook 容器日志会列出包含访问令牌的 URL,例如:
bash
notebook_1 | To access the notebook, open this file in a browser:
notebook_1 | file:///home/jovyan/.local/share/jupyter/runtime/nbserver-9-open.html
notebook_1 | Or copy and paste one of these URLs:
notebook_1 | http://abc12345d6e:8888/?token=XXXXXX
notebook_1 | or http://127.0.0.1:8888/?token=XXXXXX从您自己的日志中复制以 127.0.0.1 为主机名的 URL(token 与示例不同),粘贴到浏览器即可看到一个空白可用的 Jupyter notebook 环境。
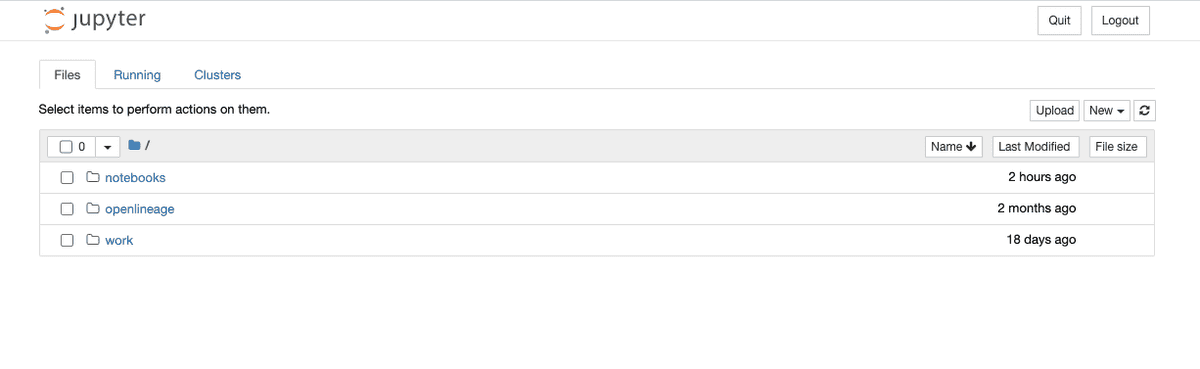
环境就绪后,点击 notebooks 目录,再点击 New 按钮,新建一个 Python 3 notebook。
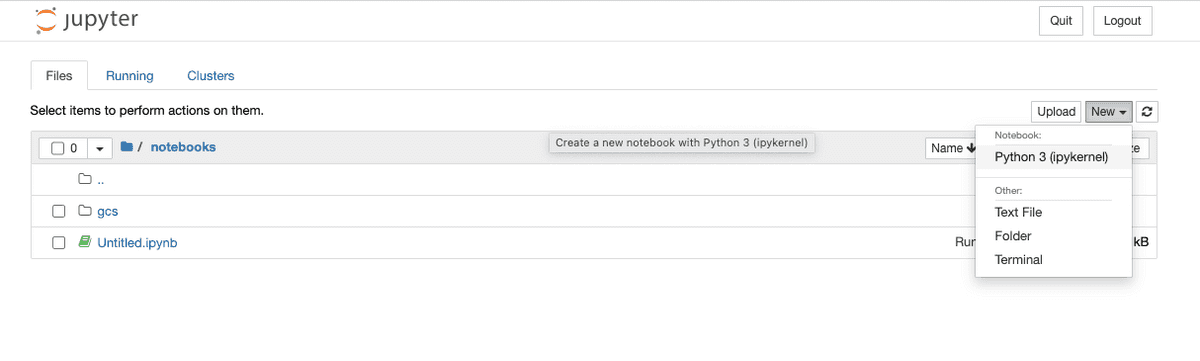
在首个单元格中粘贴以下内容:
python
from pyspark.sql import SparkSession
spark = (SparkSession.builder.master('local')
.appName('sample_spark')
.config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener')
.config('spark.jars.packages', 'io.openlineage:openlineage-spark:{{PREPROCESSOR:OPENLINEAGE_VERSION}}')
.config('spark.openlineage.transport.type', 'console')
.getOrCreate())Spark 上下文启动后,将日志级别设为 INFO:
python
spark.sparkContext.setLogLevel("INFO")接着创建一个 Spark 表:
python
spark.createDataFrame([
{'a': 1, 'b': 2},
{'a': 3, 'b': 4}
]).write.mode("overwrite").saveAsTable("temp")命令将以日志形式输出 OpenLineage 事件:
text
22/08/01 06:15:49 INFO ConsoleTransport: {"eventType":"START","eventTime":"2022-08-01T06:15:49.671Z","run":{"runId":"204d9c56-6648-4d46-b6bd-f4623255d324","facets":{"spark_unknown":{"_producer":"https://github.com/OpenLineage/OpenLineage/tree/0.12.0-SNAPSHOT/integration/spark","_schemaURL":"https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet","inputs":[{"description":{"@class":"org.apache.spark.sql.execution.LogicalRDD","id":1,"streaming":false,"traceEnabled":false,"canonicalizedPlan":false},"inputAttributes":[],"outputAttributes":[{"name":"a","type":"long","metadata":{}},{"name":"b","type":"long","metadata":{}}]}]},"spark.logicalPlan":{"_producer":"https://github.com/OpenLineage/OpenLineage/tree/0.12.0-SNAPSHOT/integration/spark","_schemaURL":"https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet","plan":[{"class":"org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand","num-children":1,"table":{"product-class":"org.apache.spark.sql.catalyst.catalog.CatalogTable","identifier":{"product-class":"org.apache.spark.sql.catalyst.TableIdentifier","table":"temp"},"tableType":{"product-class":"org.apache.spark.sql.catalyst.catalog.CatalogTableType","name":"MANAGED"},"storage":{"product-class":"org.apache.spark.sql.catalyst.catalog.CatalogStorageFormat","compressed":false,"properties":null},"schema":{"type":"struct","fields":[]},"provider":"parquet","partitionColumnNames":[],"owner":"","createTime":1659334549656,"lastAccessTime":-1,"createVersion":"","properties":null,"unsupportedFeatures":[],"tracksPartitionsInCatalog":false,"schemaPreservesCase":true,"ignoredProperties":null},"mode":null,"query":0,"outputColumnNames":"[a, b]"},{"class":"org.apache.spark.sql.execution.LogicalRDD","num-children":0,"output":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num-children":0,"name":"a","dataType":"long","nullable":true,"metadata":{},"exprId":{"product-class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":6,"jvmId":"6a1324ac-917e-4e22-a0b9-84a5f80694ad"},"qualifier":[]}],[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num-children":0,"name":"b","dataType":"long","nullable":true,"metadata":{},"exprId":{"product-class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":7,"jvmId":"6a1324ac-917e-4e22-a0b9-84a5f80694ad"},"qualifier":[]}]],"rdd":null,"outputPartitioning":{"product-class":"org.apache.spark.sql.catalyst.plans.physical.UnknownPartitioning","numPartitions":0},"outputOrdering":[],"isStreaming":false,"session":null}]},"spark_version":{"_producer":"https://github.com/OpenLineage/OpenLineage/tree/0.12.0-SNAPSHOT/integration/spark","_schemaURL":"https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet","spark-version":"3.1.2","openlineage-spark-version":"0.12.0-SNAPSHOT"}}},"job":{"namespace":"default","name":"sample_spark.execute_create_data_source_table_as_select_command","facets":{}},"inputs":[],"outputs":[{"namespace":"file","name":"/home/jovyan/notebooks/spark-warehouse/temp","facets":{"dataSource":{"_producer":"https://github.com/OpenLineage/OpenLineage/tree/0.12.0-SNAPSHOT/integration/spark","_schemaURL":"https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet","name":"file","uri":"file"},"schema":{"_producer":"https://github.com/OpenLineage/OpenLineage/tree/0.12.0-SNAPSHOT/integration/spark","_schemaURL":"https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet","fields":[{"name":"a","type":"long"},{"name":"b","type":"long"}]},"lifecycleStateChange":{"_producer":"https://github.com/OpenLineage/OpenLineage/tree/0.12.0-SNAPSHOT/integration/spark","_schemaURL":"https://openlineage.io/spec/facets/1-0-0/LifecycleStateChangeDatasetFacet.json#/$defs/LifecycleStateChangeDatasetFacet","lifecycleStateChange":"CREATE"}},"outputFacets":{}}],"producer":"https://github.com/OpenLineage/OpenLineage/tree/0.12.0-SNAPSHOT/integration/spark","schemaURL":"https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunEvent"}生成的 JSON 包含输出数据集的名称与位置 {"namespace":"file","name":"/home/jovyan/notebooks/spark-warehouse/temp"、Schema 字段 [{"name":"a","type":"long"},{"name":"b","type":"long"}] 等。
更全面的演示(将 Spark 事件与 Marquez 后端集成)可在我们的博客查看:使用 OpenLineage 和 Apache Spark 追踪数据血缘
关于 OpenLineage
About OpenLineage
OpenLineage 是一个用于数据血缘收集和分析的开放框架。其核心是一个可扩展的规范,系统可通过该规范与血缘元数据实现互操作。
设计
OpenLineage 是一个用于血缘元数据收集的 开放标准 ,旨在为执行中的 作业 记录元数据。
该标准定义了 数据集 、作业 和 运行 实体的通用模型,这些实体通过一致的命名策略进行唯一标识。核心模型通过 Facet 实现高度可扩展。Facet 是用户定义的元数据,可用于丰富实体。我们鼓励您先熟悉下面的核心模型:

OpenLineage 如何惠及生态系统
下面,我们说明了从多个来源、调度器和/或数据处理框架收集血缘元数据的挑战,随后概述了定义 开放标准 用于血缘元数据收集的设计优势。
之前
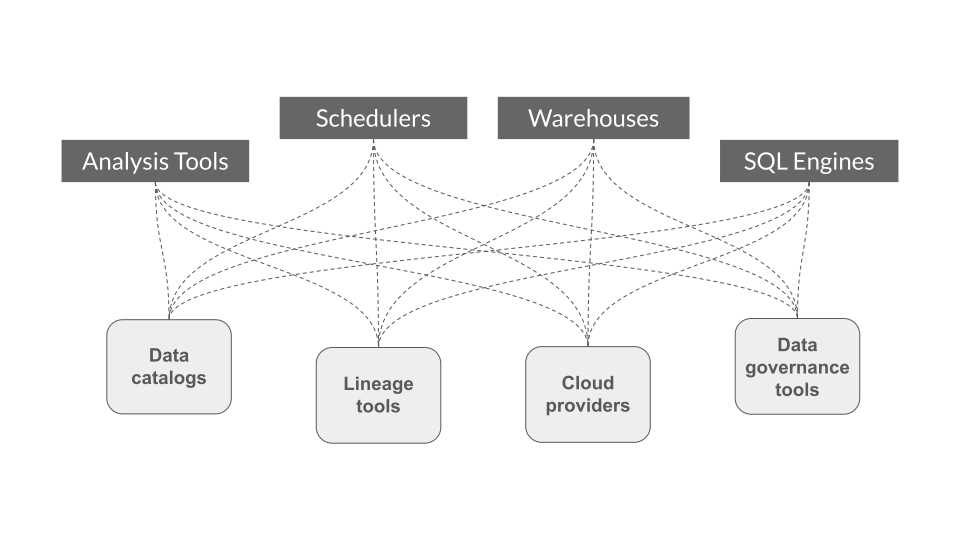
- 每个项目都必须自行实现自定义的元数据收集集成,从而造成重复劳动。
- 集成是外部的,可能会随着底层调度器和/或数据处理框架的新版本而中断,要求项目确保 向后 兼容性。
使用 OpenLineage
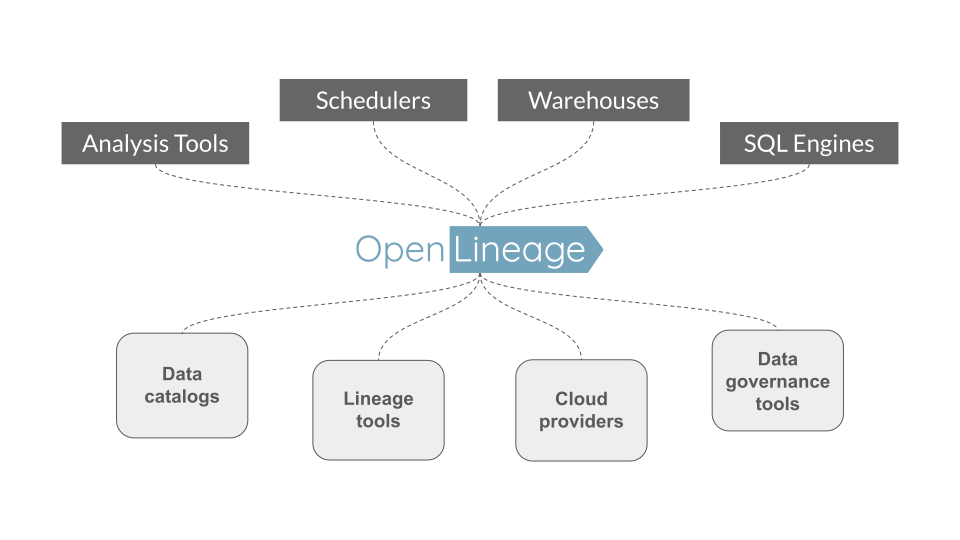
- 集成工作可在项目间 共享。
- 集成可以 推送 到底层调度器和/或数据处理框架;不再需要追赶并确保兼容性!
范围
OpenLineage 定义了正在运行作业及其对应事件的元数据。
可配置的后端允许用户选择将事件发送到的协议。
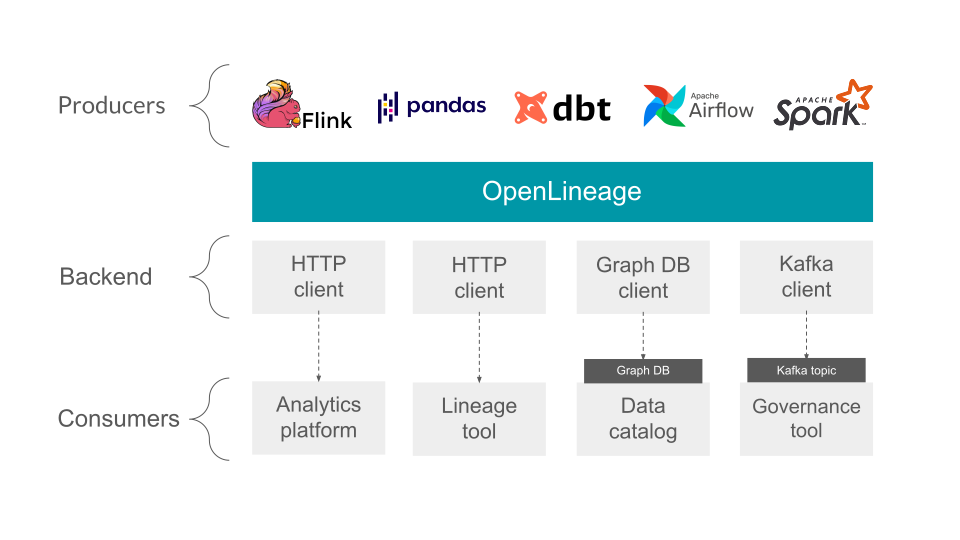
核心模型
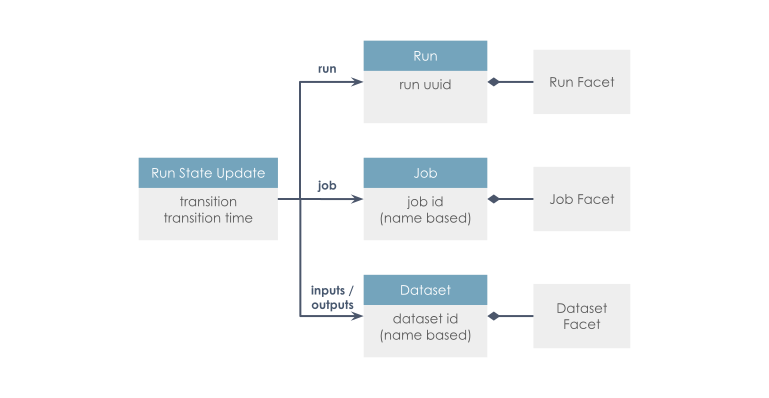
Facet 是一个附加到某个核心实体的原子元数据片段。
有关更多详细信息,请参阅规范。
规范
规范 使用 OpenAPI 定义,并允许通过自定义 Facet 进行扩展。
集成
OpenLineage 仓库包含与多个系统的集成。
相关项目
-
Marquez:Marquez 是一个 LF AI & DATA 项目,用于收集、聚合和可视化数据生态系统的元数据。它是 OpenLineage API 的参考实现。
-
Egeria:Egeria 开放元数据和治理。一个元数据总线。
风险提示与免责声明
本文内容基于公开信息研究整理,不构成任何形式的投资建议。历史表现不应作为未来收益保证,市场存在不可预见的波动风险。投资者需结合自身财务状况及风险承受能力独立决策,并自行承担交易结果。作者及发布方不对任何依据本文操作导致的损失承担法律责任。市场有风险,投资须谨慎。