
OpenLineage 是一个用于元数据和血缘采集的开放标准,专为在作业运行时动态采集数据而设计。它通过统一的命名策略定义了由作业(Job)、运行实例(Run)和数据集(Dataset) 组成的通用模型,并通过可扩展的Facets机制对这些实体进行元数据增强。
该项目是 LF AI & Data 基金会的毕业级项目,处于活跃开发阶段,欢迎社区贡献。
使用 Apache Airflow® 和 OpenLineage + Marquez 入门
Getting Started with Apache Airflow® and OpenLineage+Marquez
本教程将指导你配置 Apache Airflow® 以将 OpenLineage 事件发送到 Marquez,并通过一个真实的故障排查场景进行探索。
目录
- 前提条件
- 获取并启动 Marquez
- 配置 Airflow 将 OpenLineage 事件发送到 Marquez
- 编写 Airflow DAG
- 在 Marquez 中查看已收集的血缘
- 使用 Marquez 排查失败的 DAG
- 后续步骤
- 反馈
前提条件
开始前,请确保已安装:
如需在本地轻松安装并运行 Airflow 以用于开发,请参阅:快速开始。
获取并启动 Marquez
-
创建 Marquez 目录,然后通过运行以下命令检出 Marquez 源码:
MacOS/Linux
bashgit clone https://github.com/MarquezProject/marquez && cd marquezWindows
bashgit config --global core.autocrlf false git clone https://github.com/MarquezProject/marquez && cd marquez -
Airflow 和 Marquez 都需要 5432 端口用于其元数据库,但 Marquez 服务更易于配置。你也可以即时为数据库服务分配一个新端口。要使用 2345 端口启动 Marquez,请运行:
MacOS/Linux
bash./docker/up.sh --db-port 2345Windows
验证 Postgres 和 Bash 是否在
PATH中,然后运行:bashsh ./docker/up.sh --db-port 2345 -
要查看 Marquez UI 并验证其运行状态,请打开 http://localhost:3000。该 UI 允许你:
- 查看跨平台依赖关系,即你可在生态系统中查看生成或消费关键表的工具中的作业。
- 查看当前和先前作业运行的运行级元数据,使你能够看到作业的最新状态和数据集的更新历史。
- 获取资源使用情况的高级视图,使你能够查看操作中的趋势。
配置 Airflow 将 OpenLineage 事件发送到 Marquez
-
要配置 Airflow 以将 OpenLineage 事件发送到 Marquez,你需要修改本地 Airflow 环境并添加依赖。首先,定义一个 OpenLineage 传输。一种方法是使用环境变量。要使用
http并将事件发送到本地端口5000上运行的 Marquez API,请运行:MacOS/Linux
bashexport AIRFLOW__OPENLINEAGE__TRANSPORT='{"type": "http", "url": "http://localhost:5000", "endpoint": "api/v1/lineage"}'Windows
bashset AIRFLOW__OPENLINEAGE__TRANSPORT='{"type": "http", "url": "http://localhost:5000", "endpoint": "api/v1/lineage"}' -
你还需要为 Airflow 作业定义一个命名空间。它可以是任意字符串。请运行:
MacOS/Linux
bashexport AIRFLOW__OPENLINEAGE__NAMESPACE='my-team-airflow-instance'Windows
bashset AIRFLOW__OPENLINEAGE__NAMESPACE='my-team-airflow-instance' -
要将所需的 Airflow OpenLineage Provider 包添加到你的 Airflow 环境,请运行:
MacOS/Linux
bashpip install apache-airflow-providers-openlineageWindows
bashpip install apache-airflow-providers-openlineage -
要完成本教程,你还需要在 Airflow 中启用本地 Postgres 操作。为此,请运行:
MacOS/Linux
bashpip install apache-airflow-providers-postgresWindows
bashpip install apache-airflow-providers-postgres -
在本地 Postgres 实例中创建一个数据库,并使用默认 ID (
postgres_default) 创建一个 Airflow Postgres 连接。如需前者帮助,请参阅:Postgres 文档。如需后者帮助,请参阅:管理连接。
编写 Airflow DAG
在此步骤中,你将创建两个新的 Airflow DAG,它们执行简单任务,并将其添加到你现有的 Airflow 实例。counter DAG 每分钟将列值加 1,而 sum DAG 每五分钟计算一次总和。这将形成一个包含两个作业和两个数据集的简单管道。
-
在
dags/目录下,创建一个名为counter.py的文件,并添加以下代码:pythonimport pendulum from airflow.decorators import dag, task from airflow.providers.postgres.operators.postgres import PostgresOperator from airflow.utils.dates import days_ago @dag( schedule='*/1 * * * *', start_date=days_ago(1), catchup=False, is_paused_upon_creation=False, max_active_runs=1, description='DAG that generates a new count value equal to 1.' ) def counter(): query1 = PostgresOperator( task_id='if_not_exists', postgres_conn_id='postgres_default', sql=''' CREATE TABLE IF NOT EXISTS counts (value INTEGER); ''', ) query2 = PostgresOperator( task_id='inc', postgres_conn_id='postgres_default', sql=''' INSERT INTO "counts" (value) VALUES (1); ''', ) query1 >> query2 counter() -
在
dags/目录下,创建一个名为sum.py的文件,并添加以下代码:pythonimport pendulum from airflow.decorators import dag, task from airflow.providers.postgres.operators.postgres import PostgresOperator from airflow.utils.dates import days_ago @dag( start_date=days_ago(1), schedule='*/5 * * * *', catchup=False, is_paused_upon_creation=False, max_active_runs=1, description='DAG that sums the total of generated count values.' ) def sum(): query1 = PostgresOperator( task_id='if_not_exists', postgres_conn_id='postgres_default', sql=''' CREATE TABLE IF NOT EXISTS sums ( value INTEGER );''' ) query2 = PostgresOperator( task_id='total', postgres_conn_id='postgres_default', sql=''' INSERT INTO sums (value) SELECT SUM(value) FROM counts; ''' ) query1 >> query2 sum() -
重启 Airflow 以应用更改。然后,取消暂停两个 DAG。
在 Marquez 中查看已收集的血缘
-
要查看 Marquez 从 Airflow 收集的血缘,请访问 http://localhost:3000 打开 Marquez UI。然后,使用左上角搜索栏搜索
counter.inc作业。要查看counter.inc的血缘元数据,请从下拉列表中点击该作业: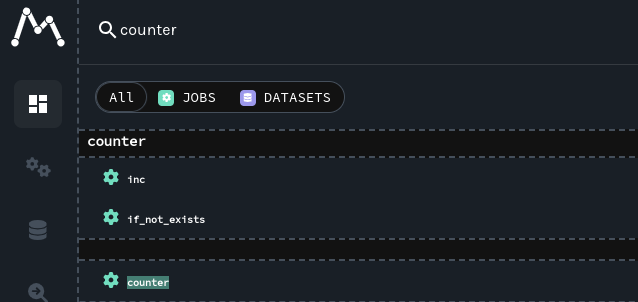
-
查看
counter.inc的血缘图,你应看到<database>.public.counts作为输出数据集,sum.total作为下游作业:
使用 Marquez 排查失败的 DAG
-
在此步骤中,你将模拟由于跨 DAG 依赖项更改导致的管道中断,并了解来自 OpenLineage + Marquez 的增强血缘如何使架构更改的故障排查变得轻松。
假设
Team A拥有 DAGcounter。Team A更新counter以将counts表中的values列重命名为value_1_to_10,但未将架构更改正确传达给拥有sum的团队。对
counter应用以下更改以模拟破坏性更改:diffquery1 = PostgresOperator( - task_id='if_not_exists', + task_id='alter_name_of_column', postgres_conn_id='example_db', sql=''' - CREATE TABLE IF NOT EXISTS counts ( - value INTEGER - );''', + ALTER TABLE "counts" RENAME COLUMN "value" TO "value_1_to_10"; + ''' )diffquery2 = PostgresOperator( task_id='inc', postgres_conn_id='example_db', sql=''' - INSERT INTO counts (value) + INSERT INTO counts (value_1_to_10) VALUES (1) ''', )正如
sum的所有者Team B所做的那样,注意 Marquez 中 DataOps 视图的失败运行:
Team B只能猜测 DAG 失败的可能原因,因为 DAG 最近没有更改。因此,团队决定检查 Marquez。 -
在 Marquez 中,导航到 Datasets 视图,并从右上角的命名空间下拉菜单中选择你的 Postgres 实例。然后,点击
<database>.public.counts数据集并检查图表。你将在节点上找到架构: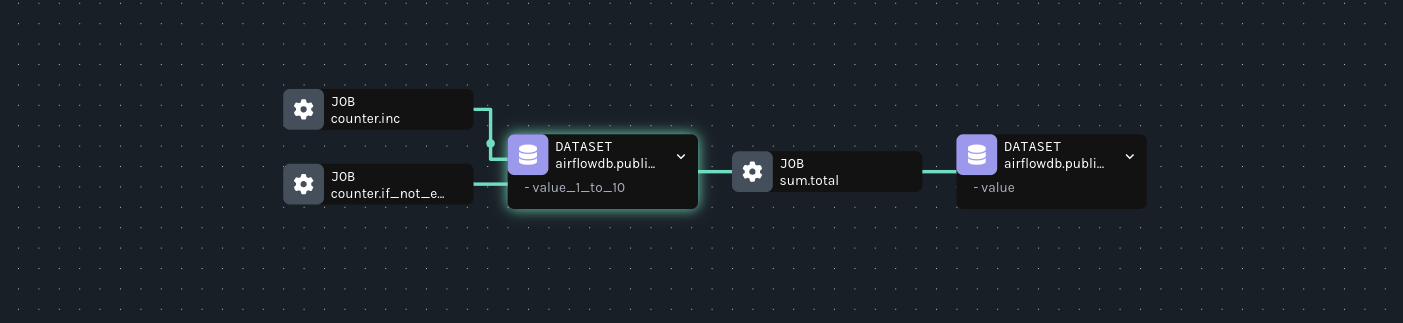
-
假设你不认识该列,并希望了解其原始名称及更改时间。点击节点将打开详情抽屉。在那里,使用版本历史查找架构更改的运行:
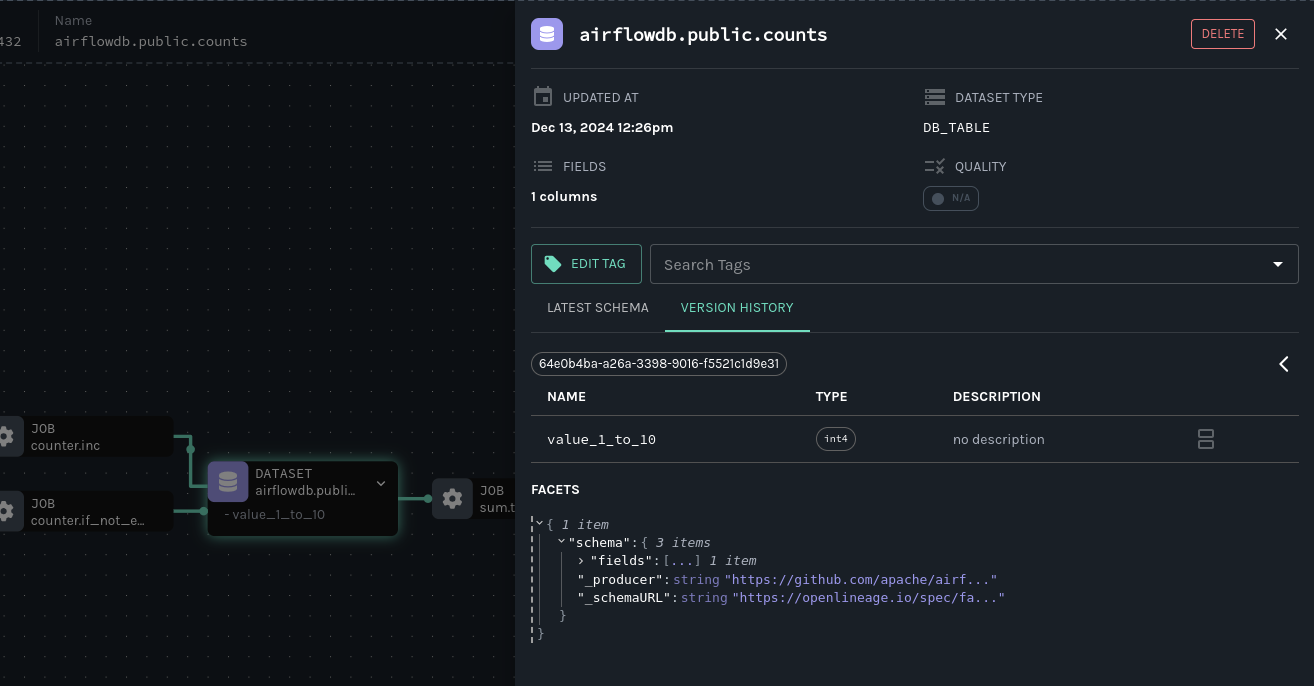
-
在 Airflow 中,通过更新计算计数总和的任务以使用新列名来修复中断的下游 DAG:
diffquery2 = PostgresOperator( task_id='total', postgres_conn_id='example_db', sql=''' - INSERT INTO sums (value) - SELECT SUM(value) FROM counts; + SELECT SUM(value_1_to_10) FROM counts; ''' ) -
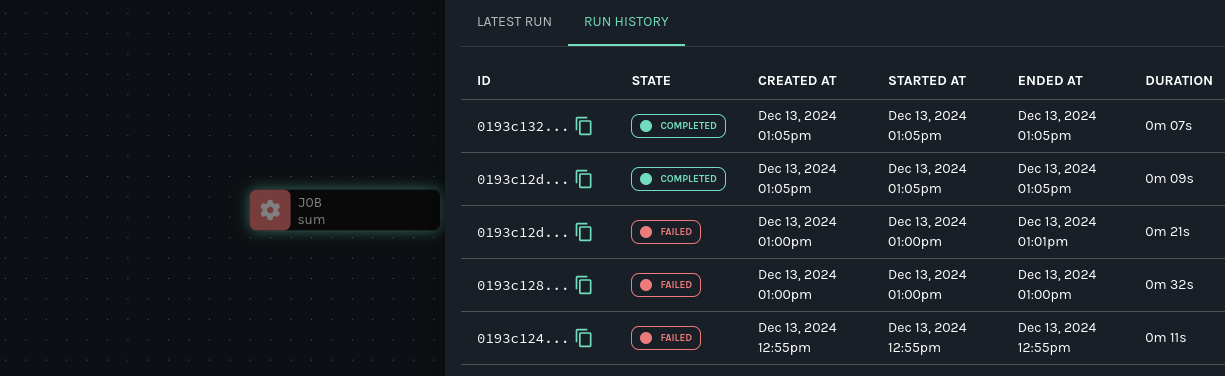
重新运行 DAG。在 Marquez 中,通过查看 DataOps 视图中最近的运行历史来验证修复:
后续步骤
- 查看用于收集 Airflow DAG 元数据的 Marquez HTTP API,并学习如何使用 OpenLineage 构建自己的集成。
- 查看可与 Airflow 一起使用的
openlineage-spark集成。
反馈
你觉得本指南如何?请在 OpenLineage Slack 或 Marquez Slack 中告诉我们。你也可以通过 提交拉取请求 直接提出更改。
风险提示与免责声明
本文内容基于公开信息研究整理,不构成任何形式的投资建议。历史表现不应作为未来收益保证,市场存在不可预见的波动风险。投资者需结合自身财务状况及风险承受能力独立决策,并自行承担交易结果。作者及发布方不对任何依据本文操作导致的损失承担法律责任。市场有风险,投资须谨慎。