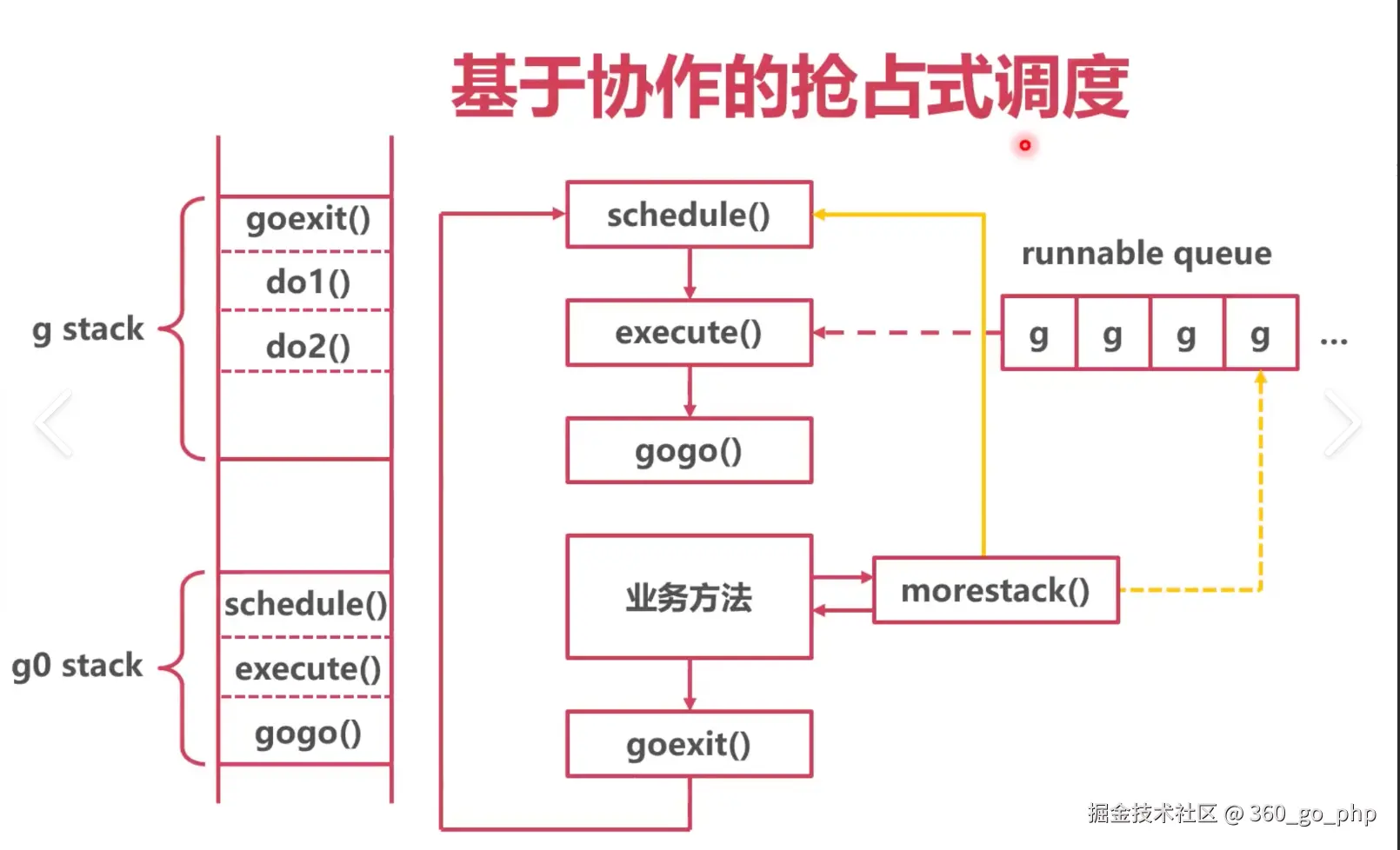
在 Go 语言中,Goroutine 是实现并发的基本单位,而 Go 的并发模型(也称为 GMP 模型)则是其并发系统的核心。理解 Goroutine 的工作原理以及 GMP 模型对于高效开发并发程序至关重要。本文将深入探讨 Goroutine 的实现机制,以及 Go 的 GMP 模型如何高效地调度和管理 Goroutines。

一、什么是 Goroutine?
Goroutine 是 Go 语言中的轻量级线程,是实现并发的核心。与操作系统线程不同,Goroutine 在创建和切换时的开销非常小,因此可以在同一程序中创建成千上万的 Goroutine 而不会影响性能。Goroutine 是由 Go 运行时(runtime)管理的,并且每个 Goroutine 都在独立的栈上运行。
GM模型
面试官:你知道GMP之前用的是GM模型吗?
超超:这个我知道,在12年的go1.1版本之前用的都是GM模型,但是由于GM模型性能不好,饱受用户诟病。之后官方对调度器进行了改进,变成了我们现在用的GMP模型。
面试官:那你能给我说说什么是GM模型?为什么效率不好呢?
考点:GM模型
超超:GM模型中的G全称为Goroutine协程,M全称为Machine内核级线程,调度过程如下
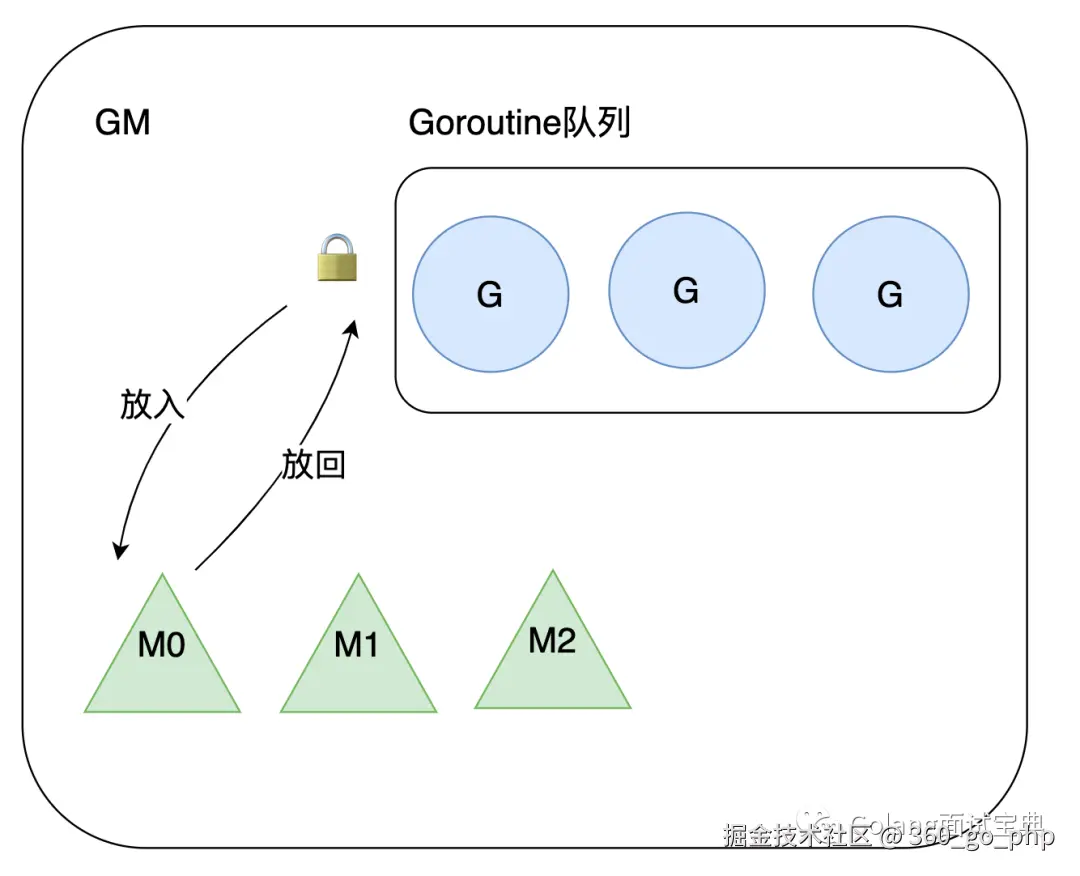
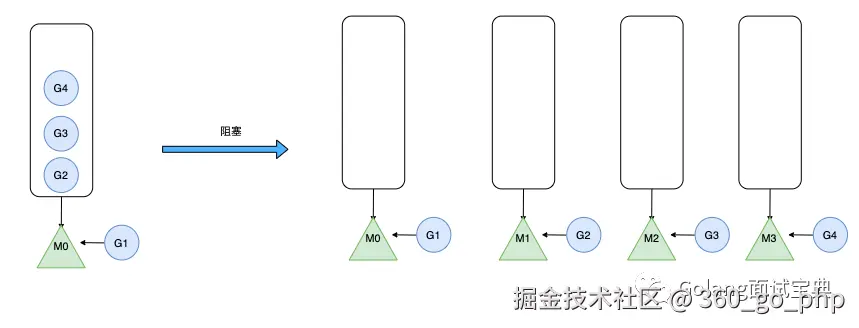
M(内核线程)从加锁的Goroutine队列中获取G(协程)执行,如果G在运行过程中创建了新的G,那么新的G也会被放入全局队列中。
很显然这样做有俩个缺点,一是调度,返回G都需要获取队列锁,形成了激烈的竞争。二是M转移G没有把资源最大化利用。比如当M1在执行G1时,M1创建了G2,为了继续执行G1,需要把G2交给M2执行,因为G1和G2是相关的,而寄存器中会保存G1的信息,因此G2最好放在M1上执行,而不是其他的M。
GMP
面试官:那你能给我说说GMP模型是怎么设计的吗?
考点:GMP设计
超超:G全称为Goroutine协程,M全称为Machine内核级线程,P全称为Processor协程运行所需的资源,他在GM的基础上增加了一个P层,下面我们来看一下他是如何设计的。
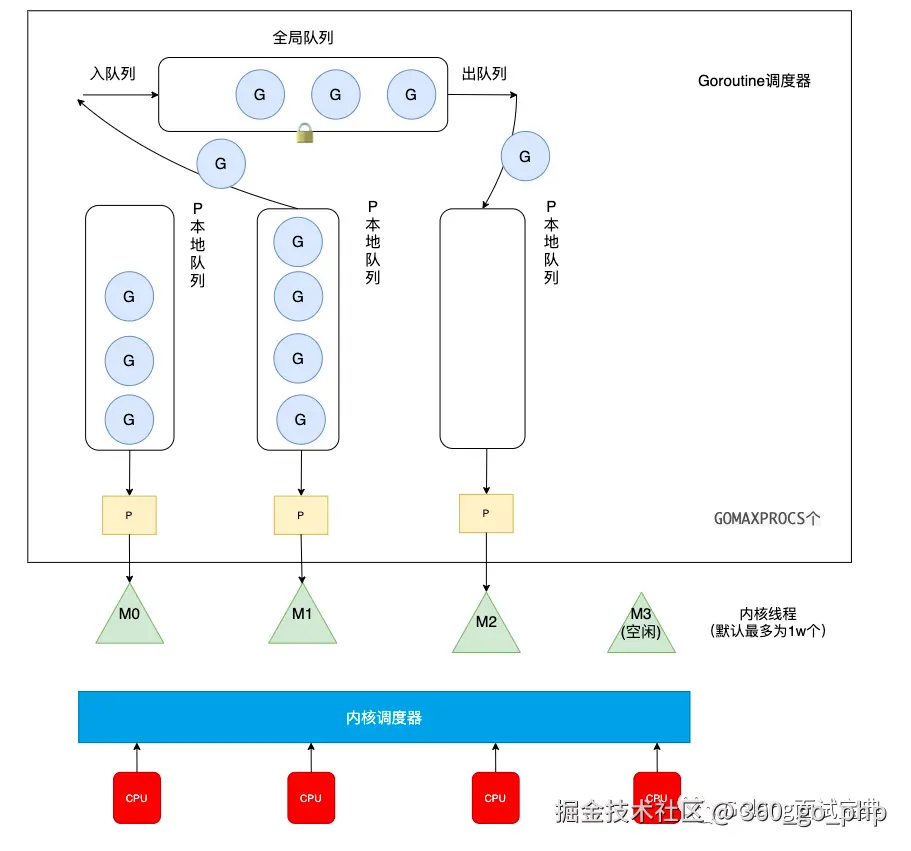
全局队列:当P中的本地队列中有协程G溢出时,会被放到全局队列中。
P的本地队列:P内置的G队列,存的数量有限,不超过256个。这里有俩种特殊情况。一是当队列P1中的G1在运行过程中新建G2时,G2优先存放到P1的本地队列中,如果队列满了,则会把P1队列中一半的G移动到全局队列。二是如果P的本地队列为空,那么他会先到全局队列中获取G,如果全局队列中也没有G,则会尝试从其他线程绑定的P中偷取一半的G。
面试官:P和M数量是可以无限扩增的吗?
考点:GMP细节
超超:是不能无限扩增的,无限扩增系统也承受不了呀,哈哈
P的数量:由启动时环境变量$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()决定。
M的数量:go程序启动时,会设置M的最大数量,默认10000。但是内核很难创建出如此多的线程,因此默认情况下M的最大数量取决于内核。也可以调用runtime/debug中的SetMaxThreads函数,手动设置M的最大数量。
面试官:那P和M都是在程序运行时就被创建好了吗?
考点:继续深挖GMP细节
超超:P和M创建的时机是不同的
P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P。
M何时创建:内核级线程的初始化是由内核管理的,当没有足够的M来关联P并运行其中的可运行的G时会请求创建新的M。比如M在运行G1时被阻塞住了,此时需要新的M去绑定P,如果没有在休眠的M则需要新建M。
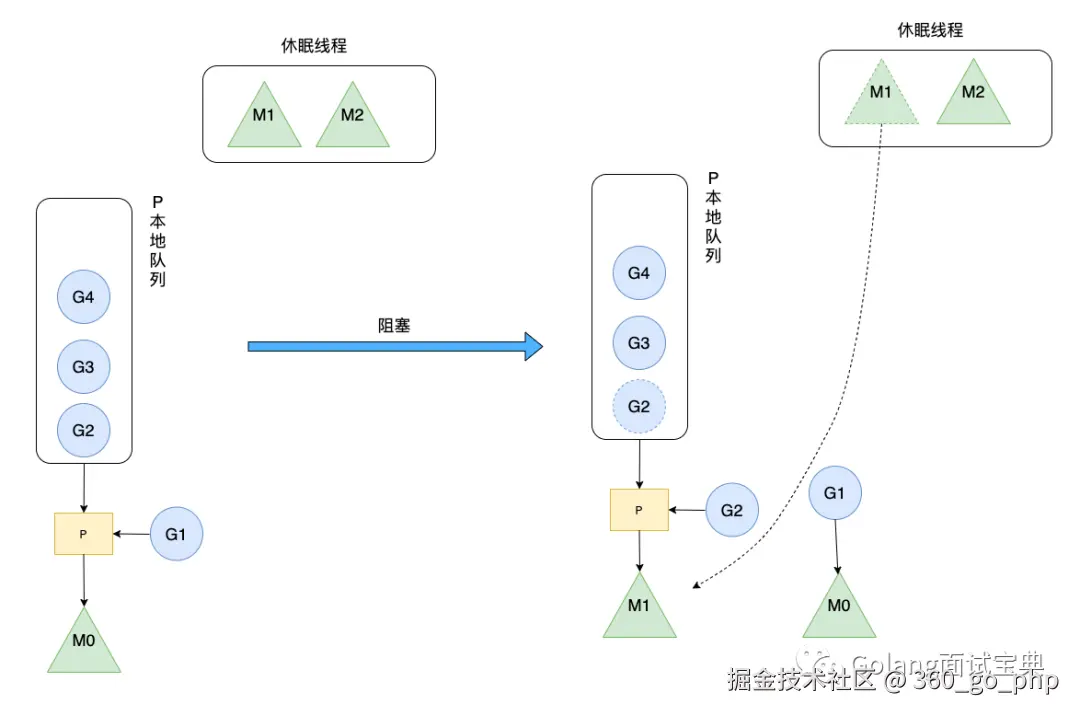
面试官:你能给我说说当M0将G1执行结束后会怎样做吗?
考点:G在GMP模型中流动过程
超超:那我给你举个例子吧(:这次把整个过程都说完,看你还能问什么
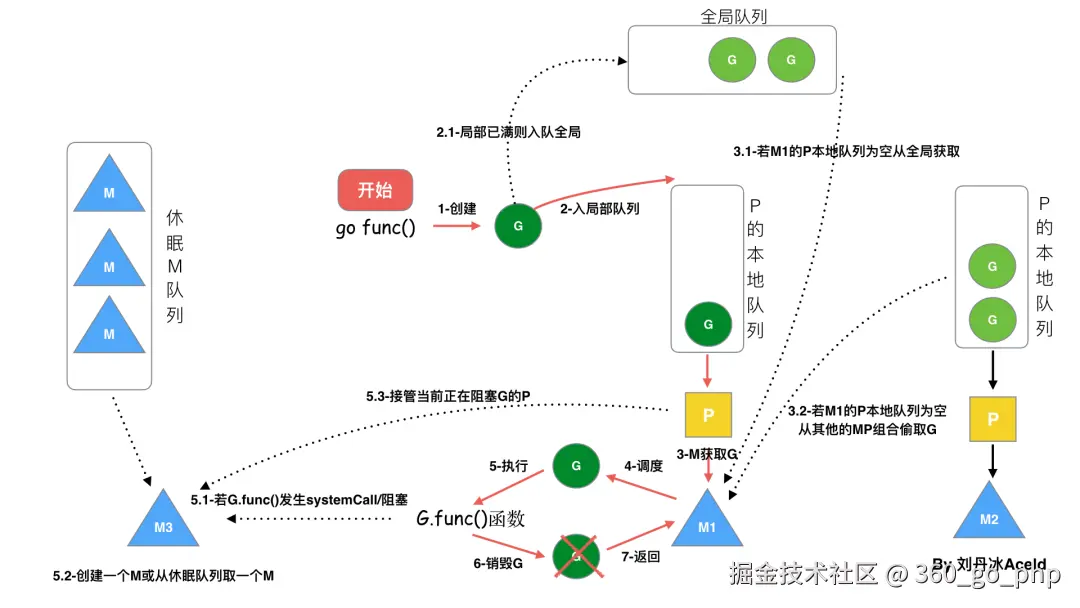
(图转自刘丹冰Golang的协程调度器原理及GMP设计思想)
-
调用 go func()创建一个goroutine;
-
新创建的G优先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中;
-
M需要在P的本地队列弹出一个可执行的G,如果P的本地队列为空,则先会去全局队列中获取G,如果全局队列也为空则去其他P中偷取G放到自己的P中
-
G将相关参数传输给M,为M执行G做准备
-
当M执行某一个G时候如果发生了系统调用产生导致M会阻塞,如果当前P队列中有一些G,runtime会将线程M和P分离,然后再获取空闲的线程或创建一个新的内核级的线程来服务于这个P,阻塞调用完成后G被销毁将值返回;
-
销毁G,将执行结果返回
-
当M系统调用结束时候,这个M会尝试获取一个空闲的P执行,如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中。
GM与GMP
面试官:看来你对GMP整个流程还是比较清楚的,那你再给我说说GMP相对于GM做了哪些优化吧。
考点:GM与GMP区别
超超:优化点有三个,一是每个 P 有自己的本地队列,而不是所有的G操作都要经过全局的G队列,这样锁的竞争会少的多的多。而 GM 模型的性能开销大头就是锁竞争。
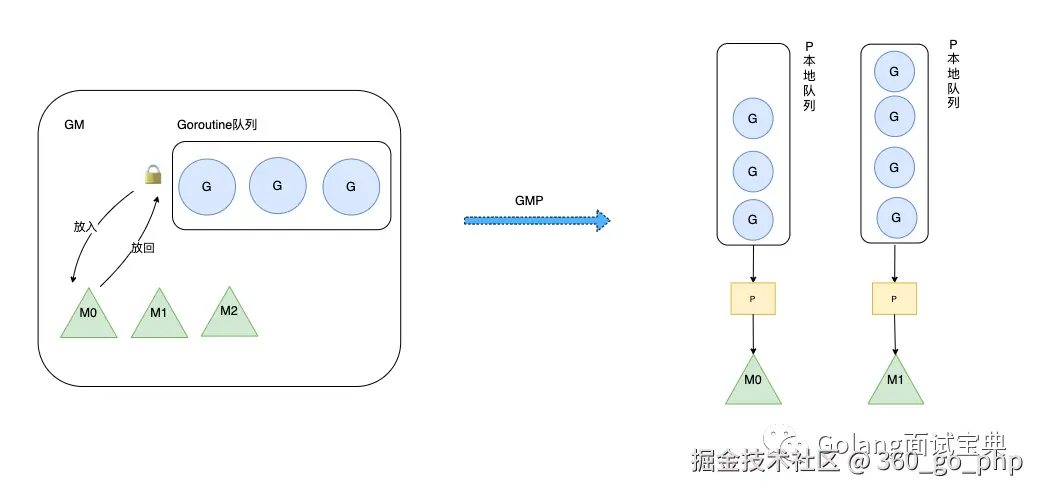
二是P的本地队列平衡上,在 GMP 模型中也实现了 Work Stealing 算法,如果 P 的本地队列为空,则会从全局队列或其他 P 的本地队列中窃取可运行的 G 来运行(通常是偷一半),减少空转,提高了资源利用率。
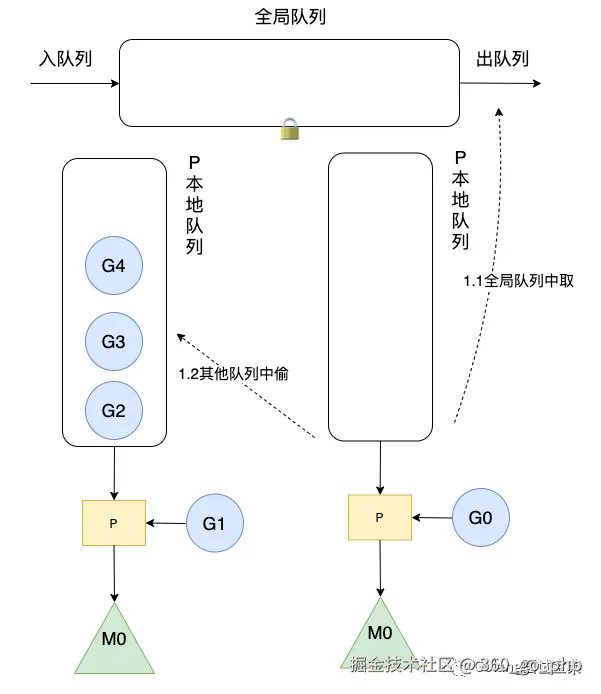
三是hand off机制当M0线程因为G1进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程M1执行,同样也是提高了资源利用率。
面试官:你有没有想过队列和线程的优化可以做在G层和M层,为什么要加一个P层呢?
考点:深挖GMP
超超:这是因为M层是放在内核的,我们无权修改,在前面协程的问题中回答过,内核级也是用户级线程发展成熟才加入内核中。所以在M无法修改的情况下,所有的修改只能放在用户层。将队列和M绑定,由于hand off机制M会一直扩增,因此队列也需要一直扩增,那么为了使Work Stealing 能够正常进行,队列管理将会变的复杂。因此设定了P层作为中间层,进行队列管理,控制GMP数量(最大个数为P的数量)。
二、什么是 GMP 模型?
GMP 模型是 Go 语言并发调度的核心模型,负责将 Goroutine 映射到操作系统线程(OS thread)上进行执行。这个模型的名称源于三个关键部分:
- G (Goroutine) :表示 Go 语言的轻量级线程。每个 Goroutine 是 Go 程序的基本执行单位,具有独立的栈,并且由 Go 运行时调度。
- M (Machine) :表示操作系统线程。每个 M 代表一个操作系统线程,Go 运行时使用 M 来执行 Goroutine。
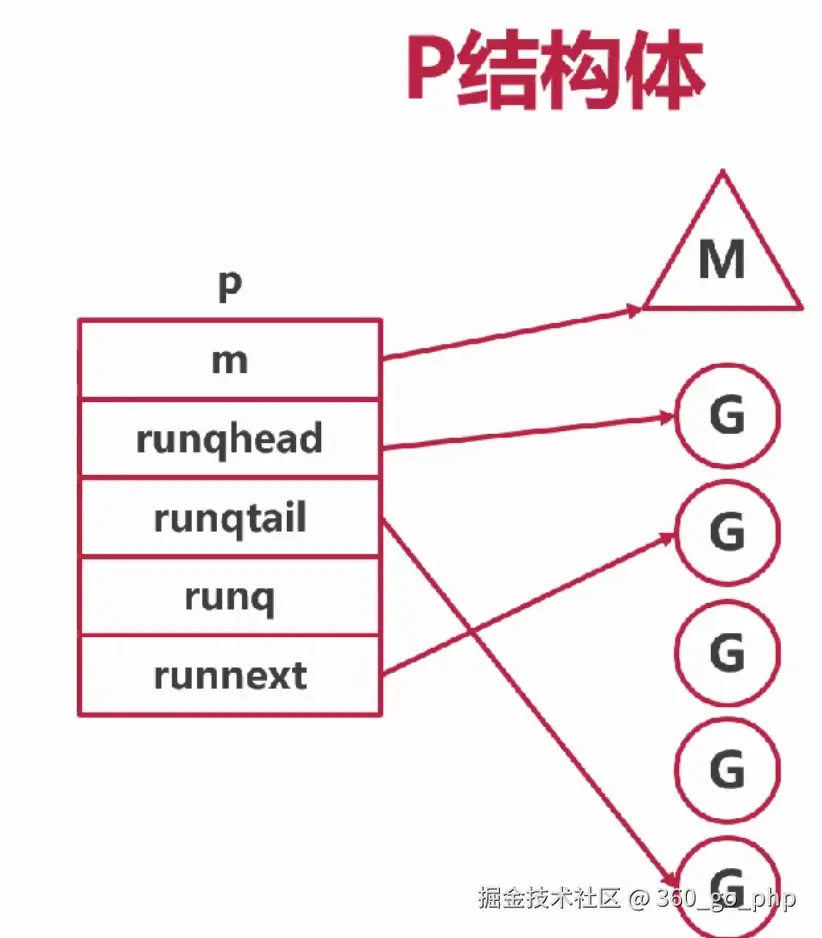
- P (Processor) :表示 Go 运行时中的处理器,它是执行 Goroutine 的资源调度器。每个 P 控制着一组 M 和一个 Goroutine 队列,并负责将 Goroutine 分配给 M 以执行。
三、GMP 模型如何工作?
Go 的运行时使用 GMP 模型来实现 Goroutine 的调度。每个 Goroutine 都会被分配给一个 P,而每个 P 会在一个 M 上执行。操作系统线程(M)与 Goroutine(G)之间的映射是由 Go 运行时管理的,并不是一一对应的,运行时调度器通过将多个 Goroutine 分配给一个 M 来最大化 CPU 核心的利用。
1. Goroutine 和 P 的关系:
每个 P 都有一个与之关联的 Goroutine 队列,当一个 Goroutine 被启动时,它会被添加到某个 P 的队列中。在 Go 程序中,通常会启动多个 Goroutine,运行时调度器会根据空闲的 P 来选择合适的 Goroutine 来执行。
2. P 和 M 的关系:
每个 M 都会绑定一个 P,当 M 运行时,它会执行与该 P 关联的 Goroutine。为了提高并发性,Go 的调度器会动态调整 P 和 M 的绑定关系,确保 Goroutine 能够在不同的 M 上进行高效执行。
3. G、P 和 M 的调度:
Go 的调度器会周期性地调整 M 与 P 的绑定关系,尤其在高并发环境下,调度器会尽量让每个 CPU 核心都能有 P 在运行,确保更高效的并发执行。
四、Goroutine 的内存管理和调度
Go 的调度器使用了一个被称为 协作式调度(Cooperative Scheduling)的机制。Go 运行时会根据以下规则来管理 Goroutine 和操作系统线程的调度:
- Goroutine 的栈空间:每个 Goroutine 都有一个独立的栈,初始栈大小为 2 KB,随着 Goroutine 的执行,它的栈会动态增长和缩小,以减少内存占用。
- 调度周期:Go 的调度器每 10 毫秒就会进行一次 Goroutine 的调度。调度器会在空闲的 M 上分配新的 Goroutine,确保充分利用系统资源。
- 抢占式调度:虽然 Go 的调度模型主要基于协作式调度,但在特定情况下,Go 运行时会进行抢占式调度。比如,如果一个 Goroutine 在执行过程中长时间没有主动让出 CPU,调度器会强制让它暂停,重新调度其他 Goroutine。
五、GMP 模型的优势与挑战
1. 优势:
- 高效的资源利用:通过将多个 Goroutine 映射到少数几个 M 上,Go 的调度器能够更高效地利用 CPU 核心,并且不需要操作系统线程的过度开销。
- 动态调整:Go 调度器能够根据当前的负载动态地调整 P 与 M 的关系,适应不同的工作负载。
- 低内存消耗:每个 Goroutine 的栈空间非常小,通常只有 2 KB,能够容纳成千上万的 Goroutine。
2. 挑战:
- 调度器复杂度:虽然 Go 的调度器设计得非常高效,但在高并发情况下,调度器的内部工作可能变得复杂,需要精细的调度策略。
- 内存占用:尽管 Goroutine 栈大小较小,但大量的 Goroutine 会导致堆内存占用增加,可能需要优化内存管理策略。
六、总结
Go 的并发模型基于 Goroutine 和 GMP,通过灵活的调度机制,高效地利用了系统资源。Goroutine 的轻量化设计使得 Go 程序能够在高并发场景下处理大量任务,而 GMP 模型的调度算法则保证了资源的高效利用。理解 Goroutine 和 GMP 模型的原理,对于编写高效并发程序非常重要。在实际开发中,程序员需要根据具体的业务场景合理设计 Goroutine 的使用,确保系统的高效和稳定。