作为一名开发者,我们经常需要从 YouTube 等平台获取技术资讯。但看视频太费时间,如果能自动把视频内容转录、提炼并整理成一篇结构清晰的 Markdown 技术博客,效率将直接起飞。
今天分享我基于 n8n 搭建的一套全自动工作流,它能实现:
-
自动下载:输入 URL,自动按日期归档下载。
-
音频提取:自动压缩音频以适应 API 限制。
-
极速转录:使用 Groq 的 Whisper-v3 模型(速度极快)。
-
AI 洗稿:使用 DeepSeek 模型将口语转为技术博文。
-
自动归档:将生成的 Markdown 文件保存到本地。


🏗️ 架构概览
整个工作流包含 7 个核心步骤:
表单触发 -> yt-dlp 下载 -> 路径清洗 -> ffmpeg 提取音频 -> Groq 语音转文字 -> DeepSeek AI 重写 -> 保存 MD 文件
🛠️ 前置准备 (Docker 环境)
为了让 n8n 的 Code 节点能够直接读写硬盘文件(这是本工作流最关键的 Hack 点),我们需要在启动 Docker 时添加环境变量:
YAML
environment:
- NODE_FUNCTION_ALLOW_BUILTIN=fs # 允许 Code 节点使用 fs 模块
- N8N_SECURE_FILE_SYSTEM_ACCESS_WHITELIST=/files # 允许访问挂载目录
volumes:
- /your/local/path:/files # 挂载下载目录🚀 核心节点详解
1. 下载与归档 (yt-dlp)
我们需要一个 Execute Command 节点来下载视频。为了方便管理,我增加了一个"按日期归档"的功能。
命令逻辑: 利用 n8n 的 $now 变量生成 YYYY-MM-DD 文件夹,并使用 --print filename 让 yt-dlp 吐出最终的文件路径,方便后续节点抓取。
Bash
yt-dlp -o '/files/{{ $now.toFormat("yyyy-MM-dd") }}/%(title)s.%(ext)s' {{ $json.url }} --print filename --no-simulate2. 路径清洗 (Code Node)
yt-dlp 输出的路径可能包含多行日志。我们需要精准提取出 全路径、文件名 和 所在文件夹。
这里的关键是用正则去掉文件后缀,生成 clean_name,后续生成的 MD 文件就用这个名字。
javascript
// 核心逻辑:提取不带后缀的文件名
const filenameWithExt = filePath.split('/').pop();
clean_name: filenameWithExt.replace(/\.[^/.]+$/, "")3. 音频瘦身 (ffmpeg)
直接传视频给 AI 接口既慢又费钱。我们需要用 ffmpeg 提取音频并"压榨"体积。
命令参数:
-
vn: 去掉视频流。
-
ac 1: 单声道(人声单声道足矣)。
-
b:a 64k: 64k 码率(保证 Whisper 能听清,同时体积极小)。
bash
ffmpeg -i "{{ $json.full_path }}" -vn -ac 1 -b:a 64k "{{ $json.folder_dir }}/{{ $json.clean_name }}.mp3" -y4. 绕过限制读取文件 (Code Node with fs)
n8n 原生的 Read Binary File 节点受限于权限配置,有时读取大文件不稳定。既然我们在 Docker 里开放了 fs 权限,直接用 JS 代码读取文件到底层 Buffer 是最稳健的。
js
const fs = require('fs');
// 直接读取 ffmpeg 生成的 mp3 路径
const fileBuffer = fs.readFileSync(filePath);
// 转为 n8n 标准 Binary 对象
const binaryData = {
data: {
data: fileBuffer.toString('base64'),
mimeType: 'audio/mpeg',
// ...
}
};5. 极速转录 (HTTP Request + Groq)
为什么不用 n8n 自带的 OpenAI 节点?因为原生节点对模型名称有白名单限制,无法直接调用 Groq 的 whisper-large-v3。
使用 HTTP Request 节点构建原生 POST 请求,可以无视限制:
-
Body: Multipart-form-data
-
Model: whisper-large-v3
-
File: 映射上一步的 Binary Data。
6. AI 深度洗稿 (DeepSeek + Basic LLM Chain)
拿到原始文本后,如果直接看就是一堆流水账。我们需要 AI 扮演"主编"角色。
-
模型:DeepSeek Chat (性价比之王)。
-
Prompt 设计:
"你是一位资深的技术博客主编... 请执行以下任务:重构逻辑、清洗语言、Markdown排版..."
这一步能将口语化的 "这个、那个、我们来看一下" 转化为 "### 核心原理" 这样的结构化内容。
7. 闭环写入 (Merge & Code Node)
最后一步,我们需要把 AI 生成的文本写入 .md 文件。
Merge 节点:我们需要 步骤2 的 clean_name (文件名) 和 步骤6 的 text (文章内容)。所以用 Merge 节点把这两路数据合并。
写入硬盘:再次使用 fs.writeFileSync 直接写入。
js
const fs = require('fs');
const content = $('Basic LLM Chain').first().json.text;
const fileName = $('格式化路径').first().json.clean_name;
const outputDir = $('格式化路径').first().json.folder_dir;
fs.writeFileSync(`${outputDir}/${fileName}.md`, content, 'utf8');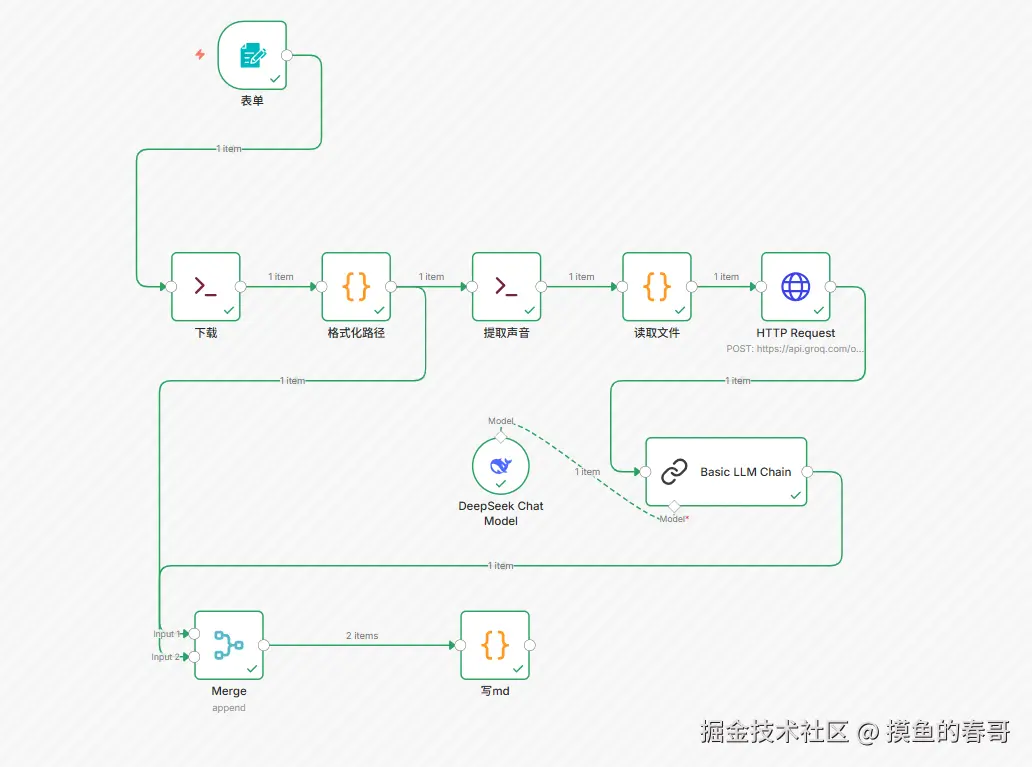
避坑与心得
-
路径地狱:Windows 和 Linux 的路径斜杠方向不同,Docker 容器内外的路径映射也容易晕。最佳实践是依靠 yt-dlp --print filename 动态获取路径,而不是自己拼接字符串。
-
Groq 的优势:对于长视频,Groq 的 Whisper v3 速度极快,且目前 API 调用非常宽松,是音频转录的首选。
-
HTTP Request 的灵活性:当 n8n 原生节点跟不上 API 更新速度时(比如新模型发布),HTTP Request 节点永远是你的救星。
-
DeepSeek 的 Prompt:由于转录文本没有标点符号或断句错误,Prompt 中必须强调"修复转录错误"和"重构逻辑",否则 AI 可能会被带跑偏。
-
匿名能下载的视频有限,最终你还是得把你的cookie授权给工作流,这样一来你必须控制频率,否则账号非常可能被封。