论文题目:BlenderGym: Benchmarking Foundational Model Systems for Graphics Editing(BlenderGym:图形编辑的基准基础模型系统)
会议:CVPR2025
摘要:3D图形编辑在电影制作和游戏设计等应用中至关重要,但它仍然是一个耗时的过程,需要高度专业化的领域专业知识。自动化此过程具有挑战性,因为图形化编辑需要执行各种任务,每个任务都需要不同的技能集。最近,视觉语言模型(VLMs)作为自动化编辑过程的强大框架而出现,但由于缺乏需要人类水平感知和呈现现实世界编辑复杂性的综合基准,它们的开发和评估受到瓶颈。在这项工作中,我们提出了BlenderGym,这是第一个用于3D图形编辑的综合VLM系统基准。BlenderGym通过基于代码的3D重建任务来评估VLM系统。我们评估了封闭和开源的VLM系统,并观察到即使是最先进的VLM系统也很难完成对人类Blender用户来说相对容易的任务。在BlenderGym的支持下,我们研究了推理缩放技术如何影响VLM在图形编辑任务中的性能。值得注意的是,我们的研究结果表明,用于指导生成缩放的验证器本身可以通过推理缩放来改进,这补充了最近关于编码和数学任务中大型语言模型生成的推理缩放的见解。我们进一步表明,推理计算不是均匀有效的,可以通过在生成和验证之间策略性地分配来优化。
引言
在人工智能快速发展的今天,视觉语言模型(VLM)正在改变我们处理复杂视觉任务的方式。然而,在3D图形编辑这一专业领域,我们仍然缺乏系统性的评估工具。最近的一篇开创性论文,提出了BlenderGym------首个专门针对3D图形编辑的VLM基准测试系统。
背景:3D图形编辑的挑战
3D图形编辑在电影制作和游戏开发中起着至关重要的作用,但这个领域面临着几个根本性挑战:
专业技能壁垒高
- 需要掌握复杂的3D软件(如Blender、Maya、Unity)
- 涉及多种专业技能:建模、材质设计、光照、动画等
- 学习曲线陡峭,需要大量时间投入
评估困难
- 缺乏标准化的评估基准
- 传统评估依赖主观人工判断,成本高昂
- 不同方法间难以进行客观比较
虽然VLM在自动化图形编辑方面展现出潜力,但我们急需一个综合性的基准测试来系统评估这些模型的实际能力。
BlenderGym:开创性的解决方案
核心创新
BlenderGym采用了一种全新的评估方式:通过Python代码编辑进行3D场景重建。这种方法的巧妙之处在于:
- 客观性:使用固定的起始-目标场景对,消除主观评判
- 全面性:覆盖图形编辑的五个核心任务类型
- 实用性:模拟真实的图形编辑工作流程
五大任务类型
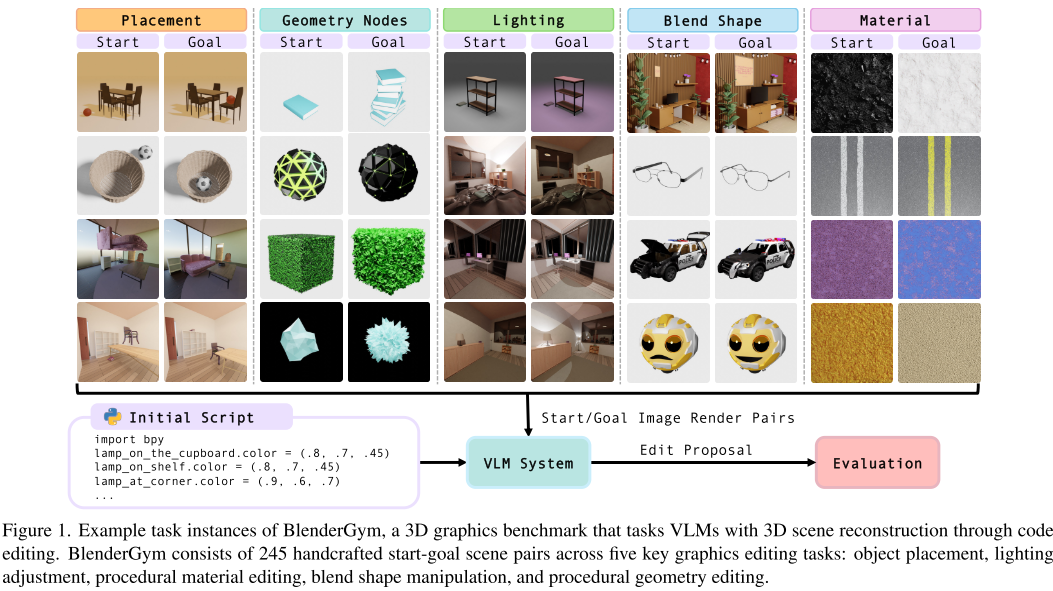
BlenderGym包含245个精心设计的任务实例,涵盖:
1. 物体放置(Object Placement)
- 测试模型对空间关系的理解
- 要求准确识别和重定位3D场景中的物体
- 评估指标:Chamfer距离、光度损失、CLIP得分
2. 程序化几何编辑(Procedural Geometry)
- 挑战模型的空间几何推理能力
- 涉及形状、尺度、空间分布的变化
- 需要使用Blender Python API和Infinigen包
3. 光照调整(Lighting Adjustments)
- 测试对光照环境的理解和操控
- 包括颜色、强度、位置、方向的调整
- 特别包含隐藏光源的推理场景
4. 混合形状操作(Blend Shape Manipulation)
- 评估对连续变量控制的掌握
- 涉及面部表情、物体形状等的精细调整
- 需要语义理解和数值精确控制
5. 程序化材质编辑(Procedural Material)
- 考验对表面材质的感知和修改能力
- 要求理解颜色、纹理、反射等属性
- 涉及复杂的着色器节点编辑
评估系统设计
VLM系统架构
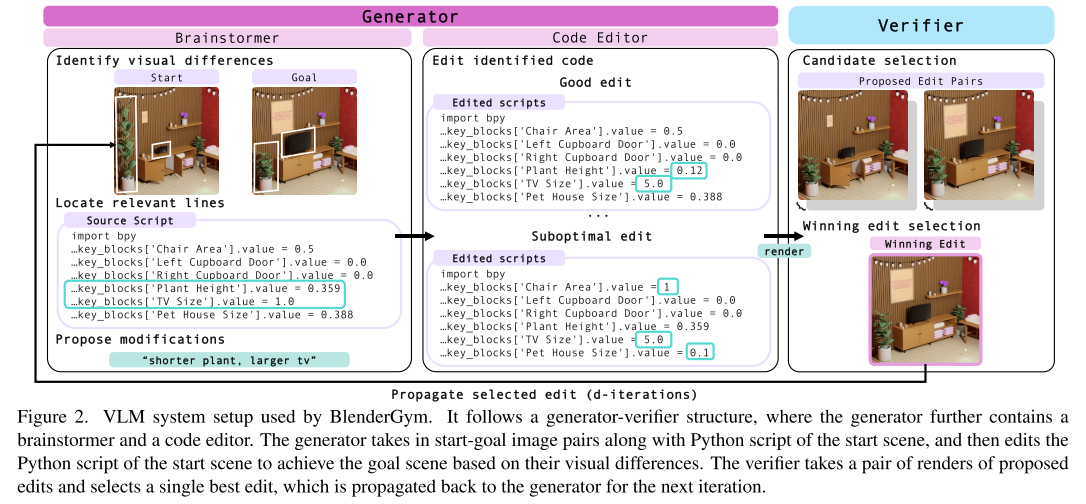
BlenderGym采用了生成器-验证器结构:
生成器(Generator):
- 头脑风暴者:识别视觉差异,定位相关代码行
- 代码编辑器:将指令转化为可执行的Python脚本
验证器(Verifier):
- 接收多个候选方案
- 通过视觉比较选择最接近目标的编辑
- 支持迭代式优化过程
客观评估指标
- 光度损失(Photometric Loss):测量渲染图像的像素级差异
- CLIP得分:评估语义层面的视觉相似性
- Chamfer距离:量化3D几何结构的差异
实验结果与发现
1. 人机性能差距巨大

实验结果显示,即使是最先进的VLM系统,与普通Blender用户相比仍存在显著差距:
- 人类用户在所有任务上都明显优于AI系统
- 即使限制人类用户的编辑时间为8分钟(与VLM相当),性能差距依然明显
- 这表明3D图形编辑对AI来说仍是一个未解决的挑战
2. 模型性能分析
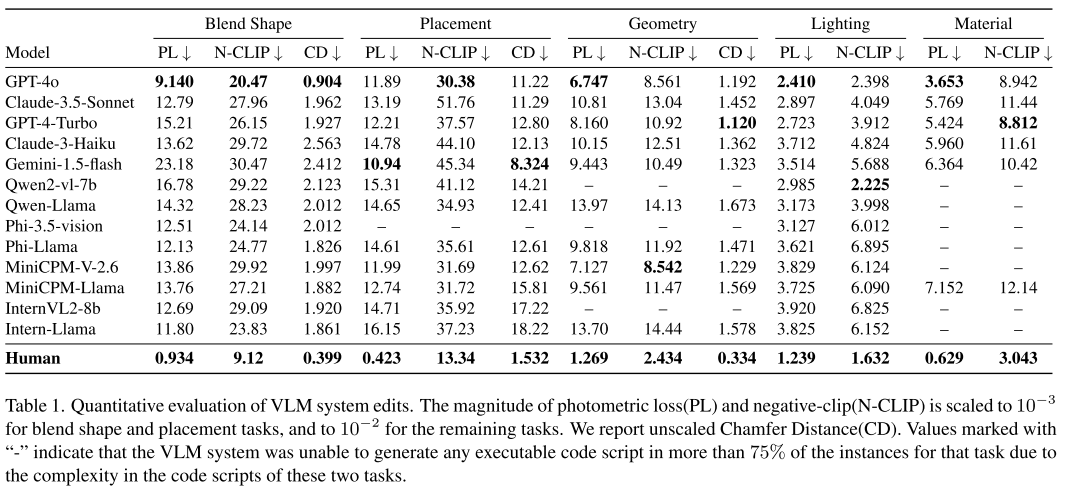
研究团队评估了13个主流VLM模型,包括:
- 闭源模型:GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Flash等
- 开源模型:InternVL2-8B、Qwen2-VL-7B等
关键发现:
- GPT-4o在大多数任务上表现最佳
- 开源模型在复杂的程序化编辑任务上表现不佳
- 超过75%的开源模型无法完成几何编辑任务
3. 生成器失败模式分析
研究发现VLM生成器的三大失败模式:
无法捕捉细微视觉差异
- 模型有时难以检测起始和目标场景间的关键差异
- 这直接影响后续的编辑质量
无法生成可执行代码
- 特别在程序化材质和几何编辑中表现不佳
- 需要复杂的着色器和几何节点连接操作
代码修改与视觉差异不匹配
- 即使代码能执行,也可能无法反映预期的视觉变化
- 在复杂脚本(80+行代码)中尤其常见
4. 验证器对齐度研究
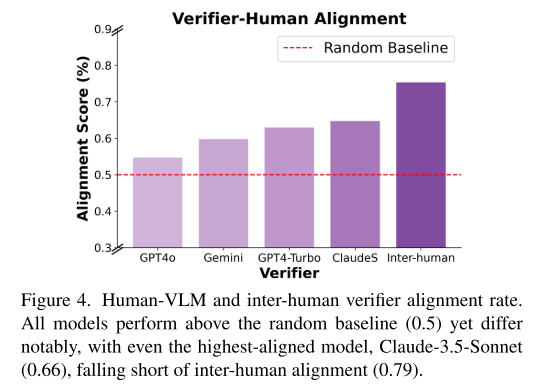
通过收集7,950个配对判断,研究团队发现:
- 人类验证器间的对齐度达到79%
- 最好的VLM验证器(Claude 3.5 Sonnet)对齐度仅为66%
- 这表明验证器仍有很大改进空间
推理时间缩放的重要发现
验证器也能从缩放中受益
传统观点认为只有生成过程能从推理时间缩放中获益。BlenderGym的研究却发现:
- 验证器缩放效果显著:通过增加验证查询次数,选择的编辑质量持续提升
- 开源模型逆袭:缩放后的开源验证器(如InternVL2-8B)可超越未缩放的闭源模型
- 闭源模型同样受益:GPT-4o和Claude 3.5 Sonnet的验证性能也随缩放提升
计算资源分配策略
研究揭示了一个重要规律:计算资源在生成和验证间的最优分配比例随总预算变化
低预算场景(< 30查询)
- 生成多样化候选更重要
- 验证比例应保持较低(约33%)
高预算场景(> 100查询)
- 验证的边际效益更高
- 验证比例应提升至73%
背后的直觉
- 预算有限时,关键是产生足够多的候选方案
- 预算充足时,从优质候选中精选更有价值
这一发现对"deliberative compute"(深思熟虑式计算)概念提供了重要支撑,表明智能系统的改进需要从单纯的生成能力转向"提出-验证-改进"的迭代工作流程。
技术实现细节
多视角渲染策略
为避免遮挡偏见,BlenderGym采用了精心设计的相机视角选择:
- 每个场景至少包含三个渲染视角
- 至少一个"综合视角"展现大部分物体
- 所有物体至少被一个视角完整捕获
人类基线设置
- 招募10名普通Blender用户
- 限制编辑时间为8分钟(与VLM相当)
- 完成约20%的总任务实例
- 使用相同指标评估人类表现
代码执行环境
- 基于Blender Python API
- 集成Infinigen程序化生成库
- 支持复杂的节点编辑操作
- 提供丰富的预定义函数
局限性与未来方向
当前局限性
- 覆盖范围:尚未涵盖物体雕刻、相机调整、动画创建等任务
- 规模限制:245个实例的规模仍有扩展空间
- 人类基线:参与的人类标注者数量有限
未来改进方向
- 任务扩展:增加更多图形编辑任务类型和实例数量
- 验证器优化:探索更先进的验证器架构和训练方法
- 缩放策略:研究更复杂的计算分配和缩放策略
社会影响考量
论文也深思了自动化3D图形编辑的社会影响:
- 可能减少创意工作者的就业机会
- 需要谨慎平衡技术进步与人类创造力价值
- 应优先考虑辅助而非替代人类创作者
结论与展望
BlenderGym不仅是一个基准测试工具,更是3D图形编辑AI研究的重要里程碑。它的贡献体现在:
学术价值
- 提供了首个标准化的3D图形编辑评估基准
- 揭示了当前AI系统的局限性和改进方向
- 证明了推理时间缩放在验证器中的有效性
实用意义
- 为图形编辑工具开发者提供客观评估标准
- 指导AI系统在创意产业中的应用方向
- 为计算资源优化提供理论指导
未来影响
BlenderGym的成功可能催生更多专业领域的AI基准测试,推动人工智能从通用能力向专业技能的深度发展。随着VLM技术的持续改进,我们有理由期待未来的AI系统能够成为图形设计师的得力助手,降低创作门槛,释放更多创造力。
在人工智能快速发展的时代,BlenderGym这样的研究为我们提供了重要启示:真正有价值的AI发展不是简单的性能提升,而是在理解人类需求基础上的精准突破。通过系统化的评估和持续的优化,我们正逐步接近AI与人类创造力完美融合的未来。