随着数据需求的不断增加,大数据架构的演变成为了现代数据工程师的重要课题。本文将对比传统大数据架构与新一代云原生湖仓 Databend,通过对比它们在实时与离线架构中的区别,感受 Databend 的优势。
传统大数据业务架构
传统的大数据平台通常由一套复杂的 Hadoop 方案组成,涉及多个组件,每个组件都有明确的任务分工。下图展示了一个典型的中小型大数据平台的架构:
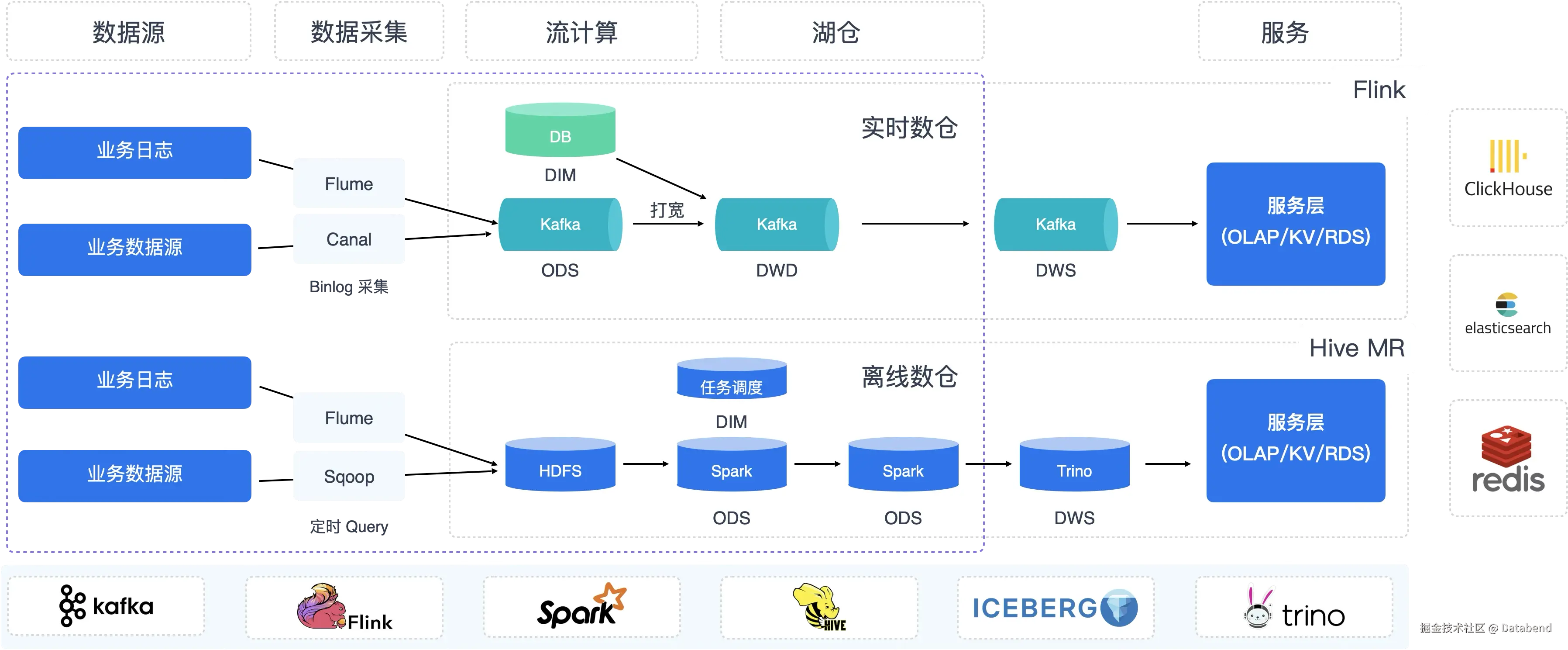
该架构看似完美,但实际操作中存在以下问题:
这个平台目前面临的问题:
实时数仓:
-
平台搭建耗时较长,通常需要超过一天,平台基本搭建需要按周规划。
-
组件繁多,运维挑战大,例如 Kafka 的高可用性和数据一致性等问题。
-
复杂的 Flink 任务处理数据打宽。
-
平台资深人员需要担负起较多的运维工作。
离线数仓:
-
数据写入通常为小时级或天级。
-
需要大量定期任务(小时级、天级)。
-
Hive 的 Catalog 易成为瓶颈,表数量和分区数据量大时管理困难。
-
数据无法去重,数据写入出错修订成本高
-
平台资深人员需要担负起较多的运维工作。
此外,同一份数据被多个路径消费,存在数据冗余,且缺少统一的权限管理服务。涉及的技术栈包括 Flume、Canal、Sqoop、Flink、Hive、Presto/Trino、HDFS、Kafka、Hadoop Yarn、Hive Catalog 等,运维复杂度极高。从业务上讲两套平台很多数据指标经常对不齐,也给使用带来困扰。
| Hadoop 生态 | 用处 | ||
|---|---|---|---|
| 数据接入层 | FlumeCanalSqoop | 任务型的组件,不用处理高可用 | |
| 计算层 | FinkSparkHivePresto | TrinoPI | 这层需要考资源调度能力,需要考虑高可用 |
| 存储层 | HDFSKafka | 需要考虑有状态的高可用,磁盘故障处理就非常麻烦。 | |
| 资源调度层 | Hadoop YarnSQL 任务调度平台 | Hadoop 平台标准的资源调度组件 | |
| 元数据服务 | Hive Catalog (MysQL)Zookeeper | 上了 Hive 基本就是 Hive Catalog,也就意味着低效 | |
| 权限管理 | Ranger | 需要再引入 Ranger 来处理 |
其实这些还不够,真正要把这个平台运行起来,应该会用到 Redis 等其它开源组件,这也是为什么当年大数据工程师可以年薪 40-80万,这个平台确实太复杂,单单能把这个平台搭建运行起来 1 天也搞不定,往往需要按周来规划,平台出点问题基本就是各种慌,非常无力,需要有资深的 Java 源码能力的工程师来 Hold 这个平台功能开发及稳定性。 而这平台花时间最多就是数据的迁移,任务的调度,这里基本上还有一个任务调度平台。
那么有没有更加简单的方案呢? 目前这块也是云厂商在做的工作。
目前每家云厂商都提供了一站式的打包方案的 EMR + DataWorks 让数据工作者更加容易,但传统的架构搬到云上带来的效果就是成本突增,预留实例模式,总是因为业务高峰资源不够,被诱导扩容 ,让人只能远观。
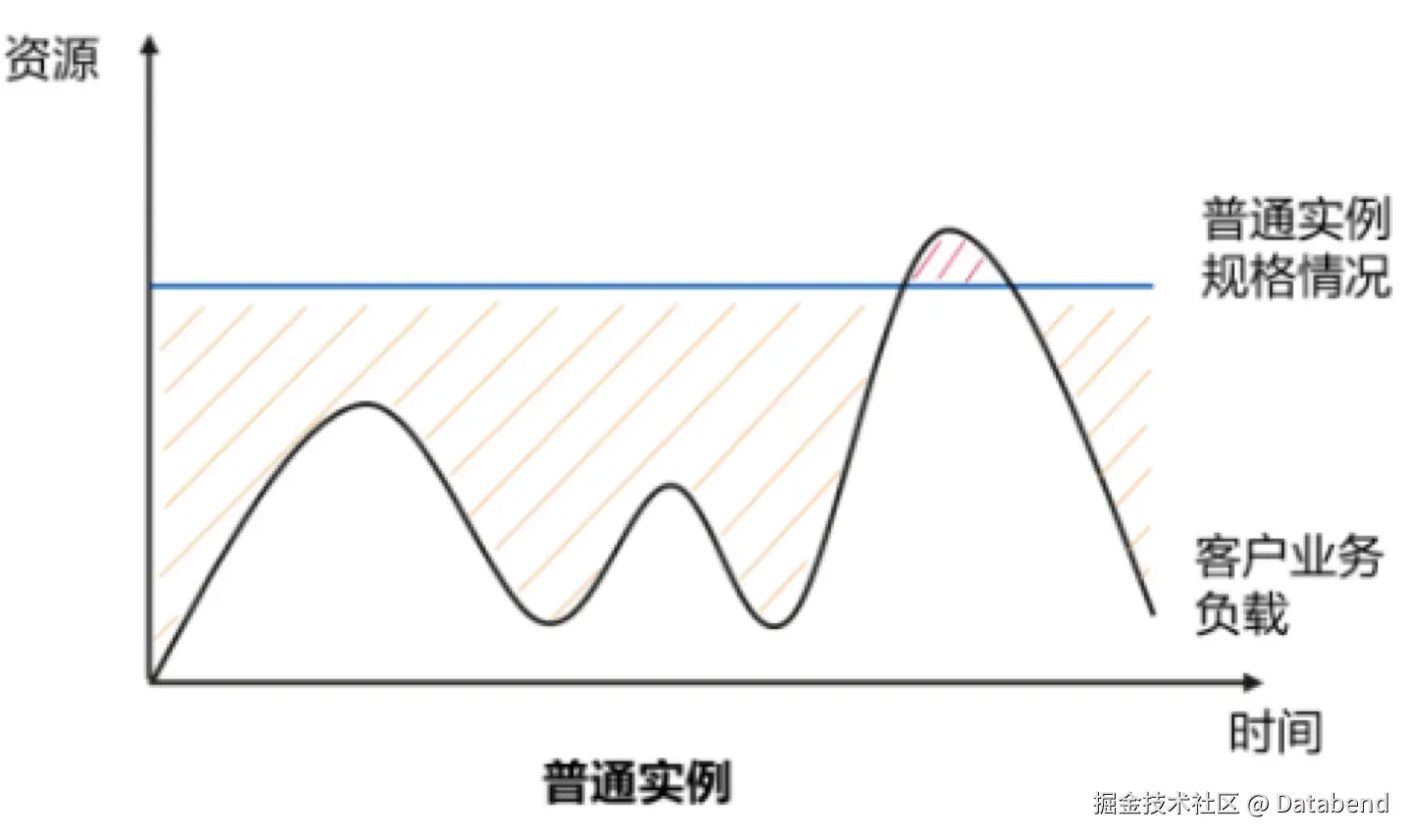
基于物理机部署的架构很容易出现高峰期资源不够,低峰期大量资源闲置的现象。用户往往需要按着高峰期的配置来采购资源。要不就面临高峰期资源紧张的问题。
基于 Databend 的大数据业务架构
Databend 基于 Rust 开发,强调 Serverless 架构,支持按需付费和计算层的弹性伸缩,使得用户能在高峰期按需扩展资源,低峰期降低成本,实现大数据架构的最大化效能。Databend 整体的架构:
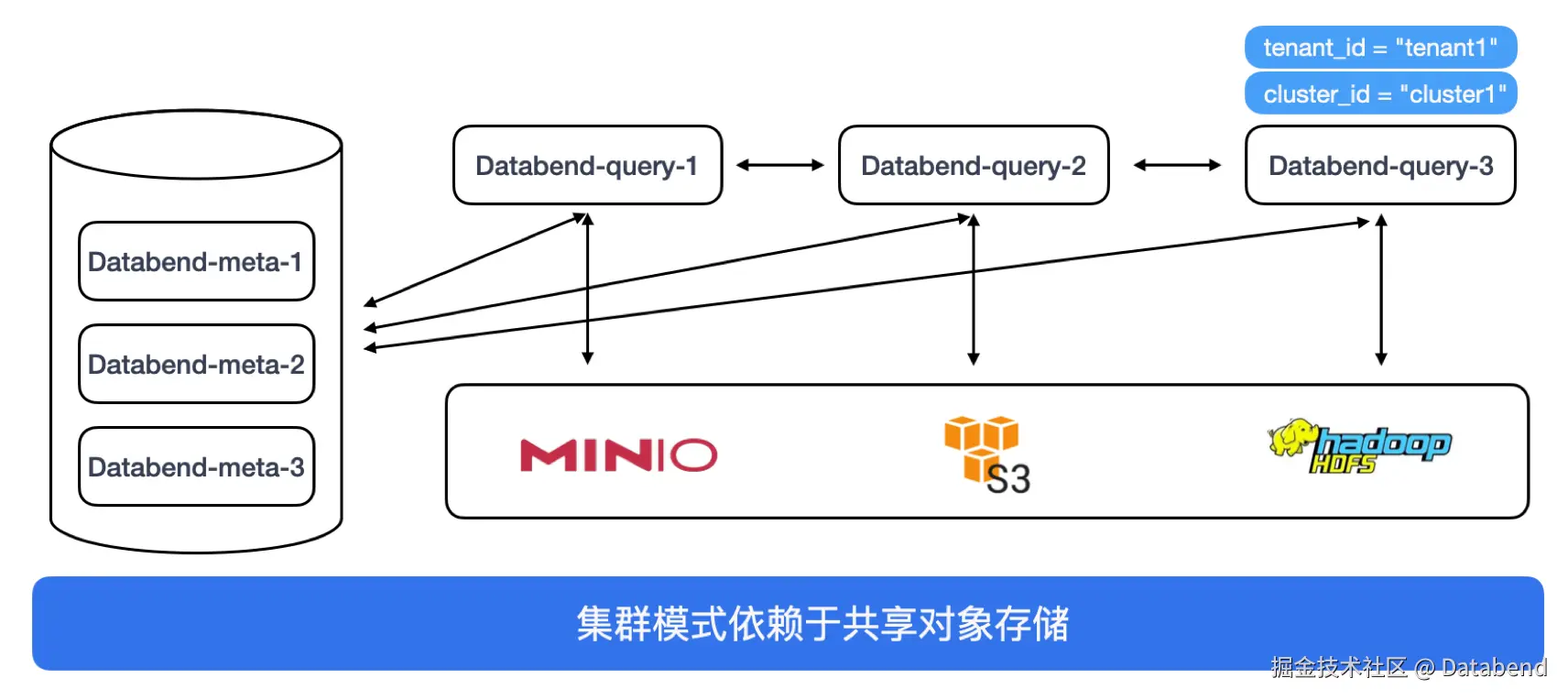
在 Databend 的业务架构设计中, 大简化架构:
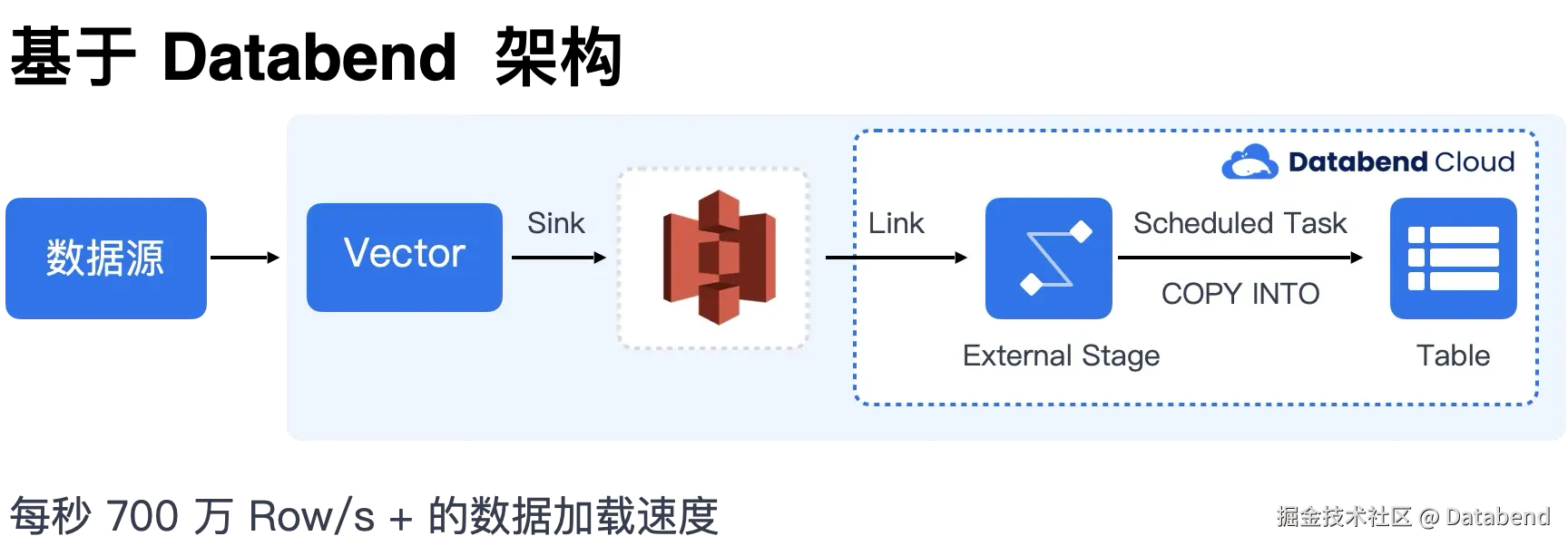
在 Databend 中你只需要关注于 SQL ,实现一份数据可以供多个 WH 同时使用。
| Databend 生态 | 用处 | |
|---|---|---|
| 数据接入层 | VectorFink-cdc | 任务型的组件 |
| 计算层 | Databend | |
| 存储层 | 对象存储 S3 | |
| 资源调度层 | 基于 WH 方案 | Databend 中 SQL 可以在一个集群进行分布式运算,一个租户下面支持多个集群,共享同一份数据 |
| 元数据服务 | Databend | |
| 权限管理 | Databend | 丰富的权限管理,不同的用户连接到集群上看到的数据不一样的 |
Databend 是基于 Rust 开发的 Serverless 数据处理平台 Databend Cloud,可以实现
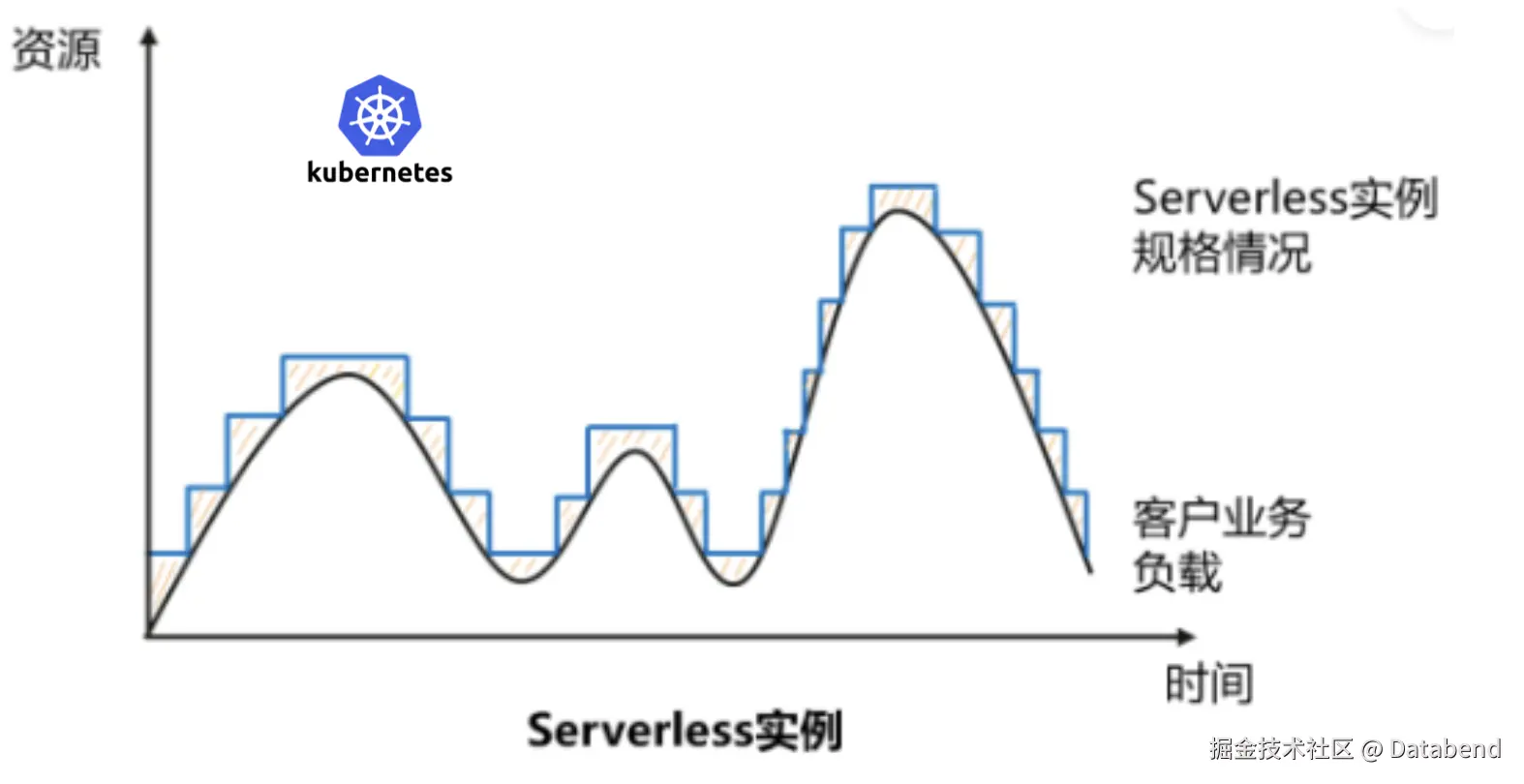
在 Databend Serverless 架构下,可以让用户实现按需付费,甚至不使用是可以休眠 WH ,实现计算层 0 付费。计算层可以借助于 k8s 的弹性伸缩实现计算层按需付费。 也就是说,基于 Databend 的大数据架构中,可以实现计算,存储都可以按需付费。在该架下,在公有云上可以实现按需付费,在私有化中可以结合业务的潮汐效应灵活的组织一个资源池。
传统大数据架构和 Databend 业务架构的对比
| 传统大数据业务架构 | Databend | 对比 | ||
|---|---|---|---|---|
| 数据接入 | FlumeCanalSqoopFink-cdc | VectorFink-cdc* * *Databend 可以直接读取 csv, ndjson , parquet, orc 类文件 | 这块其实区别不大,只是 Vector 相对轻量一点, Fink-cdc 现在用的更多一点。 | |
| 计算层 | FinkHivePresto | Trino | Databend内置 SQL 接口的计算引擎 | 从产品整体上规划, Databend 是一个完善的产品。 |
| 存储层 | HDFSS3 | S3有限支持 HDFS | 把存储分层到一个独立的产品,多 IDC 容灾只需要考虑存储的可用性即可。 | |
| 存储引擎 | 按目录方式进行分区 | Databend Data Fuse Engine | Databend 放弃了分区声明,减化用户的操作, 数据访问裁剪可以到文件级中坚力量 | |
| 是否依赖 kafka | 是依赖非常重,Kafka 是传统大数据中流式计算中中间存储 | 否 | Databend 可以利用 s3 替换了 kafka 简化应用 | |
| 资源调度层 | Hadoop Yarn | 内置- 按业务拆分集群 |
- 同集群内划分 Resource Group | | | SQL 任务管理 | 需要 | 不是必须Databend 中内置 Task 管理, 可以使用部的数据任务管理系统集成 | | | 元数据服务 | Hive Catalog (MysQL) | 自带 databend-meta 元数据服务轻松支持单租户几十万级到百万级别的表 | | | 依赖 Zookeeper | 是 | 否 | | | 内置权限管理 | 无 | 是 | Databend 有非常完善的权限管理传统大数据需要借助第三方实现权限管理 | | 环境搭建 | 需要大量的组件及部署 | 只有Databend-metadatabend-query基本可以实现分钟级部署 | Databend 的环境搭建非常轻构,进程是二进制的也没软件依赖问题。 | | 分区表 | 支持 | Databend 使用分区隐藏技术,使用中无需关注表的分区设计 | | | Sechma | 非严格约束 | 严格约束 | | | Time Travel | 无 | 支持 | | | 流计算 | Flink 实时Spark 批流一体 | 内置 Stream 可以实现批流一体 | 基于 Databend 可以大大简化流计算的设计,让应用开发更加简单。 | | 表级CDC | 无 | 支持 | 支持表级的增量订阅 | | 去重 | 全量 | 支持增量数据去重 | | | delete/update | 不支持 | 支持 | |
通过对比可以看出,Databend 在简化架构、降低运维复杂度和实现弹性按需付费方面显示出明显优势,未来或将成为大数据处理平台的重要选择。
Databend 基本性能测试
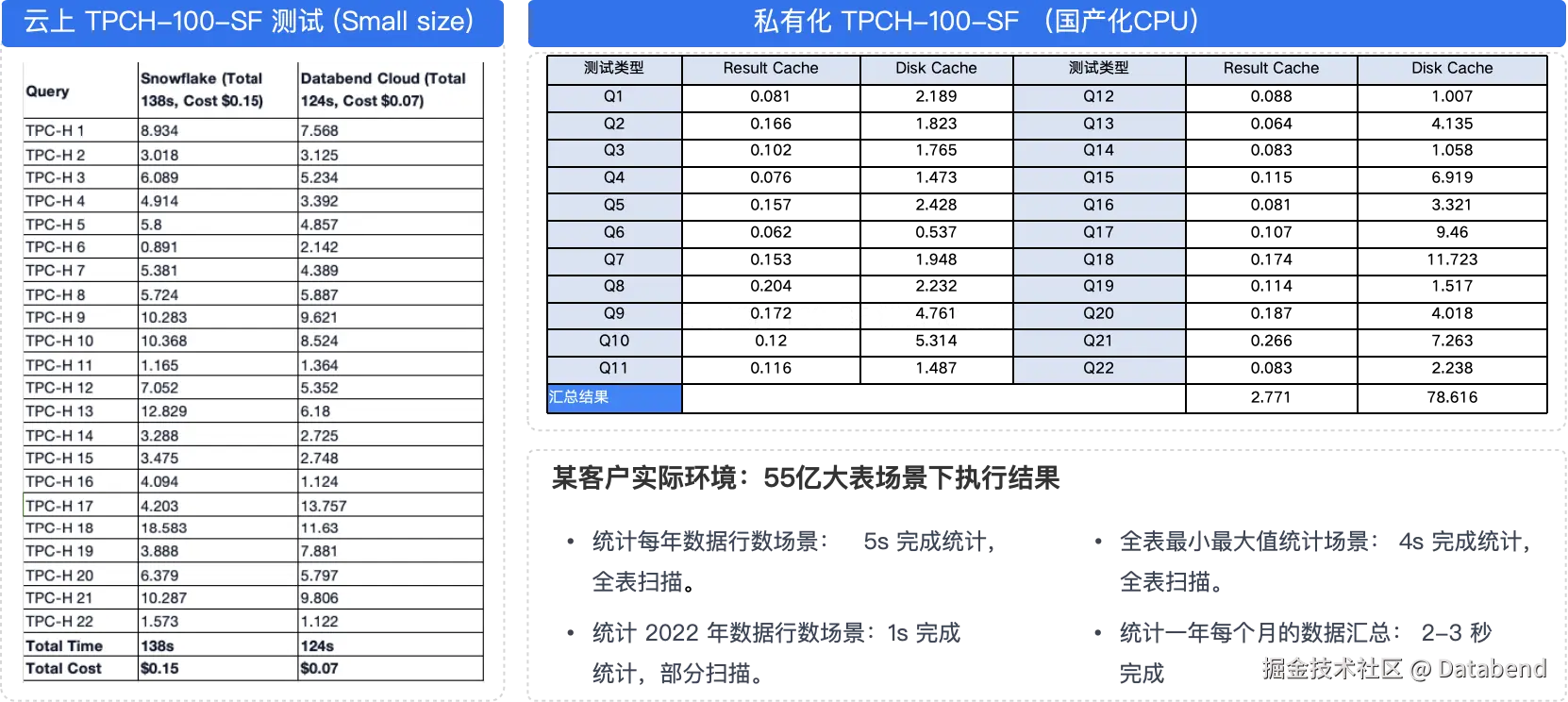
某省级大数据交易集团从传统大数据湖仓方案到 Databend 转型
大数据交易所原来使用传统大数据 Hadoop( HDFS, Hive, Hbase ) , Spark, S3, OLAP 产品等,构建了一个多产品解决方案。基础架构部分设计到的维护到的组件: HDFS, Hadoop Common, Hadoop Yarn, Hadoop MR, Hive. Hbase, Yarn, Spark, Zookeeper, Kafka, Apache Ranger, OLAP 产品,每个产品可能又包含 3-5 个组件,平台复杂非常高。 平台困境:
-
平台大量的数据同步任务,每天数据同步任务过 30万+
- 大量同步任务,经常因为异常停止,造成数据同步容易出现数据不一致
- 需要用的核心表比较多,数据稽核压力比较大,稽核的资源经常无法满足平台需求
- 多平台间数据同步任务占用了平台大量的资源,数据同步占用将近 30 台机器
-
平台上可用产品比较多,经常出现选择不合理的现象,造成工程返工,重构
-
Hbase, Hive 都是 Schema 非严格约束,出现大量数据在入湖后本身就是错误,但无法溯源问题
-
Hive 和裁剪是分区级的,分区不合理或是没有分区的情况下任意的查询都是全表扫描,只用于跑批环境,不能用于 Adhoc 查询
-
Hbase 只能基于 key 的请求,对于业务开发周期比较长,无法支撑业务的快速开发
-
引入 OLAP 产品,希望直接在 OLAP 中对外服务,但发现大数据下数据量是海量的增长,OLAP 副本集的机制存储成本非常昂贵。 数据增长已经超越了 OLAP 承载能力。
-
平台运维复杂,很多产品更改一个参数需要大量的重启,坏一块盘的修复成本都是天级的人员投入,平台中某些产品扩容几乎是需要惊动所有平台。
从传统大数据到 Databend 后的收益
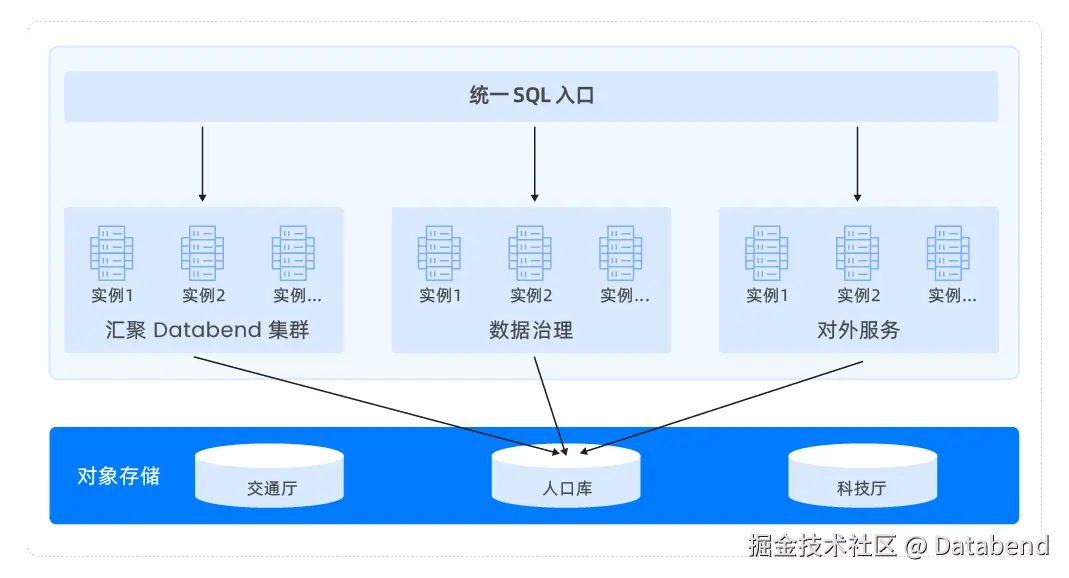
基于 Databend 构建的湖建的湖仓方案,实现了 Databend 统一 SQL 入口,实现了:
- 实现一份数据多业务集群同时访问,隔离计算的同时减少数据搬家
- 同时 Databend 针对大数据交易所各生态厅多租户物理隔离问题定开发了内置数集市场,从根本上实现一份数据可以在多个租户间共享
- 利用混闪的对象存储替代每台机器上的本地盘,实现存储分离后,可以针对存储和计算独立扩容,解决原来存储比空间要求比较大问题。另外磁盘故障更换对外无感知
- 平台基础运维从原来多个产品,多个组件(大于 50) 的情况 到只有一个 Databend 产品,只有两个进程( databend-meta , databend-query) , 可以实现分钟级的平台计算资源扩容及收缩
- 平台升级都可以秒级完成,对外基本无感知,大大提高了平台的稳定性
- 数据入环节,借助于 Databend 在公有云上打磨的方案,利用对象存储替换 Kafka 做暂存区, 减化外部 ETL 到内部 ELT 大减化数据接入能力。
- 利用 Databend 同一业务多集群架构实现湖仓平台直接对外服务,从根本上解决数据搬家
- 借助于 Databend 云原生及存储分离的理念实现对资源的更加有效的管控,精细扩容及管理。
- 借助于 Databend 利用 Rust 研发,内存安全,完美的跑在各种信创 Linux 及 Arm CPU 下面。
基于 Databend 架构实现湖仓一体化,大大简化数据接入及使用,原来的周级任务排布到现在的基本 30 分钟左右可以实现一个业务的上线及对外服务。在省级数据只采一次项目中,实现 1 个月从 0 到 1 的省级民生项目建设。
如何从 Databend 开始
如果你现在已经在使用到云上的对象存储或是你私有化环境中已经有对象存储或是 HDFS ,那么恭喜你,你已经具备了开始使用 Databend 的好的开始了。接下来我们可以看看人一个最小的场景开始:
如果你这边也有数据或是大量的数据会写先入对象存储(S3) 后续供各个数据平台使用。
这就是一个非常好的 Databend 使用场景,可以使用 Databend 在对象存储上高压缩能力,降低 S3 的存储成本,同时可以利用 Databend 的 SQL 接口能力,实现更加简单的数据推送和访问。
在这个场景 Databend 可以帮着用户实现存储成本下降 50% 以上,同时效率成本可以提升 90%+。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab...