Sqoop 查询
使用sqoop列出mysql中数据库database
sql
sqoop list-databases
--connect jdbc:mysql://192.168.249.130:3306
--username root
--password Mzp_2022!如果出现下面这个报错,说明mysql的jdbc没有配置好
这个包放到这个位置
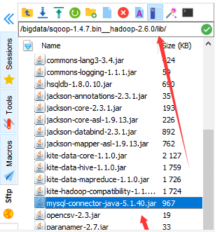
这实际是sqoop连接不上MySQL了
JDBC = Java Database Connectivity ,翻译过来是:Java 数据库连接技术
✅ 大白话解释:JDBC 是一套Java 语言写的「通用接口 / 工具包」 ,作用是:让 Java 程序,能连接上各种数据库(MySQL/Oracle 等),并且对数据库执行增删改查 SQL 语句
正常是这样的
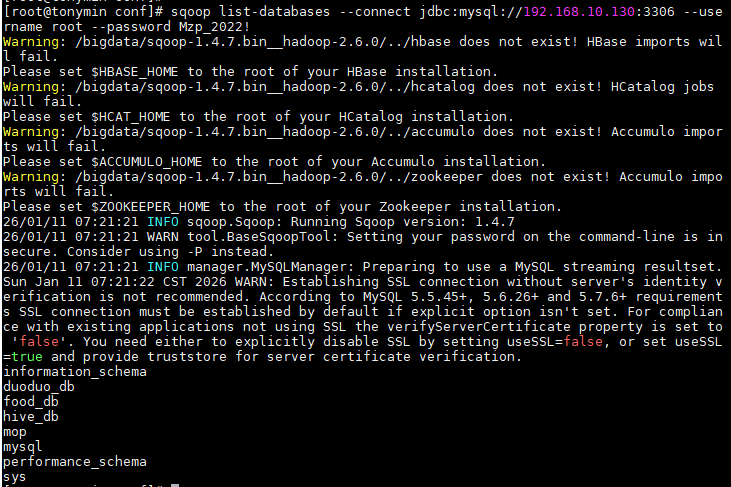
使用sqoop列出mysql中指定数据库duoduo_db中的所有表
/database的名字
sql
-- 使用sqoop列出mysql中指定数据库duoduo_db中的所有表
sqoop list-tables
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db
--username root
--password Mzp_2022!
sqoop list-tables --connect jdbc:mysql://192.168.249.130:3306/database的名字 --username root --password Mzp_2022!MySQL迁移到HDFS
从mysql数据库duoduo_db中导出表base_category1到HDFS平台/bi2513/category1
sqoop import
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db
--username root
--password Mzp_2022!
--table base_category1
-m 1
--target-dir /bi2513/category1
--delete-target-dir
--driver com.mysql.jdbc.Driver
sqoop import------把 MySQL 数据库里的表数据,导入到 HDFS 中
--username root --password Mzp_2022! ------用账号root、密码Mzp_2022! 访问duoduo_db数据库
--table base_category1 ------访问duoduo_db数据库,将该库下的base_category1表的全部数据
-m 1 ------用1 个 Map 任务
--target-dir /bi2513/category1 ------导入到 HDFS 的/bi2513/category1目录下
--delete-target-dir------
执行这条 Sqoop 导入命令之前,自动检测 HDFS 上的目标目录/bi2513/category1 是否存在:
✅ 如果存在 → 自动删除这个目录(包括目录下所有文件),然后再重新创建该目录,执行数据导入;
✅ 如果不存在 → 什么都不做,直接创建目录,执行数据导入。
--driver com.mysql.jdbc.Driver------指定使用 MySQL 的 JDBC 驱动类完成连接
从MySQL取数据中插入特定要求的 行 到hdfs中
结尾加query
sql
sqoop import \
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db \
--username root \
--password Mzp_2022! \
--target-dir /user/category3 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'SELECT * FROM base_category3 WHERE id<=100 and $CONDITIONS;'
sql
sqoop import \
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db \
--username root \
--password Mzp_2022! \
--target-dir /user/category3 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query "SELECT * FROM base_category3 WHERE NAME LIKE '%机%' and \$CONDITIONS;"提示:query的结尾必须加'CONDITIONS', must contain 'CONDITIONS' in WHERE clause.
如果query后使用的是双引号,则$CONDITIONS前必须加转义符,防止shell识别为自己的变量。
但是你一定要注意**--query** 不可 与 -- table 同用。 --query是调用符合条件的部分数据。--table是整个表导入进去。
加where 列=条件
sql
sqoop import \
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db \
--username root \
--password Mzp_2022! \
--target-dir /user/category3 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query "SELECT * FROM base_category3 WHERE NAME LIKE '%机%' and \$CONDITIONS;"
或:
sqoop import \
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db \
--username root \
--password Mzp_2022! \
--target-dir /user/category3 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table base_category3 \
--where "id=10"迁移特定的列
方法1
sql
sqoop import \
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db \
--username root \
--password Mzp_2022! \
--target-dir /user/category3 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,name \
--table base_category3-- 方法2
sql
sqoop import \
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db \
--username root \
--password Mzp_2022! \
--target-dir /user/category3 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'SELECT id,name FROM base_category3 WHERE id<=100 and $CONDITIONS;'HDFS迁移到MySQL
在Sqoop中,"导出"概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群(RDBMS)中传输数据,叫做:导出,即使用export关键字。HIVE/HDFS到RDBMS
sqoop export \
--connect jdbc:mysql://192.168.249.130:3306/duoduo_db \
--username root \
--password Mzp_2022! \
--table student \
--num-mappers 1 \
--export-dir /user/hive/warehouse/ping_bank.db/student6 \
--input-fields-terminated-by "\001
一次性同步所有的表到hdfs
冗长版
#!/bin/bash
通过 Shell 脚本,实现「不传参就全量导入 MySQL 的 duoduo_db 所有表到 HDFS」、「传表名就只导入指定单张表」
定义sqoop的绝对路径
sqoop=/bigdata/sqoop-1.4.7.bin__hadoop-2.6.0/bin/sqoop
#定义一个变量t_name,默认值为all表示导入所有的表;
t_name="all"
判断是否传入了表名参数
[[ -n "$1" ]] :这是判断条件,$1 是 Shell 的位置参数 ,代表「执行脚本时传入的第 1 个参数」;-n 代表「判断字符串是否不为空」;整句话意思:判断执行脚本时是否传入了第 1 个参数 。
if \[ -n "$1" ]; then
t_name=$1
fi
#脚本默认导入所有表(t_name不做修改,还是原来的all),如果执行脚本时传了表名参数,就只导入你传入的这个表名(如果你写的是all,那就是all,否则取你输入的那个表名)。
====================== 定义核心导入公用函数 ======================
import_data(){
sqoop import \\
--connect jdbc:mysql://192.168.229.136:3306/duoduo_db \\
--username root \\
--password Mzp_2022! \\
--table 1 \
-m 1 \
--target-dir /hive-duoduo-db/$1 \
--delete-target-dir \
--driver com.mysql.jdbc.Driver \
--null-string '\\N' \
--null-non-string '\\N'
}
====================== 定义各表的导入函数 ======================
打印。
#-e 是让 echo 支持颜色和转义字符,必须加;
# \033[32m 是「绿色字体的开始标记」,\033[0m 是「恢复默认字体的标记」;
在控制台用绿色字体打印「正在导入表数据:activity_info」,让你能清晰看到脚本执行到哪一步了。
函数import_data 输入参数activity_info,完成了sqoop数据迁移的行为
shell的函数不同于python,不是这个形式"函数名(参数)",而是"函数名 参数"
import_activity_info(){
echo -e '\033[32m正在导入表数据:activity_info\033[0m'
import_data activity_info
}
import_activity_order(){
echo -e '\033[32m正在导入表数据:activity_order\033[0m'
import_data activity_order
}
import_activity_rule(){
echo -e '\033[32m正在导入表数据:activity_rule\033[0m'
import_data activity_rule
}
import_activity_sku(){
echo -e '\033[32m正在导入表数据:activity_sku\033[0m'
import_data activity_sku
}
import_base_category1(){
echo -e '\033[32m正在导入表数据:base_category1\033[0m'
import_data base_category1
}
import_base_category2(){
echo -e '\033[32m正在导入表数据:base_category2\033[0m'
import_data base_category2
}
import_base_category3(){
echo -e '\033[32m正在导入表数据:base_category3\033[0m'
import_data base_category3
}
import_base_dic(){
echo -e '\033[32m正在导入表数据:base_dic\033[0m'
import_data base_dic
}
import_base_province(){
echo -e '\033[32m正在导入表数据:base_province\033[0m'
import_data base_province
}
import_base_region(){
echo -e '\033[32m正在导入表数据:base_region\033[0m'
import_data base_region
}
import_base_trademark(){
echo -e '\033[32m正在导入表数据:base_trademark\033[0m'
import_data base_trademark
}
import_cart_info(){
echo -e '\033[32m正在导入表数据:cart_info\033[0m'
import_data cart_info
}
import_comment_info(){
echo -e '\033[32m正在导入表数据:comment_info\033[0m'
import_data comment_info
}
import_coupon_info(){
echo -e '\033[32m正在导入表数据:coupon_info\033[0m'
import_data coupon_info
}
import_coupon_use(){
echo -e '\033[32m正在导入表数据:coupon_use\033[0m'
import_data coupon_use
}
import_date_info(){
echo -e '\033[32m正在导入表数据:date_info\033[0m'
import_data date_info
}
import_favor_info(){
echo -e '\033[32m正在导入表数据:favor_info\033[0m'
import_data favor_info
}
import_holiday_info(){
echo -e '\033[32m正在导入表数据:holiday_info\033[0m'
import_data holiday_info
}
import_holiday_year(){
echo -e '\033[32m正在导入表数据:holiday_year\033[0m'
import_data holiday_year
}
import_order_detail(){
echo -e '\033[32m正在导入表数据:order_detail\033[0m'
import_data order_detail
}
import_order_info(){
echo -e '\033[32m正在导入表数据:order_info\033[0m'
import_data order_info
}
import_order_refund_info(){
echo -e '\033[32m正在导入表数据:order_refund_info\033[0m'
import_data order_refund_info
}
import_order_status_log(){
echo -e '\033[32m正在导入表数据:order_status_log\033[0m'
import_data order_status_log
}
import_payment_info(){
echo -e '\033[32m正在导入表数据:payment_info\033[0m'
import_data payment_info
}
import_sku_info(){
echo -e '\033[32m正在导入表数据:sku_info\033[0m'
import_data sku_info
}
import_spu_info(){
echo -e '\033[32m正在导入表数据:spu_info\033[0m'
import_data spu_info
}
import_user_info(){
echo -e '\033[32m正在导入表数据:user_info\033[0m'
import_data user_info
}
====================== 补全所有case分支(原脚本核心缺失部分) ======================
#如果输入的参数不是all,而是一个具体的表名。就执行下面这些具体表名的函数。反之如果输入的参数是all,则会进入到运行所有函数的那个条件判断分支
case $t_name in
"activity_info")
import_activity_info
;;
"activity_order")
import_activity_order
;;
"activity_rule")
import_activity_rule
;;
"activity_sku")
import_activity_sku
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"base_dic")
import_base_dic
;;
"base_province")
import_base_province
;;
"base_region")
import_base_region
;;
"base_trademark")
import_base_trademark
;;
"cart_info")
import_cart_info
;;
"comment_info")
import_comment_info
;;
"coupon_info")
import_coupon_info
;;
"coupon_use")
import_coupon_use
;;
"date_info")
import_date_info
;;
"favor_info")
import_favor_info
;;
"holiday_info")
import_holiday_info
;;
"holiday_year")
import_holiday_year
;;
"order_detail")
import_order_detail
;;
"order_info")
import_order_info
;;
"order_refund_info")
import_order_refund_info
;;
"order_status_log")
import_order_status_log
;;
"payment_info")
import_payment_info
;;
"sku_info")
import_sku_info
;;
"spu_info")
import_spu_info
;;
"user_info")
import_user_info
;;
"all")
import_activity_info
import_activity_order
import_activity_rule
import_activity_sku
import_base_category1
import_base_category2
import_base_category3
import_base_dic
import_base_province
import_base_region
import_base_trademark
import_cart_info
import_comment_info
import_coupon_info
import_coupon_use
import_date_info
import_favor_info
import_holiday_info
import_holiday_year
import_order_detail
import_order_info
import_order_refund_info
import_order_status_log
import_payment_info
import_sku_info
import_spu_info
import_user_info
echo -e '\033[31m======= 所有表数据导入完成 =======\033[0m'
;;
*)
echo -e '\033[31m错误:输入的表名不存在,请检查表名是否正确!\033[0m'
exit 1
;;
esac
简化版
#!/bin/bash
sqoop=/bigdata/sqoop-1.4.7.bin__hadoop-2.6.0/bin/sqoop
数据库配置
DB_USER="root"
DB_PASS="Mzp_2022!"
DB_NAME="duoduo_db"
HDFS_DIR="/user/hadoop/data" # 指定HDFS中的存储路径
获取所有表名并逐一导入到HDFS
$(xxx) 是 Shell 的 命令替换语法,作用是:执行括号里的命令,把命令执行后的「输出结果」,作为值赋值给前面的变量。
这是一条 直接在 Linux 终端执行的 MySQL 客户端命令
-s :silent 静默模式,只返回纯文本结果,去掉 mysql 默认的表头、边框等多余格式;
-e :execute 执行,后面双引号里的内容是「要执行的 MySQL 语句」;
TABLES=(mysql -u DB_USER -pDB_PASS DB_NAME -se "SHOW TABLES;")
echo '同步开始。。。'
for TABLE in TABLES
do
sqoop import \
--connect jdbc:mysql://192.168.10.130:3306/DB_NAME \\
--username DB_USER \
--password DB_PASS \\
--table TABLE \
--target-dir HDFS_DIR/TABLE \
--m 1 \
--delete-target-dir \
--driver com.mysql.jdbc.Driver
done
echo '同步完成。。。'
连接错误
Caused by: java.net.ConnectException: 拒绝连接 (Connection refused)
遇到这种错误,就是连接的ip地址写错了,去检查。