ClickHouse 深度技术解读:列式存储与实时分析的高性能引擎
1. 整体介绍
1.1 项目概况
ClickHouse® 是一个开源的列式数据库管理系统(DBMS),专为在线分析处理(OLAP)场景设计。项目采用 Apache 2.0 许可证,由 ClickHouse, Inc.(原 ClickHouse, Inc.)主导开发与维护。根据其活跃的社区活动、月度发布节奏以及全球范围的用户组聚会判断,该项目拥有活跃的开发者社区和用户基础。
1.2 核心功能与解决的问题
ClickHouse 的核心是解决海量数据下的实时分析查询问题。传统行式数据库(如MySQL、PostgreSQL)在处理面向聚合、涉及大量数据扫描的分析查询时,会因不必要的列读取和较低的压缩效率面临I/O和计算瓶颈。
面临的挑战与对应场景:
- 挑战1:高吞吐聚合查询。在数据仓库、商业智能(BI)报表场景中,查询常常需要扫描数百万甚至数十亿行数据,但仅对少数几列进行求和、计数、分组等操作。
- 挑战2:低延迟实时分析。在监控、可观测性、实时推荐等场景,业务要求对持续流入的数据能在秒级甚至亚秒级内得到分析结果。
- 挑战3:海量数据存储成本。存储PB级数据需要高效的压缩算法来降低硬件成本。
- 对应人群:数据分析师、数据工程师、开发需要构建分析类应用的后端工程师、以及寻求高性能OLAP解决方案的架构师。
解决方案与优势: ClickHouse 采用了 列式存储 作为根本解决方案。
- 传统方式(行存):读取整行数据以获取少数几列,I/O效率低下,压缩率受限于行内数据类型的多样性。
- ClickHouse方式(列存) :
- I/O高效:查询仅需读取涉及的列数据,大幅减少磁盘I/O。
- 压缩率高:同列数据数据类型一致,便于使用专有算法(如LZ4, ZSTD, Delta编码)获得更高的压缩比。
- 向量化执行:利用现代CPU的SIMD指令集,对列式数据块进行批量操作,极大提升CPU缓存利用率和计算吞吐。
商业价值逻辑估算 : 其价值体现在替代传统MPP数据仓库或Hadoop/Spark组合方案所带来的成本下降 与效率提升。
- 代码/研发成本:作为开源软件,直接节省了数百万至数千万美元的数据库内核研发成本。
- 硬件成本:更高的压缩率和查询性能意味着可以用更少的服务器节点承载相同的业务负载,节省硬件与机房开销。
- 运维成本:简洁的架构(对比Hadoop生态)降低了运维复杂度。
- 业务效益:实时分析能力使得业务决策周期从"T+1"缩短到"秒级",加速产品迭代与市场响应,其产生的间接经济效益显著。
2. 详细功能拆解
从提供的代码片段可以窥见ClickHouse核心架构的两个关键层面:查询规划 与存储抽象。
2.1 查询规划与执行引擎(Planner.h)
Planner 类是将经过语法和语义分析后的查询树(QueryTreeNodePtr)转换为可执行的物理查询计划(QueryPlan)的核心组件。这是实现查询优化的关键环节。
- 产品视角:负责接收用户的SQL查询,并生成最高效的执行路径。这直接决定了查询性能。
- 技术视角 :实现了查询重写、基于规则的优化(RBO)、以及为后续的基于成本的优化(CBO)提供框架。
QueryNodeToPlanStepMapping结构支持高级特性如并行副本(parallel replicas)查询,这是实现横向扩展加速查询的关键。
2.2 统一的存储抽象层(IDisk.h)
IDisk 类是一个抽象接口,定义了所有存储媒介的通用操作(如读写文件、空间管理)。这是ClickHouse支持多存储后端(本地盘、S3、HDFS等)的基石。
- 产品视角:让用户和上层存储引擎(如MergeTree)无需关心数据具体存储在本地SSD、网络对象存储还是其他介质上,提供了存储策略的灵活性。
- 技术视角 :
- 抽象接口 :定义了
readFile,writeFile,getAvailableSpace等纯虚函数。 - 实现多态 :派生出
DiskLocal,DiskS3,DiskHDFS等具体实现。 - 高级功能支持 :接口中包含了零拷贝复制(
supportZeroCopyReplication)、对象存储集成(getObjectStorage)、加密文件处理等企业级功能所需的方法。createTransaction()方法暗示了其对复杂文件操作原子性的支持框架。
- 抽象接口 :定义了
2.3 数据库元数据管理(IDatabase.h)
IDatabase 类抽象了数据库引擎的行为,负责表生命周期管理(创建、删除、附着、分离)。
- 产品视角 :对应
CREATE DATABASE,ATTACH TABLE等SQL语句的后端实现。 - 技术视角 :
- 懒加载与异步启动 :
loadStoredObjects,loadTableFromMetadataAsync,startupTableAsync等方法揭示了ClickHouse支持异步加载和启动表元数据,这对于加速服务启动过程至关重要。 - 多引擎支持 :通过继承体系,支持
DatabaseOrdinary,DatabaseMemory,DatabaseReplicated等多种数据库引擎,适应不同一致性和持久化需求。 - 迭代器模式 :
IDatabaseTablesIterator提供了遍历数据库表的统一方式,并支持快照(DatabaseTablesSnapshotIterator)。
- 懒加载与异步启动 :
3. 技术难点挖掘
- 列存数据的随机更新与删除:列存天然适合追加写,但点更新和删除代价高。ClickHouse的MergeTree引擎通过"标记-合并"策略化解此难点。
- 高性能聚合计算:如何在压缩数据上直接计算,避免解压开销?ClickHouse使用了诸如在编码时预存聚合信息等技术。
- 分布式查询的协同 :在分片集群中,如何高效地进行
GROUP BY并排序?涉及全局排序、聚合下推、本地与远程查询规划等复杂问题。 - 查询优化器的复杂性 :从提供的
Planner看,其需要处理多种查询节点(QueryNode,UnionNode),并映射到物理算子树,同时考虑数据本地性、索引、采样等因素,设计难度大。 - 多级混合存储的透明化管理 :
IDisk抽象需要无缝整合本地NVMe、SSD、远程S3/HDFS,并可能涉及缓存分层,其一致性和性能调优是持续挑战。
4. 详细设计图
4.1 核心架构图
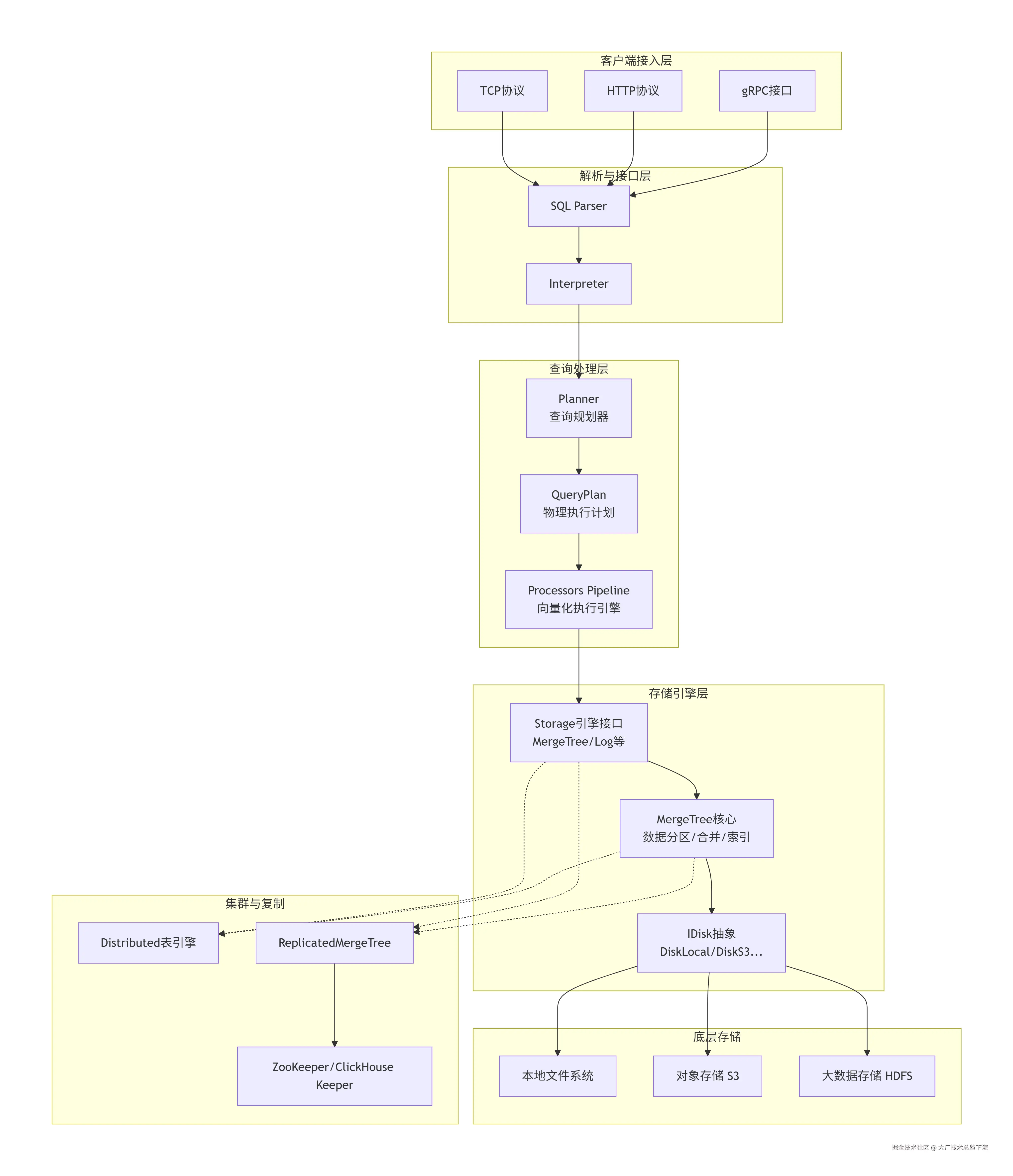
4.2 核心查询链路序列图(以 SELECT 查询为例)
4.3 核心类图(基于提供代码的简化视图)
注:Planner 与 IDisk、IDatabase 的协作通过 Storage 引擎和 Interpreter 间接进行,图中未展示全部关联。
5. 核心函数解析
5.1 Planner::buildQueryPlanIfNeeded() - 查询计划构建入口
这是查询优化的触发器。其核心职责是分析查询树,将其转换为由一系列物理算子(IQueryPlanStep)组成的执行计划。
cpp
// 伪代码逻辑,展示Planner的核心工作流
void Planner::buildQueryPlanIfNeeded() {
if (query_plan.isInitialized()) return; // 避免重复构建
switch (query_tree->getNodeType()) {
case QueryTreeNodeType::QUERY:
buildPlanForQueryNode(); // 处理SELECT查询
break;
case QueryTreeNodeType::UNION:
buildPlanForUnionNode(); // 处理UNION查询
break;
// ... 处理其他节点类型,如 TABLE, JOIN 等
}
// 构建过程中会填充 query_node_to_plan_step_mapping
// 这可能用于后续的运行时统计或并行化策略调整
}技术要点:
- 分治策略 :将复杂的查询树按类型分解为子问题(
QueryNode,UnionNode),分别优化。 - 映射关系 :维护
query_node_to_plan_step_mapping对于调试、性能分析和实现"读时写时复制"(Copy-on-Write)的并行查询至关重要。
5.2 IDisk::readFile() 与 DiskS3::readFile() - 存储抽象的关键实现
IDisk::readFile() 是一个纯虚函数,定义了读取文件的统一接口。其具体实现因存储后端而异。
IDisk 接口定义:
cpp
// 代码来源: src/Disks/IDisk.h (简化)
virtual std::unique_ptr<ReadBufferFromFileBase> readFile(
const String & path,
const ReadSettings & settings,
std::optional<size_t> read_hint = {}) const = 0;path: 文件在磁盘抽象层内的路径。settings: 包含IO调度、缓存、超时等高级控制参数。read_hint: 预读大小的提示,用于优化连续读取。
DiskS3 的简化实现逻辑:
cpp
// 伪代码,展示 DiskS3::readFile() 的可能实现
std::unique_ptr<ReadBufferFromFileBase> DiskS3::readFile(
const String & path, const ReadSettings & settings, std::optional<size_t>) const override
{
// 1. 将逻辑路径转换为S3对象键
String object_key = s3_root_path + path;
// 2. 创建并配置一个面向S3的ReadBuffer
// 它内部会调用 AWS SDK 的 GetObject 操作
auto buffer = std::make_unique<ReadBufferFromS3>(
s3_client,
bucket,
object_key,
settings
);
// 3. 可能附加缓存层(如本地SSD缓存)
if (settings.read_from_filesystem_cache_if_exists_otherwise_bypass_cache) {
buffer = wrapWithCache(std::move(buffer), cache_disk);
}
return buffer;
}技术要点:
- 桥接模式 :
IDisk接口作为抽象部分,DiskS3等作为实现部分,使上层存储引擎可以独立于具体存储后端演化。 - 缓冲与缓存 :返回的
ReadBufferFromFileBase对象负责管理数据缓冲。实现中可以灵活加入多层缓存(内存、本地文件系统),这对远程存储的性能至关重要。 - 设置传播 :
ReadSettings允许从查询层面到底层IO进行细致的性能调优控制。
5.3 IDatabase::getTablesIterator() - 元数据遍历的抽象
此函数是 SHOW TABLES 或数据库内部管理表的基础。
cpp
// 代码来源: src/Databases/IDatabase.h (简化)
virtual DatabaseTablesIteratorPtr getTablesIterator(
ContextPtr context,
const FilterByNameFunction & filter_by_table_name = {},
bool skip_not_loaded = false) const = 0;实现分析(以DatabaseOrdinary为例的伪代码):
cpp
DatabaseTablesIteratorPtr DatabaseOrdinary::getTablesIterator(
ContextPtr context,
const FilterByNameFunction & filter,
bool skip_not_loaded) const
{
// 1. 扫描元数据目录(如 /var/lib/clickhouse/metadata/db_name/)
std::vector<std::string> table_meta_files = disk->iterateDirectory(metadata_path);
// 2. 加载并过滤
Tables loaded_tables;
for (const auto & file : table_meta_files) {
String table_name = stripExtension(file);
if (filter && !filter(table_name)) continue;
// 3. 关键:可能触发表的懒加载
StoragePtr storage = tryGetTable(table_name, context);
if (!storage && skip_not_loaded) continue;
loaded_tables.emplace(table_name, storage); // storage可能为nullptr
}
// 4. 返回迭代器快照
return std::make_unique<DatabaseTablesSnapshotIterator>(std::move(loaded_tables), database_name);
}技术要点:
- 懒加载集成 :
tryGetTable调用可能触发从元数据文件(.sql)异步加载表结构。skip_not_loaded参数允许调用者决定是否等待加载完成。 - 迭代器模式:提供了一种统一、安全的方式来遍历可能动态变化的表集合。
- 快照隔离 :返回的
DatabaseTablesSnapshotIterator在构造时已固定表列表,避免了在迭代过程中因表被创建或删除而产生的竞态条件。
总结
ClickHouse 通过列式存储 这一根本设计,结合向量化执行引擎 和丰富的表引擎 ,系统性地解决了海量数据分析的性能瓶颈。其架构清晰,通过 Planner、IDisk、IDatabase 等核心抽象层,实现了查询优化、存储解耦和元数据管理的高度模块化。从代码中体现出的对异步操作、缓存、事务性文件操作的支持,反映出其在追求极致性能的同时,也兼顾了工程上的健壮性和扩展性。尽管在应对高频点更新等场景时仍有其设计取舍,但ClickHouse在OLAP领域,尤其是在需要实时查询吞吐量的场景下,无疑是一个经过深度优化且设计严谨的系统。