背景意义
在现代城市基础设施建设中,预制混凝土桩(PHC桩)作为一种重要的地基处理材料,广泛应用于各类建筑工程中。随着城市化进程的加快,对PHC桩的需求不断增加,如何高效、准确地进行PHC桩的实例分割与识别,成为了工程建设中亟待解决的问题。传统的人工检测方法不仅耗时耗力,而且容易受到人为因素的影响,导致检测结果的不准确性。因此,基于计算机视觉的自动化检测技术逐渐受到重视。
近年来,深度学习技术的快速发展为图像分割任务提供了新的解决方案。YOLO(You Only Look Once)系列模型因其高效的实时检测能力而广泛应用于实例分割领域。YOLOv11作为该系列的最新版本,结合了多种先进的技术,具备更强的特征提取能力和更高的检测精度。通过对YOLOv11模型的改进,能够更好地适应PHC桩的特征,提升实例分割的准确性和鲁棒性。
本研究旨在构建一个基于改进YOLOv11的PHC桩实例分割系统。该系统将利用包含5400张图像的专用数据集,进行PHC桩的自动识别与分割。数据集中仅包含一个类别------PHC桩,且经过精细的标注和多种数据增强处理,确保了模型训练的有效性与准确性。通过对该系统的研究与应用,不仅可以提高PHC桩的检测效率,还能为其他类似工程的自动化检测提供借鉴。
综上所述,基于改进YOLOv11的PHC桩实例分割系统的研究具有重要的理论意义和实际应用价值。它不仅推动了计算机视觉技术在土木工程领域的应用进程,也为未来的智能建筑与基础设施建设提供了新的思路与方法。
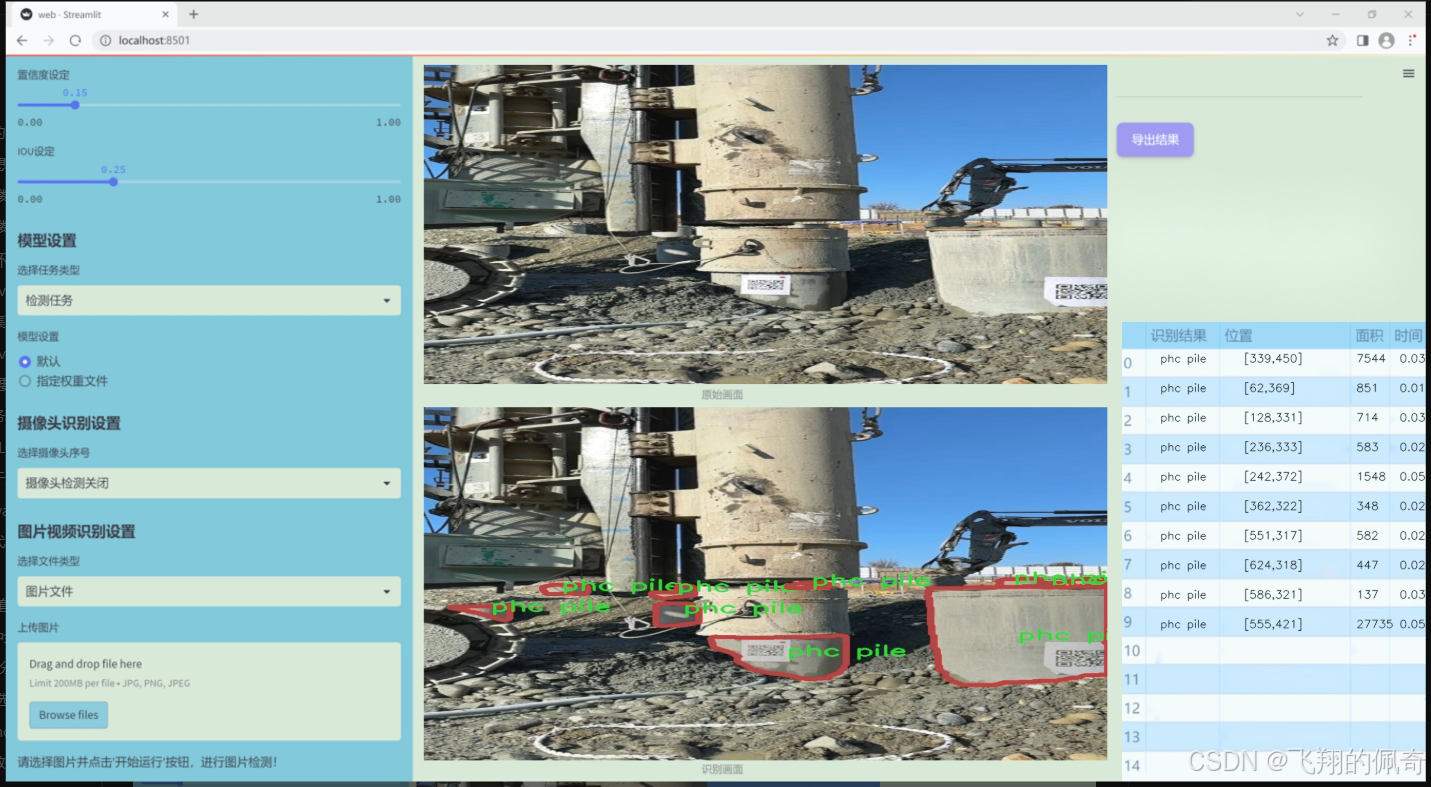
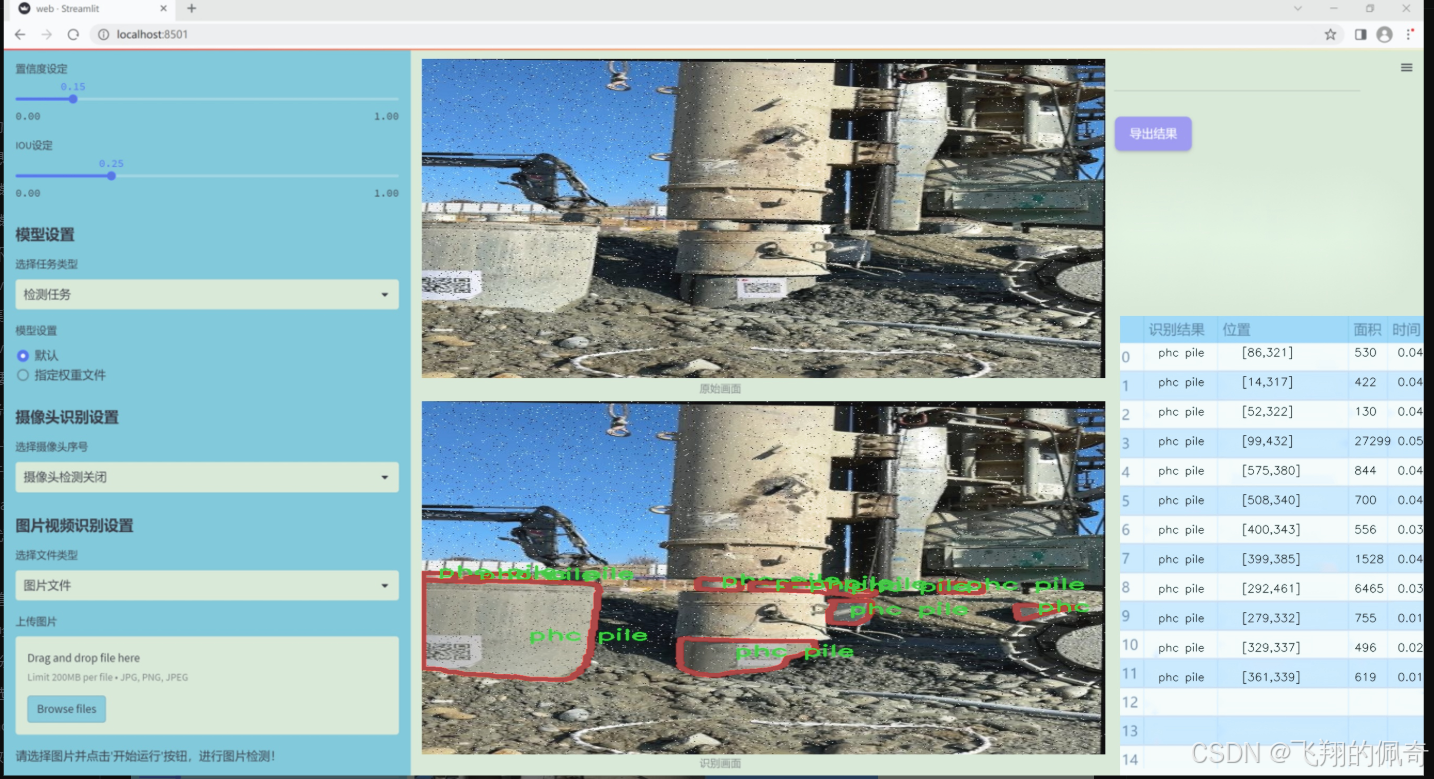
图片效果

数据集信息
本项目数据集信息介绍
本项目所使用的数据集专注于PHC桩的实例分割,旨在为改进YOLOv11的PHC桩实例分割系统提供高质量的训练数据。该数据集的主题为"civil-segm",其主要目标是通过精确的实例分割技术,提升对PHC桩在土木工程领域中的识别和分析能力。数据集中包含的类别数量为1,具体类别为"phc pile",这意味着所有的标注数据均围绕这一特定类别展开,确保了数据集的专一性和针对性。
在数据收集过程中,我们通过多种途径获取了丰富的PHC桩图像,包括实地拍摄和公开数据库的整合。这些图像涵盖了不同环境、不同角度和不同光照条件下的PHC桩,力求反映出真实世界中PHC桩的多样性。每张图像都经过精细的标注,确保每个PHC桩实例都被准确识别和分割,为模型的训练提供了坚实的基础。
此外,为了增强数据集的多样性和模型的泛化能力,我们还进行了数据增强处理,包括旋转、缩放、翻转等操作。这些处理不仅增加了数据集的样本数量,还提高了模型在不同情况下的鲁棒性。通过这样的数据集构建,我们期望在PHC桩的实例分割任务中实现更高的准确率和更好的性能表现,从而为土木工程领域的相关应用提供更为强大的技术支持。总之,本项目的数据集为改进YOLOv11的PHC桩实例分割系统奠定了坚实的基础,期待其在实际应用中的表现。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from functools import lru_cache
class KAGNConvNDLayer(nn.Module):
def init (self, conv_class, norm_class, conv_w_fun, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1, dropout: float = 0.0, ndim: int = 2):
super(KAGNConvNDLayer, self).init ()
初始化输入和输出维度、卷积参数等
self.inputdim = input_dim
self.outdim = output_dim
self.degree = degree
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.dilation = dilation
self.groups = groups
self.base_activation = nn.SiLU() # 使用SiLU激活函数
self.conv_w_fun = conv_w_fun # 卷积权重函数
self.ndim = ndim # 数据的维度
self.dropout = None # 初始化dropout层
if dropout > 0:
if ndim == 1:
self.dropout = nn.Dropout1d(p=dropout)
elif ndim == 2:
self.dropout = nn.Dropout2d(p=dropout)
elif ndim == 3:
self.dropout = nn.Dropout3d(p=dropout)
# 检查groups参数的有效性
if groups <= 0:
raise ValueError('groups must be a positive integer')
if input_dim % groups != 0:
raise ValueError('input_dim must be divisible by groups')
if output_dim % groups != 0:
raise ValueError('output_dim must be divisible by groups')
# 创建基础卷积层和归一化层
self.base_conv = nn.ModuleList([conv_class(input_dim // groups,
output_dim // groups,
kernel_size,
stride,
padding,
dilation,
groups=1,
bias=False) for _ in range(groups)])
self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])
# 初始化多项式权重
poly_shape = (groups, output_dim // groups, (input_dim // groups) * (degree + 1)) + tuple(
kernel_size for _ in range(ndim))
self.poly_weights = nn.Parameter(torch.randn(*poly_shape)) # 多项式权重
self.beta_weights = nn.Parameter(torch.zeros(degree + 1, dtype=torch.float32)) # beta权重
# 使用Kaiming均匀分布初始化卷积层权重
for conv_layer in self.base_conv:
nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')
nn.init.kaiming_uniform_(self.poly_weights, nonlinearity='linear')
nn.init.normal_(
self.beta_weights,
mean=0.0,
std=1.0 / ((kernel_size ** ndim) * self.inputdim * (self.degree + 1.0)),
)
def beta(self, n, m):
# 计算beta值,用于Legendre多项式的计算
return (
((m + n) * (m - n) * n ** 2) / (m ** 2 / (4.0 * n ** 2 - 1.0))
) * self.beta_weights[n]
@lru_cache(maxsize=128) # 使用缓存避免重复计算Legendre多项式
def gram_poly(self, x, degree):
# 计算Legendre多项式
p0 = x.new_ones(x.size()) # P0 = 1
if degree == 0:
return p0.unsqueeze(-1)
p1 = x # P1 = x
grams_basis = [p0, p1]
for i in range(2, degree + 1):
p2 = x * p1 - self.beta(i - 1, i) * p0 # 递归计算多项式
grams_basis.append(p2)
p0, p1 = p1, p2
return torch.cat(grams_basis, dim=1) # 返回多项式基
def forward_kag(self, x, group_index):
# 前向传播,处理每个组的输入
basis = self.base_conv[group_index](self.base_activation(x)) # 计算基础卷积
# 将x归一化到[-1, 1]范围内,以稳定Legendre多项式的计算
x = torch.tanh(x).contiguous()
if self.dropout is not None:
x = self.dropout(x) # 应用dropout
grams_basis = self.base_activation(self.gram_poly(x, self.degree)) # 计算多项式基
y = self.conv_w_fun(grams_basis, self.poly_weights[group_index],
stride=self.stride, dilation=self.dilation,
padding=self.padding, groups=1) # 应用卷积权重函数
y = self.base_activation(self.layer_norm[group_index](y + basis)) # 归一化并激活
return y
def forward(self, x):
# 前向传播,处理所有组的输入
split_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入
output = []
for group_ind, _x in enumerate(split_x):
y = self.forward_kag(_x.clone(), group_ind) # 处理每个组
output.append(y.clone())
y = torch.cat(output, dim=1) # 合并输出
return y代码核心部分说明:
KAGNConvNDLayer: 这是一个自定义的卷积层,支持任意维度的卷积操作。它通过多项式的方式增强卷积操作的表达能力。
beta函数: 计算Legendre多项式所需的beta值。
gram_poly函数: 计算Legendre多项式基,用于后续的卷积操作。
forward_kag函数: 实现了对每个组的前向传播逻辑,包括基础卷积、归一化和激活。
forward函数: 实现了对整个输入的前向传播,处理多个组的输入并合并输出。
这个程序文件定义了一个名为 kagn_conv.py 的模块,主要实现了一个通用的卷积层 KAGNConvNDLayer,以及针对不同维度(1D、2D、3D)的具体实现类 KAGNConv1DLayer、KAGNConv2DLayer 和 KAGNConv3DLayer。该模块的设计灵感来源于一个 GitHub 项目,目的是为了在卷积神经网络中引入更复杂的特征表示。
在 KAGNConvNDLayer 类的构造函数中,首先定义了一些卷积层的基本参数,如输入和输出维度、卷积核大小、步幅、填充、扩张、组数等。该类支持多种维度的卷积操作,具体通过 ndim 参数来指定。类中还定义了一个激活函数(SiLU)和可选的 dropout 层,用于防止过拟合。
接下来,程序检查组数是否为正整数,并确保输入和输出维度能够被组数整除。然后,使用 nn.ModuleList 创建多个基础卷积层和归一化层,以支持分组卷积的实现。卷积层的权重和多项式权重(poly_weights)被初始化为 Kaiming 均匀分布,以提高训练的起始效果。
beta 方法用于计算与 Legendre 多项式相关的系数,而 gram_poly 方法则计算给定度数的 Legendre 多项式,使用了缓存机制以避免重复计算。forward_kag 方法是该类的核心部分,负责执行前向传播,首先通过基础卷积层和激活函数处理输入,然后计算多项式基,并最终通过自定义的卷积函数将其与多项式权重结合,得到输出。
forward 方法则负责将输入张量分割成多个组,并对每个组调用 forward_kag 方法进行处理,最后将所有组的输出拼接在一起。
针对不同维度的卷积层,KAGNConv3DLayer、KAGNConv2DLayer 和 KAGNConv1DLayer 类分别继承自 KAGNConvNDLayer,并在构造函数中指定相应的卷积类和归一化类。这种设计使得代码具有很好的复用性和扩展性,能够灵活地应用于不同类型的卷积操作中。
10.3 activation.py
import torch
import torch.nn as nn
class AGLU(nn.Module):
"""AGLU激活函数模块,来源于https://github.com/kostas1515/AGLU。"""
def __init__(self, device=None, dtype=None) -> None:
"""初始化AGLU激活函数模块。"""
super().__init__()
# 使用Softplus作为基础激活函数,beta设置为-1.0
self.act = nn.Softplus(beta=-1.0)
# 初始化lambda参数,确保其在训练过程中可学习
self.lambd = nn.Parameter(nn.init.uniform_(torch.empty(1, device=device, dtype=dtype))) # lambda参数
# 初始化kappa参数,确保其在训练过程中可学习
self.kappa = nn.Parameter(nn.init.uniform_(torch.empty(1, device=device, dtype=dtype))) # kappa参数
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""计算AGLU激活函数的前向传播。"""
# 将lambda参数限制在最小值0.0001,避免数值不稳定
lam = torch.clamp(self.lambd, min=0.0001)
# 计算AGLU激活函数的输出
return torch.exp((1 / lam) * self.act((self.kappa * x) - torch.log(lam)))代码注释说明:
导入模块:导入torch和torch.nn,这两个模块是PyTorch深度学习框架的核心组件。
AGLU类:定义了一个名为AGLU的类,继承自nn.Module,用于实现AGLU激活函数。
初始化方法:
__init__方法用于初始化AGLU模块,设置了两个可学习的参数lambd和kappa,并定义了基础激活函数Softplus。
lambd和kappa参数使用均匀分布初始化,并被定义为nn.Parameter,这意味着它们将在训练过程中被优化。
前向传播方法:
forward方法实现了AGLU激活函数的前向计算。
torch.clamp用于限制lambd的最小值,避免在计算中出现数值不稳定。
最后返回AGLU激活函数的计算结果。
这个程序文件定义了一个名为 activation.py 的模块,主要用于实现一种统一的激活函数,称为 AGLU(Adaptive Gated Linear Unit)。该模块使用了 PyTorch 框架,包含了一个类 AGLU,继承自 nn.Module,这是 PyTorch 中所有神经网络模块的基类。
在 AGLU 类的构造函数 init 中,首先调用了父类的构造函数。接着,定义了一个激活函数 self.act,使用了 nn.Softplus,其参数 beta 被设置为 -1.0。Softplus 是一种平滑的激活函数,类似于 ReLU,但在负值区域也有输出。接下来,定义了两个可学习的参数 lambd 和 kappa,它们都是通过均匀分布初始化的,并且可以在训练过程中更新。lambd 和 kappa 的初始化是在指定的设备(如 CPU 或 GPU)和数据类型下进行的。
在 forward 方法中,定义了前向传播的计算过程。输入 x 是一个张量,首先通过 torch.clamp 函数对 lambd 进行限制,确保其最小值为 0.0001,以避免在后续计算中出现除以零的情况。然后,计算激活函数的输出,使用了 torch.exp 函数和之前定义的 self.act。具体的计算公式是:首先计算 (self.kappa * x) - torch.log(lam),然后将结果传入 self.act,最后将输出乘以 1 / lam,并取指数。
整体来看,这个模块实现了一个自适应的激活函数,能够根据输入动态调整其输出,有助于提高神经网络的表现。
10.4 deconv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import math
import torch
from torch import nn
from einops.layers.torch import Rearrange
定义一个卷积层类 Conv2d_cd
class Conv2d_cd(nn.Module):
def init (self, in_channels, out_channels, kernel_size=3, stride=1,
padding=1, dilation=1, groups=1, bias=False, theta=1.0):
super(Conv2d_cd, self).init ()
初始化一个2D卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.theta = theta # 用于后续权重调整的参数
def get_weight(self):
# 获取卷积层的权重
conv_weight = self.conv.weight
conv_shape = conv_weight.shape # 获取权重的形状
# 重排权重的维度
conv_weight = Rearrange('c_in c_out k1 k2 -> c_in c_out (k1 k2)')(conv_weight)
# 创建一个新的权重张量并初始化为0
conv_weight_cd = torch.zeros(conv_shape[0], conv_shape[1], 3 * 3, device=conv_weight.device)
conv_weight_cd[:, :, :] = conv_weight[:, :, :] # 复制原始权重
# 调整权重,使其符合特定的计算要求
conv_weight_cd[:, :, 4] = conv_weight[:, :, 4] - conv_weight[:, :, :].sum(2)
# 重排回原来的形状
conv_weight_cd = Rearrange('c_in c_out (k1 k2) -> c_in c_out k1 k2', k1=conv_shape[2], k2=conv_shape[3])(conv_weight_cd)
return conv_weight_cd, self.conv.bias # 返回调整后的权重和偏置定义一个卷积层类 Conv2d_ad
class Conv2d_ad(nn.Module):
def init (self, in_channels, out_channels, kernel_size=3, stride=1,
padding=1, dilation=1, groups=1, bias=False, theta=1.0):
super(Conv2d_ad, self).init ()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.theta = theta
def get_weight(self):
# 获取卷积层的权重
conv_weight = self.conv.weight
conv_shape = conv_weight.shape
conv_weight = Rearrange('c_in c_out k1 k2 -> c_in c_out (k1 k2)')(conv_weight)
# 进行权重调整
conv_weight_ad = conv_weight - self.theta * conv_weight[:, :, [3, 0, 1, 6, 4, 2, 7, 8, 5]]
conv_weight_ad = Rearrange('c_in c_out (k1 k2) -> c_in c_out k1 k2', k1=conv_shape[2], k2=conv_shape[3])(conv_weight_ad)
return conv_weight_ad, self.conv.bias定义一个解卷积类 DEConv
class DEConv(nn.Module):
def init (self, dim):
super(DEConv, self).init ()
初始化多个卷积层
self.conv1_1 = Conv2d_cd(dim, dim, 3, bias=True)
self.conv1_2 = Conv2d_ad(dim, dim, 3, bias=True)
self.conv1_3 = nn.Conv2d(dim, dim, 3, padding=1, bias=True) # 普通卷积层
self.bn = nn.BatchNorm2d(dim) # 批归一化层
self.act = nn.ReLU() # 激活函数
def forward(self, x):
# 前向传播
w1, b1 = self.conv1_1.get_weight() # 获取第一个卷积层的权重和偏置
w2, b2 = self.conv1_2.get_weight() # 获取第二个卷积层的权重和偏置
w3, b3 = self.conv1_3.weight, self.conv1_3.bias # 获取普通卷积层的权重和偏置
# 将所有卷积层的权重和偏置相加
w = w1 + w2 + w3
b = b1 + b2 + b3
# 进行卷积操作
res = nn.functional.conv2d(input=x, weight=w, bias=b, stride=1, padding=1, groups=1)
# 如果有批归一化层,则进行批归一化
res = self.bn(res)
return self.act(res) # 返回经过激活函数处理的结果
def switch_to_deploy(self):
# 将卷积层的权重和偏置合并,准备部署
w1, b1 = self.conv1_1.get_weight()
w2, b2 = self.conv1_2.get_weight()
w3, b3 = self.conv1_3.weight, self.conv1_3.bias
self.conv1_3.weight = torch.nn.Parameter(w1 + w2 + w3) # 合并权重
self.conv1_3.bias = torch.nn.Parameter(b1 + b2 + b3) # 合并偏置
# 删除不再需要的卷积层
del self.conv1_1
del self.conv1_2代码说明:
卷积层类:Conv2d_cd 和 Conv2d_ad 类分别定义了带有不同权重调整机制的卷积层。get_weight 方法用于获取调整后的权重和偏置。
解卷积类:DEConv 类整合了多个卷积层,并在前向传播中对输入进行处理。switch_to_deploy 方法用于合并卷积层的权重和偏置,以便在推理阶段使用。
前向传播:在 forward 方法中,输入经过多个卷积层处理,并最终通过批归一化和激活函数输出结果。
这个程序文件 deconv.py 定义了一系列卷积层的变体,主要用于深度学习中的卷积神经网络(CNN)。文件中包含多个类,每个类实现了不同类型的卷积操作,以下是对代码的详细讲解。
首先,程序导入了必要的库,包括 math、torch 和 torch.nn,以及一些用于张量操作的工具,如 Rearrange。Conv 是一个自定义模块,可能在其他地方定义,fuse_conv_and_bn 是一个用于融合卷积层和批归一化层的函数。
接下来,定义了多个卷积类,每个类都继承自 nn.Module。这些类的构造函数中都初始化了一个标准的二维卷积层 nn.Conv2d,并且接受多个参数来配置卷积的行为,如输入通道数、输出通道数、卷积核大小、步幅、填充、扩张、分组和偏置。
Conv2d_cd 类:这个类实现了一种特定的卷积权重处理方式。在 get_weight 方法中,首先获取卷积层的权重并进行重排,然后创建一个新的权重张量,并对其进行一些计算,最后返回处理后的权重和偏置。
Conv2d_ad 类:与 Conv2d_cd 类似,但在权重处理上有不同的计算方式。它通过对原始权重进行变换来生成新的权重。
Conv2d_rd 类:这个类的 forward 方法根据 theta 的值决定使用标准卷积还是自定义的卷积权重进行计算。它在权重处理上进行了更复杂的操作,涉及到对权重的特定索引进行赋值。
Conv2d_hd 和 Conv2d_vd 类:这两个类的实现与前面的类类似,主要是处理卷积权重并返回处理后的权重和偏置。
最后,定义了一个名为 DEConv 的类,它整合了之前定义的多个卷积层。构造函数中初始化了多个卷积层,并在 forward 方法中将它们的输出加在一起,然后通过一个标准的卷积层进行最终的计算。switch_to_deploy 方法用于将多个卷积层的权重和偏置合并到最后一个卷积层中,以便在推理时提高效率。
在文件的最后部分,提供了一个简单的测试代码,创建了一个随机输入张量,并通过 DEConv 模型进行前向传播,随后调用 switch_to_deploy 方法并再次进行前向传播,最后检查两次输出是否相同。
整体来看,这个文件实现了一个灵活的卷积层组合,能够根据不同的需求调整卷积的权重和偏置,同时也为模型的推理阶段提供了优化手段。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻