End_To_End 之于推荐onerec里,快手利用大模型做了推荐架构的革命,几个月后,v2之于v1是一些技术细节进行了进一步迭代,主要是以下两个方面:
1. 架构层面的突破:Lazy Decoder-Only
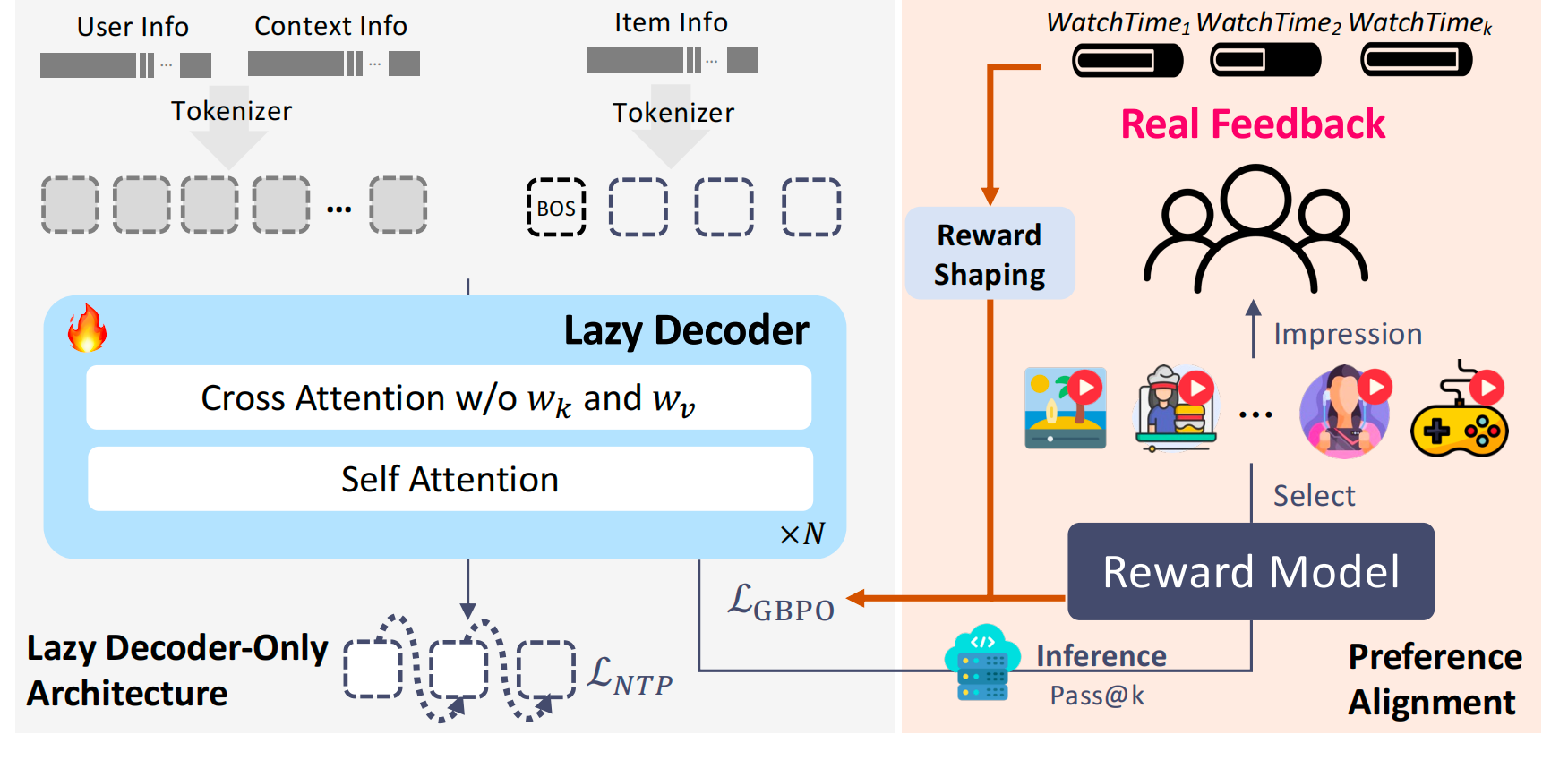
背景问题:V1 的 Encoder-Decoder 架构里,97.66% 的算力都消耗在 context encoding,真正用于生成推荐结果的部分只有 2.34%,导致算力浪费、扩展性差。
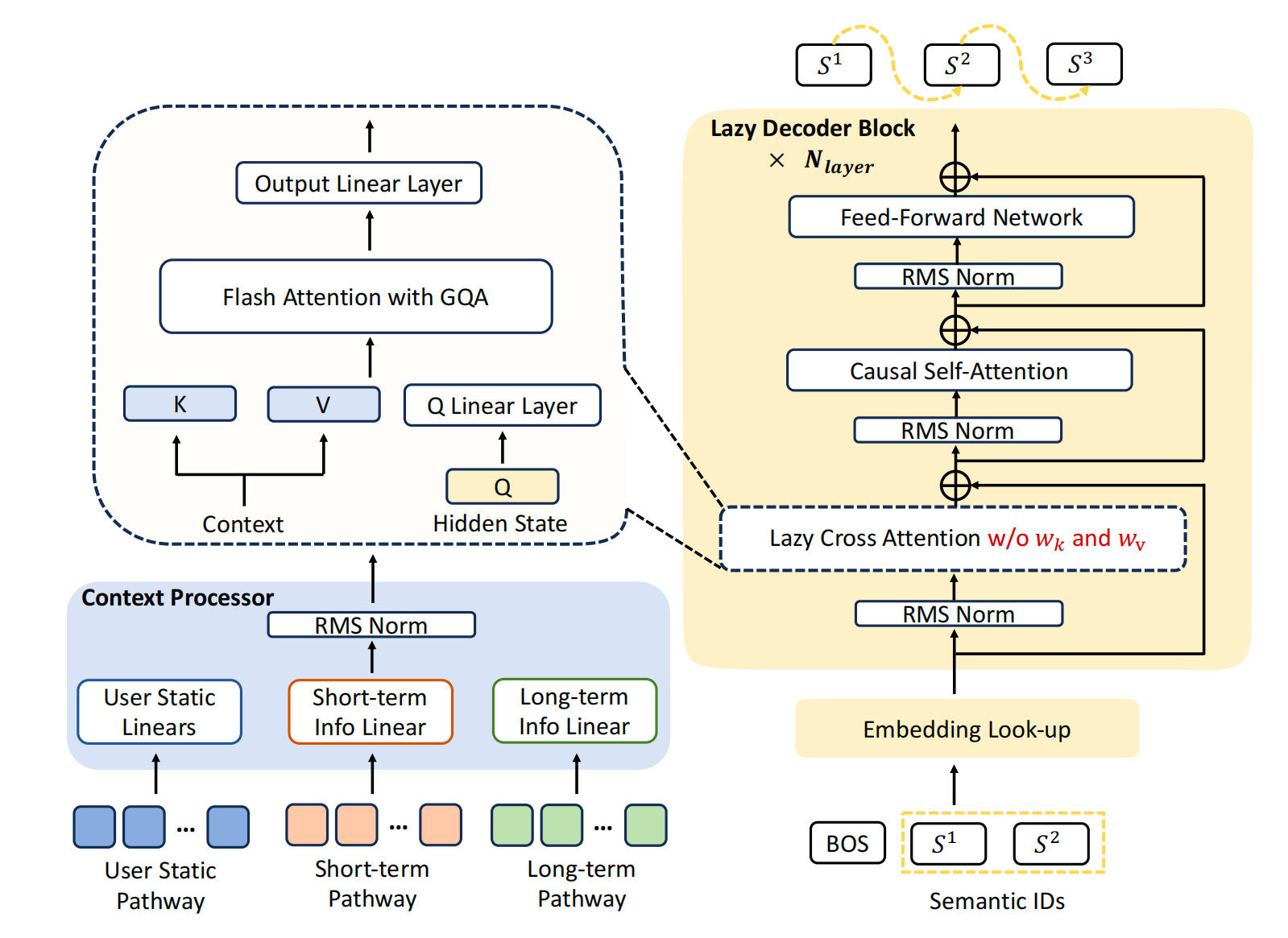
改进方案:提出 Lazy Decoder-Only 架构,彻底移除 encoder,context 只作为静态条件输入,通过轻量 cross-attention 与 GQA(Grouped Query Attention)完成交互。
效果:
- 计算量减少 94%,训练资源消耗下降 90%。
- 在同样计算预算下,模型参数可以扩展到 8B。
- 训练 loss 随模型扩展呈现一致下降趋势,验证了 scaling law 的可行性。
- 内存占用降低,支持长上下文(从 512 扩展到 3000)。
- 结合 MoE(4B 总参 / 0.5B 激活),进一步平衡算力与性能。
2. 偏好对齐:基于真实用户反馈的 RL
V1 局限:仅依赖 Reward Model,会遇到抽样效率低、奖励欺骗(reward hacking)等问题。
V2 改进:Duration-Aware Reward Shaping
直接使用用户反馈作为reward:将视频播放时长与用户历史的同类时长 bucket 对比,取分位数作为 engagement score,避免"长视频天然更高播放时长"的偏差。
GBPO (Gradient-Bounded Policy Optimization)
改进 RL 的 ratio clipping,结合 BCE 的稳定梯度,防止负样本导致梯度爆炸。
不丢弃样本 → 保持探索多样性;梯度有界 → 训练更稳定。
自举式优化:直接利用 OneRec 自身曝光的流量样本做 on-policy 训练,实现自我改进。
对比结果:
- Reward Model → 偏向互动指标(like/comment)。
- User Feedback → 偏向停留时长(App Stay Time)。
- Hybrid → 指标均衡,避免 seesaw 效应。
3. 线上 A/B 测试结果
在快手主站 & 极速版 5% 流量实验中(400M DAU):
App Stay Time:+0.467%(主站) / +0.741%(极速版)
LT7(7 日生命周期):+0.069% / +0.034%
互动指标全面提升:like、follow、comment、collect、forward 全部正向改善
推理部署:1B 模型,context=3000,MFU 达 62%,延迟仅 36ms(20×A100 GPU)。
最后,给出一个对比表:
| 维度 | OneRec-V1 | OneRec-V2 | 改进点总结 |
|---|---|---|---|
| 模型架构 | Encoder-Decoder | Lazy Decoder-Only | 移除 Encoder,计算集中在 Decoder,减少 94% FLOPs |
| 算力分配 | 97.66% 用于 context encoding,仅 2.34% 用于生成 | ≈100% 用于 target decoding | 解决算力浪费问题,提升 scaling 潜力 |
| 扩展能力 | Decoder 参数比 Encoder 多,但受算力瓶颈限制,难以扩展 | 支持扩展到 8B 参数,MoE 版本 4B 总参(0.5B 激活) | 高效扩展,更接近 LLM 的 scaling law |
| Cross Attention | 标准 cross-attention(KV 投影 + 多头) | Lazy Cross-Attention(去掉 KV 投影,KV-Sharing + GQA) | 降低内存 & 计算开销,支持长上下文(3000) |
| 训练数据组织 | User-Centric / Encoder-Decoder 组织,存在冗余和泄漏风险 | Chronological + 仅最新 impression 计算 loss | 减少冗余训练,避免时间泄漏 |
| RL 策略 | 仅基于 Reward Model(DPO/ECPO) | User Feedback 信号驱动 + Duration-Aware Reward + GBPO | 避免 reward hacking,提升真实偏好对齐 |
| Reward 设计 | Proxy Reward(容易被模型利用) | Duration-Aware Reward Shaping(分位数归一化) | 去除长视频偏差,更好反映质量 |
| 优化算法 | ECPO(早期裁剪) | GBPO(梯度有界 + 全样本利用) | 稳定性更高,不丢弃样本,探索更多样 |
| 自举优化 | 流量较小,主要依赖传统 pipeline 样本 | OneRec 曝光占流量 25%,可用自生成样本 on-policy 训练 | 实现 self-improvement |
| 线上效果 (主站) | App Stay Time +0.269% | App Stay Time +0.467%,LT7 +0.069% | 明显提升,平衡 seesaw 效应 |
| 线上效果 (极速版) | App Stay Time +0.163% | App Stay Time +0.741%,LT7 +0.034% | 效果更显著 |
| 互动指标 | 偏向提升 Like / Comment | 全面提升(Like、Follow、Comment、Collect、Forward) | 多目标更均衡 |
| 推理效率 | MFU 较低,部署成本高 | MFU 62%,延迟 36ms(1B 模型,20×A100) | 接近 LLM 部署效率,成本降低 |