目录
[1. 基本概念](#1. 基本概念)
[2. 安装部署 (基于 Docker)](#2. 安装部署 (基于 Docker))
[2.1 使用 docker 获取 redis 镜像](#2.1 使用 docker 获取 redis 镜像)
[2.2 编排 主从节点](#2.2 编排 主从节点)
[2.3 编排 redis-sentinel 节点](#2.3 编排 redis-sentinel 节点)
[3. 重新选举](#3. 重新选举)
[4. 选举原理](#4. 选举原理)
[5. 总结](#5. 总结)
1. 基本概念
|---------------------|------------------|-------------------------|
| 名词 | 逻辑结构 | 物理结构 |
| 主节点 | Reids 主服务 | 一个独立的 redis-server 进程 |
| 从节点 | Redis 从服务 | 一个独立的 reids-server 进程 |
| Reids 数据节点 | 主从节点 | 主节点和从节点的进程 |
| 哨兵节点 | 监控 Reids 数据节点的节点 | 一个独立的 redis-sentinel 进程 |
| 哨兵节点集合 | 若干哨兵节点的抽象组合 | 若干 redis-sentinel 进程 |
| Redis 哨兵 (Sentinel) | Redis 提供的高可用方案 | 哨兵节点结合和 Redis 主从节点 |
| 应用方 | 泛指一个多多个客户端 | 一个或多个连接 Redis 的进程 |
我们在使用 主从复制时, 主从节点的复制模式, 让我们的主节点在故障的时候, 有了一个从节点的备份, 保证数据尽量不丢失, 从节点还可以分担主节点的读压力, 让主节点只承担写的请求. 但是这种模式并不是万能的, 还是有问题的 :
- 主节点发生故障时, 进行主从切换的过程的复杂的, 需要完全的人工参与, 导致故障时间无法保障.
- 主节点可以将读压力分散出去, 但写压力 / 存储压力是无法被分担的, 还是受到单机的限制.
我们的第一个问题就是使用哨兵来解决的, 哨兵可以使我们的的切换过程自动化
Redis Sentinel 故障转移的流程 :
- 节点故障, 从节点同步连接中断, 主从复制停止
- 哨兵节点通过定期监控发现主节点出现故障, 哨兵节点与其他哨兵节点进行协商, 达成多数认同主节点故障的共识. 这步主要是防止该情况 : 出故障的不是主节点, 而是发现故障的哨兵节点, 该情况经常发生于哨兵节点的网络被孤立的场景下
- 哨兵节点之间使用 Raft 算法选举出一个领导角色, 由该节点负责后续的故障转移工作
- 哨兵领导者开始执行故障转移 : 从节点中选择一个作为新主节点, 让其他从节点同步新主节点, 通知应用层转移到新主节点
Redis Sentinel 的核心功能 :
- 监控 : Sentinel 节点会定期检测 Redis 数据节点, 其余哨兵节点是否可达
- 故障转移 : 实现从节点晋升 (promotion) 为主节点并维护后续正确的主从关系
- 通知 : Sentinel 节点会将故障转移的结果通知给应用方
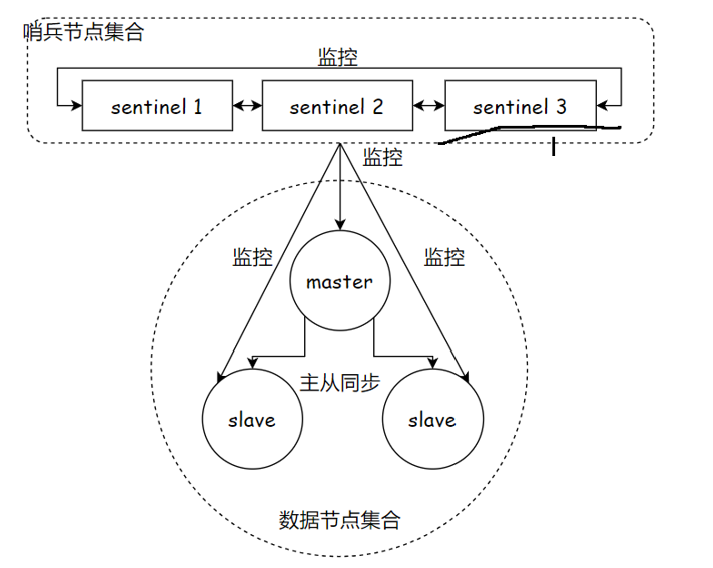
哨兵节点有一个也是可以的
2. 安装部署 (基于 Docker)
2.1 使用 docker 获取 redis 镜像
查看

2.2 编排 主从节点
创建容器 :

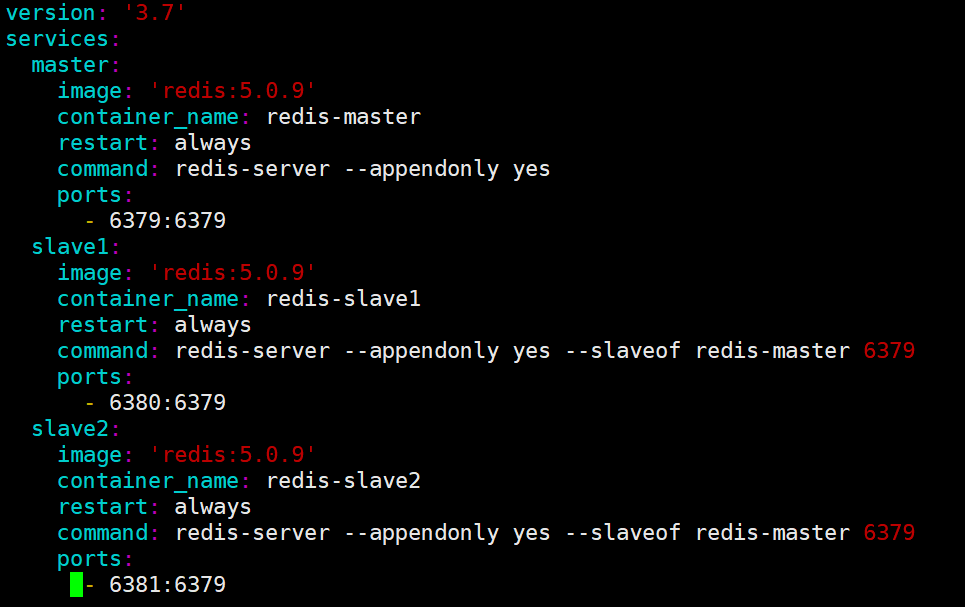
启动所有容器 :

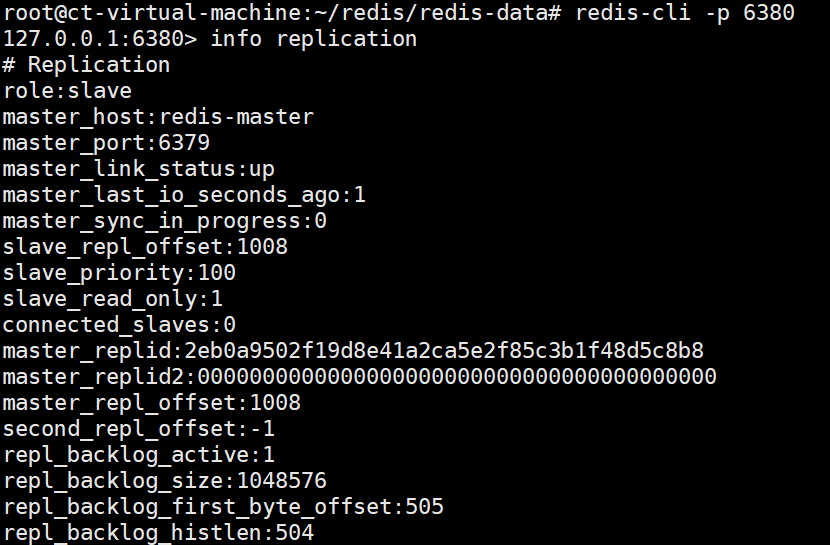
验证 :
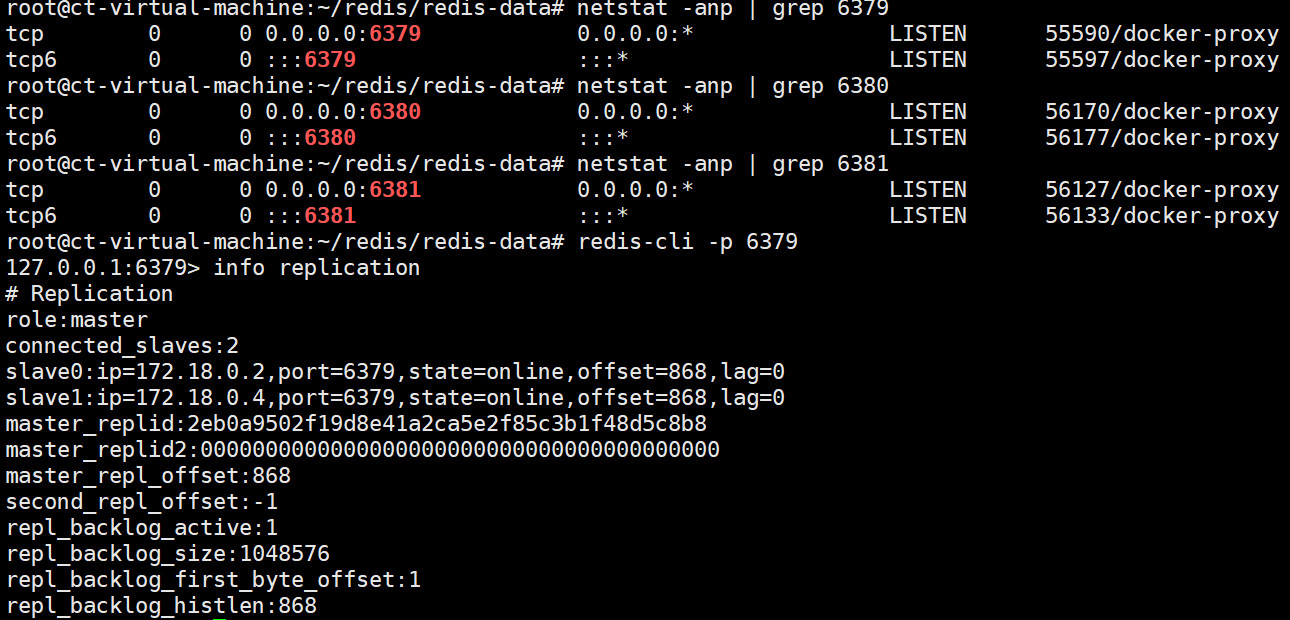
2.3 编排 redis-sentinel 节点
创建容器 :
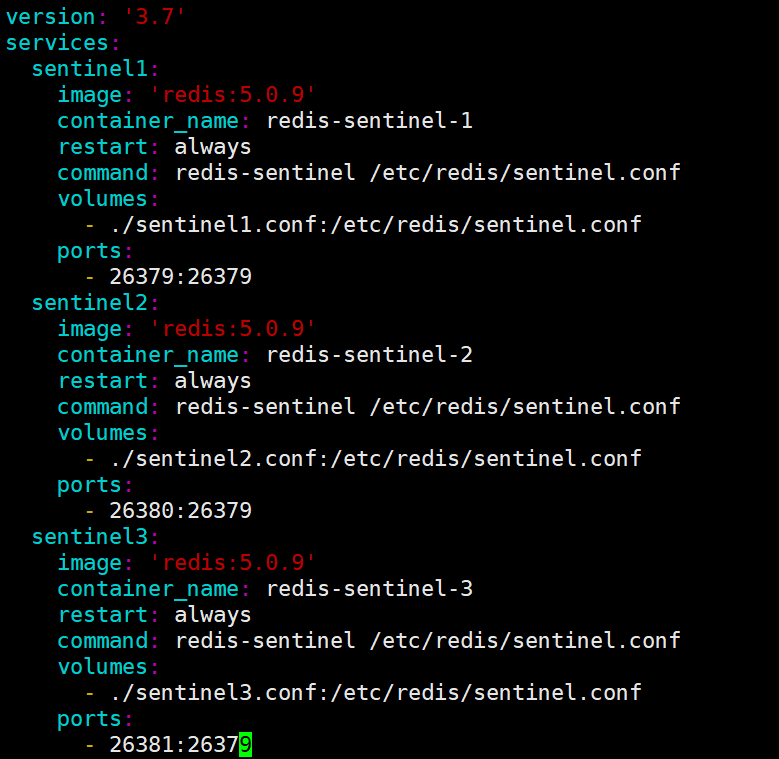
这里因为启动之后, 每个 sentinel.conf 的内容会发生改变, 所以要是用不同的文件, 但文件的内容是一样的


启动容器 :

查看日志 : docker-compose logs

此处, 会发生报错, 哨兵节点不认识 redis-master (一个域名, docker 会解析)
为什么会解析不了呢? docker-compose 一下启动了 N 个容器, 此时 N 哥容器都处于同一个 "局域网" 中, 可以使这 N 个容器之间可以相互访问. 三个 redis-server 节点, 是一个局域网, 三个哨兵节点, 是另一个局域网, 默认情况下, 这两个网络, 不是互通的.
那么我们可以使用 docker-compose 把此处的两组服务给放到同一个局域网中.
查看 docker 创建的局域网 :

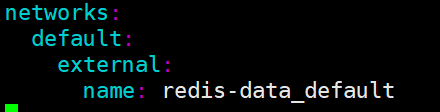
在 docker-compose.yml 中加入 :
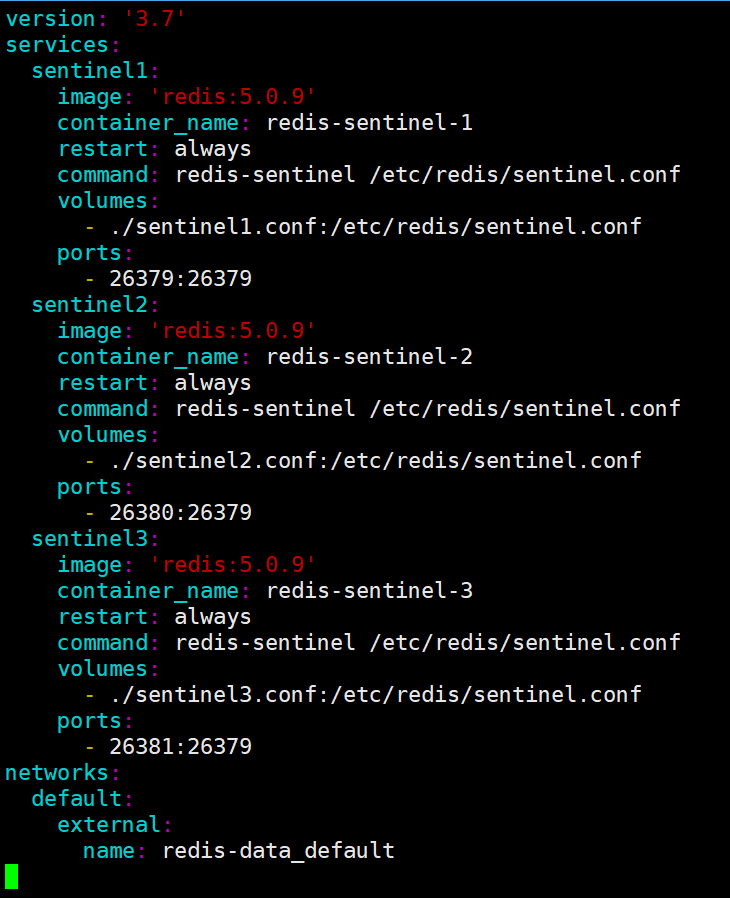
重新启动容器 :
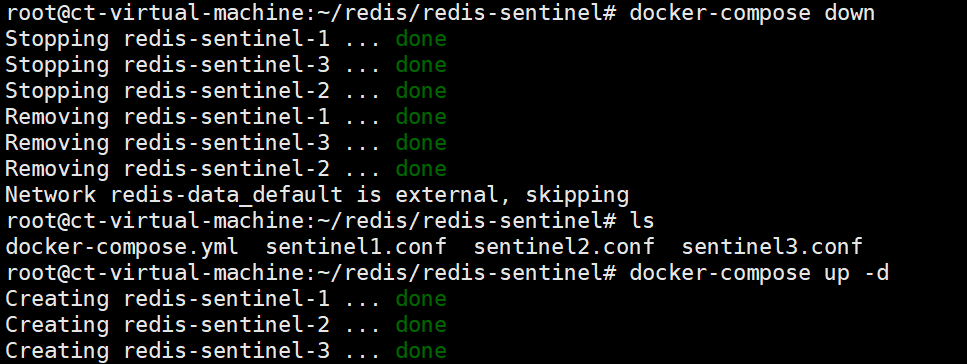
这下全都在同一个局域网中, 就没有问题了
也可以将 六个容器, 都写到同一个 yml 配置中, 一次全都启动, 这样也可以保证互通问题
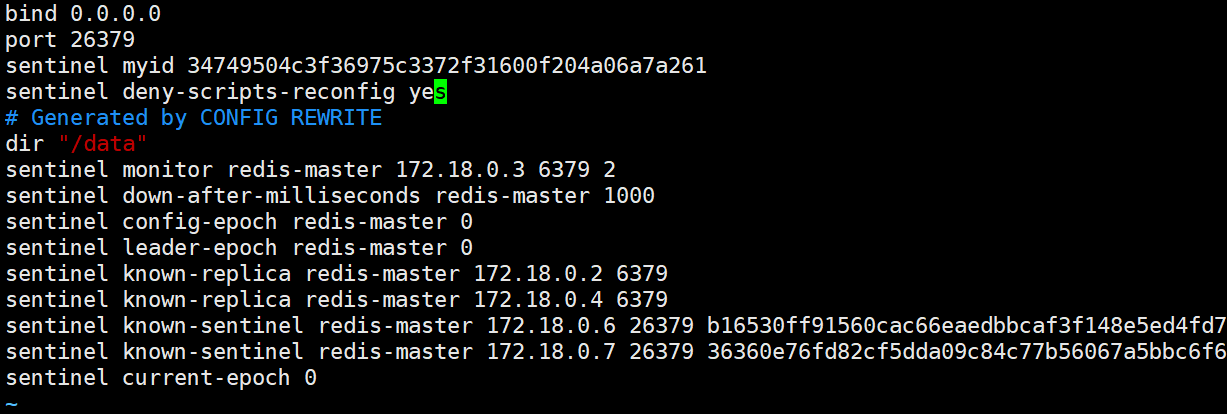
查看 sentinel. conf 文件, 发现确实发生了变化 :
3. 重新选举
当 redis-master 宕机之后, 观察 哨兵的日志, 我们可以发现, 哨兵发现了主节点 sdown, 多个哨兵开投票, 当票数达到法定票数,于是, 主节点被判定 odown
- 主观下线 (sdown) : 哨兵感知到主节点没心跳了. 判定为主观下线.
- 客观下线 (odown) : 多个哨兵达成一致意见, 才能认为 master 确实下线了.
Redis 主机如果宕机, 哨兵会把其中一个从节点, 提拔成主节点, 当之前的 redis 主节点重启之后, 这个主节点被加入到哨兵的监控中, 但是只会被作为从节点使用
4. 选举原理
- 主观下线 : 当 redis-master 宕机, 此时 redis-master 和三个哨兵之间的心跳包就没有了. 此时, 站在三个哨兵的角度来看, redis-master 出现严重故障. 因此三个哨兵均会把 redis-master 判定为主观下线 (SDown)
- 客观下线 : 此时, 哨兵 sentinel1, sentinel2, sentinel3 均会对主节点故障这件事情进行投票. 当故障得票数 >= 配置的法定票数之后, 此时意味着 redis-master 故障这个事情被做实了. 此时触发客观下线 (ODown)
- 选举出哨兵的 leader : 接下来需要哨兵把剩余的 slave 中挑选出一个新的 master. 这个工作不需要所有的哨兵都参与. 只需要选出个代表(称为 leader ), 由 leader 负责进行 slave 升级到 master 的提拔过程 .这个选举的过程涉及到 Raft 算法 (先下手为强).
- leader 挑选出合适的 slave 成为新的 master : 挑选规则 : 1. 比较优先级. 优先级高(数值小的)的上位. 优先级是配置文件中的配置项 (slave-priority 或者 replica-priority). 2.比较 replication offset 谁复制的数据多, 高的上位. 3.比较run id, 谁的 id 小, 谁上位.
- 当某个 slave 节点被指定为 master 之后, leader 指定该节点执行slave no one, 成为 master, leader 指定剩余的 slave 节点, 都依附于这个新 master \
5. 总结
- 哨兵节点不能只有一个. 否则哨兵节点挂了也会影响系统可用性.
- 哨兵节点最好是奇数个. 方便选举leader, 得票更容易超过半数.
- 哨兵节点不负责存储数据. 仍然是 redis 主从节点负责存储
- 哨兵 + 主从复制解决的问题是 "提高可用性", 不能解决 "数据极端情况下写丢失" 的问题.
- 哨兵 + 主从复制不能提高数据的存储容量. 当我们需要存的数据接近或者超过机器的物理内存, 这样的结构就难以胜任了.