MySQL数据库是一种传统的关系型数据库,我们可以使用MySQL来更好的管理我们的数据,虽然在小型web项目内采用MySQL+Mybatis可以胜任大部分的数据存储,但是MySQL只能将数据存在本地存储内缺是其一大硬伤,如果是不需要长期修改的信息数据倒是无所谓,但是遇上秒杀,热搜等不仅需要高速的服务器响应,并且还需要面对数据的上千次以上的访问,MySQL的IO读写性能完全不能满足以上需求。为此我们需要寻找一种更好的解决方案,来存储上述特殊的数据,以面对大时代的考验。
NoSQL概论
NoSQL全称是Not Only SQL(不仅仅是SQL)它是一种非关系型数据库,相比传统SQL关系型数据库,它:
-
不保证关系数据的ACID特性
-
并不遵循SQL标准
-
消除数据之间关联性
乍一看,这玩意不比MySQL垃圾?我们再来看看它的优势:
-
远超传统关系型数据库的性能
-
非常易于扩展
-
数据模型更加灵活
-
高可用
这样,NoSQL的优势一下就出来了,这不就是我们正要寻找的高并发海量数据的解决方案吗!
NoSQL数据库分为以下几种:
-
**键值存储数据库:**所有的数据都是以键值方式存储的,类似于我们之前学过的HashMap,使用起来非常简单方便,性能也非常高。
-
**列存储数据库:**这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。
-
**文档型数据库:**它是以一种特定的文档格式存储数据,比如JSON格式,在处理网页等复杂数据时,文档型数据库比传统键值数据库的查询效率更高。
-
**图形数据库:**利用类似于图的数据结构存储数据,结合图相关算法实现高速访问。
其中我们要学习的Redis数据库,就是一个开源的键值存储数据库,所有的数据全部存放在内存中,它的性能大大高于磁盘IO,并且它也可以支持数据持久化,他还支持横向扩展、主从复制等。
实际生产中,我们一般会配合使用Redis和MySQL以发挥它们各自的优势,取长补短。
Redis安装和部署
我们这里还是使用Windows安装Redis服务器,但是官方指定是安装到Linux服务器上,我们后面学习了Linux之后,再来安装到Linux服务器上。由于官方并没有提供Windows版本的安装包,我们需要另外寻找:
-
GitHub Windows版本维护地址:https://github.com/tporadowski/redis/releases
基本操作
在我们之前使用MySQL时,我们需要先在数据库中创建一张表,并定义好表的每个字段内容,最后再通过insert语句向表中添加数据,而Redis并不具有MySQL那样的严格的表结构,Redis是一个键值数据库,因此,可以像Map一样的操作方式,通过键值对向Redis数据库中添加数据(操作起来类似于向一个HashMap中存放数据)
在Redis下,数据库是由一个整数索引标识,而不是由一个数据库名称。 默认情况下,我们连接Redis数据库之后,会使用0号数据库,我们可以通过Redis配置文件中的参数来修改数据库总数,默认为16个。
我们可以通过select语句进行切换:
select 序号;数据操作
我们来看看,如何向Redis数据库中添加数据:
set <key> <value>
-- 一次性多个
mset [<key> <value>]...所有存入的数据默认会以字符串的形式保存,键值具有一定的命名规范,以方便我们可以快速定位我们的数据属于哪一个部分,比如用户的数据:
-- 使用冒号来进行板块分割,比如下面表示用户XXX的信息中的name属性,值为lbw
set user:info:用户ID:name lbw我们可以通过键值获取存入的值:
get <key>你以为Redis就仅仅只是存取个数据吗?它还支持数据的过期时间设定:
set <key> <value> EX 秒
set <key> <value> PX 毫秒当数据到达指定时间时,会被自动删除。我们也可以单独为其他的键值对设置过期时间:
expire <key> 秒通过下面的命令来查询某个键值对的过期时间还剩多少:
ttl <key>
-- 毫秒显示
pttl <key>
-- 转换为永久
persist <key>那么当我们想直接删除这个数据时呢?直接使用:
del <key>...删除命令可以同时拼接多个键值一起删除。
当我们想要查看数据库中所有的键值时:
keys *也可以查询某个键是否存在:
exists <key>...还可以随机拿一个键:
randomkey我们可以将一个数据库中的内容移动到另一个数据库中:
move <key> 数据库序号修改一个键为另一个键:
rename <key> <新的名称>
-- 下面这个会检查新的名称是否已经存在
renamex <key> <新的名称>如果存放的数据是一个数字,我们还可以对其进行自增自减操作:
-- 等价于a = a + 1
incr <key>
-- 等价于a = a + b
incrby <key> b
-- 等价于a = a - 1
decr <key>最后就是查看值的数据类型:
type <key>Redis数据库也支持多种数据类型,但是它更偏向于我们在Java中认识的那些数据类型。
数据类型介绍
一个键值对除了存储一个String类型的值以外,还支持多种常用的数据类型。
Hash
这种类型本质上就是一个HashMap,也就是嵌套了一个HashMap罢了,在Java中就像这样:
#Redis默认存String类似于这样:
Map<String, String> hash = new HashMap<>();
#Redis存Hash类型的数据类似于这样:
Map<String, Map<String, String>> hash = new HashMap<>();它比较适合存储类这样的数据,由于值本身又是一个Map,因此我们可以在此Map中放入类的各种属性和值,以实现一个Hash数据类型存储一个类的数据。
我们可以像这样来添加一个Hash类型的数据:
hset <key> [<字段> <值>]...我们可以直接获取:
hget <key> <字段>
-- 如果想要一次性获取所有的字段和值
hgetall <key>同样的,我们也可以判断某个字段是否存在:
hexists <key> <字段>删除Hash中的某个字段:
hdel <key>我们发现,在操作一个Hash时,实际上就是我们普通操作命令前面添加一个h,这样就能以同样的方式去操作Hash里面存放的键值对了,这里就不一一列出所有的操作了。我们来看看几个比较特殊的。
我们现在想要知道Hash中一共存了多少个键值对:
hlen <key>我们也可以一次性获取所有字段的值:
hvals <key>唯一需要注意的是,Hash中只能存放字符串值,不允许出现嵌套的的情况。
List
我们接着来看List类型,实际上这个猜都知道,它就是一个列表,而列表中存放一系列的字符串,它支持随机访问,支持双端操作,就像我们使用Java中的LinkedList一样。
我们可以直接向一个已存在或是不存在的List中添加数据,如果不存在,会自动创建:
-- 向列表头部添加元素
lpush <key> <element>...
-- 向列表尾部添加元素
rpush <key> <element>...
-- 在指定元素前面/后面插入元素
linsert <key> before/after <指定元素> <element>同样的,获取元素也非常简单:
-- 根据下标获取元素
lindex <key> <下标>
-- 获取并移除头部元素
lpop <key>
-- 获取并移除尾部元素
rpop <key>
-- 获取指定范围内的
lrange <key> start stop注意下标可以使用负数来表示从后到前数的数字(Python:搁这儿抄呢是吧):
-- 获取列表a中的全部元素
lrange a 0 -1没想到吧,push和pop还能连着用呢:
-- 从前一个数组的最后取一个数出来放到另一个数组的头部,并返回元素
rpoplpush 当前数组 目标数组它还支持阻塞操作,类似于生产者和消费者,比如我们想要等待列表中有了数据后再进行pop操作:
-- 如果列表中没有元素,那么就等待,如果指定时间(秒)内被添加了数据,那么就执行pop操作,如果超时就作废,支持同时等待多个列表,只要其中一个列表有元素了,那么就能执行
blpop <key>... timeoutSet和SortedSet
Set集合其实就像Java中的HashSet一样(我们在JavaSE中已经讲解过了,HashSet本质上就是利用了一个HashMap,但是Value都是固定对象,仅仅是Key不同)它不允许出现重复元素,不支持随机访问,但是能够利用Hash表提供极高的查找效率。
向Set中添加一个或多个值:
sadd <key> <value>...查看Set集合中有多少个值:
scard <key>判断集合中是否包含:
-- 是否包含指定值
sismember <key> <value>
-- 列出所有值
smembers <key>集合之间的运算:
-- 集合之间的差集
sdiff <key1> <key2>
-- 集合之间的交集
sinter <key1> <key2>
-- 求并集
sunion <key1> <key2>
-- 将集合之间的差集存到目标集合中
sdiffstore 目标 <key1> <key2>
-- 同上
sinterstore 目标 <key1> <key2>
-- 同上
sunionstore 目标 <key1> <key2>移动指定值到另一个集合中:
smove <key> 目标 value 移除操作:
-- 随机移除一个幸运儿
spop <key>
-- 移除指定
srem <key> <value>...那么如果我们要求Set集合中的数据按照我们指定的顺序进行排列怎么办呢?这时就可以使用SortedSet,它支持我们为每个值设定一个分数,分数的大小决定了值的位置,所以它是有序的。
我们可以添加一个带分数的值:
zadd <key> [<value> <score>]...同样的:
-- 查询有多少个值
zcard <key>
-- 移除
zrem <key> <value>...
-- 获取区间内的所有
zrange <key> start stop由于所有的值都有一个分数,我们也可以根据分数段来获取:
-- 通过分数段查看
zrangebyscore <key> start stop [withscores] [limit]
-- 统计分数段内的数量
zcount <key> start stop
-- 根据分数获取指定值的排名
zrank <key> <value>有关Bitmap、HyperLogLog和Geospatial等数据类型,这里暂时不做介绍,感兴趣可以自行了解。
持久化
我们知道,Redis数据库中的数据都是存放在内存中,虽然很高效,但是这样存在一个非常严重的问题,如果突然停电,那我们的数据不就全部丢失了吗?它不像硬盘上的数据,断电依然能够保存。
这个时候我们就需要持久化,我们需要将我们的数据备份到硬盘上,防止断电或是机器故障导致的数据丢失。
持久化的实现方式有两种方案:一种是直接保存当前已经存储的数据 ,相当于复制内存中的数据到硬盘上,需要恢复数据时直接读取即可;还有一种就是保存我们存放数据的所有过程,需要恢复数据时,只需要将整个过程完整地重演一遍就能保证与之前数据库中的内容一致。
RDB
RDB就是我们所说的第一种解决方案,那么如何将数据保存到本地呢?我们可以使用命令:
save
-- 注意上面这个命令是直接保存,会占用一定的时间,也可以单独开一个子进程后台执行保存
bgsave执行后,会在服务端目录下生成一个dump.rdb文件,而这个文件中就保存了内存中存放的数据,当服务器重启后,会自动加载里面的内容到对应数据库中。保存后我们可以关闭服务器:
shutdown重启后可以看到数据依然存在。
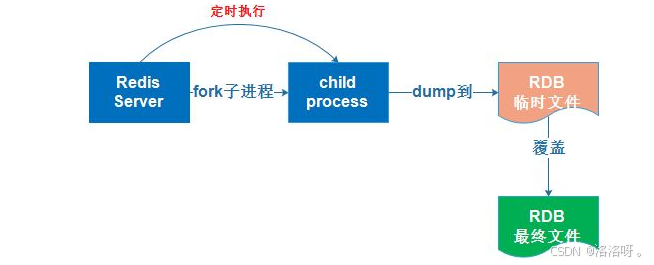
虽然这种方式非常方便,但是由于会完整复制所有的数据,如果数据库中的数据量比较大,那么复制一次可能就需要花费大量的时间,所以我们可以每隔一段时间自动进行保存;还有就是,如果我们基本上都是在进行读操作,而没有进行写操作,实际上只需要偶尔保存一次即可,因为数据几乎没有怎么变化,可能两次保存的都是一样的数据。
我们可以在配置文件中设置自动保存,并设定在一段时间内写入多少数据时,执行一次保存操作:
save 300 10 # 300秒(5分钟)内有10个写入
save 60 10000 # 60秒(1分钟)内有10000个写入配置的save使用的都是bgsave后台执行。
AOF
虽然RDB能够很好地解决数据持久化问题,但是它的缺点也很明显:每次都需要去完整地保存整个数据库中的数据,同时后台保存过程中也会产生额外的内存开销,最严重的是它并不是实时保存的,如果在自动保存触发之前服务器崩溃,那么依然会导致少量数据的丢失。
而AOF就是另一种方式,它会以日志的形式将我们每次执行的命令都进行保存,服务器重启时会将所有命令依次执行,通过这种重演的方式将数据恢复,这样就能很好解决实时性存储问题。

但是,我们多久写一次日志呢?我们可以自己配置保存策略,有三种策略:
-
always:每次执行写操作都会保存一次
-
everysec:每秒保存一次(默认配置),这样就算丢失数据也只会丢一秒以内的数据
-
no:看系统心情保存
可以在配置文件中配置:
# 注意得改成也是
appendonly yes
# appendfsync always
appendfsync everysec
# appendfsync no重启服务器后,可以看到服务器目录下多了一个appendonly.aof文件,存储的就是我们执行的命令。
AOF的缺点也很明显,每次服务器启动都需要进行过程重演,相比RDB更加耗费时间,并且随着我们的操作变多,不断累计,可能到最后我们的aof文件会变得无比巨大,我们需要一个改进方案来优化这些问题。
Redis有一个AOF重写机制进行优化,比如我们执行了这样的语句:
lpush test 666
lpush test 777
lpush test 888实际上用一条语句也可以实现:
lpush test 666 777 888正是如此,只要我们能够保证最终的重演结果和原有语句的结果一致,无论语句如何修改都可以,所以我们可以通过这种方式将多条语句进行压缩。
我们可以输入命令来手动执行重写操作:
bgrewriteaof或是在配置文件中配置自动重写:
# 百分比计算,这里不多介绍
auto-aof-rewrite-percentage 100
# 当达到这个大小时,触发自动重写
auto-aof-rewrite-min-size 64mb至此,我们就完成了两种持久化方案的介绍,最后我们再来进行一下总结:
-
AOF:
-
优点:存储速度快、消耗资源少、支持实时存储
-
缺点:加载速度慢、数据体积大
-
-
RDB:
-
优点:加载速度快、数据体积小
-
缺点:存储速度慢大量消耗资源、会发生数据丢失
-
ok,今天就先讲到这,下课!