前言
在Java集合框架中,HashMap和TreeMap是Map接口下最常用的两个实现类,二者都能存储键值对数据,但底层结构、性能特性和适用场景差异极大。很多开发者在选择时容易凭经验"随便用",导致项目出现性能瓶颈或功能异常------比如需要排序时用了HashMap,不得不额外写排序逻辑;追求高效查询时用了TreeMap,浪费了不必要的性能开销。本文将从底层原理、核心差异、代码示例三个维度,帮你彻底搞懂"什么时候该用HashMap,什么时候该用TreeMap"。
一、先搞懂底层:为什么二者差异这么大?
选择工具前,必须先理解它的"构造原理"。HashMap和TreeMap的核心区别,根源在于底层数据结构的不同------一个靠"哈希表"实现高效查询,一个靠"红黑树"实现有序存储。
1. HashMap:基于哈希表,追求"快"
HashMap的底层是数组+链表/红黑树(JDK 1.8优化后),核心逻辑是"通过哈希值定位数据位置":
•存储时,先计算键(Key)的哈希值,再通过哈希算法确定该键值对在数组中的索引位置;
•如果索引位置没有数据,直接存入;如果有数据(哈希冲突),则用链表或红黑树(当链表长度超过8时)串联存储;
•查询时,同样通过键的哈希值快速定位到索引位置,再遍历链表/红黑树找到目标数据------理想情况下,查询、插入、删除的时间复杂度都是O(1),这是它"快"的核心原因。
但要注意:HashMap的键值对是无序存储的,遍历结果既不保证按插入顺序,也不保证按键的自然顺序(比如整数的1、2、3,字符串的A、B、C)。
2. TreeMap:基于红黑树,追求"有序"
TreeMap的底层是红黑树(一种自平衡的二叉搜索树),核心逻辑是"通过键的比较维持有序结构":
•存储时,会根据键的大小关系(默认是自然顺序,也可自定义比较器)将键值对插入红黑树的对应位置,确保树始终是有序的;
•查询、插入、删除时,都需要通过二叉搜索树的特性遍历节点,时间复杂度稳定为O(log n)------比HashMap的理想情况慢,但胜在"有序";
•遍历TreeMap时,会按照键的排序规则输出结果,无需额外排序操作。
这里的"有序"是TreeMap的核心优势,但代价是牺牲了部分性能------红黑树的平衡维护需要额外的计算开销。
二、核心差异对比:5个维度帮你快速判断
理解底层后,我们从实际开发中最关注的5个维度,对比HashMap和TreeMap的差异,这是选择的直接依据:
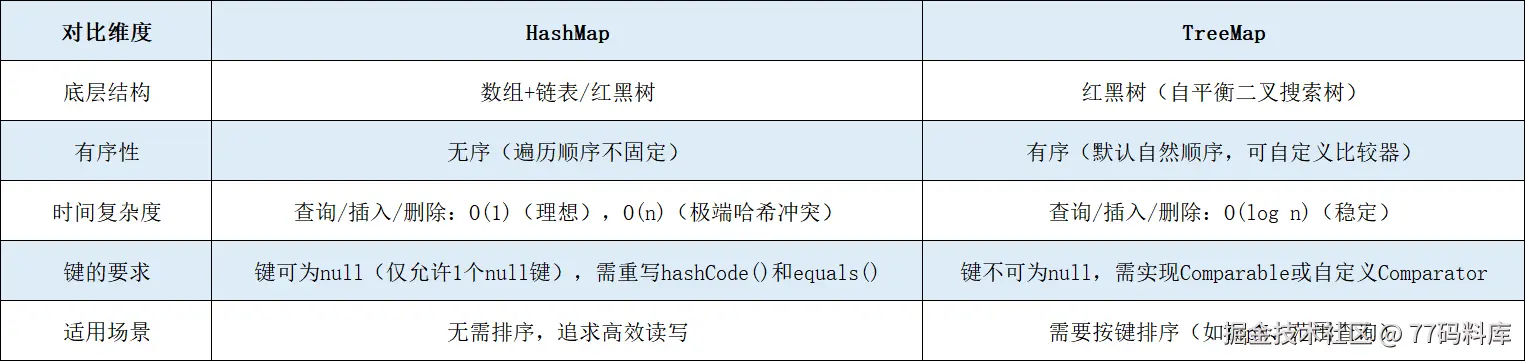
这里有两个关键细节需要特别注意:
• HashMap的null键问题 :HashMap允许键为null,但只能有1个(因为null的哈希值固定为0,重复插入会覆盖);而TreeMap的键不能为null,否则会抛出NullPointerException(因为无法比较null和其他键的大小)。
• 键的方法重写 :使用HashMap时,键的类必须重写hashCode()和equals()方法(否则无法正确判断键的唯一性,会导致重复存储);TreeMap则不需要重写这两个方法,因为它通过Comparable或Comparator判断键的唯一性(比较结果为0即认为是同一个键)。
三、代码示例:从场景看选择
理论不如实践,下面通过4个典型场景的代码示例,带你直观感受"该用哪个"。
场景1:普通业务存储,无需排序------选HashMap
需求 :存储用户ID和用户名的映射关系,只需根据用户ID快速查询用户名,无需排序。 这种场景是HashMap的"主场",因为无需有序性,追求的是高效读写。
java
import java.util.HashMap;
import java.util.Map;
public class HashMapDemo {
public static void main(String[] args) {
// 1. 创建HashMap,存储<用户ID, 用户名>
Map<Integer, String> userMap = new HashMap<>();
// 2. 插入数据(时间复杂度O(1))
userMap.put(103, "张三");
userMap.put(101, "李四");
userMap.put(102, "王五");
userMap.put(104, "赵六");
// 3. 快速查询(根据ID查用户名,时间复杂度O(1))
String userName = userMap.get(102);
System.out.println("用户102的名字:" + userName); // 输出:用户102的名字:王五
// 4. 遍历(注意:无序,输出顺序可能与插入顺序不同)
System.out.println("\n遍历HashMap(无序):");
for (Map.Entry<Integer, String> entry : userMap.entrySet()) {
System.out.println("ID:" + entry.getKey() + ",名字:" + entry.getValue());
}
// 可能的输出顺序:101-李四、102-王五、103-张三、104-赵六(顺序不固定)
}
}结果分析 :HashMap的插入和查询都非常快,适合普通的键值对存储场景。但遍历结果无序,如果业务不需要排序,这完全不是问题;如果强行用TreeMap,反而会因为红黑树的维护开销,导致性能下降。
场景2:需要按键自然排序------选TreeMap
需求 :存储学生的学号(整数)和成绩的映射关系,要求遍历输出时按学号从小到大排序。 这种场景需要"键的自然顺序",TreeMap无需额外处理,直接满足需求。
java
import java.util.Map;
import java.util.TreeMap;
public class TreeMapNaturalOrderDemo {
public static void main(String[] args) {
// 1. 创建TreeMap,存储<学号, 成绩>(默认按键的自然顺序排序)
Map<Integer, Integer> studentScoreMap = new TreeMap<>();
// 2. 插入数据(时间复杂度O(log n))
studentScoreMap.put(2023003, 88);
studentScoreMap.put(2023001, 95);
studentScoreMap.put(2023002, 76);
studentScoreMap.put(2023004, 92);
// 3. 查询数据(时间复杂度O(log n))
Integer score = studentScoreMap.get(2023002);
System.out.println("学号2023002的成绩:" + score); // 输出:学号2023002的成绩:76
// 4. 遍历(按键的自然顺序排序,即学号从小到大)
System.out.println("\n遍历TreeMap(按学号升序):");
for (Map.Entry<Integer, Integer> entry : studentScoreMap.entrySet()) {
System.out.println("学号:" + entry.getKey() + ",成绩:" + entry.getValue());
}
// 固定输出顺序:2023001-95、2023002-76、2023003-88、2023004-92
}
}结果分析 :TreeMap在插入时自动按键的自然顺序(整数从小到大)维护结构,遍历直接得到有序结果。如果用HashMap,则需要先把键存入List,再调用Collections.sort()排序,多一步操作且效率更低。
场景3:需要自定义键的排序规则------选TreeMap
需求 :存储商品的名称(字符串)和价格的映射关系,要求按价格从高到低排序(自定义排序规则,而非键的自然顺序)。 TreeMap支持通过Comparator自定义排序规则,完美解决这类需求。
java
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
public class TreeMapCustomOrderDemo {
public static void main(String[] args) {
// 1. 创建TreeMap,自定义排序规则:按价格降序(Value降序)
Map<String, Double> productPriceMap = new TreeMap<>(
new Comparator<String>() {
@Override
public int compare(String productName1, String productName2) {
// 先获取两个商品的价格
double price1 = productPriceMap.get(productName1);
double price2 = productPriceMap.get(productName2);
// 按价格降序:price2 - price1(如果price2大,返回正数,即productName2排在前面)
return Double.compare(price2, price1);
}
}
);
// 2. 插入商品数据
productPriceMap.put("手机", 5999.0);
productPriceMap.put("笔记本电脑", 8999.0);
productPriceMap.put("平板", 3299.0);
productPriceMap.put("耳机", 899.0);
// 3. 遍历(按价格降序输出)
System.out.println("遍历TreeMap(按价格降序):");
for (Map.Entry<String, Double> entry : productPriceMap.entrySet()) {
System.out.println("商品:" + entry.getKey() + ",价格:" + entry.getValue() + "元");
}
// 固定输出顺序:笔记本电脑-8999.0、手机-5999.0、平板-3299.0、耳机-899.0
}
}结果分析 :通过自定义Comparator,TreeMap实现了"按值排序"(实际是通过值反推键的排序关系)。这种场景下,HashMap完全无法直接满足,必须额外写复杂的排序逻辑,而TreeMap一行代码就能搞定排序规则。
场景4:需要范围查询或TopN------选TreeMap
需求 :存储员工的工号(整数)和薪资的映射关系,要求查询"工号在2023002到2023004之间的员工薪资"(范围查询),以及"薪资最高的2名员工"(TopN)。 TreeMap提供了subMap()、headMap()、tailMap()等方法,专门用于范围查询,而HashMap需要遍历所有数据才能实现,效率极低。
java
import java.util.Map;
import java.util.TreeMap;
public class TreeMapRangeQueryDemo {
public static void main(String[] args) {
// 1. 创建TreeMap,存储<工号, 薪资>(默认按工号升序)
Map<Integer, Integer> empSalaryMap = new TreeMap<>();
empSalaryMap.put(2023001, 15000);
empSalaryMap.put(2023002, 18000);
empSalaryMap.put(2023003, 22000);
empSalaryMap.put(2023004, 16000);
empSalaryMap.put(2023005, 25000);
// 2. 范围查询:工号在2023002(含)到2023004(含)之间的员工
Map<Integer, Integer> rangeMap = ((TreeMap<Integer, Integer>) empSalaryMap).subMap(2023002, true, 2023004, true);
System.out.println("工号2023002-2023004的员工薪资:");
for (Map.Entry<Integer, Integer> entry : rangeMap.entrySet()) {
System.out.println("工号:" + entry.getKey() + ",薪资:" + entry.getValue() + "元");
}
// 输出:2023002-18000、2023003-22000、2023004-16000
// 3. TopN查询:薪资最高的2名员工(先按薪资降序,再取前2个)
// 方式:创建反向排序的TreeMap(按工号降序,间接对应薪资排序,实际项目中可按薪资排序)
Map<Integer, Integer> reverseMap = new TreeMap<>(Comparator.reverseOrder());
reverseMap.putAll(empSalaryMap);
System.out.println("\n薪资最高的2名员工:");
int count = 0;
for (Map.Entry<Integer, Integer> entry : reverseMap.entrySet()) {
if (count >= 2) break;
System.out.println("工号:" + entry.getKey() + ",薪资:" + entry.getValue() + "元");
count++;
}
// 输出:2023005-25000、2023003-22000
}
}结果分析 :TreeMap的subMap()方法能快速定位到范围边界,时间复杂度O(log n + k)(k是范围中的元素个数),而HashMap需要遍历所有元素(O(n)),数据量大时性能差距会非常明显。对于TopN场景,TreeMap的有序特性也能减少排序开销。
四、总结:3步决定用HashMap还是TreeMap
看完底层原理和代码示例,我们可以总结出一个"3步选择法",帮你在实际开发中快速做决定:
第一步:判断是否需要"有序"
•如果不需要有序(仅需存储和快速查询):直接选HashMap,它的读写性能更优;
•如果需要有序(按键自然排序、自定义排序、范围查询、TopN):选TreeMap,它能原生支持有序操作,避免额外开发。
第二步:检查键的特性
•如果键需要为null:只能选HashMap(TreeMap不允许null键);
•如果键的类没有重写hashCode()和equals():优先选TreeMap(HashMap会出现键重复问题);
•如果键的比较逻辑复杂(需要自定义):选TreeMap(通过Comparator轻松实现)。
第三步:评估性能需求
•如果数据量小(万级以下):HashMap和TreeMap性能差距不大,可根据有序性选择;
•如果数据量大(十万级以上):
◦无需有序:必须选HashMap,O(1)的时间复杂度能大幅提升效率;
◦需要有序:只能选TreeMap,但要注意红黑树的维护开销,避免频繁插入删除(可考虑批量操作)。
最后记住一句话:"无排序用HashMap,要排序用TreeMap"------这是最核心的选择原则。只有根据业务场景选择合适的集合,才能写出高效、简洁的代码,避免踩不必要的坑。
好啦,先给大家分享到这吧,大家觉得对自己有帮助的可以支持一下,留个关注和大拇指吧!