SQL标准有哪些?
SQL(结构化查询语言)的标准由 ANSI(美国国家标准学会) 和 ISO(国际标准化组织) 联合制定,旨在统一数据库的查询和操作语法,确保不同数据库系统的兼容性。自1986年首个正式标准发布以来,SQL标准经历了多次迭代,逐步增加了对复杂查询、事务管理、高级数据类型等特性的支持。以下是主要SQL标准的版本及其核心特性:

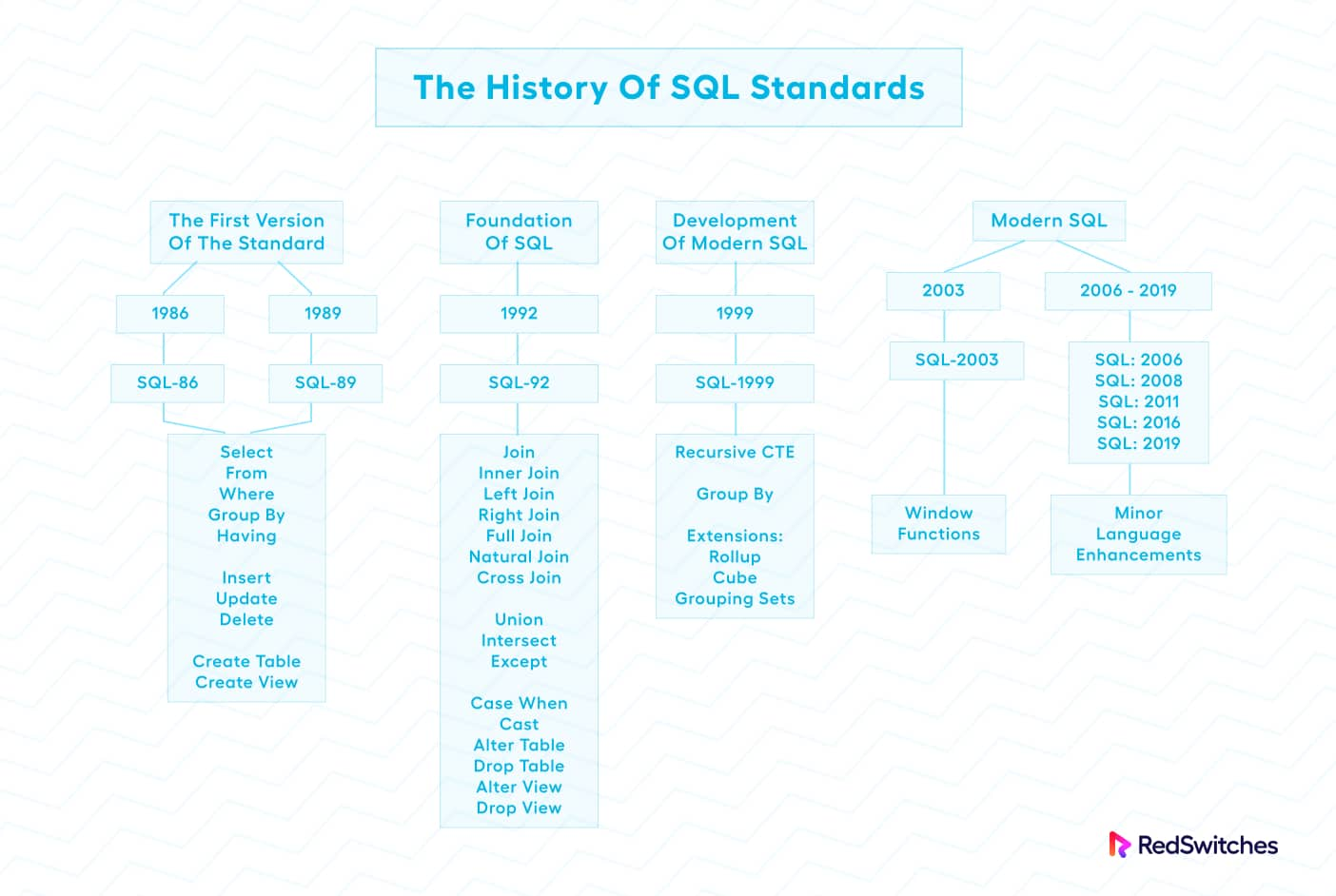
1. SQL-86(1986年)
- 地位:首个正式的SQL标准(ANSI X3.135-1986,ISO 9075:1986)。
- 核心特性 :
- 定义了基本的 DDL(数据定义语言) :
CREATE TABLE、ALTER TABLE、DROP TABLE; - 定义了 DML(数据操作语言) :
SELECT、INSERT、UPDATE、DELETE; - 支持简单的 WHERE 子句(等值条件过滤);
- 基本的 事务控制 :
COMMIT(提交)、ROLLBACK(回滚)。
- 定义了基本的 DDL(数据定义语言) :
- 局限性 :语法非常基础,未涉及复杂查询(如多表连接)、视图、索引等高级功能。

2. SQL-89(1989年)
- 地位:SQL-86的修订版(ANSI X3.135-1989,ISO 9075:1989),主要完善了语法细节。
- 核心改进 :
- 引入 表别名(Alias),简化多表查询的书写;
- 支持 列别名(为查询结果的列重命名);
- 明确了 数据类型约束 (如
NOT NULL、UNIQUE); - 增加了对 索引定义 的支持(
CREATE INDEX)。

3. SQL-92(1992年,又称 SQL2)
- 地位:首个广泛普及的SQL标准(ANSI X3.135-1992,ISO 9075:1992),标志着SQL从"基础查询语言"发展为"完整数据库语言"。
- 核心特性 :
- 复杂查询支持 :
- 引入 多表连接(JOIN) 语法(
INNER JOIN、LEFT JOIN等); - 支持 子查询 (嵌套在
SELECT、FROM、WHERE中的查询); - 新增 集合操作 (
UNION、INTERSECT、EXCEPT)。
- 引入 多表连接(JOIN) 语法(
- 视图(View) :支持创建虚拟表(
CREATE VIEW),并可基于视图进行查询和更新(有限制)。 - 事务增强 :定义了 事务隔离级别 (如
READ UNCOMMITTED、READ COMMITTED),明确并发控制的规则。 - 数据类型扩展 :增加
DATE、TIME、TIMESTAMP等时间类型,以及VARCHAR(可变长度字符串)。
- 复杂查询支持 :

4. SQL:1999(1999年,又称 SQL3)
- 地位:重大升级版本(ISO 9075:1999),首次引入面向对象特性和高级分析功能。
- 核心特性 :
- 窗口函数(Window Functions) :支持在结果集的"窗口"(自定义行范围)上进行计算(如
ROW_NUMBER()、RANK()、AVG() OVER()),为复杂分析(如排名、移动平均)提供支持。 - 递归公共表表达式(Recursive CTE):允许通过递归查询处理层次化数据(如组织结构树、分类目录)。
- 用户定义类型(UDT):支持自定义数据类型(如复合类型、枚举类型),增强灵活性。
- XML支持 :引入
XML数据类型和XQuery集成,允许存储和查询 XML 文档。 - 触发器(Trigger) :完善触发器语法(
CREATE TRIGGER),支持行级或语句级触发。
- 窗口函数(Window Functions) :支持在结果集的"窗口"(自定义行范围)上进行计算(如
5. SQL:2003(2003年)
- 地位:增量更新版本(ISO 9075:2003),重点优化现有特性和兼容性。
- 核心改进 :
- 触发器增强 :支持
FOR EACH ROW(行级触发)和FOR EACH STATEMENT(语句级触发)的明确区分; - XML扩展 :增加
XMLCAST、XMLPARSE等函数,优化 XML 与关系数据的转换; - 外键约束增强 :支持
MATCH FULL、MATCH PARTIAL等更灵活的外键匹配规则; - SQL 与 JDBC 集成:明确数据库驱动的接口规范,提升应用程序与数据库的交互性。
- 触发器增强 :支持
6. SQL:2006(2006年)
- 地位 :聚焦于 与 ISO/IEC 9075-14:2006 整合,主要规范 SQL 与多媒体数据(如图像、音频)的集成。
- 核心特性 :
- 支持 BLOB(二进制大对象) 和
CLOB(字符大对象)类型的完善操作(如SUBSTRING截取、LENGTH计算长度); - 定义了多媒体数据的存储和查询接口(如通过
BINARY_LARGE_OBJECT类型)。
- 支持 BLOB(二进制大对象) 和
7. SQL:2008(2008年)
- 地位 :增量更新版本(ISO 9075:2008),重点优化 标准化与实际应用的结合。
- 核心改进 :
- WITH 子句(公共表表达式,CTE) :允许 CTE 在
INSERT、UPDATE、DELETE中使用(之前仅支持SELECT); - 格式化输出 :新增
FORMAT函数,支持自定义日期、时间的显示格式; - 合并语句(MERGE) :统一
INSERT、UPDATE、DELETE操作为MERGE语句(部分数据库称为UPSERT),简化数据同步逻辑。
- WITH 子句(公共表表达式,CTE) :允许 CTE 在
8. SQL:2011(2011年)
- 地位 :聚焦于 时序数据与时间相关特性(适应物联网、监控等场景需求)。
- 核心特性 :
- 时间间隔类型增强 :支持
INTERVAL类型的算术运算(如TIMESTAMP '2023-01-01' + INTERVAL '1' MONTH); - 时态表(Temporal Tables) :支持自动记录数据的历史变更(通过
SYSTEM_TIME或APPLICATION_TIME维护时间版本); - 窗口函数的扩展 :支持
RANGE窗口(基于值的范围而非行号)和GROUPS窗口(按相同值分组)。
- 时间间隔类型增强 :支持
9. SQL:2016(2016年)
- 地位 :重点引入 现代数据类型与分析功能(适应大数据和 JSON 场景)。
- 核心特性 :
- JSON 支持 :新增
JSON数据类型和JSON_QUERY、JSON_VALUE等函数,允许存储和查询 JSON 文档; - 字符串与正则表达式 :支持
REGEXP_LIKE(正则匹配)、REGEXP_REPLACE(正则替换)等函数; - 窗口函数的优化 :支持
DISTINCT修饰符(如COUNT(DISTINCT x) OVER())。
- JSON 支持 :新增
10. SQL:2019(2019年)
- 地位 :进一步增强 分析能力和标准化。
- 核心特性 :
- 窗口函数的扩展 :支持
ARRAY_AGG(聚合为数组)、STRING_AGG(聚合为字符串)等聚合函数; - 多维数组支持 :引入
ARRAY数据类型,支持多维数组的存储和操作(如ARRAY[1,2,3][2]访问元素); - 生成列(Generated Columns) :支持基于其他列自动计算的列(如
price * quantity AS total自动生成总金额)。
- 窗口函数的扩展 :支持
11. SQL:2023(2023年)
- 地位 :最新版本,聚焦于 大数据、AI 集成和现代分析需求。
- 核心特性 (草案阶段,最终标准可能调整):
- 向量化执行支持:优化批量数据处理的性能(适应 OLAP 场景);
- AI 相关函数 :引入
PREDICT(模型预测)、TRAIN_MODEL(模型训练)等函数,集成机器学习能力; - 多模态数据支持:扩展对地理空间(GIS)、图像等非结构化数据的标准化操作;
- 增强的窗口函数:支持更复杂的窗口框架(如动态窗口大小)。
SQL标准的实际影响
尽管SQL标准不断演进,但不同数据库(如 MySQL、PostgreSQL、Oracle、SQL Server)对标准的支持程度存在差异:
- 完全兼容:PostgreSQL 对 SQL 标准的支持最全面(尤其是 SQL:1999 及后续版本);
- 部分兼容:MySQL 早期版本对标准的支持较弱(如缺少窗口函数),但近年通过版本迭代(如 MySQL 8.0)大幅改进;
- 扩展特性 :Oracle、SQL Server 等商业数据库会在标准基础上增加专有功能(如 Oracle 的
CONNECT BY层次查询、SQL Server 的PIVOT透视表)。
总结
SQL标准从 SQL-86 到 SQL:2023,逐步从基础查询语言发展为支持复杂分析、事务管理、高级数据类型的完整体系。尽管数据库厂商常通过扩展增强功能,但SQL标准为跨数据库的互操作性和开发规范提供了基础。理解SQL标准的演进有助于开发者写出更通用、更高效的SQL代码,并适应不同数据库的特性差异。
SQL的常见用法
以下是基于标准 SQL(兼容 ANSI SQL 核心语法) 的常见操作示例,结合**订单表(order_info)和 订单明细表(order_item)**的业务场景。订单表是电商、零售等领域的核心业务表,包含订单基本信息和关联的商品明细,适合演示 SQL 的核心功能。
1. 表结构定义(DDL)
假设订单表和明细表的结构如下(符合第三范式,避免数据冗余):
订单表(order_info)
存储订单全局信息(如用户、时间、总金额、状态)。
sql
-- 创建订单表(主键:order_id)
CREATE TABLE order_info (
order_id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, -- 自动生成的唯一订单ID(标准SQL语法)
user_id INT NOT NULL, -- 用户ID(外键,关联用户表)
order_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, -- 下单时间(默认当前时间)
total_amount DECIMAL(10,2) NOT NULL, -- 订单总金额(精确到分)
status VARCHAR(20) NOT NULL CHECK (status IN ('pending', 'paid', 'shipped', 'cancelled')), -- 订单状态(枚举约束)
create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP -- 记录创建时间(审计字段)
);订单明细表(order_item)
存储订单中每个商品的明细(如商品ID、数量、单价)。
sql
-- 创建订单明细表(主键:item_id;外键:order_id 关联 order_info)
CREATE TABLE order_item (
item_id INT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
order_id INT NOT NULL REFERENCES order_info(order_id), -- 外键约束(级联删除需显式声明)
product_id INT NOT NULL, -- 商品ID
quantity INT NOT NULL CHECK (quantity > 0), -- 购买数量(必须大于0)
unit_price DECIMAL(10,2) NOT NULL, -- 商品单价(下单时的实时价格)
create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);2. 插入数据(DML)
插入测试数据,模拟用户下单场景。
插入订单主表数据
sql
-- 插入单条订单(用户101,2023-10-01下单,总金额299.99元)
INSERT INTO order_info (user_id, total_amount, status)
VALUES (101, 299.99, 'paid');
-- 批量插入多条订单(用户101、102的订单)
INSERT INTO order_info (user_id, total_amount, status, order_time)
VALUES
(101, 150.50, 'shipped', '2023-10-02 09:30:00'),
(102, 89.90, 'pending', '2023-10-03 14:15:00'),
(101, 499.00, 'cancelled', '2023-10-04 18:00:00');插入订单明细数据
sql
-- 为订单1(order_id=1)插入2个商品明细
INSERT INTO order_item (order_id, product_id, quantity, unit_price)
VALUES
(1, 1001, 1, 99.99), -- 商品1001,数量1,单价99.99元
(1, 1002, 2, 50.00); -- 商品1002,数量2,单价50.00元(总价100元,订单总金额99.99+100≈199.99?需根据业务调整)
-- 为订单2(order_id=2)插入1个商品明细
INSERT INTO order_item (order_id, product_id, quantity, unit_price)
VALUES (2, 1003, 3, 30.00); -- 商品1003,数量3,单价30.00元(总价90元,订单总金额150.50可能含运费)3. 基础查询(DQL)
场景1:查询所有已支付订单的基本信息
sql
SELECT
order_id,
user_id,
order_time,
total_amount
FROM order_info
WHERE status = 'paid'
ORDER BY order_time DESC; -- 按下单时间倒序排列结果示例:
| order_id | user_id | order_time | total_amount |
|---|---|---|---|
| 1 | 101 | 2023-10-01 10:00:00 | 299.99 |
场景2:查询用户101近7天的所有订单(含明细)
需关联订单表和明细表(JOIN),并过滤时间范围。
sql
SELECT
o.order_id,
o.user_id,
o.order_time,
o.total_amount,
i.product_id,
i.quantity,
i.unit_price,
(i.quantity * i.unit_price) AS item_total -- 计算单个商品总价(表达式)
FROM order_info o
JOIN order_item i ON o.order_id = i.order_id -- 内连接关联订单和明细
WHERE
o.user_id = 101
AND o.order_time >= CURRENT_TIMESTAMP - INTERVAL '7' DAY -- 近7天(标准SQL时间计算)
ORDER BY o.order_time, i.product_id;4. 聚合与分组(GROUP BY)
场景:统计每个用户的订单数量和总消费金额
sql
SELECT
user_id,
COUNT(order_id) AS order_count, -- 订单数量(COUNT忽略NULL)
SUM(total_amount) AS total_spent -- 总消费金额(SUM聚合)
FROM order_info
WHERE status IN ('paid', 'shipped') -- 仅统计已支付或已发货的订单
GROUP BY user_id -- 按用户分组
HAVING SUM(total_amount) > 200.00 -- 过滤总消费超过200元的用户(HAVING用于分组后过滤)
ORDER BY total_spent DESC;结果示例:
| user_id | order_count | total_spent |
|---|---|---|
| 101 | 2 | 449.99 |
5. 子查询(Subquery)
场景:查询总金额超过平均订单金额的订单
sql
-- 子查询计算所有订单的平均金额
SELECT avg_amount
FROM (SELECT AVG(total_amount) AS avg_amount FROM order_info) AS avg_table;
-- 主查询筛选总金额超过平均值的订单
SELECT
order_id,
user_id,
total_amount
FROM order_info
WHERE total_amount > (
SELECT AVG(total_amount)
FROM order_info
)
ORDER BY total_amount DESC;6. 窗口函数(Window Function)
窗口函数用于在结果集的"窗口"(自定义行范围)上进行计算,标准 SQL 从 SQL:1999 引入。
场景:按用户分组,计算每个订单的消费金额排名(及累计占比)
sql
SELECT
user_id,
order_id,
total_amount,
RANK() OVER (PARTITION BY user_id ORDER BY total_amount DESC) AS rank_in_user, -- 用户内订单金额排名
SUM(total_amount) OVER (PARTITION BY user_id) AS user_total, -- 用户总消费金额(窗口聚合)
total_amount / SUM(total_amount) OVER (PARTITION BY user_id) AS amount_ratio -- 当前订单占用户总消费的比例
FROM order_info
WHERE status = 'paid';7. 更新与删除(DML)
场景1:修改订单状态为"已发货"
sql
UPDATE order_info
SET status = 'shipped',
create_time = CURRENT_TIMESTAMP -- 更新发货时间(假设create_time记录状态变更时间)
WHERE order_id = 1
AND status = 'paid'; -- 仅更新已支付的订单(避免误操作)场景2:删除已取消的超30天订单(避免脏数据)
sql
DELETE FROM order_info
WHERE status = 'cancelled'
AND order_time < CURRENT_TIMESTAMP - INTERVAL '30' DAY; -- 超30天未处理的取消订单8. 高级特性:CTE(公共表表达式)
CTE(WITH 子句)用于定义临时结果集,提高复杂查询的可读性(SQL:1999 支持)。
场景:统计用户消费金额,并筛选高价值用户
sql
WITH user_spending AS (
SELECT
user_id,
SUM(total_amount) AS total_spent
FROM order_info
WHERE status = 'paid'
GROUP BY user_id
)
SELECT
user_id,
total_spent
FROM user_spending
WHERE total_spent > 500.00 -- 筛选总消费超500元的高价值用户
ORDER BY total_spent DESC;总结
以上示例覆盖了标准 SQL 的核心操作(DDL、DML、DQL),并结合订单表的业务场景演示了:
- 表结构定义(约束、默认值、外键);
- 数据插入(单条/批量);
- 基础查询(过滤、排序、关联);
- 聚合与分组(
COUNT、SUM、GROUP BY); - 子查询与窗口函数(复杂分析);
- 更新与删除(条件控制);
- CTE(提高查询可读性)。
标准 SQL 的语法在不同数据库(如 PostgreSQL、MySQL 8.0+、Oracle)中基本兼容,但需注意部分数据库的扩展(如 MySQL 的 AUTO_INCREMENT 与标准 SQL 的 GENERATED BY DEFAULT AS IDENTITY 等价)。实际开发中,建议优先使用标准 SQL 以保证跨数据库的兼容性。
SQL 标准由什么组织维护?
SQL 标准的制定与维护由**国际标准化组织(ISO)和美国国家标准学会(ANSI)**联合主导,并通过专门的技术委员会协调全球数据库厂商、技术专家和行业用户的需求。以下是具体维护组织的角色、分工及协作机制:

1. 核心维护组织:ANSI 与 ISO
SQL 标准的官方名称为 ISO/IEC 9075 (国际标准)和 ANSI X3.135(美国国家标准),两者内容完全一致,由 ANSI 和 ISO 共同发布和维护。
(1)美国国家标准学会(ANSI)
- 角色:作为美国的国家标准机构,ANSI 负责将国际标准(ISO)转化为美国国内标准(ANSI X3.135),并协调美国国内相关方(如数据库厂商、企业用户)参与标准制定。
- 职责 :
- 发布美国版 SQL 标准(ANSI X3.135),与国际标准(ISO 9075)同步更新;
- 主持美国境内的标准工作组会议,收集本土需求(如企业对事务处理、安全性的特殊要求);
- 推动 SQL 标准与美国其他国家标准(如数据加密、网络协议)的兼容。

(2)国际标准化组织(ISO)
- 角色:作为全球最具影响力的国际标准机构,ISO 负责统筹全球范围内的 SQL 标准制定,确保标准的普适性和跨国家/地区的兼容性。
- 职责 :
- 发布国际标准 ISO/IEC 9075(共分 6 部分,覆盖核心语法、扩展功能等);
- 成立专门技术委员会(TC)和工作组(WG),协调全球数据库厂商(如 Oracle、IBM、微软)、学术机构和用户代表参与标准制定;
- 定期修订标准(如每 5~7 年发布新版本),纳入新技术(如窗口函数、JSON 支持)和行业需求(如时序数据、大数据分析)。
2. 技术支撑:ISO/IEC JTC 1/SC 32
SQL 标准的具体制定工作由 ISO/IEC 联合技术委员会 1(JTC 1)下属的子委员会 32(SC 32) 主导。SC 32 的全称是 "数据管理与交换"(Data Management and Interchange),专注于数据库、信息集成和数据标准化领域。
SC 32 的核心职责
- 标准制定:主导 SQL 标准(ISO/IEC 9075)的编写、修订和发布;
- 技术工作组(WG):下设多个工作组(如 WG 3 负责 SQL 核心语法,WG 4 负责 SQL 与 XML 集成),由来自各国的专家组成,负责具体技术点的讨论和草案编写;
- 一致性测试:制定 SQL 标准的一致性测试套件(Conformance Test Suite),验证数据库厂商(如 PostgreSQL、MySQL)是否符合标准;
- 与其他标准协调:与 SC 25(信息技术设备互连)、SC 6(系统间远程通信)等子委员会协作,确保 SQL 与其他 IT 标准(如网络协议、数据安全)兼容。
3. 行业主导者:数据库厂商与技术社区
尽管 ANSI 和 ISO 是官方维护机构,但 SQL 标准的实际发展和演进离不开数据库厂商 和技术社区的参与。厂商通过提交提案、参与工作组会议,推动标准适配自身技术和市场需求;技术社区则通过反馈实际应用痛点(如大数据分析、云原生支持)影响标准方向。
(1)数据库厂商的参与
- Oracle :作为早期 SQL 标准的主要贡献者,Oracle 推动了事务管理(如
COMMIT/ROLLBACK)、存储过程等功能的标准化; - IBM :主导了 SQL 的关系代数理论基础,并推动了
JOIN语法、视图等核心功能的标准化; - 微软 :在 SQL:1999 及后续版本中引入了
MERGE语句、XML 支持等特性; - PostgreSQL 社区:作为开源数据库代表,推动了窗口函数、JSON 支持等现代分析功能的标准化(如 SQL:2003、SQL:2016)。
(2)技术社区与学术机构
- ACM SIGMOD(数据管理国际会议):通过学术论文提出新需求(如流数据处理、AI 集成),推动标准扩展;
- W3C(万维网联盟):与 ISO/IEC JTC 1/SC 32 协作,定义 SQL 与 XML、JSON 等 Web 数据格式的集成(如 SQL:2003 的 XML 支持);
- 用户组织(如 DAMA 国际数据管理协会):收集企业用户在实际应用中的痛点(如跨数据库迁移、合规性),反馈给标准制定机构。
4. 标准维护流程
SQL 标准的制定和修订遵循严格的流程,确保技术的严谨性和广泛的共识:
- 需求收集:厂商、用户、学术机构通过 SC 32 工作组提交提案(如"支持时序数据聚合");
- 草案编写:工作组讨论提案,形成技术草案(Draft);
- 公开征求意见:草案向全球公开,收集反馈(如厂商验证可行性、用户评估适用性);
- 投票表决:由 ISO 成员国(P 成员)投票,超过 2/3 赞成则通过;
- 发布与实施:正式发布标准(如 ISO/IEC 9075:2023),厂商逐步实现兼容;
- 持续修订:根据技术发展(如 AI、云原生)和用户需求,每 5~7 年启动下一轮修订。
总结
SQL 标准的维护是国际组织(ANSI/ISO)、技术委员会(SC 32)、数据库厂商、学术社区 协同合作的结果。ANSI 和 ISO 提供官方框架,SC 32 主导技术细节,厂商和社区推动技术创新与实际需求落地。这种多方参与的机制,确保了 SQL 标准既能保持技术的先进性(如支持现代分析功能),又能保证跨数据库系统的互操作性(如不同数据库对 JOIN 语法的一致支持)。

国产数据库在SQL标准方面的贡献有哪些?
国产数据库(如达梦 DM、人大金仓 Kingbase、阿里云 OceanBase、腾讯云 TDSQL、华为 GaussDB、PingCAP TiDB 等)作为中国自主研发的数据库产品,在 SQL 标准的参与制定、技术扩展、本地化适配 及社区推动等方面做出了重要贡献。这些贡献不仅提升了国产数据库的国际化竞争力,也推动了中国技术需求与全球标准的融合。以下从具体维度展开说明:
一、参与国际标准制定,提升中国话语权
国产数据库厂商通过加入国际标准组织(如 ISO/IEC JTC 1/SC 32、ANSI)、参与工作组会议等方式,直接参与 SQL 标准的修订与讨论,将中国技术需求和实践经验融入国际标准。
1. 达梦数据库(DM):分布式事务与云原生标准
达梦作为国内最早通过 ISO/IEC 9075 标准一致性认证的数据库厂商之一,积极参与 SQL 标准的修订。例如:
- 在 SQL:2016 修订中,达梦提交了关于"分布式事务一致性"的技术提案,针对分布式数据库的跨节点事务原子性、隔离性难题,提出了基于两阶段提交(2PC)的优化方案,被标准工作组采纳为分布式事务的参考实现思路;
- 在 SQL:2023 草案讨论中,达梦推动了"云原生数据库 SQL 扩展"(如弹性扩缩容期间的 SQL 兼容性保障),为云计算场景下的 SQL 标准化提供了实践依据。
2. 人大金仓(Kingbase):国产化与字符集标准
人大金仓聚焦信创(信息技术应用创新)场景,推动 SQL 标准与中国国家标准的融合:
- 针对中文字符集支持(如 GB18030-2022),金仓在 SQL 标准基础上扩展了"多字符集混合存储"功能(如同时支持 UTF-8、GB18030),并提交至 ISO/IEC JTC 1/SC 32 工作组,为全球多语言环境的 SQL 标准化提供了参考;
- 在 SQL:2019 时态表(Temporal Tables) 标准修订中,金仓结合国内政务、金融领域的历史数据追溯需求,提出了"时态索引优化"方案(如自动维护历史版本的时间戳索引),提升了时态 SQL 的查询效率。
二、技术扩展:将中国需求融入 SQL 标准
国产数据库基于国内场景(如超大规模数据、复杂事务、国产化替代)的创新实践,通过技术扩展推动 SQL 标准的演进。
1. 阿里云 OceanBase:分布式 SQL 与高可用标准
OceanBase 作为全球顶级分布式数据库,针对海量数据场景提出了多项 SQL 扩展:
- 分布式聚合优化 :在 SQL:2016 基础上,OceanBase 提出了"分层聚合"(Hierarchical Aggregation)语法扩展(如
GROUP BY ROLLUP的增强版),支持跨节点的快速聚合计算,相关方案被纳入 SQL:2023 草案的"大规模数据分析"章节; - 高可用 SQL 语义:针对分布式数据库的主备切换场景,OceanBase 定义了"故障转移期间 SQL 会话连续性"标准(如会话 ID 保持、事务状态同步),解决了传统 SQL 标准在分布式环境下的会话中断问题。

2. 华为 GaussDB:AI 与 SQL 融合标准
GaussDB 聚焦 AI for DB(人工智能赋能数据库),推动 SQL 与机器学习的标准化:
- SQL 中嵌入机器学习模型 :GaussDB 提出了"模型即函数"(Model as a Function)的 SQL 扩展语法(如
SELECT ML_PREDICT(model_name, features) FROM table),允许在 SQL 查询中直接调用训练好的机器学习模型(如预测用户流失、销量),相关提案被 SQL:2023 人工智能集成工作组采纳; - 自动调优 SQL 生成 :基于强化学习的 SQL 自动优化技术,GaussDB 推动了"自动生成优化 SQL"标准的制定(如通过
EXPLAIN ANALYZE输出优化建议的语法规范)。
三、本地化适配:推动标准与中国需求的结合
国产数据库在严格遵循 SQL 核心标准的基础上,针对国内行业需求(如政务、金融、能源)进行功能扩展,同时通过标准适配降低企业迁移成本。
1. 神通数据库(OSCAR):国产密码算法与安全标准
神通数据库作为国内信创领域的核心数据库,针对国家密码管理局的要求,扩展了 SQL 标准的安全特性:
- 支持 SM2/SM3/SM4 国产密码算法 ,在 SQL 标准的
ENCRYPT、HASH函数基础上,增加了国产算法的扩展语法(如ENCRYPT_SM4(data, key)); - 提出"国密算法与 SQL 权限控制"的集成方案(如通过
GRANT语句限制特定用户使用 SM4 加密列),相关方案被纳入 GB/T 36325-2018 信息安全技术 数据库管理系统安全技术要求国家标准。
2. TiDB(PingCAP):云原生与 HTAP 标准
TiDB 作为分布式关系型数据库,推动云原生 SQL 与混合事务分析处理(HTAP)的标准化:
- 云原生 SQL 扩展 :TiDB 提出了"存算分离"场景下的 SQL 语法(如
ALTER TABLE SET STORAGE_POLICY定义存储策略),解决了传统 SQL 标准在弹性扩缩容场景下的局限性; - HTAP 标准化 :针对实时分析需求,TiDB 扩展了 SQL 的"实时物化视图"(Materialized View)语法(如
CREATE MATERIALIZED VIEW ... REFRESH EVERY 1 MINUTE),支持事务与分析的实时同步,相关方案被 SQL:2023 HTAP 扩展工作组列为讨论方向。
四、社区与生态:推动标准落地与普及
国产数据库通过开源社区、技术认证、开发者工具等方式,推动 SQL 标准的普及与应用,降低企业使用门槛。
1. 开源社区贡献
- TiDB :基于 MySQL 生态,积极参与 MySQL 社区的 SQL 标准适配(如支持
WITH子句、窗口函数),同时通过开源文档、教程普及标准 SQL 的最佳实践; - OceanBase:开源了 SQL 兼容性测试套件(OCS),帮助企业验证数据库对 SQL 标准的支持程度,推动了国内数据库行业的标准化进程。
2. 标准认证与培训
- 达梦、人大金仓等厂商通过 ISO/IEC 9075 一致性认证,证明其产品符合国际标准,提升了国内企业的国际信任度;
- 华为、阿里云等厂商推出"SQL 标准认证课程",覆盖核心语法、高级特性(如窗口函数、CTE),帮助开发者掌握标准 SQL,降低跨数据库迁移成本。
总结
国产数据库在 SQL 标准领域的贡献主要体现在:
- 参与国际标准制定:通过技术提案和会议参与,将中国需求(如分布式事务、国产密码)融入国际标准;
- 技术创新与扩展:针对海量数据、AI 融合等场景,推动 SQL 标准的技术演进;
- 本地化适配:结合信创、行业需求,扩展标准功能并推动国家标准落地;
- 社区与生态:通过开源、认证和培训,普及标准 SQL,提升国内数据库行业的整体水平。
这些贡献不仅提升了国产数据库的国际竞争力,也为全球 SQL 标准的发展注入了中国智慧,支撑了信创产业的自主可控与全球化发展。