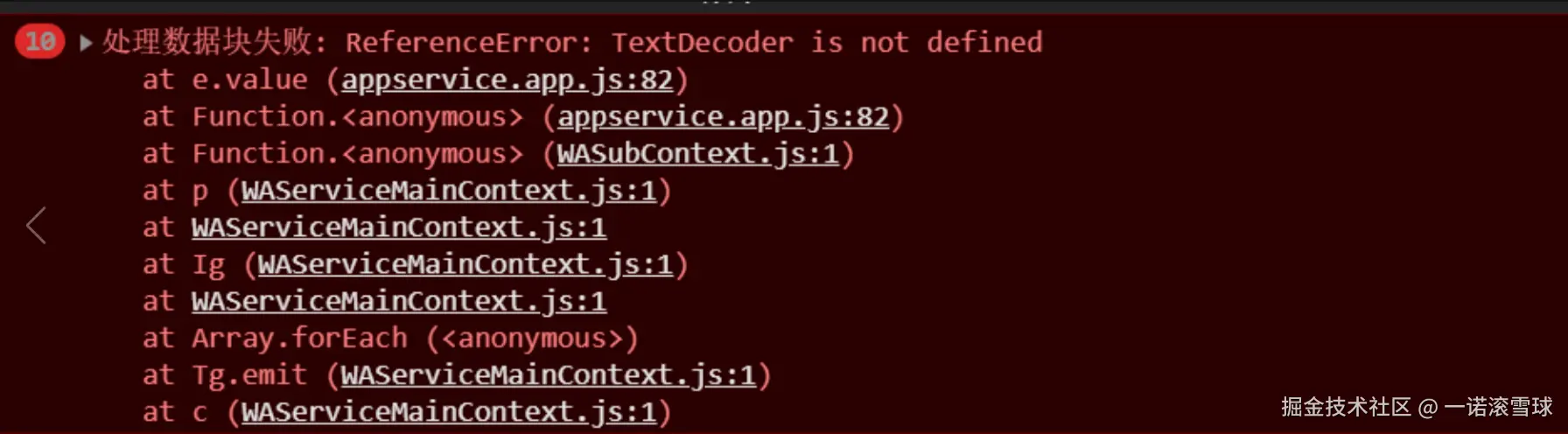
1. 问题复现
在微信小程序开发时,使用sse接收接口返回的是流式编码数据是中文的非纯ASCII字符,需要使用TextDecoder的decode方法将二进制数据转换为文本。在开发环境中,数据处理一直没有问题,但在真机测试及上线后,发现调用接口时出现了TextDecoder is not defined的报错,导致数据无法正常显示。
线上报错,问题出在TextDecoderAPI在小程序的生产环境中并不兼容。
2 如何解决
sse接口返回可能是中文的ASCII编码,会出现这种问题,如果是非中文的纯ASCII编码则不会出现。下面我们说下两种问题的解决方式。
这两种处理方式的主要区别在于字符编码的处理方式以及对二进制数据的转换方法,它们在处理非ASCII字符(如中文)时会有差异。
2.1 中文编码
看网上需要引入额外的插件或者手写,其实并不需要,具体代码如下:
typescript
const uint8Array = new Uint8Array(res.data);
const type = Object.prototype.toString.call(uint8Array);
if (type === "[object Uint8Array]") {
txt = decodeURIComponent(escape(String.fromCharCode(...uint8Array)));
} else if (uint8Array instanceof ArrayBuffer) {
const arr = new Uint8Array(uint8Array);
txt = decodeURIComponent(escape(String.fromCharCode(...arr)));
}-
支持 UTF-8 编码 :通过
escape+decodeURIComponent组合,实现了UTF-8 字节序列到字符串的正确转换 。escape将多字节字符(如 UTF-8)转换为%xx格式的转义序列,decodeURIComponent再将其解码为正确字符。 -
兼容性处理 :检查输入数据类型(
Uint8Array或ArrayBuffer),确保统一转换为Uint8Array后再处理。- 使用
Object.prototype.toString.call是更安全的类型检查方式(避免原型被篡改时的误判)。
- 使用
-
适用:能正确处理包含中文等非 ASCII 字符的流式数据(前提是原始数据是 UTF-8 编码)。
如果支持TextDecoder则使用下面代码:
ini
// 使用 TextDecoder(需兼容性检查)
const decoder = new TextDecoder('utf-8');
txt = decoder.decode(uint8Array);2.2 非中文编码
不含中文的编码,则直接使用如下代码:
ini
const uint8Array = new Uint8Array(res.data);
let text = lastText + String.fromCharCode.apply(null, uint8Array);- 直接转换 :使用
String.fromCharCode.apply(null, uint8Array)直接将每个字节转换为对应的 Unicode 字符。 - 仅适用于纯 ASCII 字符 (0-127),因为
fromCharCode按单字节处理,无法正确解析多字节编码(如 UTF-8 的中文字符)。
注意:如果
res.data是 UTF-8 编码的流式数据(例如包含中文),这种方式会导致乱码 ,因为 UTF-8 的中文字符由多个字节组成,而fromCharCode会逐字节解析,破坏多字节序列。
2.3 为什么这种方式能正确处理中文?
-
UTF-8 编码原理:
- 中文字符在 UTF-8 中占 3~4 字节(如 "你" 的 UTF-8 编码是
0xE4 0xBD 0xA0)。 - 直接
fromCharCode会拆分成 3 个独立字符(乱码),而escape会将多字节序列转为%E4%BD%A0,再通过decodeURIComponent还原为 "你"。
- 中文字符在 UTF-8 中占 3~4 字节(如 "你" 的 UTF-8 编码是
-
escape和decodeURIComponent的作用:javascript// 示例:中文 "你" 的 UTF-8 编码 [0xE4, 0xBD, 0xA0] const bytes = new Uint8Array([0xE4, 0xBD, 0xA0]); // 第一步:String.fromCharCode 得到乱码 "ä½ " const raw = String.fromCharCode(...bytes); // "ä½ " // 第二步:escape 将乱码转为 "%E4%BD%A0" const escaped = escape(raw); // "%E4%BD%A0" // 第三步:decodeURIComponent 解码为正确字符 "你" const decoded = decodeURIComponent(escaped); // "你"
2.4 两者区别
| 特性 | 无中文 | 有中文 |
|---|---|---|
| 字符编码支持 | 仅 ASCII | UTF-8、ASCII 等 |
| 中文处理 | 乱码 | 正常显示 |
| 数据类型检查 | 无 | 严格检查 Uint8Array 或 ArrayBuffer |
| 实现复杂度 | 简单 | 较复杂(需组合编码函数) |
| 适用场景 | 纯英文文本或二进制数据 | 多语言文本(如中文、特殊符号) |
3. 总结
最后总结一下:在微信小程序中,若返回的是中文的编码,真机TextDecoder 不可用,则使用替代方案。返回的是非中文的纯编码,则非常简单。
如有错误,请指正O^O!