1.缓存雪崩
在某一时间段Redis中有大量的key过期,导致大量请求落到数据库,对数据造成巨大压力;另外redis服务器宕机了也算是一种雪崩,导致所有请求落到数据库中.
简单来说就是大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据,这就导致大量的请求直接落到数据库上,造成巨大的压力.
解决办法
- 采用Redis集群,避免单机出问题影响整个缓存服务都无法使用.设置哨兵节点,保证Redis的服务高可用.
- 多级缓存,除却Redis服务层再设计一层jvm的本地缓存 如 Caffeine、Guava Cache) ,当Redis出问题,还可以从本地缓存中获取数据
- 设计随机失效时间,在原本为Redis缓存设计失效时间的基础上加一个大约1~5分钟的随机值,这样就可以有效避免大量数据在同一时刻过期,从而减少缓存雪崩的风险.
- 提前预热,对于热点数据提前预热将其存入缓存中并设置合理的过期时间,避免在高并发下key过
2.缓存穿透
就是访问大量不存在的key,在Redis中查询不到,落到MySQL中,对数据库造成巨大压力.
类似黑客在恶意制造一些非法的key发送大量请求,导致大量请求落在数据库,数据库中也没有数据,无法加入缓存,重复之后数据库中压力剧增.
解决方法
- 空值缓存:就是对访问的非法key进行缓存一个空值(需要设置过期时间),当下次这个非法key进行访问的话就会在缓存中查询到一个空值,并不会访问到数据库中.但是当网络攻击中的key是随机的会导致Redis中缓存大量的无效key,对内存造成压力;
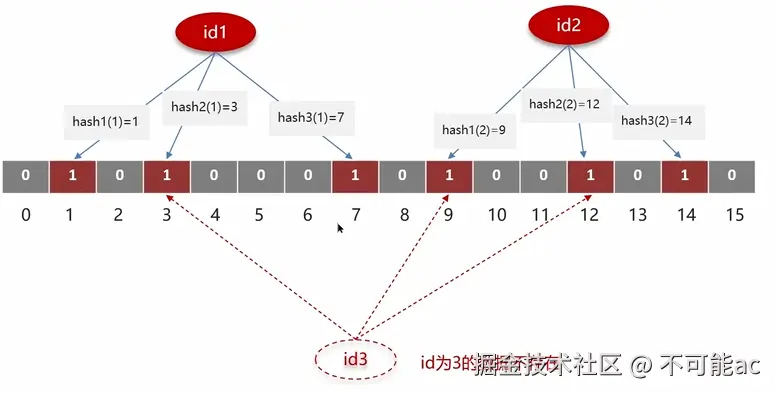
- 布隆过滤器:是一种数据结构,占用空间小并且效率高,可以快速的判断一个key是否在海量数据中.底层是一个位数组,每个元素存储0/1,对已有的key进行几种指定的hash运算,计算出对应的数组下标,并将下标元素置为1.当需要判断是否存在布隆过滤器中就计算对应的hash值判断几个hash值对应的元素是否都为1,由于hash计算不同的值可能会计算出相同的下标,可能非法key几个hash运算计算出的下标元素都为1那么就会出现误判.虽然误判概率很小.
- 接口限流:就是对一些异常访问行为,采用黑名单机制(ip黑名单),也可以对每个用户规定时间内的访问次数进行限制,从而减少数据库压力
3.缓存击穿
和缓存穿透很像,这个是请求的是在短时间内大量请求访问热点数据,但是该热点数据刚好过期或者其他原因不存在于redis中导致大量请求落在数据库中,对数据库造成巨大压力。
解决方法
- 不设置过期时间:这个就能有效避免击穿,但是这样对与内存不友好
- 提前预热:针对热点数据进行提前预热,将其存入缓存中并设置合适的过期时间
- 加锁:当查询缓存没有的话就对该条数据加上互斥锁确保只有一个请求查询完数据并更新缓存,这样后面的请求就能够查询到缓存中的数据。
4.Big Key问题
如果一个key对应的value所占的内存比较大,那这个key就算是一个big key,具体多大没有具体的判定标准,要根据业务实际情况去判定

常见的bigkey
- String类型存储文件二进制数据
- 集合类型数据量增长迅速
bugkey消耗很多内存空间和带宽.当Redis去操作一个bigkey的时候会比较耗时,那样就会阻塞Redis(单线程) ,同时每次去获取bigkey产生的网络流量较大,当请求数大的时候服务器可能没有那么大的带宽去处理,在删除bigkey时同样也会阻塞工作线程.
可以使用Redis自带的 --bigkeys进行查找
解决办法
- 分割bigkey:例如将一些集合,hash按照一定策略拆分成多个
- 手动清理:使用UNLINK命令来异步删除一个或多个bigkey
- 开启lazy-free (惰性删除/延迟释放): 就是把内存释放的工作 交给后台线程异步完成,而不是阻塞主线程 (Redis的多线程)
5.HotKey 问题
如Hot Key 指的是在 Redis 中被 频繁访问的某个 key ,它可能被成千上万次请求同时访问。
在高并发场景下,如果某些 key 特别"热门",就可能导致:
- CPU 开销过大:Redis 单线程反复处理对同一个 key 的请求。
- 网络瓶颈:大量请求集中访问一个 key,造成瞬时 QPS 峰值
- 缓存击穿风险:如果这个 hot key 过期,可能会导致成千上万请求同时打到数据库。
可以使用Redis自带的 --hotkeys参数检测
解决办法
- 本地缓存(JVM):添加本地缓存缓存热点数据,这样就不用每次去访问redis了
- 热点数据副本:将redis热点数据复制到多个节点,分散读流量
- 读写分离:主节点处理写请求,从节点处理读请求
- 避免hotkey变成bigkey 进行数据拆分
6.双写一致性问题
指的是当数据同时存在于数据库和缓存中时,如何保证两者数据的一致性。
问题产生原因
- 并发写入问题: 多个线程同时更新数据库和缓存,操作执行顺序不确定,导致数据不一致,网络延迟导致操作到达时间不同
- 操作失败问题:数据库操作成功,缓存操作失败,缓存操作成功,数据库操作失败,部分操作成功,部分操作失败
- 时序问题:先更新数据库后更新缓存的时序问题,多个请求并发执行时的竞态条件
几种策略问题
- 先删除缓存,在操作数据库: 高并发情况下,线程1删除了缓存 ,线程2开始查询缓存未命中查询数据库又写入到缓存中,而线程1后更新了数据库导致数据不一致
- 先操作数据库,在删除缓存:高并发下,线程1查询缓存为命中查询数据库,这时线程2更新数据,删除缓存,最后线程1又将旧数据加入到缓存中导致数据不一致了
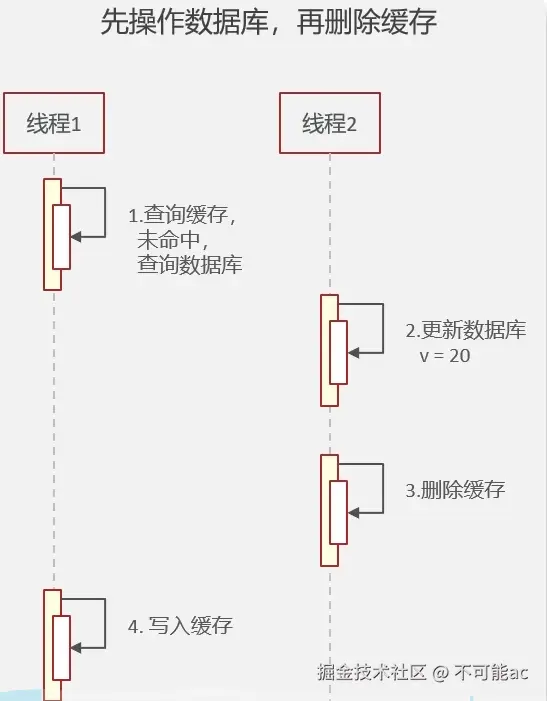
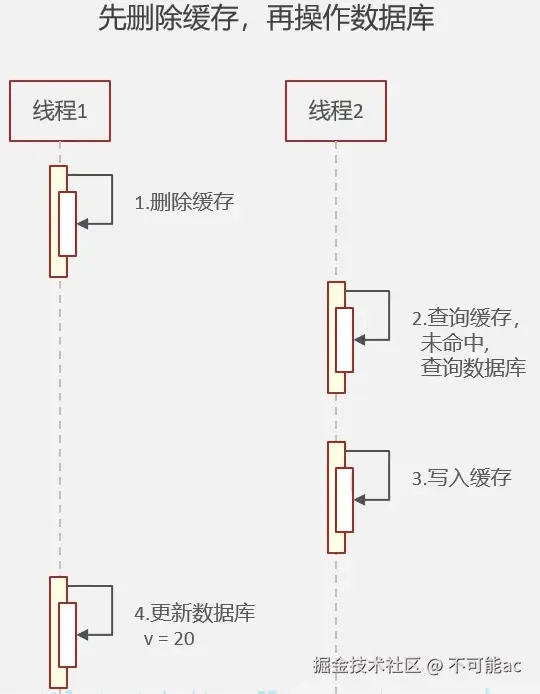
3.延时双删:删除缓存-更新数据库-删除缓存 ,这样可以大大避免以上两种情况下的脏数据,但是还是无法避免脏数据的风险;如 线程A,
- A 删除缓存。
- B 发现缓存不存在,从数据库中读到了旧数据(因为 A 还没更新完数据库)。
- B 把旧数据写回缓存。
- A 更新数据库。
- A 延时后再次删除缓存,但如果延时时间过短,刚好删之前 B 已经把旧数据写回缓存了,那么缓存就变成脏数据了。
为什么要进行延时呢?主要有以下几个原因:
- 避免误删:在高并发场景下,如果不进行延时,可能会出现误删的情况。比如,一个客户端发送了删除请求,但是由于网络延迟或其他原因,删除操作的响应耗时较长。这时,如果立即进行物理删除操作,可能会导致数据被误删。而延时操作可以给予足够的时间用于重复确认是否真的需要删除,从而避免误删问题的发生。
- 提高性能:Redis是单线程的,如果立即进行物理删除操作,会阻塞其他操作。延时双删可以将删除操作的开销分摊到不同的时间段内,从而提高系统的整体性能。
- 增加安全性:延时操作可以为删除操作增加一个缓冲期,如果在这段时间内出现了错误的删除操作,管理员可以及时通过恢复备份数据或者其它手段进行数据恢复,从而减少数据损失的风险。
- 支持事务操作:延时双删可以和Redis的事务功能结合使用。通过将删除操作放入事务中,并进行延时操作,可以确保删除操作与其他操作在同一个事务中,从而保证了一致性和可靠性。
- 兼顾性能和安全:延时双删可以在一定程度上平衡性能和安全性。在高并发场景中,可以通过合理调整延时时间来达到性能和安全的平衡点。
主要就是在怕在修改数据库之前其他业务线程已经拿到旧数据,但是业务时间长,没有延时的话就可能会让业务线程在双删后再次写入旧数据.
可以用互斥锁去实现当双写时的并发问题,但是这样性能会大大降低
因为redis是ap系统无法保证数据的强一致性,如果想要实现强一致性问题就需要使用cp的zookeeper.
7.缓存读写策略
有三种常见的缓存读写模式
旁路缓存模式
平时用的比较多的一种缓存读写模式.主体以数据库为准,以下是读写步骤
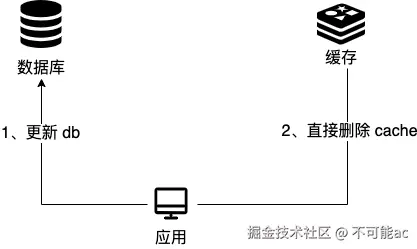
写:
- 先更新数据库
- 再删除缓存
读:
- 从缓存中读取数据,读取到就直接返回
- 缓存没有数据就进一步查询数据库
- 将数据库查询到的数据写入缓存
但是这样还是会产生数据不一致的问题,具体参考第6部分双写一致性问题
对于热点数据,需要将热点数据源提前写入缓存,以防遇到hotkey等问题
而且写操作比较频繁的话会导致缓存中的数据会被频繁删除,影响缓存命中率
读写穿透模式
这是一种以缓存视为主要数据存储的模式,缓存服务负责将数据读取和写入到数据库中.
写:
- 先查缓存,缓存不存在,直接更新数据库
- 缓存中存在数据,就先更新缓存,然后缓存服务自己更新数据库
读:
- 从缓存中读取数据,读取到就直接放回
- 读取不到,先将数据库中的数据写入到缓存中再响应
异步缓存写入模式
顾名思义,这种模式和以上两种最大的差异就是异步,这种模式只更新缓存,不会直接去更新数据库,而是采用异步批量的方式来更新数据库,类似消息队列消息异步写入磁盘
这种模式对数据一致性不好处理.但是对数据库的写性能非常高
布隆过滤器简单实现
arduino
import java.util.BitSet;
/**
* 布隆过滤器核心实现
* 主要功能:add() 添加元素,contains() 判断元素是否可能存在
*/
public class BloomFilter {
// 位数组的默认大小,越大则误判率越低,但占用内存越多
private static final int DEFAULT_SIZE = 1 << 24; // 约1600万位 ≈ 2MB
// 哈希函数的种子,使用不同的质数作为种子可以生成多个不同的哈希函数
private static final int[] SEEDS = {3, 13, 46, 71, 91, 134};
// 位数组,用于存储元素是否出现过
private BitSet bitSet = new BitSet(DEFAULT_SIZE);
// 保存多个哈希函数
private SimpleHash[] func = new SimpleHash[SEEDS.length];
/**
* 构造方法:初始化多个哈希函数
*/
public BloomFilter() {
for (int i = 0; i < SEEDS.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 向布隆过滤器中添加一个元素
* @param value 要添加的字符串
*/
public void add(String value) {
for (SimpleHash f : func) {
bitSet.set(f.hash(value), true); // 将哈希值对应的 bit 置为 1
}
}
/**
* 判断一个元素是否可能存在
* @param value 要判断的字符串
* @return true 表示可能存在(有误判几率); false 表示一定不存在
*/
public boolean contains(String value) {
for (SimpleHash f : func) {
if (!bitSet.get(f.hash(value))) {
return false; // 如果有一个位置为 0,则一定不存在
}
}
return true; // 所有位置都为 1,则可能存在
}
/**
* 自定义简单哈希函数
*/
public static class SimpleHash {
private int cap; // 位数组大小(取模用)
private int seed; // 哈希函数的种子
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算字符串的哈希值
* @param value 输入字符串
* @return 哈希值(映射到位数组范围内)
*/
public int hash(String value) {
int result = 0;
for (int i = 0; i < value.length(); i++) {
result = seed * result + value.charAt(i); // 哈希运算
}
return (cap - 1) & result; // 保证哈希值落在 [0, cap) 范围内
}
}
}参考文献: JavaGuide