大家好,我是你们踩过无数坑的后端博主。前阵子线上出了个大活 ------MQ 丢了一批订单消息,运营小姐姐追着我要数据,老板站在身后看我查日志,那场面,现在想起来还手心冒汗。
后来复盘发现,不是 MQ 本身菜,是我当初对 "MQ 可靠性" 的理解太浅了 ------ 以为发出去、收进来就完事,结果从生产者到消费者,每一步都藏着 "丢消息陷阱"。今天就把这些坑和解决方案扒明白,让你家 MQ 从此稳如老狗。
先搞懂:为啥 MQ 可靠性这么重要?
你想啊,要是支付消息丢了,用户付了钱没收到订单;要是物流消息丢了,商家发了货系统没记录 ------ 这些场景轻则用户投诉,重则直接丢钱。MQ 作为分布式系统的 "消息快递员",一旦掉链子,整个链路都会跟着崩。
所以咱们聊的 "MQ 可靠性",本质是解决三个问题:
- 生产者能不能把消息稳稳发给 MQ?(别发丢)
- MQ 能不能把消息稳稳存住?(别存丢)
- 消费者能不能把消息稳稳处理完?(别处理丢)
一、生产者:别让消息死在 "发货路上"
生产者的核心痛点:要么连不上 MQ 发不出去,要么发出去了不知道 MQ 收没收到。这俩坑,得针对性填。
1. 连接失败?重连机制来救场
你有没有遇到过 "启动服务时 MQ 连不上,重启一下又好了" 的情况?这不是玄学,是没配重连机制。
就像打电话,一次没通不能直接挂吧?得隔几秒再打,还得控制频率 ------ 总不能每秒打 100 次,把 MQ 服务器 "打烦了" 拉黑你。
实用方案(以 RocketMQ 为例):
scss
DefaultMQProducer producer = new DefaultMQProducer("group1");
producer.setNamesrvAddr("localhost:9876");
// 关键:设置重连参数
producer.setRetryAnotherBrokerWhenNotStoreOK(true); // 连不上当前Broker,重试其他Broker
producer.setSendMsgTimeout(3000); // 发送超时时间,别等太久
// 重连间隔:默认会用指数退避(1s→2s→4s...),不用自己瞎写
producer.start();简单说:重连要 "聪明点"------ 别死磕一个 Broker,别高频轰炸,超时就收手,重试间隔循序渐进。
2. 消息没送达?确认机制要盯紧
有时候连接通了,但消息发出去 "石沉大海"------ 可能是网络波动,也可能是 MQ 暂时没存住。这时候你得要个 "回执",也就是确认机制。
MQ 的确认分两种,像两种 "快递签收方式":
- 同步确认:发完消息,等着 MQ 说 "收到了" 才走(类似顺丰 "本人签收")。适合支付、订单这类核心消息,丢不起!
scss
SendResult result = producer.send(msg);
if (result.getSendStatus() == SendStatus.SEND_OK) {
System.out.println("消息稳了!");
} else {
// 没确认,重试或兜底
retrySend(msg);
}- 异步确认:发完消息不等回执,MQ 收到后会回调通知你(类似快递 "放驿站,短信通知")。适合日志、监控这类非核心消息,追求高吞吐。
typescript
producer.send(msg, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
System.out.println("异步收到回执:稳了");
}
@Override
public void onException(Throwable e) {
System.out.println("寄了,赶紧兜底");
saveToLocal(msg); // 存本地日志
}
});3. 发送失败的 "终极兜底":别让消息死无葬身之地
要是重连也试了,确认也没收到,怎么办?总不能让消息 "凭空消失" 吧?
这时候必须有本地兜底方案:
- 把失败的消息存到本地数据库 / 文件(比如一张mq_send_failed表);
- 加个定时任务(比如每 5 分钟),重试表里的失败消息;
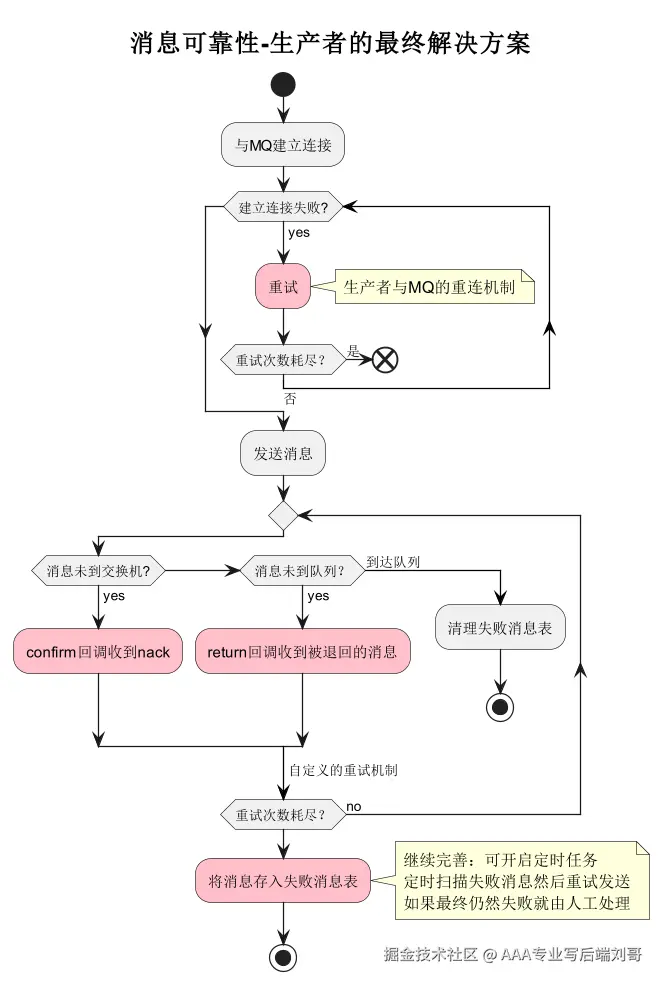
- 要是重试 3 次还失败,发告警到钉钉 / 企业微信,让开发介入 ------ 毕竟总不能让消息在表里躺一辈子。
记住:生产者的底线是 "宁可存重复,不能丢一条"(重复消息后续消费者能解决,丢了就真没了)。
二、中间件:MQ 自己得 "靠谱"------ 持久化是关键
就算生产者发得稳,要是 MQ 自己崩了,消息没存住,那也是白搭。比如你发了个订单消息,MQ 放内存里还没来得及存盘,突然断电 ------ 消息直接没了,哭都来不及。
这时候持久化就是 MQ 的 "保命符":把消息存到磁盘上,就算 MQ 宕机,重启后还能从磁盘读回来。
持久化怎么选?看你要 "速度" 还是 "安全"
不同 MQ 的持久化方案差不多,核心分两种:
- 同步刷盘:MQ 收到消息后,先写磁盘,确认写成功了再给生产者回执(类似你存文件点 "保存",等提示 "保存成功" 再关)。
✅ 优点:绝对安全,除非磁盘炸了; ❌ 缺点:慢,吞吐低。适合金融、支付场景。
- 异步刷盘:MQ 收到消息先放内存,定期批量写磁盘(类似你写文档开 "自动保存",不用手动点)。
✅ 优点:快,吞吐高; ❌ 缺点:内存里的消息没来得及刷盘,宕机就丢。适合日志、监控场景。
以 Kafka 为例,改配置就能切换:
ini
# server.properties 中
log.flush.interval.messages=10000 # 每收到1万条消息刷一次盘(异步)
log.flush.interval.ms=1000 # 每1秒刷一次盘(异步)
# 要是想同步刷盘,发消息时加参数:ProducerConfig.ACKS_CONFIG = "all"简单说:核心消息选 "同步刷盘 + 多副本"(比如 Kafka 副本数设 3),普通消息选 "异步刷盘",别一刀切。
三、消费者:别让消息 "签收了没处理"
消费者的坑更隐蔽:有时候 MQ 把消息发出去了,消费者 "签收" 了,但业务代码没执行完就崩了 ------ 结果消息丢了,还没法重试。
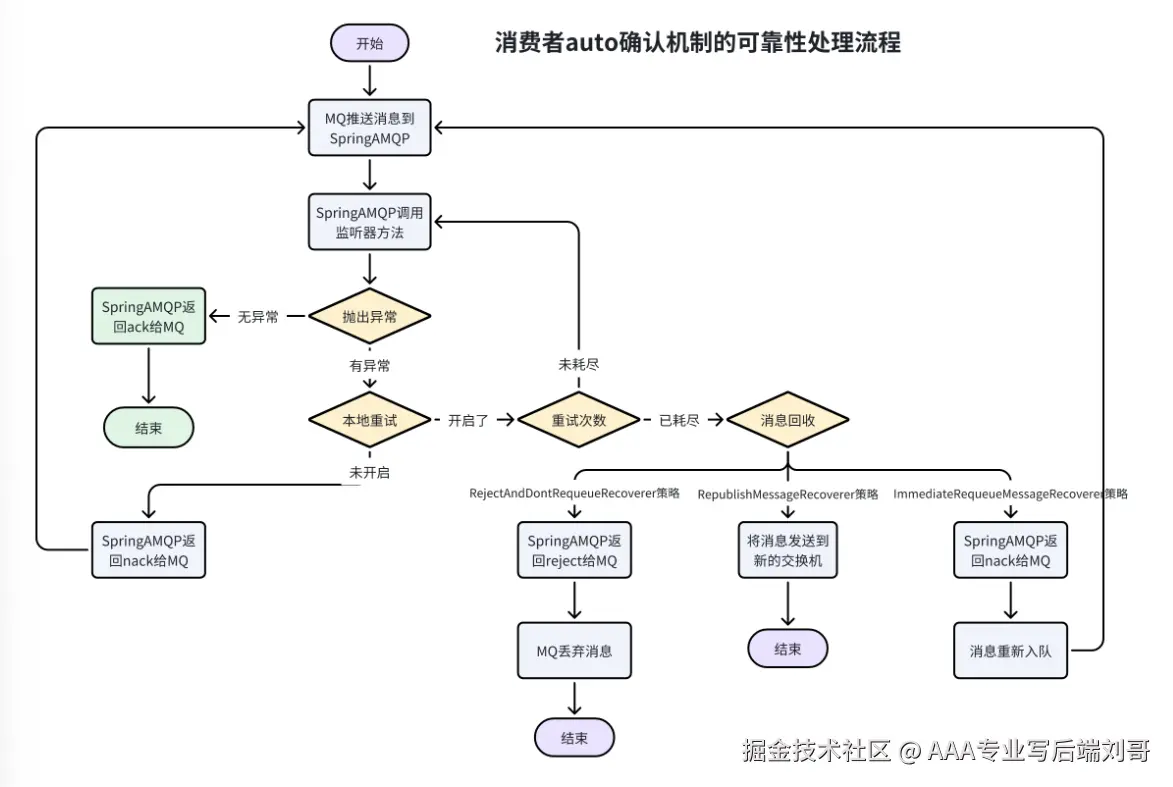
1. 确认机制:别瞎 "ACK"!
消费者的确认(ACK)原则就一个:业务处理完了,再 ACK!
千万别用 "自动 ACK"(比如 Spring Kafka 默认 auto-commit=true)------ 消息一收到就自动 ACK,万一处理到一半崩了,MQ 以为你处理完了,不会再发了,消息直接丢。
正确姿势:手动 ACK(以 Spring Boot 为例):
typescript
@KafkaListener(topics = "order_topic")
public void consume(ConsumerRecord<String, String> record, Acknowledgment ack) {
try {
// 1. 先处理业务逻辑(比如更新订单状态)
orderService.updateStatus(record.value());
// 2. 业务处理完了,再手动ACK
ack.acknowledge();
} catch (Exception e) {
// 处理失败,不ACK,让MQ重新发
log.error("处理消息失败", e);
}
}2. 处理失败?重试机制来兜底
业务处理失败(比如数据库临时连不上),别直接扔异常,得重试几次。但重试也有讲究:
- 别无限重试:比如重试 3 次还失败,就别再试了,不然会导致 "消息阻塞队列"(比如一条坏消息反复重试,后面的消息都卡住)。
- 重试间隔要合理:别失败了马上重试,比如第一次等 1 秒,第二次等 3 秒,第三次等 5 秒(指数退避),给下游服务恢复时间。
Spring Kafka 配置重试示例:
yaml
spring:
kafka:
consumer:
enable-auto-commit: false # 关闭自动ACK
listener:
retry:
enabled: true # 开启重试
max-attempts: 3 # 最多重试3次
initial-interval: 1000 # 第一次重试间隔1秒3. 重试耗尽:死信队列来 "收尸"
要是 3 次重试都失败,说明这条消息大概率有问题(比如数据格式错了、依赖服务彻底挂了),再重试也没用。这时候就该把它丢进死信队列(DLQ)。
死信队列就像 "问题件仓库":
- 配置死信队列(比如给order_topic配个死信 topicorder_topic_dlq);
- 重试耗尽的消息自动转存到死信队列;
- 开发定期检查死信队列,排查问题(比如数据格式错了就修正后重新发,依赖挂了就等恢复后重试)。
RocketMQ 配置死信队列很简单,不用写代码,控制台里给 Topic 配个 "死信交换机" 就行,省心。
4. 终极补偿:主动查 "漏网之鱼"
就算前面的机制都配了,还是可能有 "漏网之鱼"(比如消费者宕机时间太长,MQ 没来得及重发)。这时候得有主动查询机制。
比如:
- 生产者发消息时,把消息存到 "消息记录表"(mq_message),状态设为 "待发送";
- 消费者处理完消息,调用接口把mq_message的状态改成 "已处理";
- 加个定时任务(比如每 10 分钟),查mq_message里 "待发送" 且超过 30 分钟的消息;
- 对这些 "疑似未消费" 的消息,主动调用 MQ 的查询接口(比如 RocketMQ 的queryMessage),确认是否已被消费;
- 要是没消费,就重新发送一次。
这招虽然麻烦,但能兜底 99.99% 的丢消息场景,核心业务一定要加!
最后总结:MQ 稳如老狗的 3 个核心
其实 MQ 可靠性没那么复杂,记住三句话:
- 生产者:重连机制防断连 + 确认机制防丢发 + 本地日志防极端;
- 中间件:持久化(同步 / 异步按需选) + 多副本防单机崩;
- 消费者:手动 ACK 防瞎签 + 重试 + 死信防失败 + 主动查询防漏网。
最后问大家一句:你以前踩过 MQ 的什么坑?是丢消息还是重复消费?评论区聊聊,让更多人避坑~