📖 目录
- 背景
- [传统 RAG 的小尴尬](#传统 RAG 的小尴尬 "#%E4%BC%A0%E7%BB%9F-rag-%E7%9A%84%E5%B0%8F%E5%B0%B4%E5%B0%AC")
- [GraphRAG 到底是啥?](#GraphRAG 到底是啥? "#graphrag-%E5%88%B0%E5%BA%95%E6%98%AF%E5%95%A5")
- [GraphRAG 怎么工作?](#GraphRAG 怎么工作? "#graphrag-%E6%80%8E%E4%B9%88%E5%B7%A5%E4%BD%9C")
- 有什么用?
- 挑战在哪里?
- [🚀 GraphRAG 实战:从零到跑通 Demo](#🚀 GraphRAG 实战:从零到跑通 Demo "#-graphrag-%E5%AE%9E%E6%88%98%E4%BB%8E%E9%9B%B6%E5%88%B0%E8%B7%91%E9%80%9A-demo")
- 🔑 小结(#🔑 小结)
背景
最近在搞 RAG(Retrieval-Augmented Generation,检索增强生成)的朋友可能会发现一个问题:
明明我把文档分块建了索引,检索也能找到相关段落,可一旦问题需要跨多个文档、或者涉及事件关系时,模型就容易答不全,甚至胡说八道。
这就是传统 RAG 的局限性。它擅长找"相关段落",但不擅长理解"关系"。
于是,社区里开始冒出来一个新思路:GraphRAG。
传统 RAG 的小尴尬
RAG 的思路很直白:
- 文档分块 → 存进向量库;
- 用户提问 → 找几个最相似的块;
- 把块塞进大模型 → 输出答案。
这种方法解决了"模型不知道"的问题,但也带来了几个痛点:
- 碎片化:每个 chunk 就像孤岛,之间没什么联系;
- 跨文档推理难:如果答案需要结合多个文件,RAG 就懵了;
- 检索精度不足:相似度高 ≠ 真正相关,模型常常被"干扰项"误导。
有没有办法让检索变得更像"人类理解"?这就是 GraphRAG 想解决的。
GraphRAG 到底是啥?
一句话:GraphRAG = 知识图谱 + RAG。
它的核心思路是:
- 不仅把文档切块,还要抽取里面的 实体、事件、关系,把它们画成图;
- 检索的时候,不只是比向量,还能顺着图谱去找"路径",理解上下文的逻辑关系;
- 最后再把这些带关系的内容丢给大模型,让它生成答案。
这样,模型看到的不再是"零散段落",而是"有逻辑关系的知识网络"。
GraphRAG 怎么工作?
一个典型的 GraphRAG 系统,大概是这样的:
- 文档处理:先切块,再用 NLP 技术抽取实体(人、组织、地点、时间)和事件。
- 建图:节点 = 实体/事件,边 = 它们之间的关系,比如"发生在"、"属于"、"因果"。
- 图谱检索:当你提问时,系统会在图谱里走一遍,找到最相关的节点和路径。
- 答案生成:把相关文档 + 图谱关系送进 LLM,得到答案,还能顺带输出一条推理链。
相比传统 RAG,这种方式更像"知识导航",而不是"碎片堆砌"。
有什么用?
GraphRAG 特别适合那些"知识关系复杂"的场景,比如:
- 企业知识库:部门流程、历史事件、政策条款之间有大量关联;
- 科研文献:作者、实验、结果往往互相关联,需要推理链路;
- 法律法规:条款之间层层引用,光靠相似度检索很容易漏掉关键点;
- 多模态数据:未来还能把图片/视频里的事件抽出来,统一到知识图谱里。
一句话:只要场景涉及"跨文档、多关系推理",GraphRAG 都有优势。
挑战在哪里?
当然,GraphRAG 也不是银弹:
- 图谱构建成本高:关系抽取、事件识别要靠 NLP 技术,效果不好直接拖后腿;
- 规模与性能问题:图谱越大,检索越复杂;
- 缺乏标准化:目前还没有特别统一的工具链。
所以现在的 GraphRAG 还在早期阶段,更多是探索性研究。
🚀 GraphRAG 实战:从零到跑通
下面我们用来快速体验 GraphRAG 的基本流程。
环境准备
bash
# 创建虚拟环境
conda create -n graphrag python=3.12 -y #创建虚拟环境
conda activate graphrag #激活虚拟环境
# 安装graphrag
pip install graphrag -i https://pypi.tuna.tsinghua.edu.cn/simple/安装jupyter
通过jupyter,我们编写写代码查看生成的索引信息
安装
bash
# 创建jupyterlab,编码使用
conda install jupyterlab -y # 安装jupyterlab
conda install ipykernel -y # 安装jupyter内核
python -m ipykernel install --user --name graphrag --display-name "Python (graphrag)" # 设置内核名字为graphrag设置密码
vbscript
jupyter server password运行
如果是使用linux的root账号运行,需要添加命令--allow-root
shell
jupyter lab --allow-root --no-browser --ip 0.0.0.0--allow-root:允许root下运行,没有这个会有警告
--no-browser :不打开浏览器
--ip:设置ip,所有所有网络地址都能访问
初始化
-
创建目录
bashmkdir -p ./openl/input -
初始化项目
bashgraphrag init --root ./openl 2025-09-02 23:31:32.0805 - INFO - graphrag.cli.initialize - Initializing project at D:\pythonws\graphrag\openl
-
准备知识文件
txt在 2023 年的深圳,一家名为「星河机器人」的初创公司与华为签署了合作协议,计划联合研发下一代类人机器人。 这项合作由星河机器人的创始人李明推动,他此前曾在麻省理工学院学习人工智能。 协议中提到,华为将提供 5G 通讯技术与昇腾芯片,而星河机器人则负责机器人的操作系统与感知算法。 与此同时,在北京,中科院自动化研究所也在进行类似的研究,其负责人王芳曾多次公开表示,中国在未来十年内有望在机器人与脑机接口的结合上取得突破。 值得注意的是,王芳与李明在 2021 年上海的「全球人工智能大会」上曾经同台演讲,探讨过 AI 与神经科学的交叉应用。 如果这两条研发路线最终能够汇合,可能会加速人形机器人在医疗康复与工业制造中的落地。修改配置文件
setting.yaml是项目的配置文件,修改添加我们自己的模型与设置切割大小。我们这边使用本地搭建的ollama大模型。
-
设置模型
使用
qwen3:30B与bge-m3,下图为添加模型的api地址与对应的模型名。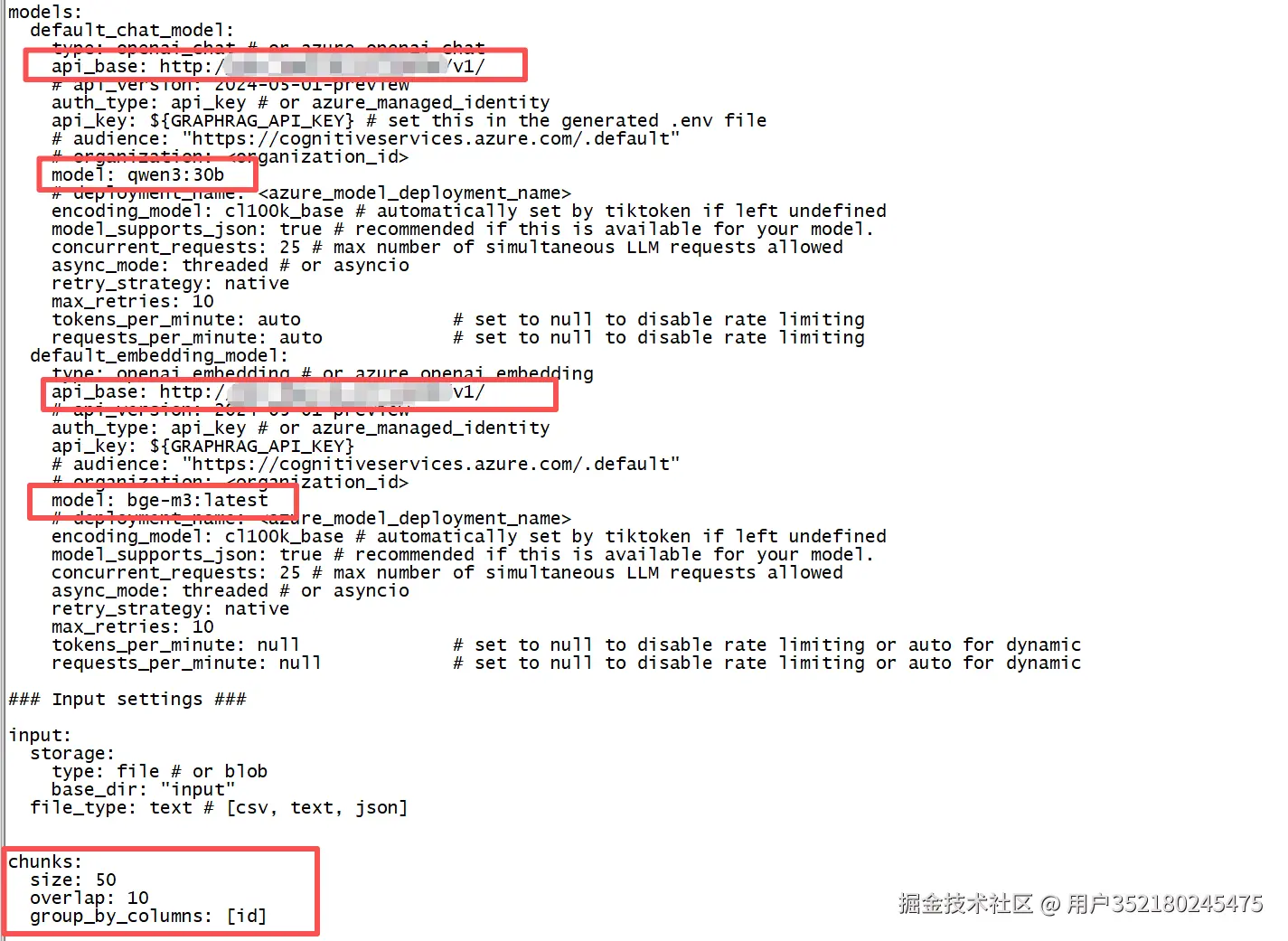
-
设置分块大小
设置分块的大小,影响到我们索引创建的粒度。由于我们文档内容少,我们可以设置小些。
yaml
chunks:
size: 50
overlap: 10size:分块的大小,如果文件比较少可以是50;
overlap:重叠的token大小,,如果文件比较少可以是10;
- 设置分词的模型encoding_model,如果不设置会议异常
vbnet
KeyError: 'Could not automatically map qwen3:30b to a tokeniser. Please use `tiktoken.get_encoding` to explicitly get the tokeniser you expect.'把两个地方encoding_model: cl100k_base,前面的#去掉
建立索引
graphrag默认使用Parquet作为索引的存储,Parquet 采用列式存储,数据按列组织,结合高级压缩算法(如Snappy、Gzip),显著减少存储空间,提升查询性能。
-
创建索引
bashgraphrag index --root ./openl -
查看索引信息
下面主要在jupyterlab中进行查看,注意这边是在linux中查看的,所以目录分隔符是
/ -
查看文件信息
pythonimport pandas as pd document_df = pd.read_parquet(r'./openl/output/documents.parquet') document_df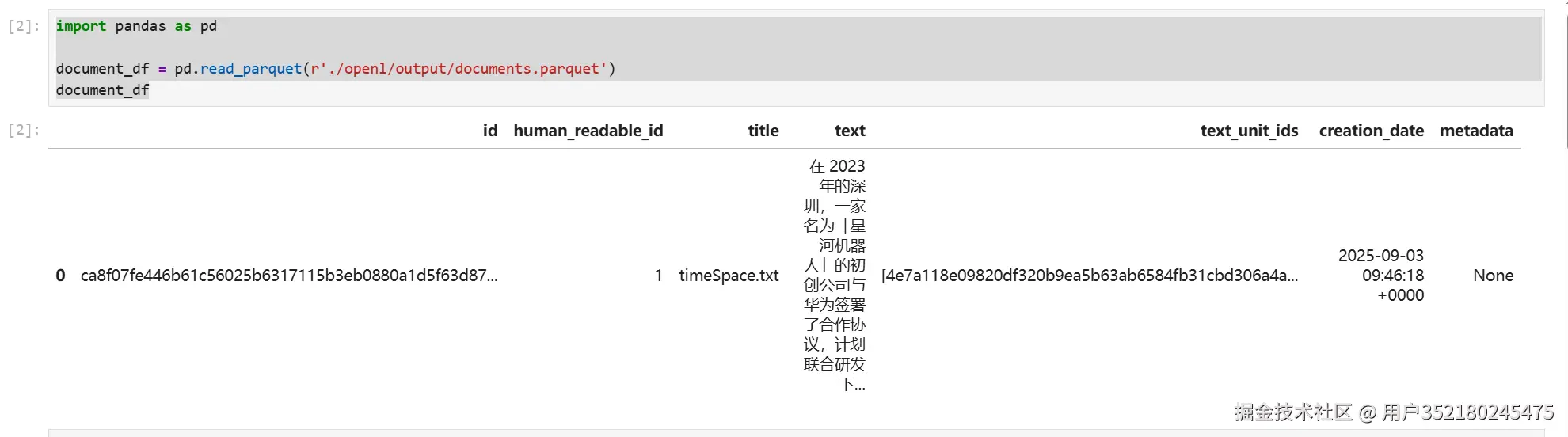
-
查看分割的文件信息
pythontext_unit_df = pd.read_parquet(r'./openl/output/text_units.parquet') text_unit_df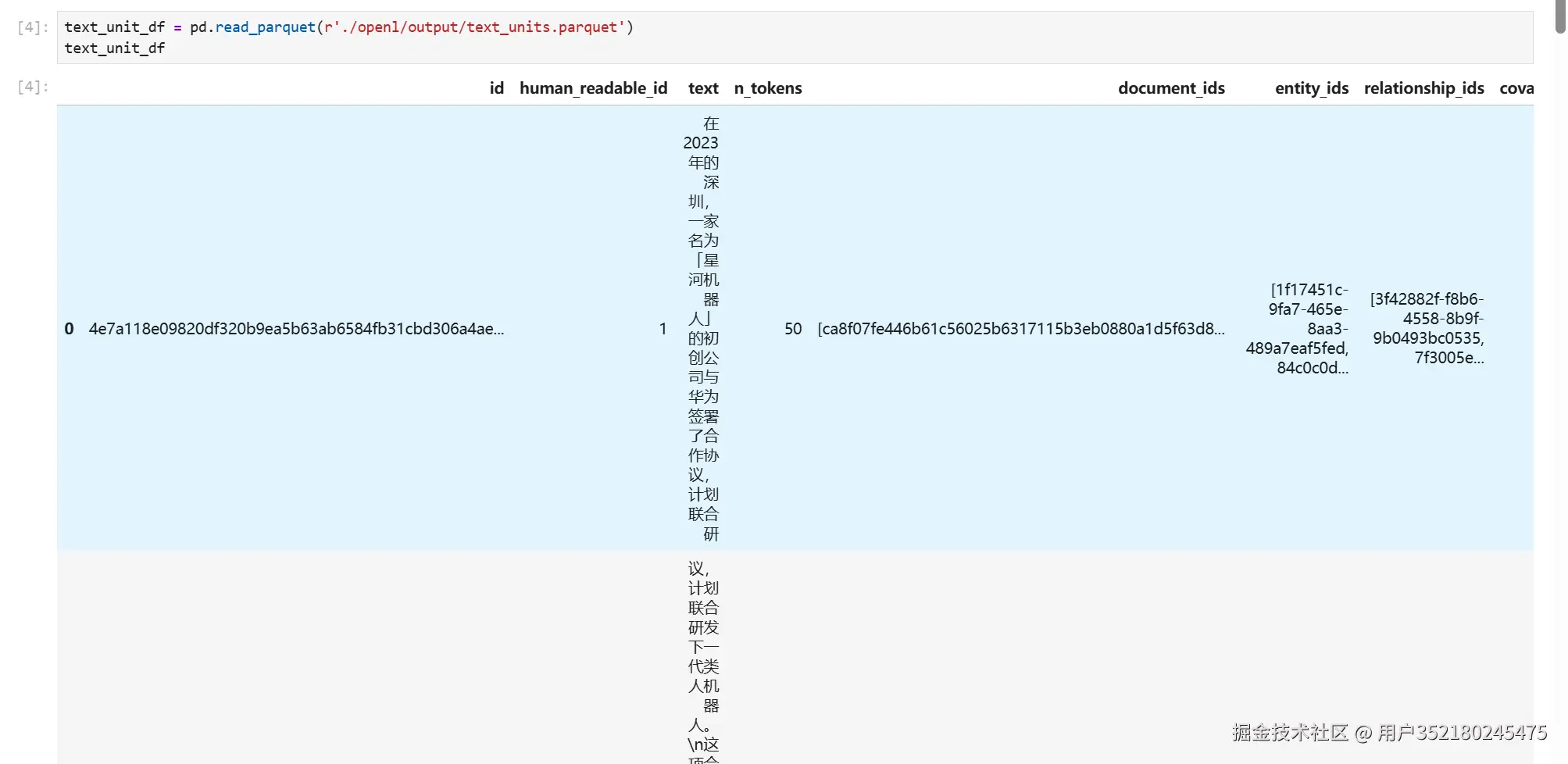
-
查看实体的信息
pythonentities_df = pd.read_parquet(r'./openl/output/entities.parquet') entities_df
-
查看关系的信息
pythonrelationships_df = pd.read_parquet(r'./openl/output/relationships.parquet') relationships_df
-
查看社区的信息
pythoncommunities_df = pd.read_parquet(r'./openl/output/communities.parquet') communities_df
-
查看社区报告的信息
pythoncommunity_reports_df = pd.read_parquet(r'./openl/output/community_reports.parquet') community_reports_df
查询
由于默认的prompt都是使用英文,要让回答使用中文,那么咱们就要在问题前加上请使用中文答复。
本地查询
本地查询专注于从知识图谱的特定子集检索信息,适合处理针对具体实体或上下文的详细问题。
bash
graphrag query --root ./openl --method local --query "请使用中文答复星河机器人和华为合作的具体内容是什么?" 
全局查询
全局查询针对整个数据集,适合需要综合分析或概括性答案的问题,如主题总结或数据集整体趋势。
css
graphrag query --root ./openl --method global --query "请使用中文答复哪些机构在研发类人机器人?" 
🔑 小结
通过上面的 Demo,你已经跑通了一个最小 GraphRAG 案例:
下一步可以尝试:
- 自动化实体关系抽取(NER + 关系抽取模型);
- 将图谱检索与向量检索结合;
- 在更大规模的数据集上部署。
如果说传统 RAG 是"记忆碎片拼凑",那 GraphRAG 更像是"知识网络导航"。 在知识密集型的应用里,它确实让模型变得更聪明了一点。