在数字化浪潮席卷全球的当下,企业数据量呈指数级增长,传统 OLTP 数据库 Oracle 在海量数据实时分析场景中逐渐显得力不从心。而 ClickHouse 作为开源列式存储数据库,凭借超高的查询性能和并行处理能力,成为企业构建实时数据仓库的 "新宠"。然而,从 Oracle 到 ClickHouse 的异构数据库 ETL 迁移之路却布满荆棘,数据类型不兼容、索引机制差异导致的查询性能拉胯、数据丢失等问题,让不少企业望而却步。本文将解析以上痛点并对症下药给出解法。
一、Oracle与ClickHouse的差异
要做好迁移,首先得认清 Oracle 与 ClickHouse 在设计理念上的本质区别 ------Oracle 面向事务处理,强调数据一致性和事务 ACID 特性;ClickHouse 面向分析场景,追求查询速度和海量数据存储效率。这种差异直接体现在数据类型和索引机制两大核心模块,也是迁移中最容易踩坑的地方。
1.数据类型的差异
Oracle 的数据类型设计偏向 "通用化",支持复杂嵌套类型和自定义类型,能适配多样业务场景;而 ClickHouse 的数据类型以 "高效存储" 和 "快速计算" 为目标,划分更精细,部分类型与 Oracle 存在显著不兼容。比如 Oracle 的NUMBER精度可动态调整,但存储占用高,若直接映射为 ClickHouse 的 Int64,可能导致数据溢出;Oracle 的 TIMESTAMP 精确到微秒,而 ClickHouse 的 Date 仅精确到天,DateTime64 需手动指定小数位,简单映射会造成时间精度丢失。
2.索引机制的差异
Oracle 默认使用 B 树索引,通过多层节点结构快速定位单行数据,适配事务高频读写;而 ClickHouse 的核心是主键索引和跳数索引,均为 "稀疏索引",每隔一定行数记录一个 "标记",虽能大幅降低查询 IO 开销,却不支持单行快速更新 / 删除。若迁移时照搬 Oracle 的 B 树索引,不仅会让 ClickHouse 索引体积膨胀,还会导致写入性能骤降。
二、ETL工具
面对 Oracle 与 ClickHouse 的数据类型差异,手动处理不仅效率低,还容易出错。这时候就需要借助ETL工具处理,而ETLCloud作为一款功能强大、性能卓越的数据集成工具,其高效性、灵活性、强大的流程控制功能以及丰富的数据处理功能,使得它能够满足各种复杂的数据处理需求。让字段类型映射与兼容性处理变得简单高效,完美规避数据丢失、精度异常等问题。下面演示下如何使用ETLCLoud进行Oracle 到 ClickHouse的数据迁移。
1.新建数据源创建Oracle源数据库:
进入数据源管理选择新建数据源,在数据源中找到Oracle模板进行创建。
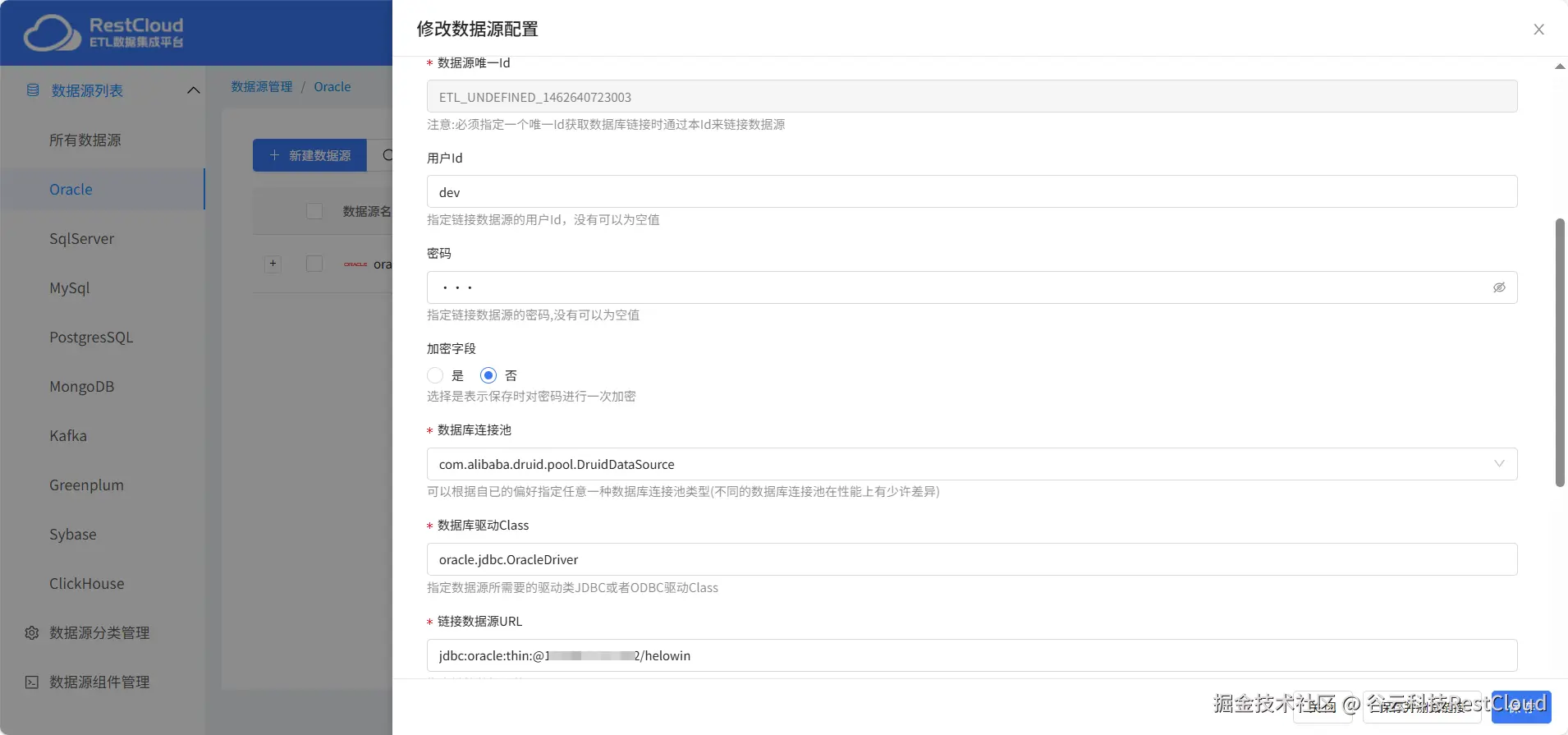
填写Oracle相关配置
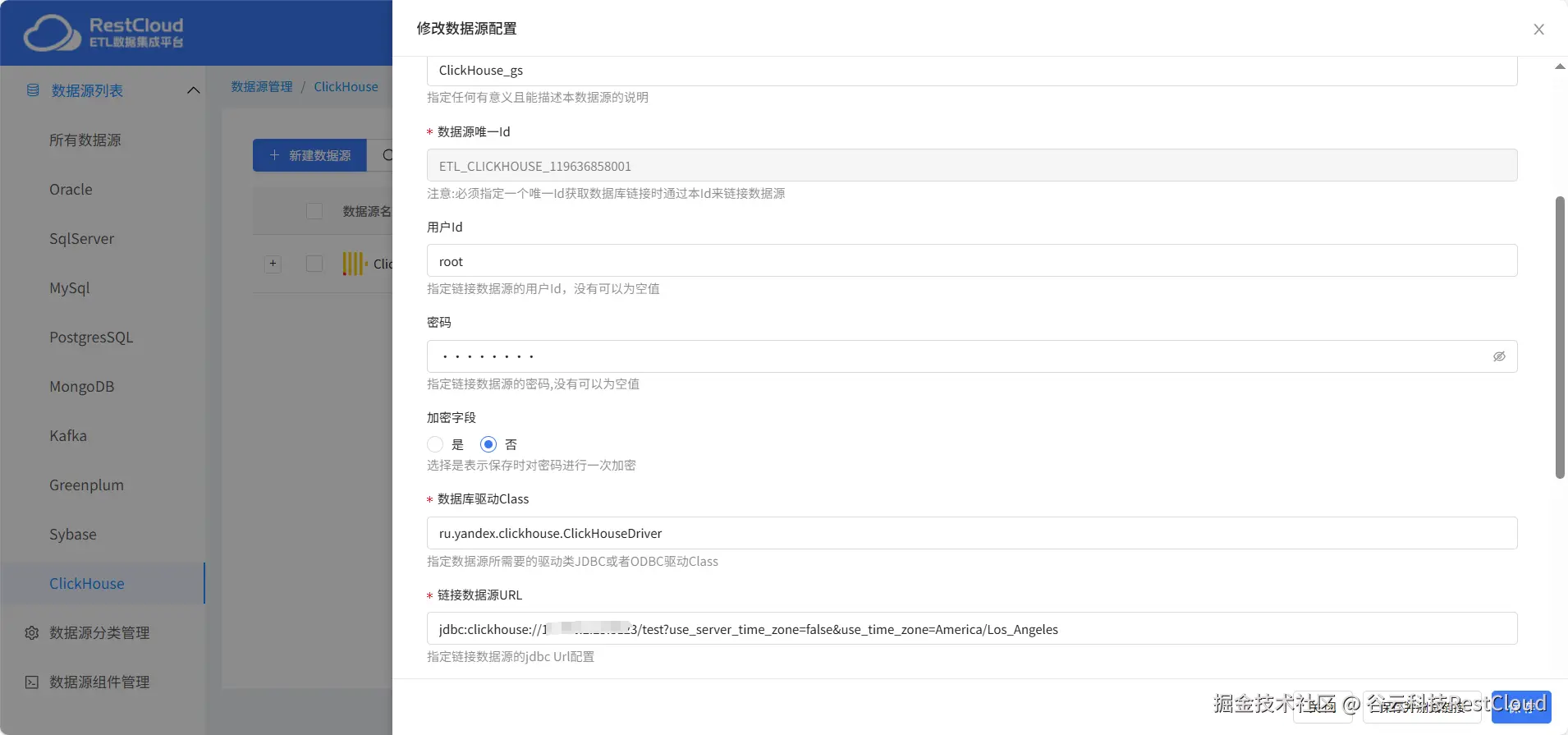
2.新建数据源创建ClickHouse源数据库:
ClickHouse数据源创建步骤和上述相同
新建流程
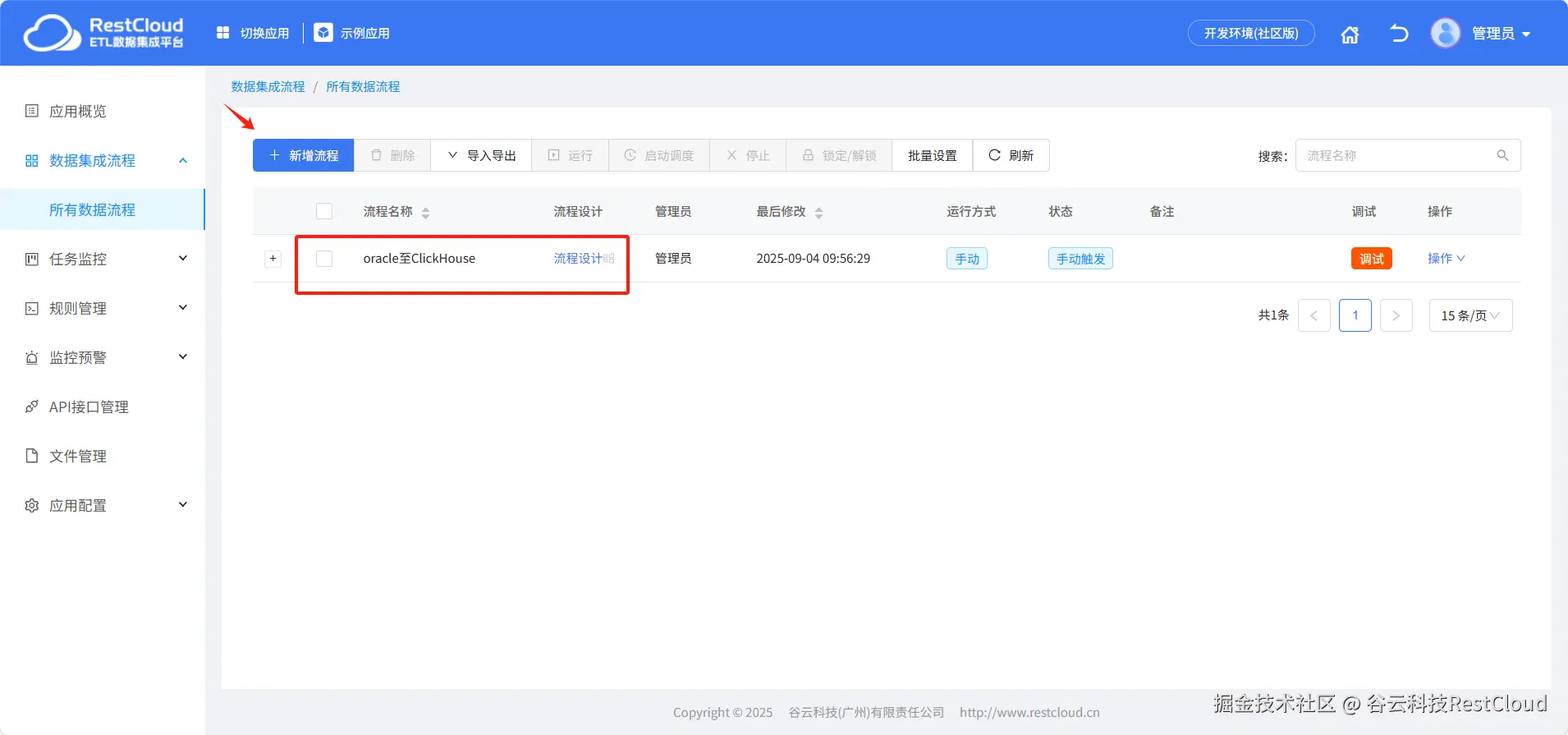
打开流程设计,在组件列表中拉取库表输入组件和库表输出组件,库表输入用于读取oracle数据,库表输出用于往ClickHouse中同步数据。
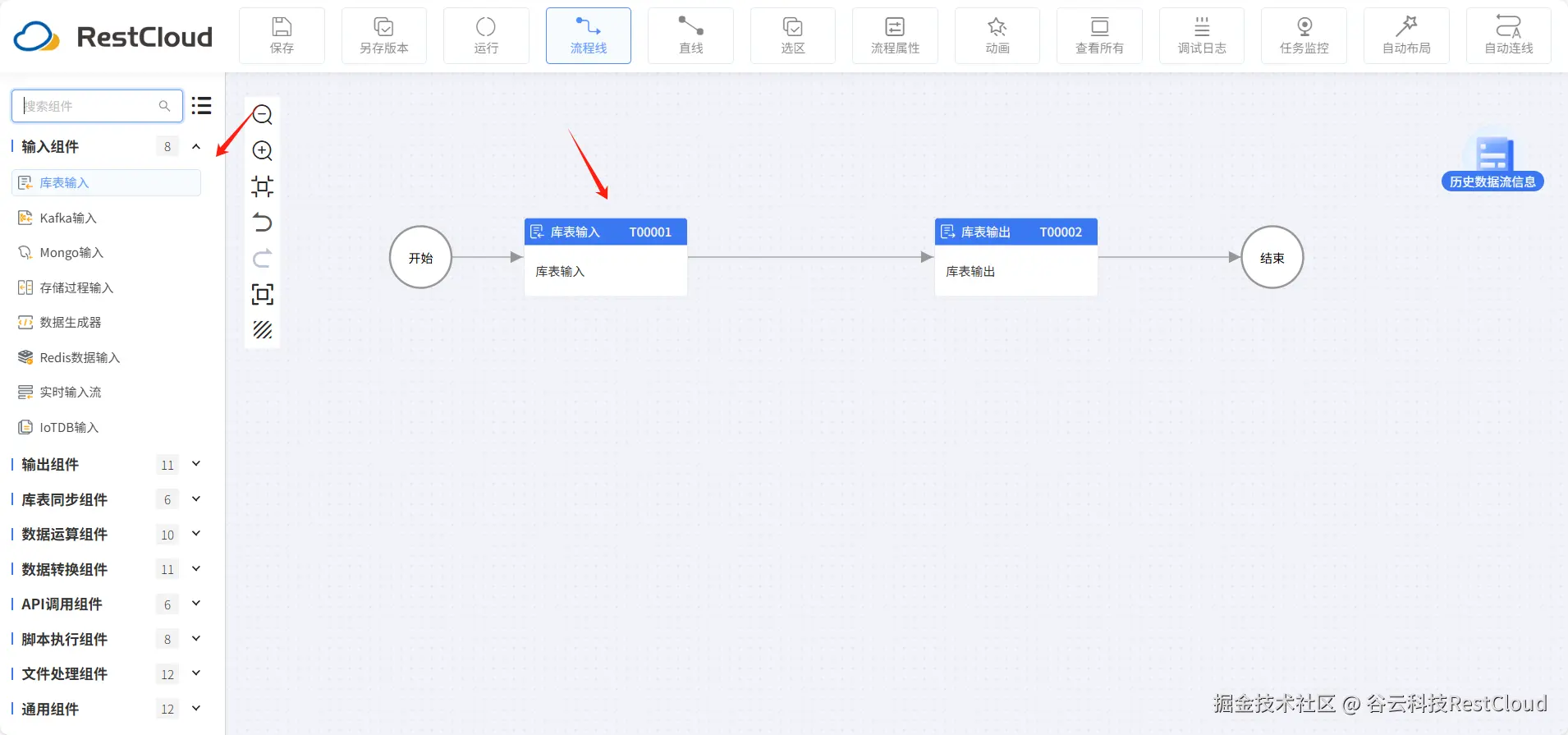
配置库表输入组件,只需选择刚才创建的数据源和数据源中表。当前表中有30万条数据。
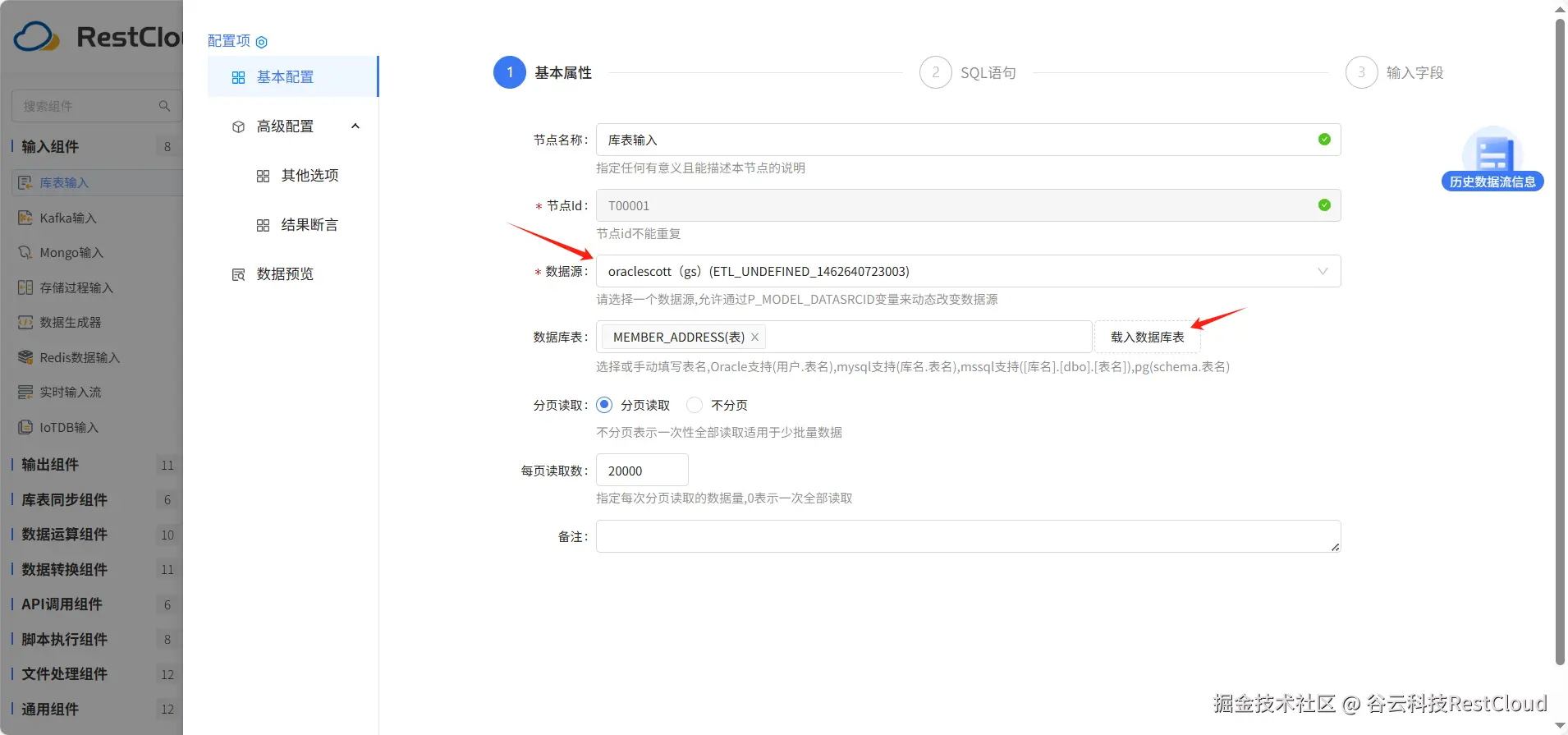
选中表后会默认生成查询语句,也可以更具需要更改语句。后续的输入字段也会自动识别。
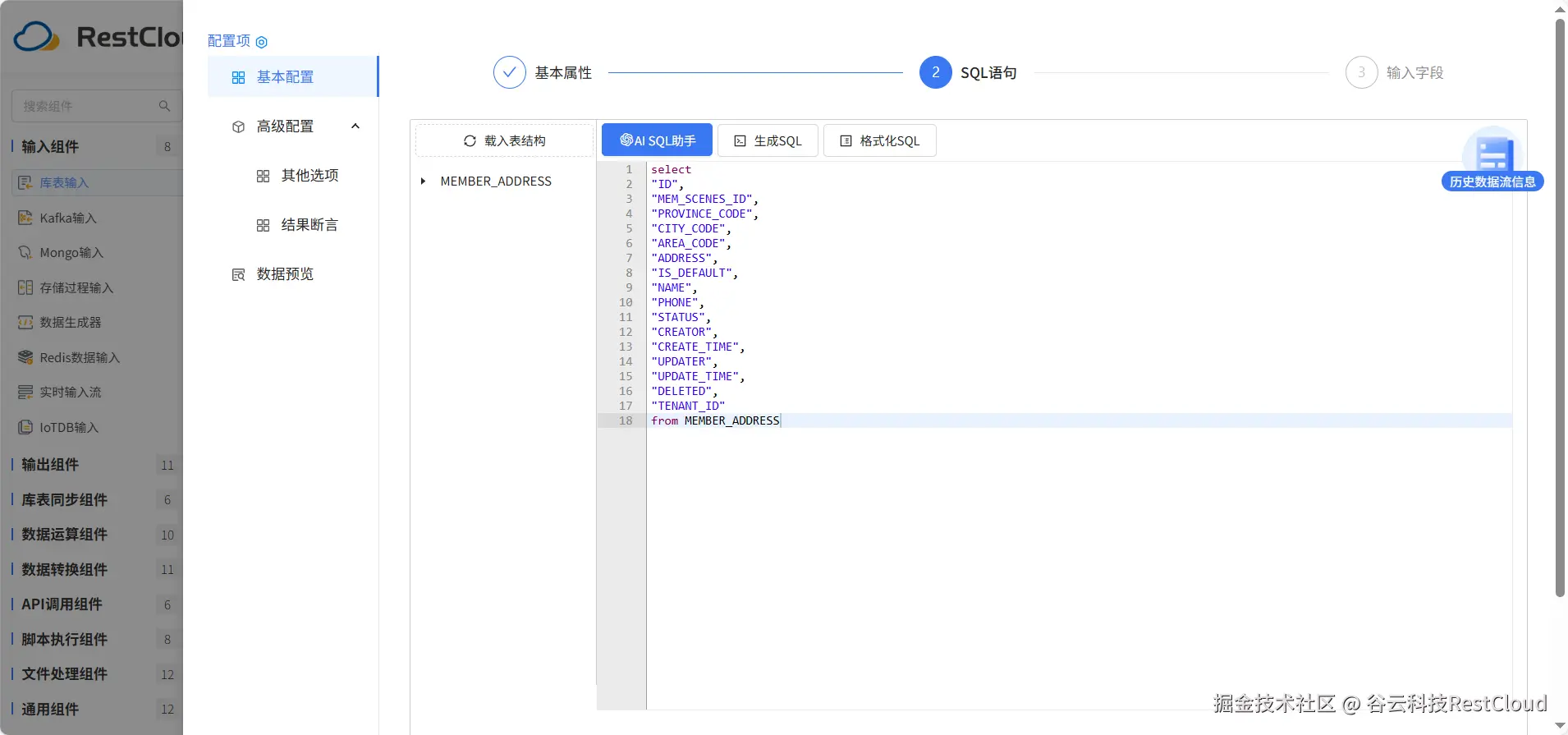
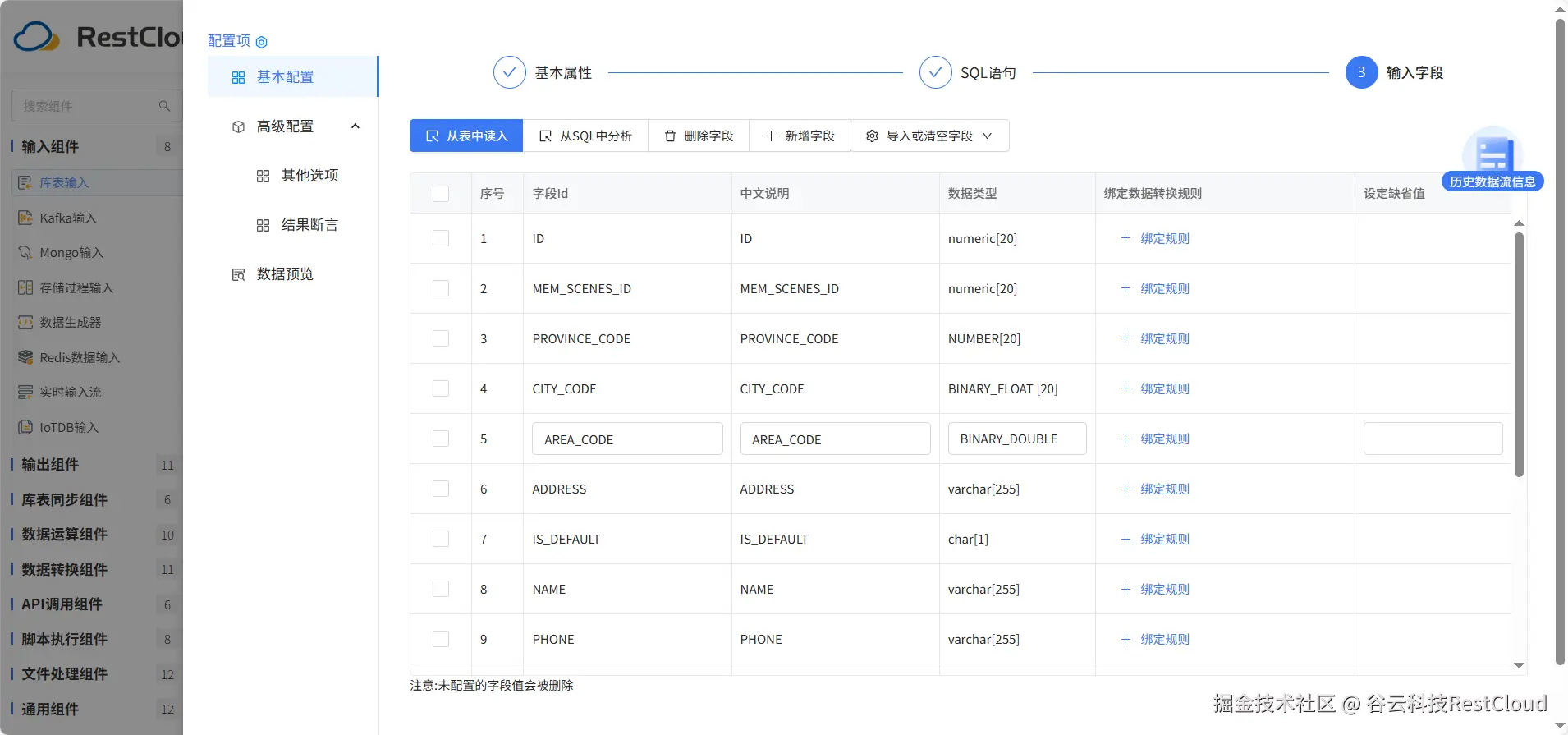
配置库表输出组件,同样的ClickHouse选择数据源和目标表。
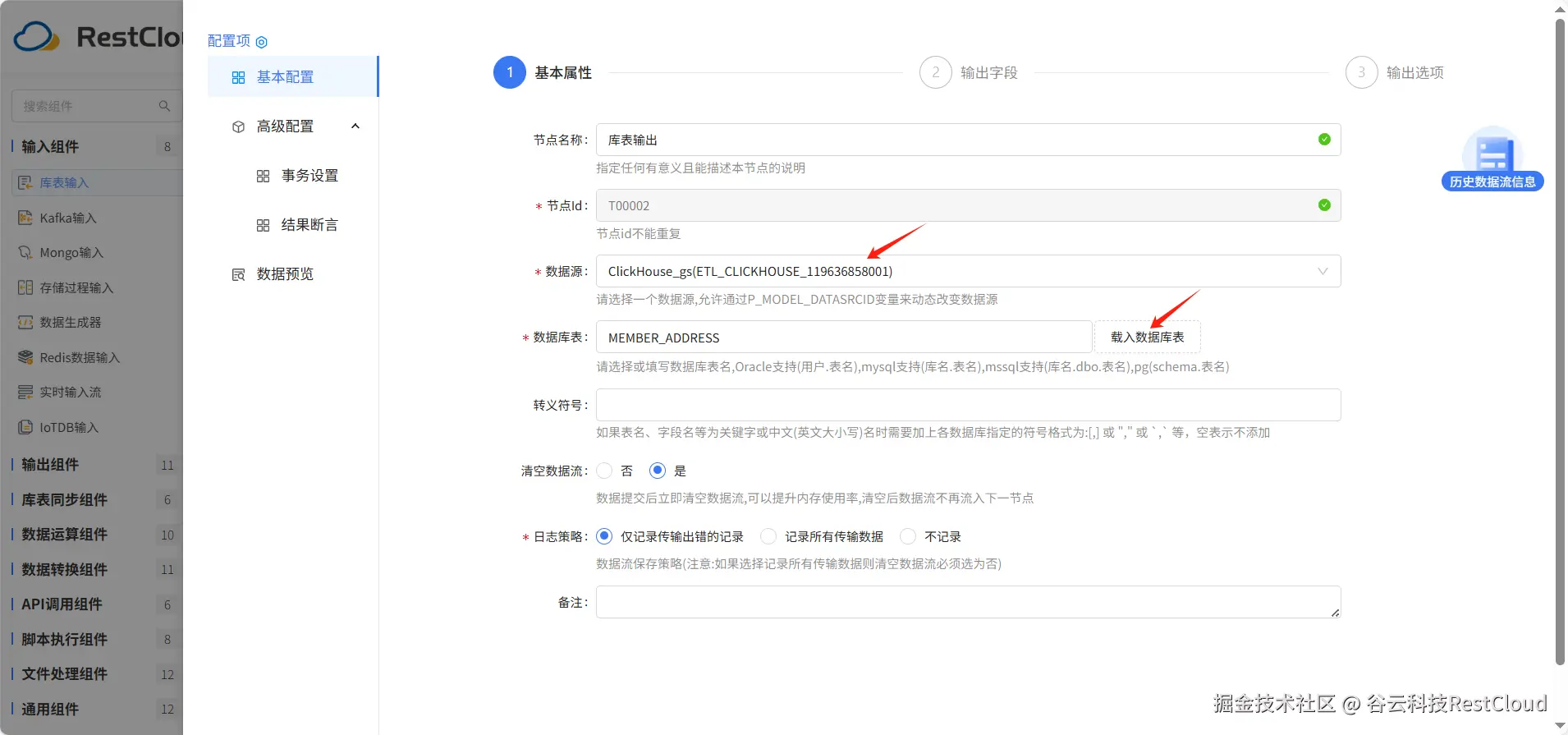
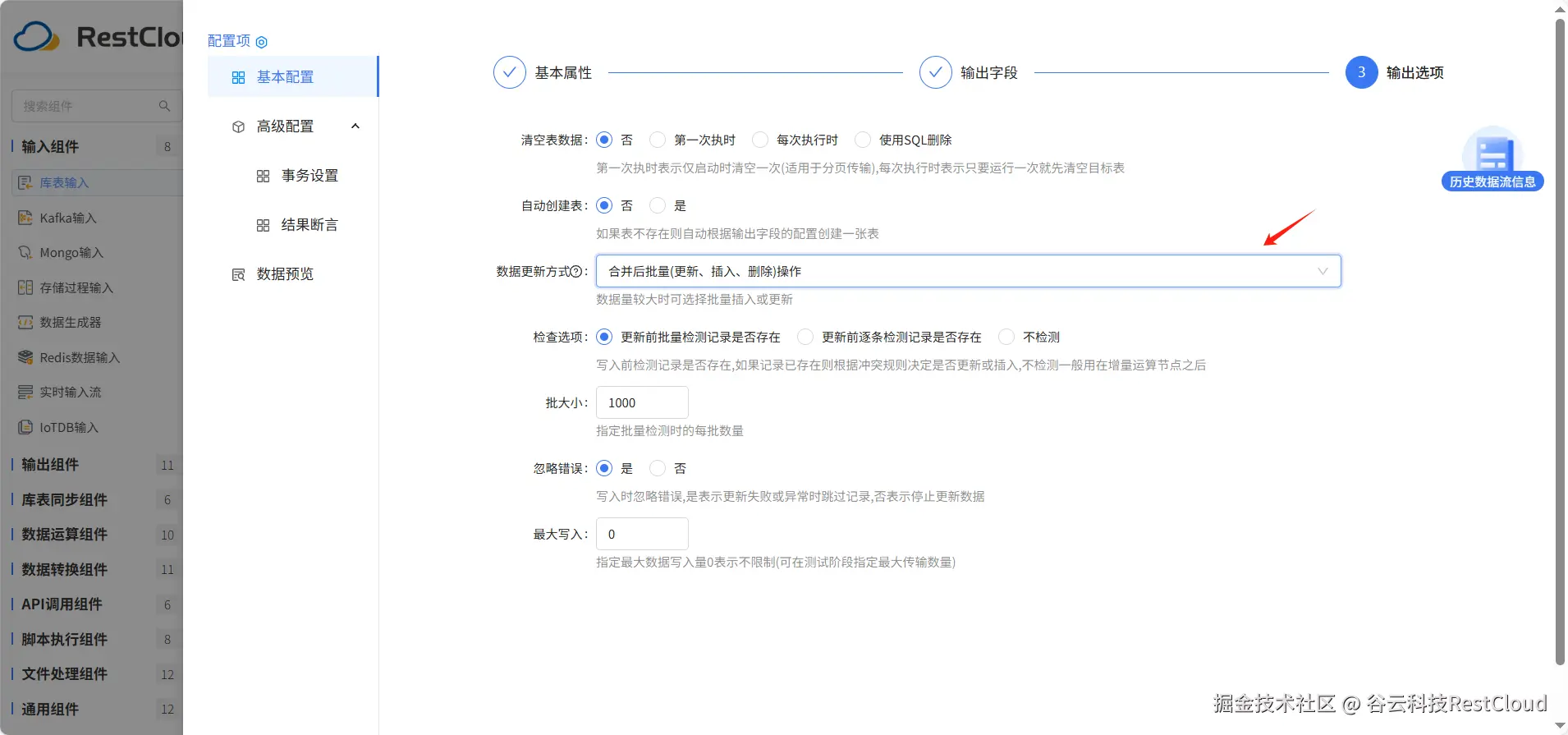
输出字段配置会自动识别表字段,输出选项修改数据更新方式为合并后批量
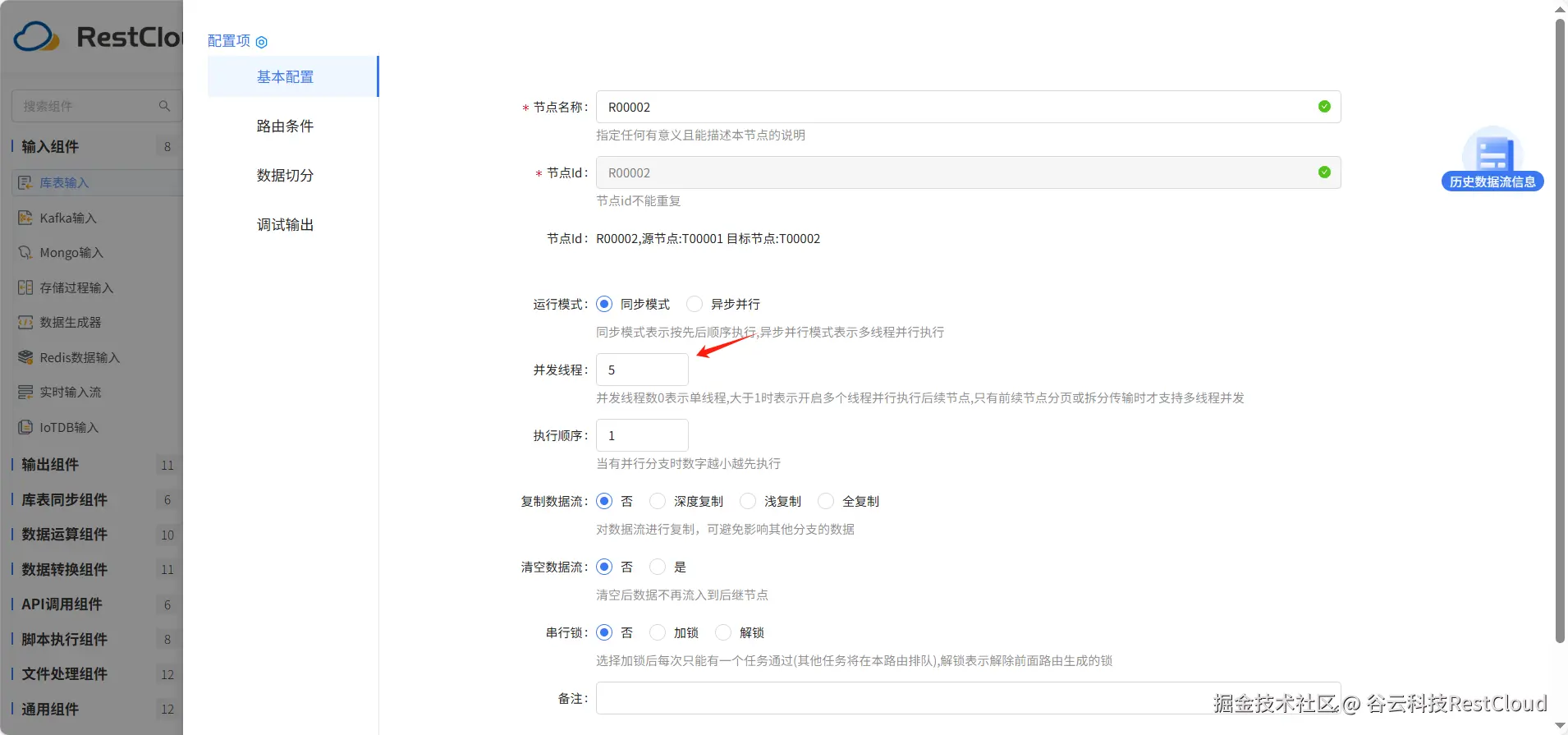
在路由线中开启5个并发线程优化同步速度
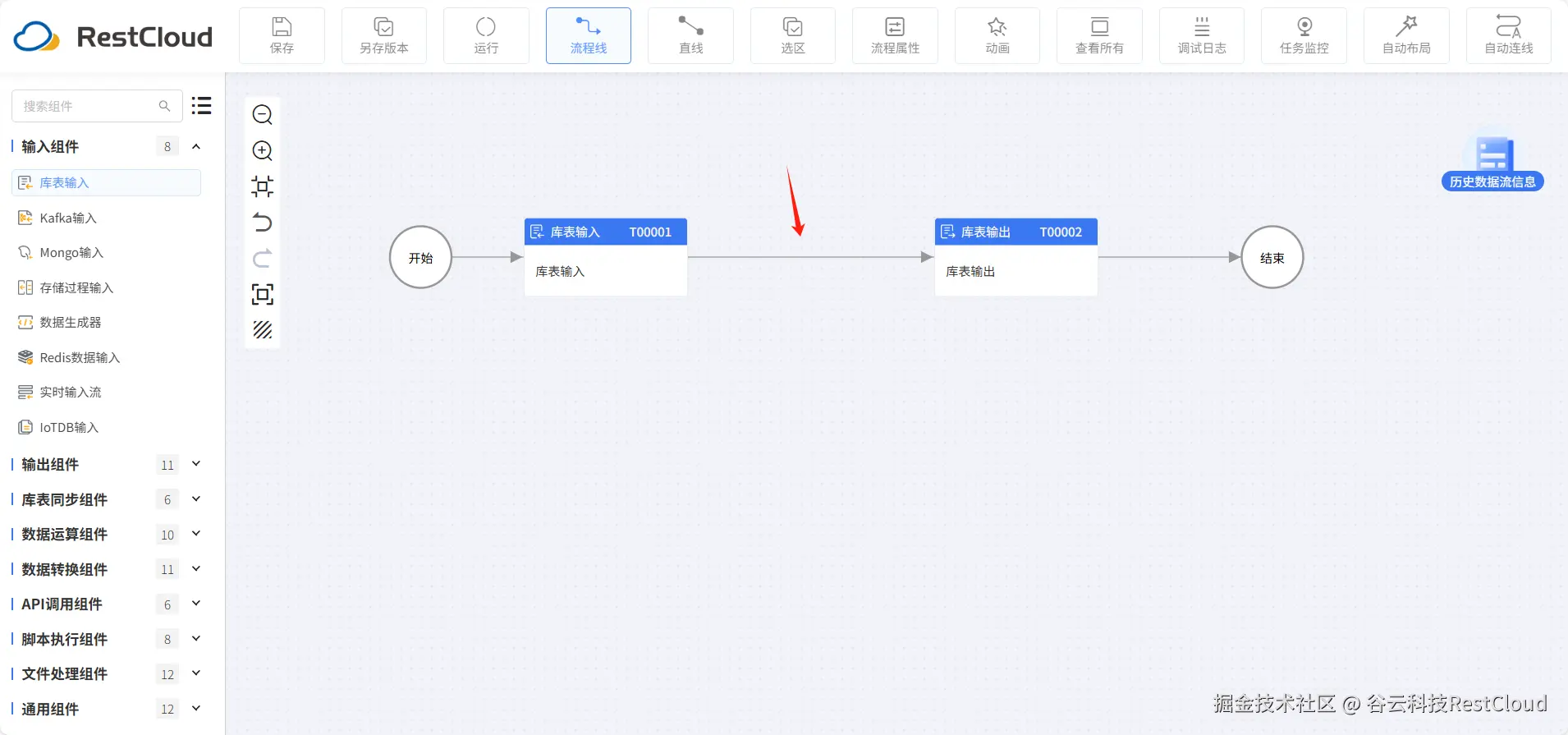
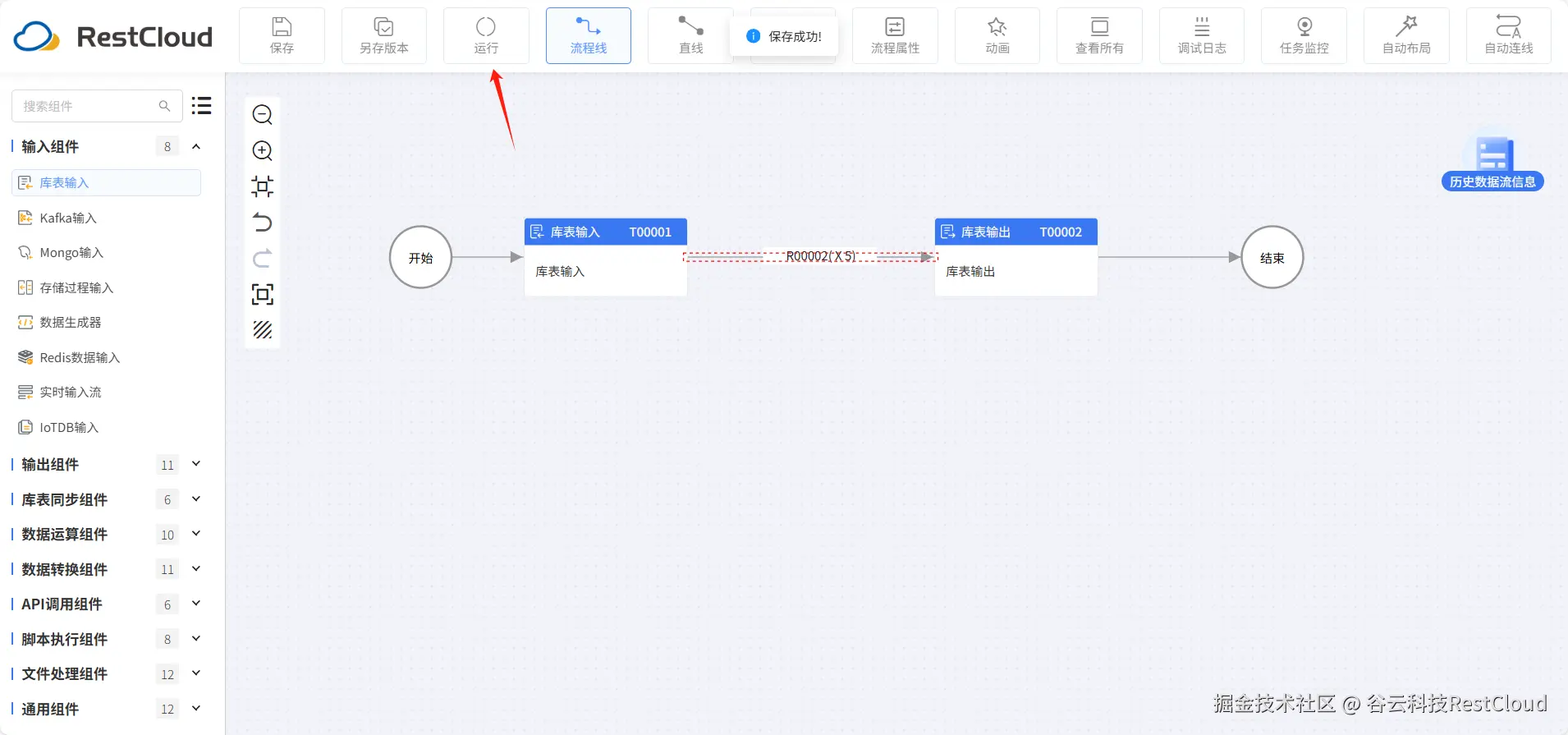
3.执行流程并查看结果
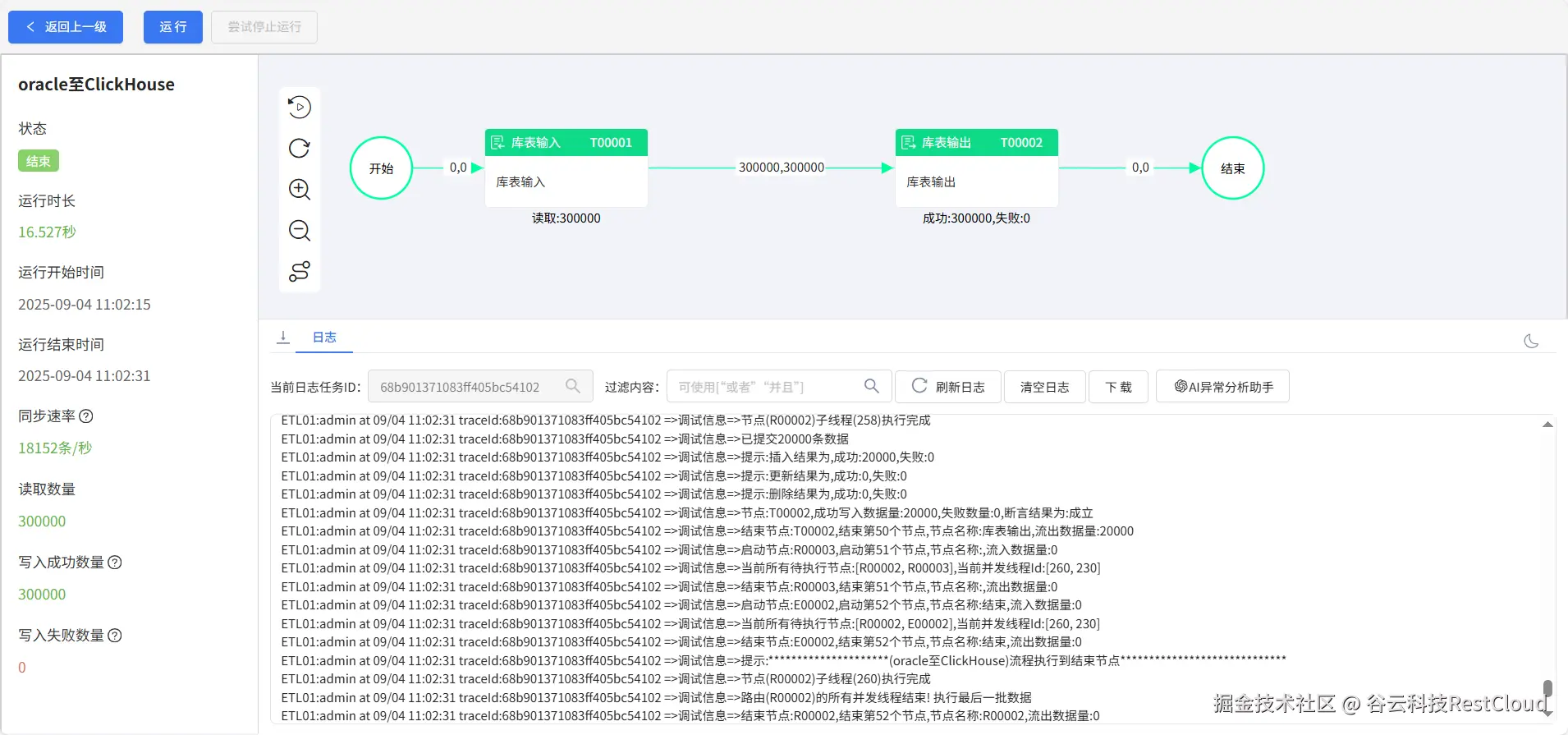
三、总结
从 Oracle 到 ClickHouse 的异构数据库迁移,不仅是技术的切换,更是数据架构思维的转变。ETLCloud 作为企业数据集成的 "得力助手",凭借智能化的字段映射、全场景的兼容性处理、自动化的性能优化,帮助企业轻松跨越迁移鸿沟,无需组建专业的技术团队,无需深入钻研底层技术细节,就能实现从 Oracle 到 ClickHouse 的平滑迁移,让 ClickHouse 的超高查询性能快速落地,为企业实时数据分析、业务决策提供有力支撑。