📚大模型框架系列文章
在大模型应用中,推理性能往往成为限制系统规模和用户体验的关键因素。为此,vLLM 应运而生,提供了高吞吐量、低延迟的推理引擎,并支持多模型协作和异构硬件调度。vLLM 不仅可以独立作为推理服务,还能与 LangChain 等工程框架无缝集成,实现完整的业务流程编排。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案。
- vLLM 的核心架构与推理机制是如何设计的?
- vLLM 如何通过流水线化和 Batch 调度提升吞吐量?
- vLLM 在多模型协作与异构硬件调度方面有哪些工程实践?
1. vLLM 核心架构解析
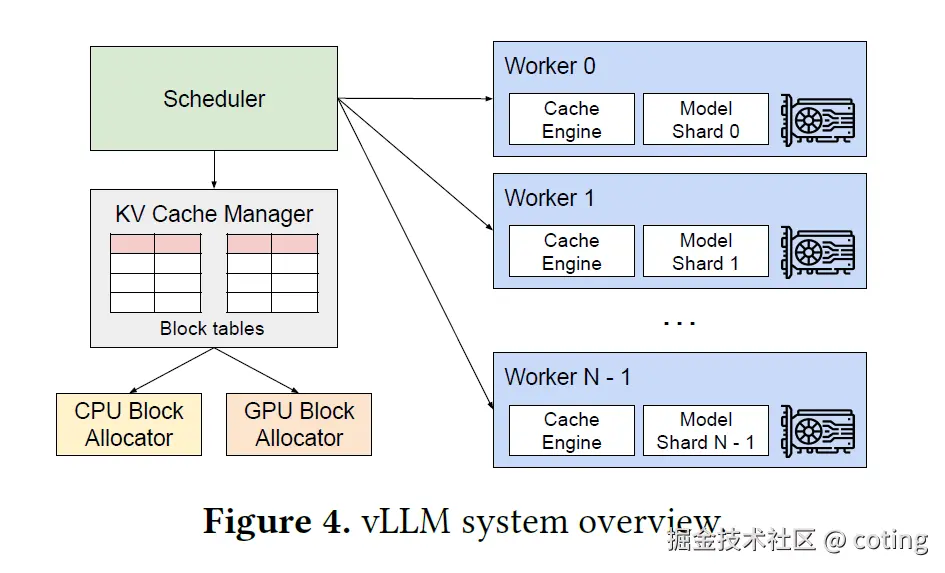
vLLM 是一个高性能推理引擎,核心架构包括模型加载与管理、请求调度、流水线推理、结果汇聚与缓存。它支持多模型并行、异步执行,并能与上层框架(如 LangChain)集成,提供完整业务流程的推理能力。
示例代码:加载模型与单条推理
python
from vllm import LLM, SamplingParams
# 初始化 vLLM 模型
model = LLM(model="huggingface/gpt-j-6B")
# 单条请求推理
response = model.generate(["Hello, world!"], sampling_params=SamplingParams(temperature=0.7, max_output_tokens=50))
print(response[0].text)2. 流水线化推理与 Batch 调度
vLLM 使用流水线化推理,将生成任务拆分为多个阶段(如 token 生成、注意力计算、输出汇总)并行执行,同时结合 Batch 调度,将多个请求合并为一个批次,提高 GPU 利用率和吞吐量。
示例代码:批量推理
python
prompts = ["Hello, how are you?", "What is the capital of France?", "Tell me a joke."]
# 使用 Batch 调度可以显著提升高并发场景下的性能,同时保证响应延迟低。
responses = model.generate(prompts, sampling_params=SamplingParams(temperature=0.7, max_output_tokens=50))
for i, r in enumerate(responses):
print(f"Prompt: {prompts[i]}")
print(f"Response: {r.text}\n")3. vLLM 与 LangChain 集成实践
vLLM 可以作为 LangChain 的底层 LLM 提供高吞吐量推理能力,LangChain 负责任务拆解、Agent 调度和工具调用。这种结合实现了业务逻辑与高性能推理的统一。
示例代码:与 LangChain 集成
python
from langchain import LLMChain, PromptTemplate
from langchain.llms import VLLM
# 通过这种方式,LangChain 管理复杂任务流程,vLLM 提供高性能推理支撑。
# 使用 vLLM 作为 LangChain 的 LLM backend
vllm_llm = VLLM(model="huggingface/gpt-j-6B")
template = PromptTemplate(input_variables=["topic"], template="Write a short paragraph about {topic}.")
chain = LLMChain(llm=vllm_llm, prompt=template)
result = chain.run({"topic": "Artificial Intelligence"})
print(result)4. 异构硬件调度与扩展策略
vLLM 支持在异构硬件环境中优化资源利用,包括 GPU/CPU 混合调度、多 GPU 并行以及动态显存管理。
示例代码:多 GPU 并行推理
python
# 分配模型到不同 GPU
# 异构硬件调度可以显著提升吞吐量,同时避免显存溢出(OOM)。
model_gpu0 = LLM(model="huggingface/gpt-j-6B", device="cuda:0")
model_gpu1 = LLM(model="huggingface/gpt-j-6B", device="cuda:1")
prompts_gpu0 = ["Task for GPU0"]
prompts_gpu1 = ["Task for GPU1"]
responses0 = model_gpu0.generate(prompts_gpu0)
responses1 = model_gpu1.generate(prompts_gpu1)5. 多模型协作与动态路由实现
vLLM 支持动态路由,将不同任务分发给不同模型执行,并结合流水线与 Batch 调度实现高效多模型协作。
示例代码:动态路由执行
python
# 动态路由使系统能够根据任务复杂度和资源状态灵活调度模型,实现高性能和高可用。
tasks = [
{"text": "Write a poem", "model": model_gpu0},
{"text": "Explain quantum physics", "model": model_gpu1}
]
for task in tasks:
resp = task["model"].generate([task["text"]])
print(resp[0].text)最后,我们回答一下文章开头提出的问题
- vLLM 的核心架构与推理机制如何设计?
核心架构包括模型管理、请求调度、流水线化推理和结果汇聚,支持多模型并行和异步执行。 - vLLM 如何通过流水线化和 Batch 调度提升吞吐量?
将任务拆分为流水线阶段并行执行,动态合并请求形成批次,并使用异步调度降低平均延迟。 - vLLM 在多模型协作与异构硬件调度方面有哪些工程实践?
支持多模型路由、动态策略调整、GPU/CPU 异构调度、多 GPU 扩展,以及边缘与云混合部署,实现高性能、高可用推理。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 coting!
以上内容部分参考了 vLLM 官方文档和社区资料。非常感谢,如有侵权请联系删除!