


专栏:MySQL数据库成长记
个人主页:手握风云
目录
[1.1. 主键索引](#1.1. 主键索引)
[1.2. 普通索引](#1.2. 普通索引)
[1.3. 唯一索引](#1.3. 唯一索引)
[1.4. 全文索引](#1.4. 全文索引)
[1.5. 聚集索引](#1.5. 聚集索引)
[1.6. 非聚集索引](#1.6. 非聚集索引)
[1.7. 回表查询](#1.7. 回表查询)
[1.8. 索引覆盖](#1.8. 索引覆盖)
[2.1. 自动创建](#2.1. 自动创建)
[2.2. 手动创建](#2.2. 手动创建)
[2.3. 查看索引](#2.3. 查看索引)
[2.4. 删除索引](#2.4. 删除索引)
[2.5. 创建索引的注意事项](#2.5. 创建索引的注意事项)
一、索引分类
1.1. 主键索引
- 当在一个表上定义一个主键 PRIMARY KEY (以主键列进行排序)时,InnoDB使用它作为聚集索引。
- 推荐为每个表定义一个主键。如果没有逻辑上唯一且非空的列可以使用主键,则添加一个自增列。
1.2. 普通索引
- 最基本的索引类型,没有唯一性的限制。
- 可能为多列创建组合索引,称为复合索引或组全索引(可以是单列也可以是多列)。
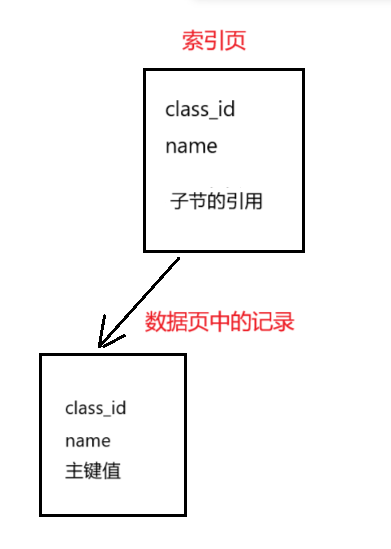
复合索引中包含了创建索引时的所有列,比如用class_id和name这两个列创建一个复合索引,先按class_id进行排序,在这个基础上再对name进行排序。比如字典中拼音音节索引就是复合索引,先排序声母再排序韵母。子节点向下延伸,保存下一页的索引。每一次索引都会创建一棵索引树。当往数据库中写入数据时,不但会更新主键索引树还是会其他所有的索引树。每个索引树都会消耗磁盘空间。
1.3. 唯一索引
- 当在一个表上定义一个唯一键 UNQUE 时,自动创建唯一索引。
- 与普通索引类似,但区别在于唯一索引的列不允许有重复值。
1.4. 全文索引
- 基于文本列(CHAR、VARCHAR或TEXT列)上创建,以加快对这些列中包含的数据查询和DML操作。
- 用于全文搜索,仅MyISAM和InnoDB引擎支持。
全文索引主要针对大文件数据比如报刊日志进行索引,但在实际开发中,有专门的文档类型的数据库,可以高效处理文档的检索,比如MongoDB。
1.5. 聚集索引
一个表中肯定会有一个聚集索引。
- 与主键索引是同义词。
- 如果没有为表定义 PRIMARY KEY,InnoDB使用第一个 UNIQUE 和 NOT NULL 的列作为聚集索引。
- 如果表中没有 PRIMARY KEY 或合适的 UNIQUE 索引,InnoDB会为新插入的行生成一个行号并用6字节的ROW ID 字段记录, ROW ID 单调递增,并使用 ROW ID 做为索引。
1.6. 非聚集索引
- 聚集索引以外的索引称为非聚集索引或二级索引。
- 二级索引中的每条记录都包含该行的主键列,以及二级索引指定的列,一个列或多个列都可以。
1.7. 回表查询
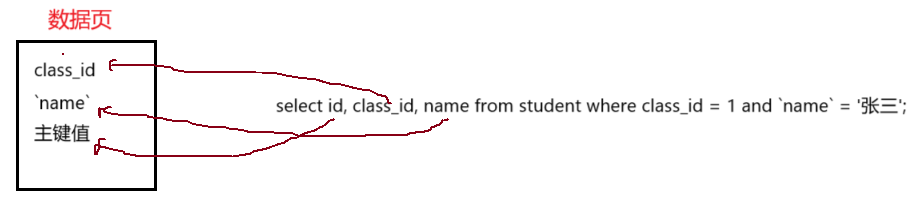
比如用 class_id 和 name 这两个列创建一个复合索引。select * from student where class _id = 1 and `name`= '张三';先通过索引的第一个列找到范围的起点,再通过第二个索引列在范围内进一步筛选。由于当前使用了class_id和name的复合索引,在数据页中得到的记录是class id + name +主键值。但是现在查询的列中指定是*(所有列),当前索引页中的数据不支持返回查询结果,这时就需要拿到主键值,回到主表(主键索引树)中进行查询,就可以得到所有的列。这种拿着主键值去主表中进一步查询的行为,称为回表查询。
1.8. 索引覆盖
当⼀个select语句使⽤了普通索引且查询列表中的列刚好是创建普通索引时的所有或部分列,这时就可以直接返回数据,而不⽤回表查询,这样的现象成为索引覆盖。
二、使用索引
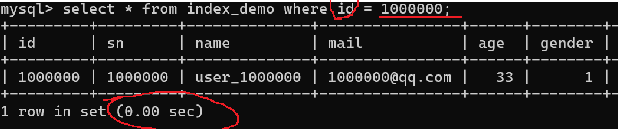
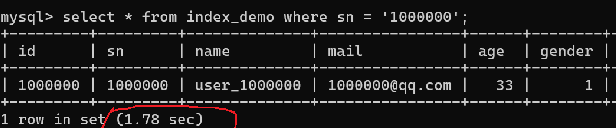
如果不使用索引进行查询,耗时将会非常久,尤其是在访问网页的操作中,往往是多条查询,效率非常低下。为了提升效率,那么就需要在经常被做查询条件的列上去创建索引。
2.1. 自动创建
- 当我们为一张表加主键约束(Primary key)外键约束(Foreign Key)唯一约束(Unique)时,MySOL会为对应的的列自动创建一个索引。
- 如果表不指定任何约束时,MySOL会自动为每一列生成一个索引并用ROW_ID进行标识,并且根据ROW_ID创建索引树。
2.2. 手动创建
- 主键索引
sql
-- 1. 创建表时创建主键
create table t_test_pk1 (
id bigint primary key auto_increment,
`name` varchar(20)
);
-- 2. 创建表时单独指定主键列
create table t_test_pk2 (
id bigint auto_increment, -- 只指定自增的列
`name` varchar(20),
primary key (id) -- 单独定义主键列
);
-- 3. 修改表中的列为主键索引
create table t_test_pk3 (
id bigint,
`name` varchar(20)
);
alter table t_test_pk3 add primary key (id);
alter table t_test_pk3 modify id bigint auto_increment;
对于主键的删除,我们可以查看MySQL官方文档里面的SQL statement。
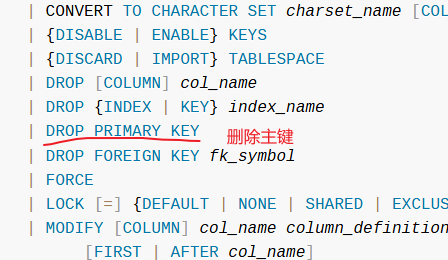
- 唯一索引
sql
-- 1. 创建表时创建唯一键
create table t_test_uk1 (
id bigint primary key auto_increment,
`name` varchar(20) unique
);
-- 2. 创建表时单独指定唯一列
create table t_test_uk2 (
id bigint primary key auto_increment, -- 只指定自增的列
`name` varchar(20),
unique (`name`)
);
-- 3. 修改表中的列为唯一索引
create table t_test_uk3 (
id bigint primary key auto_increment,
`name` varchar(20)
);
alter table t_test_uk3 add unique (`name`);
我们也可以为唯一索引起名字,删除的时候就可以直接根据这个名字进行删除。
sql
-- 根据索引名删除
DROP {INDEX | KEY} index_name
sql
-- 为唯一索引指定名字
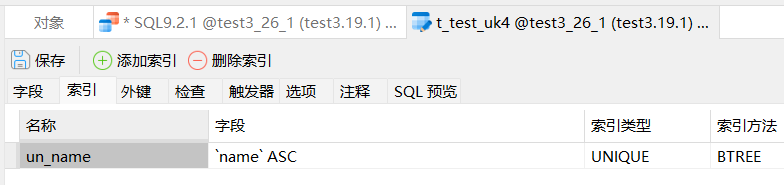
create table t_test_uk4 (
id bigint primary key auto_increment, -- 只指定自增的列
`name` varchar(20),
unique un_name (`name`)
);
如果业务中有唯一属性,强烈建议加上唯一索引,对以后的优化起到关键作用。
- 普通索引
创建时机:1. 创建表的时候如果可以预期到某个列是一个频繁查询的列,直接在这个列上创建索引。数据量比较小的系统,一般当表中的数据量到达十几万的时候再去创建索引,因为创建索引之后会单独维护一个索引树,当表中的数据量比较少的时候,有时候使用全表扫描甚至比使用索引快(是否使用索引由MySQL内部的优化器决定的)。2. 随着业务数据不断增多,在版本迭代的过程添加索引,当系统运行的过程中出现了慢SQL(运行的时间比较长的SQL),就可以针对性的添加索引。
sql
-- 创建表时指定索引列
create table t_test_index1 (
id bigint primary key auto_increment,
name varchar(20) unique,
sno varchar(10),
index(sno)
);
-- 修改表中的列为普通索引
create table t_test_index2 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
alter table t_test_index2 add index (sno);
-- 单独创建索引并指定索引名
create table t_test_index3 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
create index index_name on t_test_index3(sno);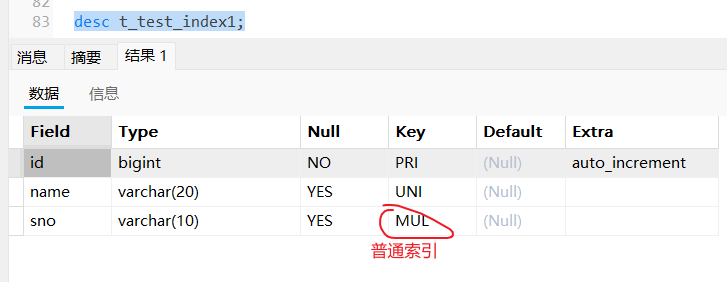
2.3. 查看索引
sql
-- 语法
-- 方法一
show keys from 表名;
-- 方法二
show index from 表名;
sql
-- 查看索引
show index from t_test_uk4;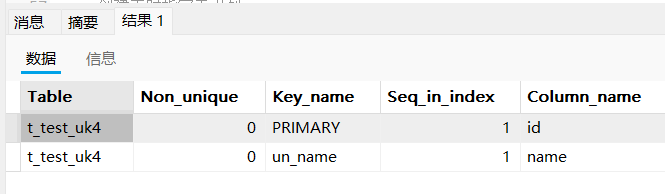
2.4. 删除索引
- 删除主键索以
sql
-- 语法
-- 因为一个表只有一个主键,所以这里不写索引名
alter table 表名 drop primary key;
sql
alter table t_test_pk1 drop primary key;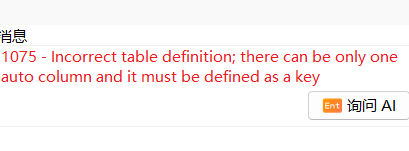
如果主键是自增列,则需要先把自增属性取消掉,再删除主键。
sql
alter table t_test_pk1 modify id bigint; -- 取消自增属性
alter table t_test_pk1 drop primary key;
desc t_test_pk1;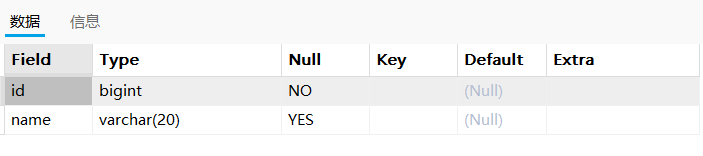
- 普通索引
sql
-- 语法
alter table 表名 drop index 索引名;索引名可以利用前面的查看索引来找到。
2.5. 创建索引的注意事项
- 索引应该创建在高频查询的列上;如果出现慢查询,都要创建索引。
- 索引需要占用额外的存储空间。
- 对表进⾏插入、更新和删除操作时,同时也会修改索引,可能会影响性能,因为索引有单独的索引树。
- 创建过多或不合理的索引会导致性能下降,需要谨慎选择和规划索引。