引言:语音交互的进化之路
语音作为人类最自然的交流方式,正推动人机交互迈向智能化时代。传统语音助手(如Siri、小爱同学)依赖ASR→NLP→TTS三级技术栈,存在信息损耗与延迟问题。而端到端语音大模型的崛起,正以"语音直达语音"的方式重塑交互体验。本文将解析ASR核心技术原理,并以Whisper模型为例,演示零代码部署方案及其在中文环境的实践挑战。
一、科普一下语音
语音的基本概念
语音是一个复杂的现象。我们基本上不知道它是如何产生和被感知的。我们最基础的认识就是语音是由单词来构成的,然后每个单词是由音素来构成的。但事实与我们的理解大相径庭。 语音是一个动态过程,不存在很明显的部分划分。 通过音频编辑软件去查看一个语音的录音对于理解语音是一个比较有效的方法。下面就是一个录音在音频编辑器里的显示的例子。 
目前关于语音的所有描述说明从某种程度上面讲都是基于频谱的。这意味着在语音单元或者单词之间并没有确定的边界。语音识别技术没办法到达100%的准确率。这个概念对于软件开发者来说有点不可思议,因为他们所研究的系统通常都是确定性的。另外,对于语音技术来说,它会产生很多和语言相关的特定的问题。
语音的构成
在本文中,我们是按照以下方式去理解语音的构成的: 语音是一个连续的音频流,它是由大部分的稳定态和部分动态改变的状态混合构成。 一个单词的发声(波形)实际上取决于很多因素,而不仅仅是音素,例如上下文、说话者、语音风格等。
语音交互
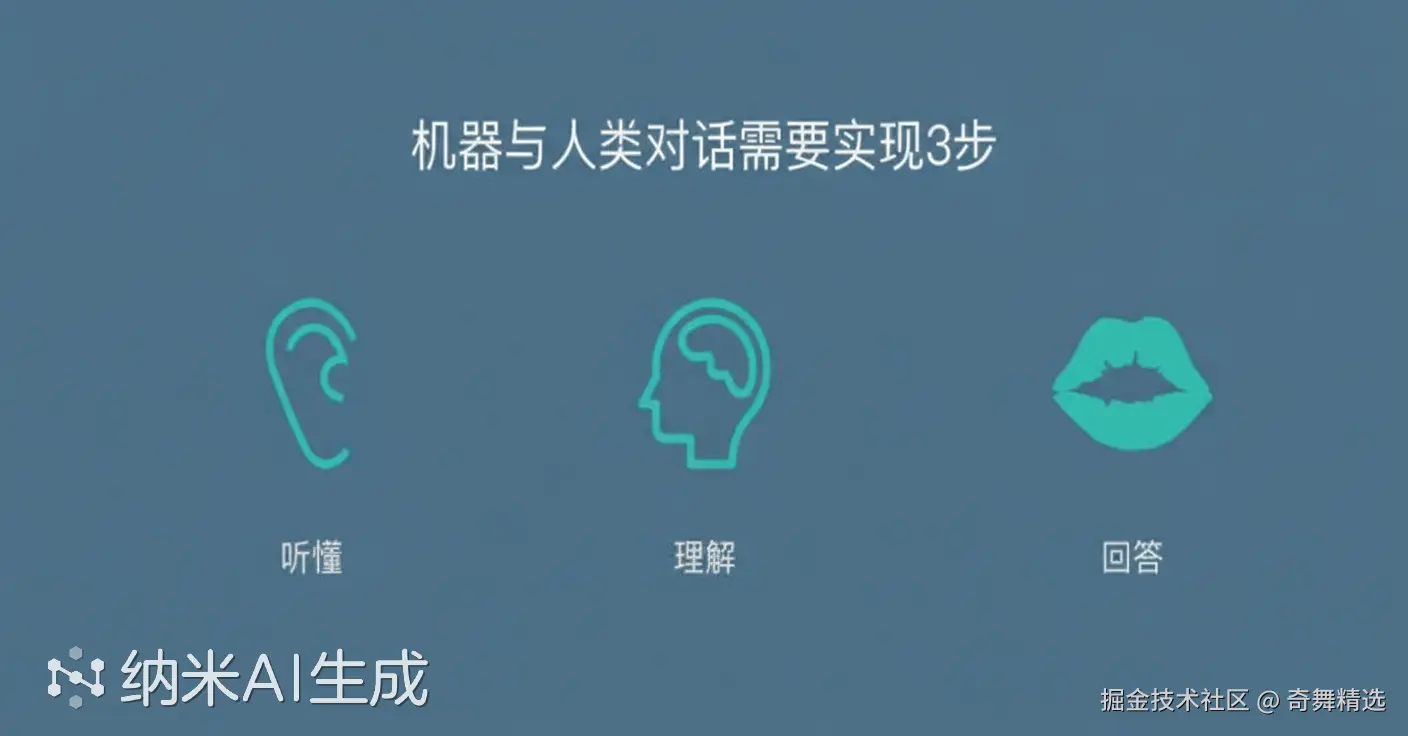
实际上,当前的Siri和小爱同学的每一句话背后都依赖于三项核心技术:自动语音识别(ASR)、自然语言处理(NLP)、文本到语音转换(TTS), 对应的便是"耳"、"脑"、"口"的工作。 他们构成了人机语音交互的基础。三剑合璧,称霸江湖长达60年之久。这三项技术共同作用,使得语音助手能够理解我们的语言,进行有效的对话。 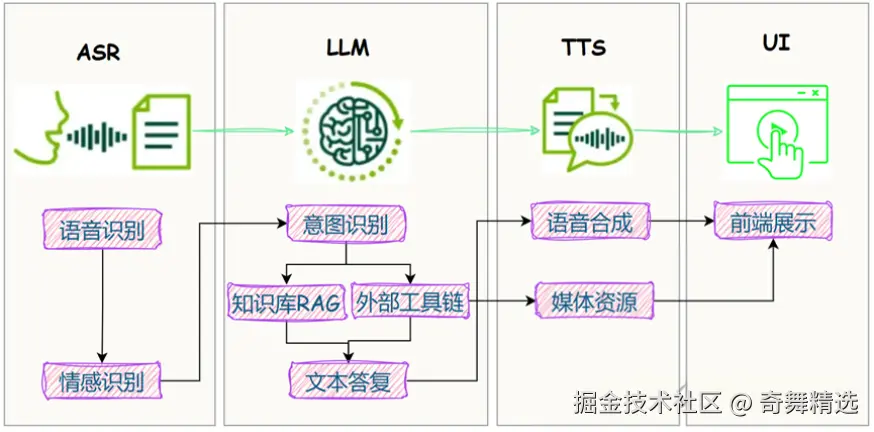 如图所示,
如图所示,
- ASR:负责将人的语音转化为机器可读的文字,是语音输入的第一步。
- 自然语言处理(NLP):处理文本数据,包含了理解、生成或匹配文本内容,是连接语音与文本的关键桥梁,是实现用户提问到机器回答的关键环节,决定了机器的智商。通常包含了规则处理、意图识别、QA匹配,当然最新的LLM可以搞定这一切。
- TTS:将文本转换成自然流畅的语音输出,使得机器能够"说话"。
二、技术基石:ASR的核心工作流
自动语音识别(ASR)是机器的"听觉系统",它通过分析和处理音频信号,识别其中的语音内容,并将其转化为文字输出。其流程可拆解为四步: 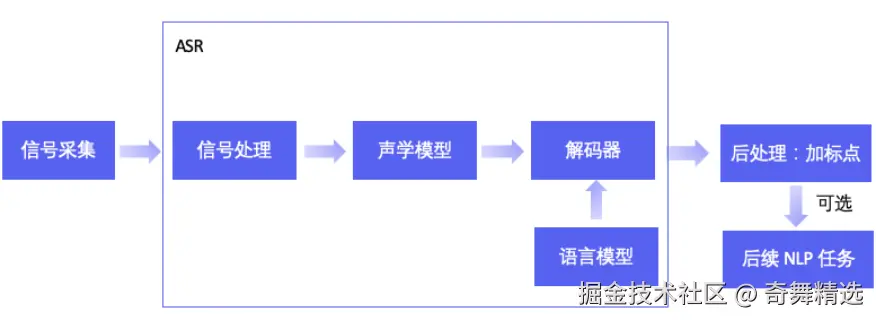
- 预处理
通过麦克风或其他音频输入设备捕获用户的语音信号。对语音信号进行噪声抑制、语音增强等预处理,以提高识别的准确性。
采样量化 → 降噪 → 端点检测(VAD) → 预加重高频
目标:提取纯净有效语音段 - 特征提取
特征提取是将预处理后的语音信号转换为能够表征语音特性的特征向量
关键特征:MFCC(模拟人耳听觉)、LPC(语音生成建模)、PLP(感知增强)
输出:表征声学特性的特征矩阵 - 声学+语言模型协同
声学模型:将特征映射为语音单元,比如音素(CNN/RNN/LSTM/CTC)
语言模型:语言模型提供语言知识约束,提高识别准确率,利用语言模型将识别的语音单元组合成连贯的文本。 - 解码输出
解码是将声学模型和语言模型结合,搜索最优词序列的过程。动态规划算法(Viterbi/集束搜索)生成最优文本序列。
ASR技术的发展历程
1952年,贝尔实验室首次尝试了自动语音识别技术AUDREY,它可以在受控条件下识别说出的数字,但AUDREY昂贵的成本和复杂的真空管电路带来的维护问题限制了它的实用性。后面又经历了模式识别阶段、统计模型阶段,发展到现代的深度学习革命,完成端到端系统的显著演进,识别准确率和鲁棒性显著提升。
三、端到端语音模型掀起实时交互新浪潮
3.1 传统级联方案的局限
过去的AI语音交互系统大多采用多阶段级联架构,虽然可以实现基本的语音转换功能,但存在显著缺陷:
信息传递损耗:ASR文本→NLP理解→TTS语音的多次转换,容易造成细节丢失;
高延迟:平均响应>4秒,机械感强,模块协同工作增加了系统的复杂度和延迟时间;
副语言信息丢失:由于各模块独立运行,此类系统难以理解语音中的情绪、语气和停顿等副语言信息,无法捕捉情感、语调等非文本信号,使得语音交互始终"人机感"浓重,难以模拟真实对话情境。
3.2 端到端架构给AI注入"灵魂"
2025年,语音大模型迎来"去文本化"拐点。端到端架构实现了"语音输入-语音输出"一体化处理,将传统级联模式(ASR→NLP→TTS)的响应延迟从4秒压缩至500毫秒内,彻底告别机械对话感。 这种端到端语音的好处具体来说: 数据流简化:用户的声音输入可以直接被处理成相应的输出,而无需经过中间步骤。 低延时响应:减少了不同组件之间的传递时间和计算开销,使得实时互动更加流畅。 高质量情感表达:通过大规模预训练和微调,新模型能够捕捉并重现说话者的情感特征,使合成语音听起来更加生动逼真。 
发展
随着大模型技术的发展,如今的语音交互实现了语音理解与生成在同一模型中的协同完成,能够更自然流畅地进行对话。去年,GPT-4o向世界展示了"真人感"语音交互的可能性,但在中文表现上仍有局限。而火山引擎今年年初发布的豆包·实时语音模型,凭借更强的中文理解力和高情商反馈,展现了中文语音交互的理想雏形。
语音交互的庞大潜力,已在业内成为共识。这一交互形态原生的沉浸感、陪伴感,使其在语音助手、AI硬件、内容制作与消费等领域展现出独特的优势和广阔的应用场景。随着生成式AI驱动的语音技术不断进化,语音或许有望成为下一代人机交互的主要入口之一。
四、 Whisper模型的本地部署
Whisper是OpenAI开发的先进语音识别模型,采用端到端的架构设计,能够直接将音频转换为文本,无需传统ASR系统中的复杂中间步骤。
部署架构
Whisper模型支持多种本地部署架构,主要包括:
1.独立Python环境部署:通过pip安装OpenAI的官方Whisper包,适合个人开发和小规模应用
2.Docker容器化部署:将Whisper及其依赖打包为容器,便于在不同环境中一致运行
3.Web API服务部署:使用Flask或FastAPI封装Whisper功能,提供RESTful接口
4.桌面应用集成:将Whisper嵌入到桌面应用中,提供图形界面操作
硬件配置要求
| 模型版本 | 参数量 | 最小内存 | GPU显存 | 适用场景 |
|---|---|---|---|---|
| tiny | 39M | 1GB | 可选 | 嵌入式设备 |
| medium | 769M | 6GB | ≥4GB | 高精度转写 |
| large-v3 | 1550M | 8GB | ≥8GB | 专业级多语种任务 |
| 对于实时处理,建议使用至少8GB显存的NVIDIA GPU,以获得流畅体验。CPU模式下,推荐使用tiny或base版本以保证合理的处理速度。 |
部署步骤
1.环境准备:
安装Python
确保你的系统上安装了Python 3.8及以上版本。可以从Python官方网站下载并安装。
创建虚拟环境(可选)
bash
python -m venv whisper-env
source whisper-env/bin/activate # Linux/Mac
# 或 whisper-env\Scripts\activate # Windows安装依赖
pip install torch torchaudio
pip install openai-whisper2.模型下载与使用:
ini
import whisper
# 加载模型(首次运行会自动下载)
model = whisper.load_model("medium")
# 语音识别,并转写音频
result = model.transcribe("audio.mp3")
print(result["text"])性能优化技巧:
- 实时流处理:结合WebSocket分块传输音频流
- 量化加速 :使用
torch.quantize压缩模型体积 - 指定语言提高准确性:model.transcribe的language参数
- 长音频处理 :启用
return_timestamps=True分段预测
ini
# Whisper 默认只支持处理最多 30 秒的音频。当音频超过 30 秒时,模型会自动启用长音频生成模式,这需要预测时间戳标记。显式设置 return_timestamps=True。
import whisper
model = whisper.load_model("medium") # 自动下载模型
result = model.transcribe("audio.mp3", language='zh', word_timestamps=True)
print(result["text"]) # 带时间戳的中文文本 - 批处理处理多个文件时重用模型:
ini
model = whisper.load_model("medium")
for file in audio_files:
result = model.transcribe(file)
save_result(file, result)五、中文场景实战:挑战与优化策略
5.1 独特挑战
| 挑战类型 | 案例 | 技术影响 |
|---|---|---|
| 声调敏感性 | "妈(mā)" vs "骂(mà)" | 音高特征提取偏差 |
| 方言多样性 | 粤语/闽南语混用 | 模型泛化能力不足 |
| 同音词歧义 | "公式" vs "公事" | 上下文依赖增强 |
5.2 优化方案
- 数据层面:注入方言语料(如AISHELL-3数据集)
- 声学模型 :
- 引入音高轮廓特征强化声调建模
- 使用Conformer架构捕捉长距离依赖
- 语言模型 :
-
融合BERT语义理解消解同音词歧义
-
知识图谱辅助专有名词识别(如"哪吒"读音)
-
六、未来趋势:语音交互的下一站
- 情感计算:实时捕捉语调情绪(兴奋/低落/愤怒)生成共情回复
- 多模态融合:唇读视觉信号+音频联合降噪(会议场景鲁棒性提升)
- 边缘智能:轻量化模型(<50MB)部署至手机/IoT设备
- AIGC内容革命:类"豆包·播客"模型生成双人对话播客,支持插话/语气词