JVM学习
文章目录
前言
- 因为JVM内部涉及的内容很广泛,我们这里主要讨论三个问题
- JVM内存区域的划分
- JVM中类加载的过程
- JVM的垃圾回收机制
内存区域划分
- 一个运行起来的Java进程,就是一个JVM虚拟机,就需要从操作系统申请一大块内存
- 会把这一块内存,划分成不同的区域,每块区域都有不同的作用
JVM 申请了一大块内存之后,也会划分成不同的内存区域~~
- 方法区(1.7 及其之前) / 元数据区 (1.8 开始)
- 这里存储的内容,就是类对象
- class 文件,加载到内存之后,就成了类对象了。
- 堆
- 这里存储的内容,就是代码中 new 的对象。
(占据空间最大的区域)
- 栈
- 这里存储的内容,就是代码执行过程中,方法之间的调用关系
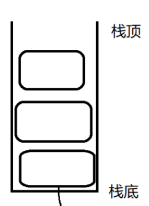
- 每个元素,称为 "栈帧"
- 每个栈帧,就代表了一个方法调用
- 栈帧里就包含了方法的入口,方法返回的位置
方法的形参,方法的返回值,局部变量......
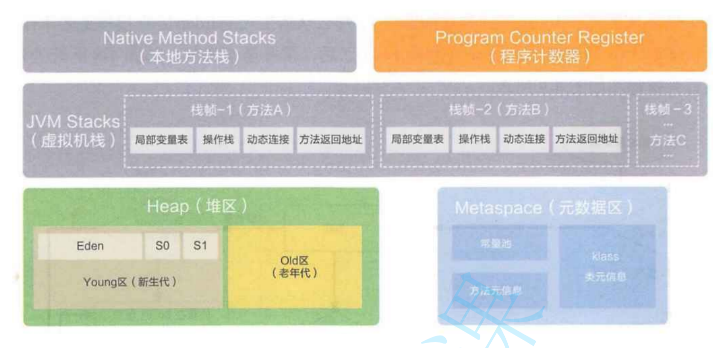
- 程序计数器
- 比较小的空间,主要就是存放一个"地址",表示,下一条要执行的指令,在内存中的哪个地方
- 刚开始调用方法,程序计数器,记录的就是方法的入口的地址。随着一条一条的执行指令,每执行一条,程序计数器的值都会自动更新去指向下一条指令
- 方法区里:
每个方法,里面的指令,都是以二进制的形式,保存到对应的类对象中的
java
class Test {
public void a() { ... }
public void b() { ... }
}- 这里的方法 a 和 方法 b 都会被编译成二进制的指令,就会放到 .class 文件中
执行 类加载 的时候,就能够把 .class 文件里的内容,给加载起来,放到类对象里 - 此时,方法的二进制指令,也就进入类对象了.
注意:
- 如果是一个顺序执行的代码,下一条指令就是把指令地址进行递增
- 如果是条件/循环代码 ,下一条指令就可能会跳转到一个比较远的地址
- 本地方法,指的是使用 native 关键字修饰的方法.这个方法不是使用 Java 实现,而是在 jvm 内部通过 C++ 代码实现的,
JVM 内部的 C++ 代码调用关系~~
变量储存区域问题:
一个变量处于哪个区域,和变量的形态密切相关
- 局部变量 处于 栈上
- 成员变量 处于 堆上
- 静态变量 (也叫做 类属性)
包含在类对象中,也是在方法区/元数据区里头
JVM中线程的内存空间特点:
-
一个 JVM 进程里,可能有多个线程.
每个线程,有自己的程序计数器,和栈空间.
这些线程共用同一份 堆 和 方法区.
-
衍生说法:每个线程都有自己私有的栈空间~~
这种说法,也可以认为是对的~~
类加载过程
- java代码会被编译成.class文件(包含了一些字节码),java程序要想运行起来,就需要让jvm读取到这些.class文件,并且把里面的内容,构造成类对象,保存到内存的方法区中.
- 所谓的"执行代码",就是调用方法.
- 就需要先知道每个方法,编译后生成的指令都是啥.
以下内容,大家就要当做八股文来 背诵了.
- 加载: 找到 .class 文件, 打开文件, 读取文件内容.
往往代码中, 会给定某个类的, "全限定类名"
例如 java.lang.String, java.util.ArrayList
jvm 就会根据这个类名, 在一些指定的目录范围内,
查找. - 验证: .class 文件是一个二进制的格式. (某个字节, 都是有某些特定含义的)
就需要验证你当前读到的这个格式是否符合要求.

-
准备阶段:给类对象分配内存空间(最终的目标,是要构造出类对象)。这里只是分配内存空间,还没有初始化呢。此时这个空间上的内存的数值,就是全 0 的
(此时如果尝试打印类的
static成员,就是全 0 的) -
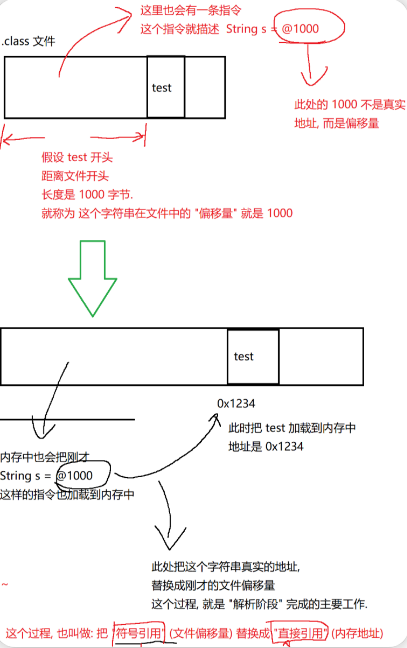
解析阶段:针对类对象中包含的字符串常量进行处理,进行一些初始化操作。java 代码中用到的字符串常量,在编译之后,也会进入到
.class文件中
-
比如代码
final String s = "test";:于此同时,
.class文件的二进制指令中,也会有一个s这样的引用被创建出来~~ -
由于引用里本质上保存的是一个变量的地址。在
.class文件中,这是文件,不涉及到内存地址。因此在.class文件中,s的初始化语句,就会先被设置成一个 "文件的偏移量",通过偏移量,就能找到 "test" 这个字符串所在的位置 -
当我们这个类真正被加载到内存中的时候,再把这个偏移量,替换回真正的内存地址
- 初始化 针对类对象进行初始化.把类对象中需要的各个属性都设置好,还需要初始化好 static 成员,还需要执行静态代码块,以及还可能需要加载一下 父类 .
文件偏移量
文件偏移量是指从文件开头到目标数据所在位置的字节数
在 .class 文件中,像字符串常量这类数据会被存储在特定位置。当代码里有对字符串常量的引用(比如 final String s = "test"; 中的 s 引用字符串常量 "test")时,由于编译后的 .class 文件还未加载到内存,不存在内存地址的概念,所以会用"文件偏移量"来标记该字符串常量在 .class 文件里的位置。当类被加载到内存时,这个文件偏移量会被替换成真正的内存地址,从而能正确访问到字符串常量
双亲委派模型
-
属于类加载中,第一个步骤"加载" 过程中,其中的一个环节
负责根据 全限定类名 找到 .class 文件.
-
类加载器。是 JVM 中的一个模块.
JVM 中,内置了,三个类加载器.
- BootStrap ClassLoader ------爷
- Extension ClassLoader ------父
- Application ClassLoader ------子
注意⚠️:
这个 父子 关系,不是 "继承" 构成的.而是这几个 ClassLoader 里有一个 parent 这样的属性,指向了一个父"类加载器"
类加载的过程 (找 .class 文件的过程)
-
给定一个类的全限定类名,形如 java.lang.String.
-
从 Application ClassLoader 作为入口,开始执行查找的逻辑.
-
Application ClassLoader, 不会立即去扫描自己负责的目录 (负责的是 搜索项目当前目录和第三方库对应目录),而是把查找的任务,交给它的父亲,Extension ClassLoader
-
Extension ClassLoader, 也不会立即扫描自己负责的目录 (负责的是 JDK 中一些扩展的库,对应的目录),而是把查找的任务,交给它的父亲,BootStrap ClassLoader
-
BootStrap ClassLoader, 也不想立即扫描自己负责的目录 (负责的是 标准库 的目录),也想把任务交给它的父亲。结果发现,自己没有父亲!!!因此 BootStrap ClassLoader 只能亲自负责扫描,标准库的目录~~
-
没有扫描到, 就会回到 Extension ClassLoader.
Extension ClassLoader 就会扫描负责的扩展库的目录.
如果找到, 就执行后续的类加载操作, 此时查找过程结束.
如果没找到, 还是把任务交给孩子来执行.
-
没有扫描到, 就会回到 Application ClassLoader
Application ClassLoader 就会负责扫描当前项目和第三方库的目录.
如果找到, 就执行后续的类加载操作.
如果没找到, 就会抛出一个 ClassNotFoundException
注意⚠️:
-
之所以搞这一套流程, 主要的目的, 为了确保, 标准库的类, 被加载的优先级最高
其次是扩展库, 其次是自己写的类和第三方库
-
假设你在自己的代码中, 写了一个 java.lang.String, 实际 JVM 加载的时候
就不会加载到你自己写的这个类, 而是加载的标准库的类.
-
双亲委派模型, 也不是不可以打破的.
如果咱们自己写一个类加载器, 不一定非要遵守上述的流程.
-
tomcat 里, 加载 webapp 的时候就是用的自定义的类加载器.
就只能在 webapp 指定目录中查找, 这里找不到, 就算了, 直接抛异常
不会去 标准库啥的里面去找了......
垃圾回收
-
Java 给出了一个方案, 垃圾回收机制 (GC),让 JVM 自行判定, 某个内存, 是否就不再使用了.如果这个内存后面确实不用了, JVM 就自动的把这个内存给回收掉~~,此时就不必让程序猿自己手动写代码回收~~
-
GC 回收的目标, 其实是 内存中的 对象.
对于 Java 来说, 就是 new 出来的这些对象.
-
栈里的局部变量, 是跟随这栈帧的生命周期走的. (方法执行结束, 栈帧销毁, 内存自然释放)
-
静态变量, 生命周期就是整个程序. 这个始终存在, 就意味着 静态变量是无需释放的.
-
因此, 真正需要 gc 释放的, 就是 堆 上的对象了.
GC可以理解成两个大的步骤:
- 找到垃圾
- 释放垃圾
找到垃圾
在GC中,有两种主流的方案:
- 引用计数:
java
class MyObject {
// 简单示例类
}
public class ReferenceCountingExample {
public static void main(String[] args) {
MyObject obj1 = new MyObject(); // obj1 引用 MyObject 对象,此时对象引用计数为 1
MyObject obj2 = obj1; // obj2 也引用该对象,引用计数变为 2
obj1 = null; // obj1 不再引用对象,引用计数减 1,变为 1
obj2 = null; // obj2 也不再引用对象,引用计数减 1,变为 0,此时对象可被回收
}
}- 出了{}之后,obj1和obj2就都要销毁了,引用计数就要归零。当对象的引用计数归零,此时代码中就不可能访问到这个对象
但是在java中一般不使用引用计数
- 无法解决 "循环引用" 问题(最致命缺陷)
- 引用计数的核心逻辑是 "通过对象的引用计数器是否为 0 判断是否为垃圾",但当两个或多个对象形成闭环引用(即相互引用,且无外部引用指向这个闭环)时,即使它们已完全无用,计数器也始终无法归零,最终导致内存泄漏(无用对象长期占用内存,无法释放)
- 比较浪费内存.
计数器, 咋说也得 2 个字节.
如果你的对象本身就很小, 这个计数器占据的空间比例就很大了.
比如对象本身就 2 个字节, 计数器占据的空间就是 50%
如果对象本身 4 个字节? 计数器占据的空间就是 33% ~~
- 如果对象很少, 或者对象比较大, 都影响不大.
如果对象小并且很多, 计数器, 占据的空间就难以忽视~~
- 可达性分析:
- 可达性分析,本质上 时间换空间 这样的手段
- 有一个/一组线程,周期性的扫描我们代码中所有的对象.
从一些特定的对象出发,尽可能的进行访问的遍历
把所有能够访问到的对象,都标记成 "可达"
反之,经过扫描之后,未被标记的对象,就是 垃圾了.
可达性分析,出发点,有很多
-
不仅仅是所有的局部变量,还有常量池中引用的对象,还有方法区中的静态引用类型引用的变量,统称为 GCRoots
-
当然,这里的遍历 不一定是二叉树,大概率是 N 叉树.
就是看你访问的某个对象,里面有多少个 引用类型的成员.
针对每个引用类型的成员都需要进一步的进行遍历
-
这里的可达性分析,都是周期性进行的(可达性分析比较消耗系统资源,开销比较大.)
-
当前某个对象是否是垃圾,是随着代码的执行,会发生改变
回收垃圾
三种基本回收思路
- 标记清除:比较简单粗暴地释放方式
-
把对应的对象,直接释放掉,就是标记清除的方案.
-
但是这个方案其实非常不好.产生很多的内存碎片~
释放内存,目的是为了让别的代码能够申请.
申请内存,都是申请到 "连续" 的内存空间. -
比如:总的空闲空间虽然是 2MB
但是申请内存的时候,只能申请 <= 1MB 的空间
随着时间的推移,内存碎片的情况,就会越演越烈.就会导致后续内存申请举步维艰.
- 复制算法:通过复制的方式,把有效的对象归类的一起,再统一释放剩下的内存
- 把内存分成两份,一次只用其中的一半.这个方案,可以有效解决内存碎片的问题.
- 但是,缺点也很明显。内存要浪费一半,利用率不高。如果有效的对象非常多,拷贝开销就很大.
- 标记整理:即能够解决内存碎片化问题,又能处理复制算法中的利用率
- 类似于顺序表删除元素的搬运操作
- 搬运开销仍很大
实际上,JVM采取的释放思路,是上述基本思路的集合体,又称为分代回收
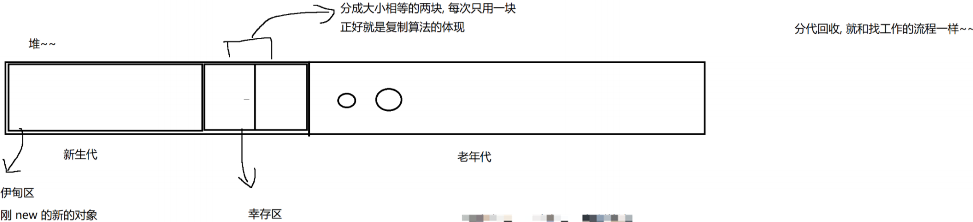
-
新的对象放到伊甸区
-
从对象诞生, 到第一轮可达性分析扫描, 这个过程中虽然时间不长 (往往就是 毫秒-秒). 但是, 在这个时间里大部分的对象都会成为垃圾~~
-
这个时间维度, 在程序的眼中也挺长了.
你创建的对象, 指向对象的引用很快就随着方法执行完毕就消亡了
-
伊甸区 => 幸存区 复制算法
每一轮 GC 扫描之后, 都把有效对象
复制到 伊甸区就可以整个释放了.
由于经验规律中, 真正需要复制的对象不多
非常适合复制算法~~
-
GC 扫描线程也会扫描 幸存区.
就会把 活过 GC 扫描的对象(扫描过程中可达)
拷贝到幸存区的另一个部分!!!
幸存区之间的拷贝, 每一轮会拷贝多个对象
每一轮也会淘汰掉一批对象 (有些对象随着时间的推移, 就成了垃圾了)
-
当这个对象已经在幸存区存活过很多轮 GC 扫描之后
JVM 就认为这个对象, 短时间内应该是释放不掉了.
就会把这个对象拷贝到 老年代
-
进入老年代的对象, 虽然也会被 GC 扫描
老年代 GC 扫描的频率就会比新生代, 低很多.
新生代的对象, 更容易挂掉 (经验规律) 要挂早挂了
老年代的对象, 更容易继续存活.
也是为了减少 GC 扫描的开销
- 分代回收,是JVM中主要的回收思想方法。但是在垃圾回收器具体体现的时候,可能还会有一些调整和优化