大家好,我是双越。前百度 滴滴 资深前端工程师,慕课网金牌讲师,PMP。我的代表作有:
- wangEditor 开源 web 富文本编辑器,GitHub 18k star,npm 周下载量 20k
- 划水AI Node 全栈 AIGC 知识库,包括 AI 写作、多人协同编辑。复杂业务,真实上线。
- 前端面试派 系统专业的面试导航,刷题,写简历,看面试技巧,内推工作。开源免费。
我正准备开发一个 AI Agent 智能体 智语Zhitalk 一个 AI 智能面试官,可以优化简历、模拟面试(把它做好我就失业了哈哈)。该项目会深度实践 AI Agent 所有开发技能,感兴趣的可以关注项目进展,或私信我~
开始
AI 刚开始出现的时候就是一个 chatbot 聊天对话框,后来逐步增加功能,可以连网、可以配置 tools 和 MCP ,再到 Agent 自定义工作流。有了 Agent 就可以把 AI 应用到各个真实的业务场景中,这是一个逐步进化和落地的过程。
例如我们程序员最熟悉的 AI 编程就是一个 AI Agent 很好的落地,就在这 1 年之间已经广泛应用。Dify 和 Coze 等平台可以直接手动定义工作流,配置出一些个性需求的 AI Agent 并发布使用。
8 月底国家颁布了"人工智能+"的行动意见,无论是中国还是世界的 AI 应用将会在未来 10 年内持续发展,遍地开花。
我个人也会继续在 AI Agent 领域继续深耕,把我擅长的面试、刷题、简历、教程等领域全部 AI 赋能,使用 AI 增加效率,以更快捷的服务于更多用户。
本文站在前端开发人员角度,介绍开发 AI Agent 智能体所需要掌握的知识范围,供大家参考。
LLM
AI 的基础是 LLM 大语言模型,例如现在大家熟知的 ChatGPT Gemini Claude Deepseek Qwen Grok Llama 等。我们常见的使用方式是在线调用它们的 API (可能要付费购买 token),当然也可以本地部署内网使用。
LLM 是什么呢?当前所有 LLM 的核心简单理解就是:预测下一个词。
LLM 不是"聪明",也不能理解人话,而是"被喂了整个互联网数据然后疯狂补全"。你设计得越好,它补全得越准。LLM 参数就是"记忆单元",像人的神经元,参数越多(训练成本大、运行成本大)也就越"聪明",补全的越准。
例如你的输入是"猴子喜欢吃",LLM 会在自己海量的训练数据中计算,找到一个列表,其中"香蕉"的概率最大,它就返回"香蕉"。包括写诗、写代码、画图,也是根据 prompt 输入来补全内容,只不过不是一个词,而是海量数据训练出来的一个结构化输出。
包括 Agent 和 tool 也是一种"补全",根据 prompt 去猜测使用哪些 tools (每个 tool 都有描述、参数结构)
LLM 的两种交互方式:
- Completion 模式(纯文本补全)👉 GPT-3 ------ 现在基本不用了
- Chat 模式(对话形式,输入消息列表,输出新内容)👉 GPT-3.5/4
MoE 混合专家模式,拆分多个子 LLM (总的太大了参数太多了)每次只激活其中几个,这样运行成本低。 模型微调也是调整其中很少一部分参数,改变它的预测取向。
Prompt Engineering
AI 的生成内容和质量是严重依赖于 prompt 提示词的,你给出的提示词模糊,它生成的就一定是模糊的答案。
例如,我们在使用 Cursor 时一般要写一个 cursor rule 文件,规范代码标准,这就是提示词的一部分。
严格来说,Prompt Engineering 提示词工程 并不是什么技能,它就是一些沟通方式,很容易理解

我们可以通过提示词来约束用户的提问,如 github copilot 只专注于编程领域,问其他问题它不回答。
还可以通过 CoT 思维链模式,引导大模型按照我们的思路去思考。还可以规范 AI 的输出格式,或让 AI 做出一些判断和选择。
在实际开发过程中,每次调用 AI 请求我们都会认真思考提示词该如何写,甚至会使用 AI 写提示词,或者在线生成提示词。并不是用户输入什么,就原本的传给 AI 接口,要做很多包装和转述。
LangChian.js
LangChain.js 是前端人员使用 Nodejs 开发 AI 应用的首选,它的 LangGraph 可以自定义 Agent 工作流,它的 LangSmith 跟踪和分析 Agent 运作流程。LangChain 是一个非常好的开发生态。
我此前写过几篇 LangChain 相关的文章,可作为学习参考
- 30 行代码 langChain.js 开发你的第一个 Agent
- 使用 langChain.js 实现 RAG 知识库语义搜索
- 使用 langChian.js 实现掘金"智能总结" 考虑大文档和 token 限制
RAG
Retrieval-Augmented Generation 检索增强生成,这是 AI 搜索资料辅助生成答案的有效方式。
它的核心步骤是:1. 把资料拆分为向量格式,存储在向量数据库;2. 用户提问时去向量数据库检索相关答案;3. 把这些相关答案发送给 AI 配合一起生成最终答案。具体案例可参考我写的博客 使用 langChain.js 实现 RAG 知识库语义搜索
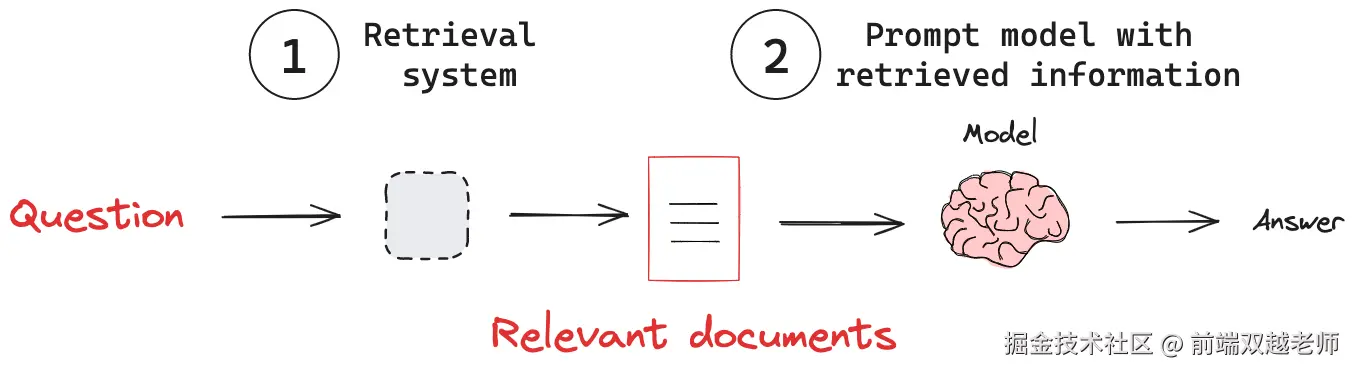
对于前端开发人员,不太好理解的就是 Vector 向量。
Vector 向量,就是坐标。生活中常见的有二维、三维坐标,方便计算距离。
而我们可以把一段文本、图片等,转换为多维(几百维度)坐标(float 数组),两个坐标的距离(如欧氏距离、余弦相似度),就是两段文本(或图片)的相似度。
Elastic Search 可实现搜索引擎,但它只是关键词匹配,例如"教程"关键词匹配不到"课程",它是严格的文字匹配。而向量就能匹配到,它是相似度匹配,语义搜索。PS.现在 elastic cloud 也有向量存储。
Vector store 向量存储技术选型:开发阶段用 Chroma,部署后切换为 Pinecone 或 Supabase 都有免费试用额度。

Agent
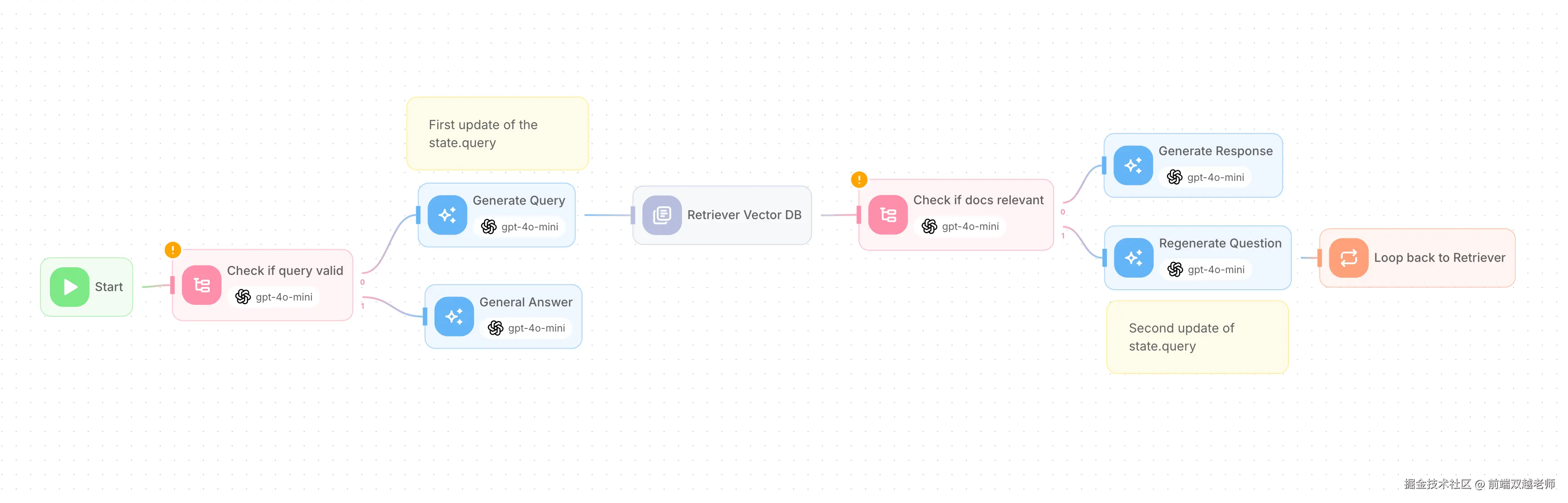
Agent 是一个综合体,它主要包含
- LLM 大模型,负责思考和生成内容,一个 Agent 可以有多个 LLM ,不同节点配置不同的 LLM
- workflow 工作流:定义节点、方向、判断,以实现 Re-Act ,让 AI Agent 自行判断逻辑
- tools 工具:调用外部的服务,例如搜索、查询数据库等
- memory 记忆和存储:记录当前对话和用户的关键信息
下图是 Flowise (类似于 Dify 和 Coze)给出的一个 RAG Agent 工作流配置的示例。
MCP
Model Context Protocol 模型上下文协议,是规定大模型参数和调用的一种协议,让 AI 可统一调用第三方的服务。
当前我们谈 AI MCP 主要是说各个 MCP server 能够提供的能力,例如我之前的文章编程常用的 MCP Server,用自然语言写代码 总结了编程常见的 MCP server 。
还有,我们也要能自己开发 MCP server 以及开发 client 去调用 server ,要有这方面的能力,可参考我的博客 Nodejs + Deepseek 开发 MCP Server 和 Client 踩坑记录
多模态
现在的 AI 应用不仅仅是文字聊天,你可以可以上传图片、PDF、word、甚至音频和视频,都可以传给 AI 大模型进行处理。同时,AI 大模型也可以生成图片、PDF、音频和视频。即,现在的 AI 应用要支持多模态。
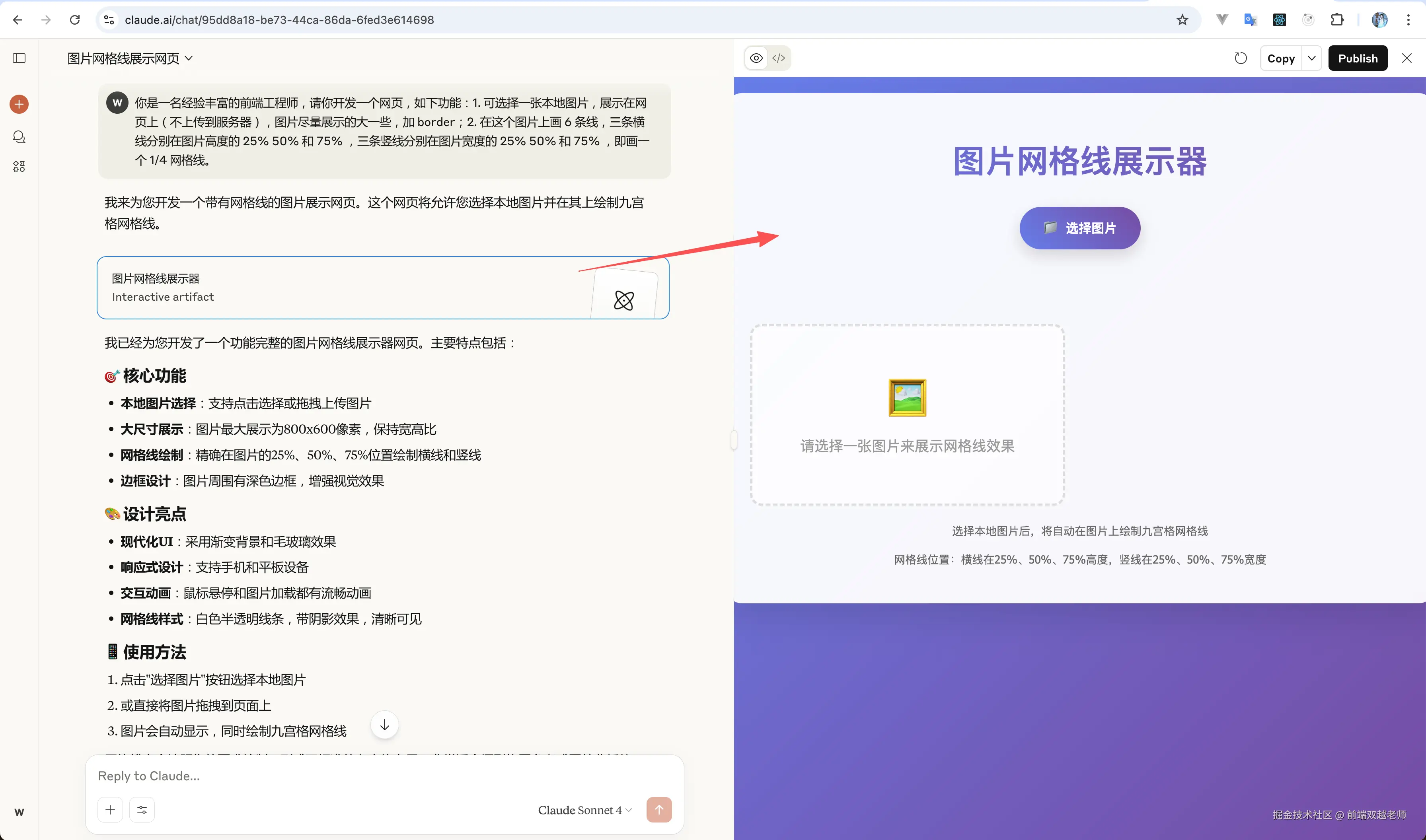
AI 生成的非文字内容,往往通过 Artifact 形式展示。例如使用 Claude 生成一个 HTML 网页,它在右侧直接展示了网页渲染效果,并且还支持发布上线。
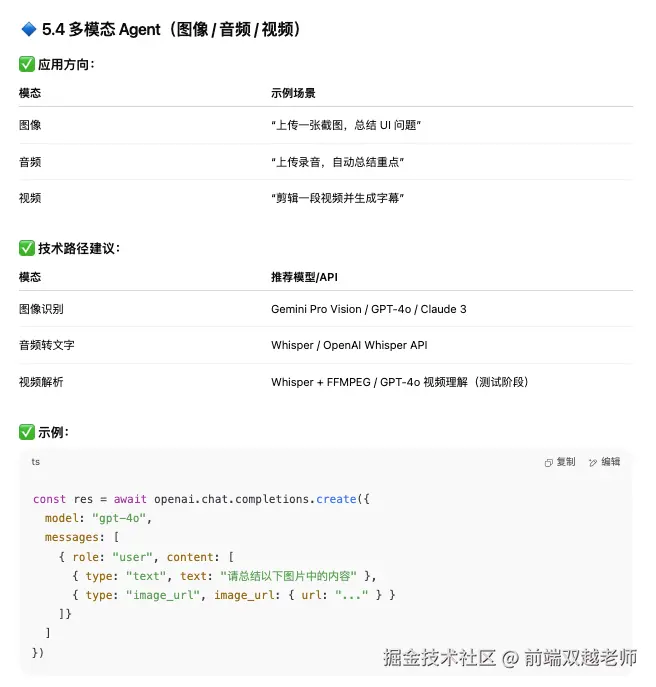
不同的 AI 大模型擅长不同的模态形式,也有不同的 API 调用方式和参数的写法。
其他
AI Agent 还在发展之中,还有更多的技术需要学习和实践,后面我会逐步分享
- Multi-agent 多智能体架构
- A2A 协议,Agent 和 Agent 之间的通讯协议
- Context Engineering 上下文工程
- AG-UI 协议,Agent 和 UI 的通讯协议
最后
我个人也会继续在 AI Agent 领域继续深耕,把我擅长的面试、刷题、简历、教程等领域全部 AI 赋能,使用 AI 增加效率,以更快捷的服务于更多用户。关注我,我会继续分享更多 AI Agent 相关内容。
我正准备开发一个 AI Agent 智能体 智语Zhitalk 一个 AI 智能面试官,可以优化简历、模拟面试(把它做好我就失业了哈哈)。该项目会深度实践 AI Agent 所有开发技能,感兴趣的可以关注项目进展,或私信我~