写在前面
大家好,我是三雒。之前我写了ART堆内存系列的第一篇 ART堆内存系列:GC抑制从入门到精通 ,以GC抑制这个需求切入,对ART触发GC的类型和时机有了比较完整的理解。这篇我们不再讨论GC,而是以大对象排除为目标,对ART堆内存的划分做一些了解。在本篇中实现了整个大对象排除方案,但经过验证后对我们要优化的指标帮助不大,另外在Android高版本上存在一些兼容性问题导致的卡死,所以最终并未全量上线,本文是更多是对ART堆内存基础知识学习 和对实现该方案的讨论。
背景
在ANR Top10 问题中WaitForGcToCompleteLocked 占比超过一半,解决WaitForGcToCompleteLocked问题迫在眉睫。
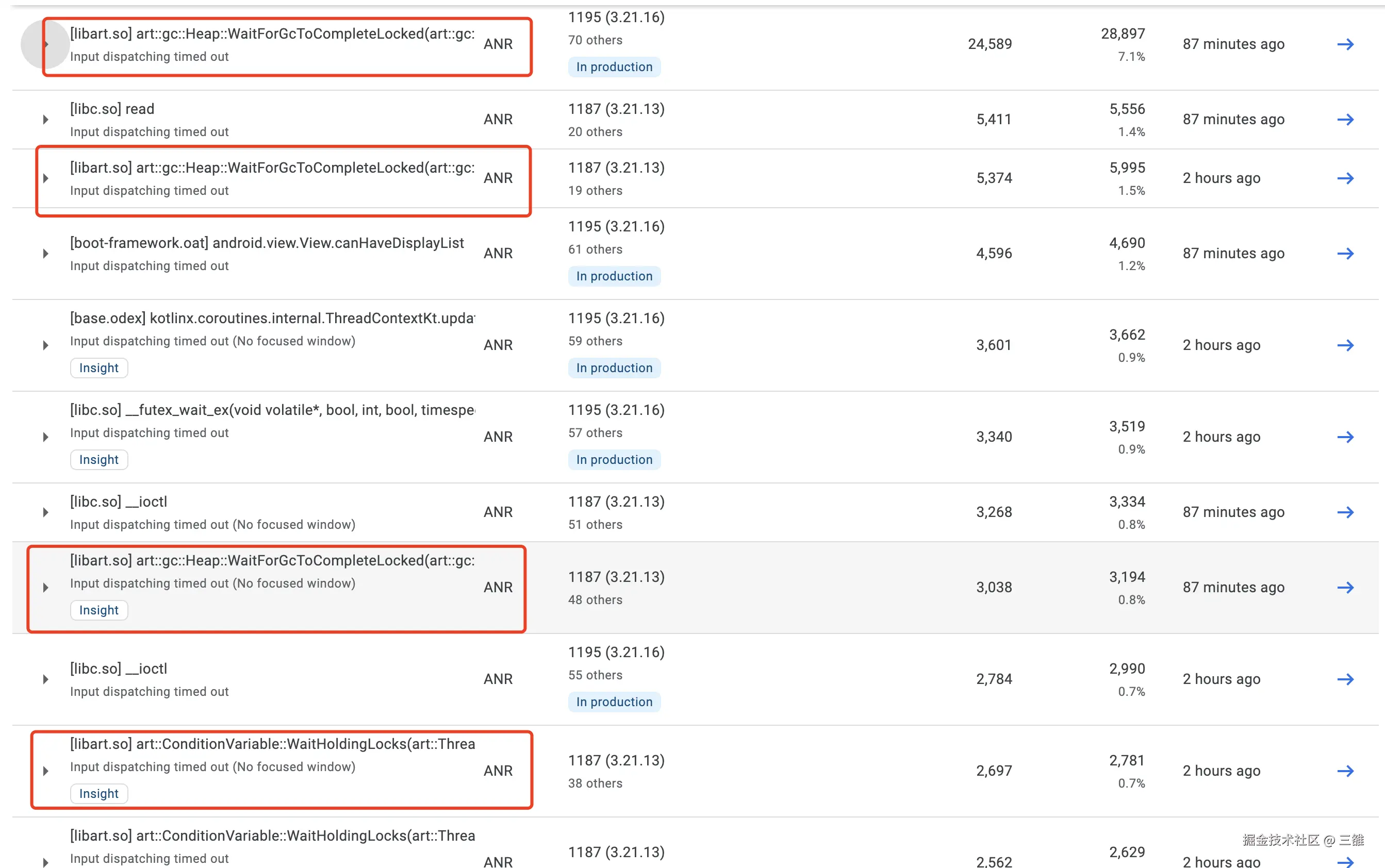
分析堆栈可以看出发生在主线程new新对象,在堆上分配空间的过程中,而且都会调用到AllocateInternalWithGc方法。根据我们对ART虚拟机分配对象过程中的代码分析,只有分配对象使内存触顶,将要触发OOM时候才会调用AllocateInternalWithGc方法触发Alloc GC, 那么也就是说这些ANR基本都发生在临近OOM时候。要想验证这一点并不难,我们只需要看ANR时候虚拟机当前的totalMemory是否接近maxMemory,由于GP上没有这些信息,从APMS搜索WaitForGcToCompleteLocked 相关的ANR查看相关信息, 可以看出大部分都是内存触顶的,比如:
Case1:
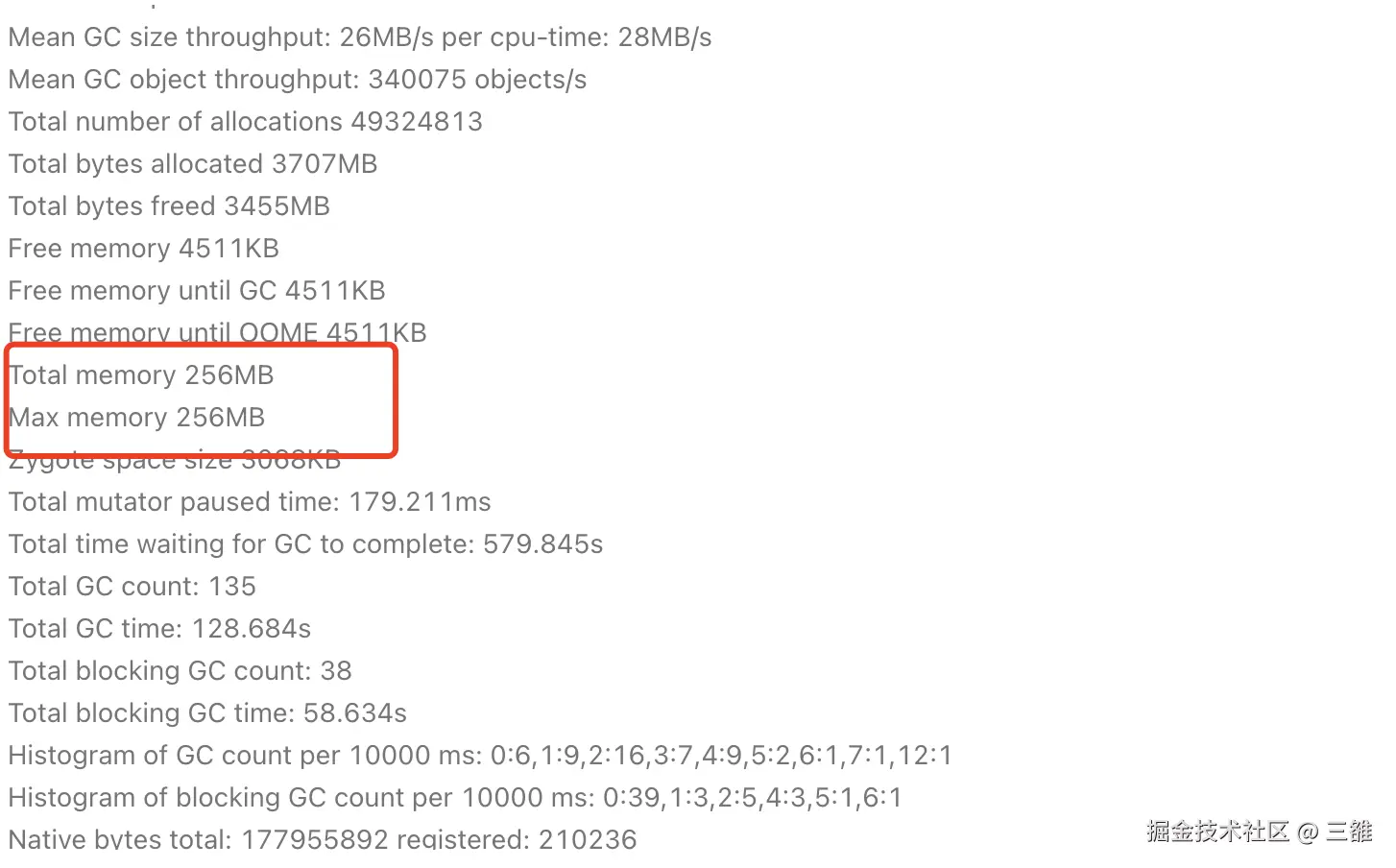
Case2:

那么我们解决这个ANR问题就转化成解决虚拟机堆内存触顶的问题,除了优化业务本身的内存泄漏之外,我们也尝试从虚拟机的堆内存分配入手,尝试扩大堆内存从而减少内存触顶的概率。
我们知道Android 8之后官方把Bitmap的内存从Java堆中移入Native中,从而减少Java堆发生OOM的概率,其实我们也可以参考这种思想。经过调研发现字节做过类似的方案拯救OOM!字节自研 Android 虚拟机内存管理优化黑科技 mSponge,大致思路就是可以将 LOS(Large Object Space)的整个内存使用从虚拟机的内存统计之中进行移除,以保障其它内存 Space 可以申请更多的内存,从而变相增大整个堆内存。
认识ART堆内存
为了更好地理解这个方案,需要对堆内存的Space划分、LOS以及对象分配和释放流程有更多的了解。
堆内存Space划分
系统在创建 Zygote 过程中会初始化虚拟机配置,其中一个便是设置 Heap 内存, 目前大部分机型堆内存最大为 512M(为方便后文都统一使用512M描述),小部分低端机甚至只有 256M,后续应用进程通过 Zygote 进程孵化时,都会继承该配置且无法修改。
对于虚拟机来说,为了更好地管理内存并提升分配和回收性能,并没有将所有 Java 对象全部放在一块空间进行管理,而是按照不同的场景属性划分成若干个内存空间,这些内存空间将会共享虚拟机 512M 最大内存,它们之间是一个此消彼长的关系。
堆具体由MainSpace、 ImageSpace、ZygoteSpace、Non moving space、LargeObjectSpace 这五个部分组成,下面是对每个组成的说明。
-
MainSpace:大对象以外的大部分的 Java 对象都会存放在这块空间
-
ImageSpace:用来存放系统库的对象,大小不固定。
-
ZygoteSpace:存放 Zygote 进程在启动过程中预加载和创建的各种对象,应用进程为 2M 左右,Zygote 进程为 64M,挨着 Image Space。
-
Non moving space:如果非 Zygote 或 Native 进程启动时,会将 ZygoteSpace 切分出 62M 左右,当做 Non moving space,用来存放一些生命周期较长的对象。
-
LargeObjectSpace:用来存放大对象,大对象是指大于 12K 的基本类型数组和 String 对象。
如下图是一个Demo应用进程的maps文件,我可以看出堆内存各个空间的分布:
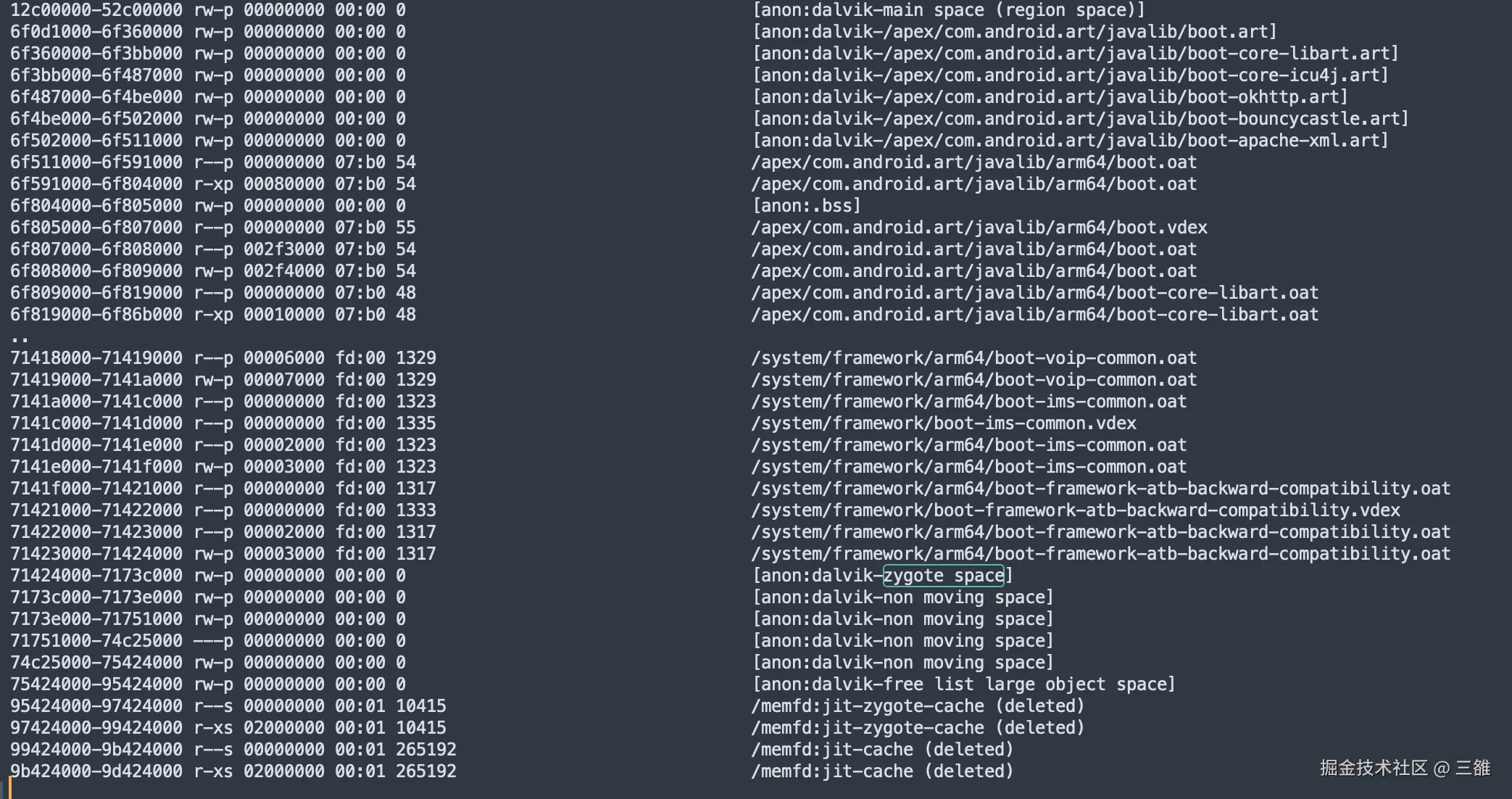
通过 maps 文件可以看到,12c00000 到 52c00000 的地址范围是1G,属于 MainSpace。从 6f0d1000 到 71424000 属于 ImageSpace,约40M大小,存放了各个系统相关的库。紧跟着 ImageSpace 的便是 ZygoteSpace、Non Moving Space 和 Large Object Space。
暂时无法在飞书文档外展示此内容
从大小上来看虽然Main Space虚拟内存占用1G,但实际上最大只能用512M,另外一半用于使用拷贝算法进行垃圾回收时候拷贝存活的对象;LOS申请了512M虚拟内存;必须说清楚的是,这两个Space虽然可用虚拟内存最大都是512M,但实际上并不能用这么多,在真正给对象分配内存时,Heap会用 num_bytes_allocated_ 这个成员记录已经分配的所有对象,不管是在 MainSpace 还是 Large Object Space 中分配的空间,都会累加到这个数值上,如果这个值超过了阈值(标志位为 growth_limit_ ),就会认为即将OOM。
对象分配
虽然 虚拟机堆的Space很多,但实际上应用代码中的 Java 对象几乎只会存放到MainSpace 和 LargeObjectSpace 这两个空间中,其他的空间都是给系统库或者 Zygote 使用的,所以下面我们就来看看 Java 对象所需的内存是如何在 MainSpace 和 LargeObjectSpace 进行申请和释放的。
分配流程
从代码执行方式上看无论是解释执行、机器码,从创建对象的方式无论是new还是反射创建,最终都会调用 AllocObjectWithAllocator 这个方法从 Java 堆中申请内存,我们直接看这个方法的逻辑:
Heap::AllocObjectWithAllocator
c++
inline mirror::Object* Heap::AllocObjectWithAllocator(Thread* self,
ObjPtr<mirror::Class> klass,
size_t byte_count,
AllocatorType allocator,
const PreFenceVisitor& pre_fence_visitor) {
...
//1.检测是否是LargeObject,如果是则在LargeObjectSpace申请内存,AllocLargeObject内部还是会调用AllocObjectWithAllocator这个方法
if (kCheckLargeObject && UNLIKELY(ShouldAllocLargeObject(klass, byte_count))) {
obj = AllocLargeObject<kInstrumented, PreFenceVisitor>(self, &klass, byte_count,
pre_fence_visitor);
if (obj != nullptr) {
return obj.Ptr();
}
}
//调用TryToAllocate申请对象
obj = TryToAllocate<kInstrumented, false>(self, allocator, byte_count, &bytes_allocated,
&usable_size, &bytes_tl_bulk_allocated);
if (UNLIKELY(obj == nullptr)) {
//3. 分配失败,执行AllocateInternalWithGc, 里面会执行等上次GC完成后分配、尝试几种不同程度的GC后分配、回收软引用并扩容分配、最终失败抛出OOM等逻辑
obj = AllocateInternalWithGc(self,
allocator,
kInstrumented,
byte_count,
&bytes_allocated,
&usable_size,
&bytes_tl_bulk_allocated,
&klass);
}
if (bytes_tl_bulk_allocated > 0) {
//4. 更新堆已使用计数 num_bytes_allocated_
size_t num_bytes_allocated_before = AddBytesAllocated(bytes_tl_bulk_allocated);
}
if ( IsGcConcurrent()) {
//5. 对象分配完成之后,检查当前所使用内存是否达到并发GC出发阈值,如果达到则触发并发GC
CheckConcurrentGC(self, new_num_bytes_allocated, &obj);
}
...
return obj.Ptr();
}
虚拟机为 Java 对象申请内存时,会先检测是否是大对象。 如果是大对象,则会调用 AllocLargeObject 在 LargeObjectSpace 中申请;如果不是,则调用 TryToAllocate 在 MainSpace 中申请。
不论是否大对象如果申请失败,就会直接触发Alloc GC, 进行几次不同Type的 GC后继续尝试申请,直至OOM。
LOS
什么是大对象呢?通过 ShouldAllocLargeObject 判断接口可以看到,申请的内存大小大于 3页,且是基本类型数组或者字符串便认为是大对象。
c++
inline bool Heap::ShouldAllocLargeObject(ObjPtr<mirror::Class> c, size_t byte_count) const {
return byte_count >= large_object_threshold_ && (c->IsPrimitiveArray() || c->IsStringClass());
}我们继续追踪大对象时如何分配的,大对象分配的AllocLargeObject方法中其实还是会调用AllocObjectWithAllocator,进而调用到TryToAllocate方法。
c++
template <const bool kInstrumented, const bool kGrow>
inline mirror::Object* Heap::TryToAllocate(Thread* self,
AllocatorType allocator_type,
size_t alloc_size,
size_t* bytes_allocated,
size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
if (allocator_type != kAllocatorTypeRegionTLAB &&
allocator_type != kAllocatorTypeTLAB &&
allocator_type != kAllocatorTypeRosAlloc &&
// 判断是否会触发OOM
UNLIKELY(IsOutOfMemoryOnAllocation(allocator_type, alloc_size, kGrow))) {
return nullptr;
}
mirror::Object* ret;
// 根据不同类型的分配器分配对象
switch (allocator_type) {
...
case kAllocatorTypeNonMoving: {
ret = non_moving_space_->Alloc(self,
alloc_size,
bytes_allocated,
usable_size,
bytes_tl_bulk_allocated);
break;
}
case kAllocatorTypeLOS: {
//在LOS上分配大对象
ret = large_object_space_->Alloc(self,
alloc_size,
bytes_allocated,
usable_size,
bytes_tl_bulk_allocated);
DCHECK(ret == nullptr || large_object_space_->Contains(ret));
break;
}
case kAllocatorTypeRegion: {
DCHECK(region_space_ != nullptr);
alloc_size = RoundUp(alloc_size, space::RegionSpace::kAlignment);
ret = region_space_->AllocNonvirtual<false>(alloc_size,
bytes_allocated,
usable_size,
bytes_tl_bulk_allocated);
break;
}
...
}
return ret;
}对于大对象而言最终调用到了LOS的Alloc方法,而LOS的实现类其实有两个,根据系统CPU架构和位数不同而不同,64位ARM主要是使用FreeListSpace,而32位是LargeObjectMapSpace
c++
Heap::Heap(......){
...
// 创建LargeObjectSpace给large_object_space_赋值
if (large_object_space_type == space::LargeObjectSpaceType::kFreeList) {
large_object_space_ = space::FreeListSpace::Create("free list large object space", capacity_);
} else if (large_object_space_type == space::LargeObjectSpaceType::kMap) {
large_object_space_ = space::LargeObjectMapSpace::Create("mem map large object space");
} else {
...
}
...
}large_object_space_type的默认值是kDefaultLargeObjectSpaceType,kDefaultLargeObjectSpaceType由系统CPU 架构决定
c++
static constexpr space::LargeObjectSpaceType kDefaultLargeObjectSpaceType =
USE_ART_LOW_4G_ALLOCATOR ?
space::LargeObjectSpaceType::kFreeList
: space::LargeObjectSpaceType::kMap;Android 主流是ARM架构,ARM 64是USE_ART_LOW_4G_ALLOCATOR 为1,否则是0。
c++
#if defined(__LP64__) && !defined(__Fuchsia__) && \
(defined(__aarch64__) || defined(__riscv) || defined(__APPLE__))
#define USE_ART_LOW_4G_ALLOCATOR 1
#else
#if defined(__LP64__) && !defined(__Fuchsia__) && !defined(__x86_64__)
#error "Unrecognized 64-bit architecture."
#endif
#define USE_ART_LOW_4G_ALLOCATOR 0
#endifOOM判断
c++
inline bool Heap::IsOutOfMemoryOnAllocation(AllocatorType allocator_type, size_t alloc_size) {
//分配之后预计占用的内存
size_t new_footprint = num_bytes_allocated_.LoadSequentiallyConsistent() + alloc_size;
//如果分配之后预计占用内存大于max_allowed_footprint,max_allowed_footprint是虚拟机给堆内存的一个软限制,表示当前能用的总内存,大致对应Runtime.totalMemory
if (UNLIKELY(new_footprint > max_allowed_footprint_)) {
//如果超过growth_limit_ 则直接OOM,growth_limit_表示虚拟机能用的最大堆内存,对应于Runtime.maxMemory
if (UNLIKELY(new_footprint > growth_limit_)) {
return true;
}
// 如果处于在max_allowed_footprint_和growth_limit_之间,并且是并发GC模式则认为不会认为OOM,因为max_allowed_footprint_ 只是个软限制,真正分配内存的Space是比这个限制空间充足,可以先进行分配之后分配完成再触发并发GC进行回收以及扩容
if (!IsGcConcurrent()) {
if (!kGrow) {
return true;
}
max_allowed_footprint_ = new_footprint;
}
}
// 如果分配之后预计占用内存小于max_allowed_footprint,则一定不OOM
return false;
}这个方法里主要也是用num_bytes_allocated_来判断是否可以看出当内存触顶达将要到最大堆内存growth_limit_之后才会分配失败,进一步执行AllocateInternalWithGc,触发Alloc GC, 未达到growth_limit_ 是不会执行AllocateInternalWithGc方法。
堆内存计数增加
这里需要再说明的是对象分配成功后更新num_bytes_allocated_的值,进一步更新堆内存的计数。
c++
size_t AddBytesAllocated(size_t bytes) {
return num_bytes_allocated_.fetch_add(bytes, std::memory_order_relaxed);
}对象回收
不论是并发GC还是分配过程中发生的Alloc GC等 最终都会调用到CollectGarbageInternal这个方法来进行垃圾回收,这个方法先选择合适的垃圾回收器,然后执行对应的Run方法进行垃圾回收
c++
collector::GcType Heap::CollectGarbageInternal(collector::GcType gc_type,
GcCause gc_cause,
bool clear_soft_references,
uint32_t requested_gc_num) {
......
collector::GarbageCollector* collector = nullptr;
if (compacting_gc) {
//选择对应的垃圾回收器
switch (collector_type_) {
...
case kCollectorTypeCC:
collector::ConcurrentCopying* active_cc_collector;
if (use_generational_cc_)
active_cc_collector = (gc_type == collector::kGcTypeSticky) ?
young_concurrent_copying_collector_ : concurrent_copying_collector_;
active_concurrent_copying_collector_.store(active_cc_collector,
std::memory_order_relaxed);
collector = active_cc_collector;
} else {
collector = active_concurrent_copying_collector_.load(std::memory_order_relaxed);
}
break;
default:
}
if (collector != active_concurrent_copying_collector_.load(std::memory_order_relaxed)) {
temp_space_->GetMemMap()->Protect(PROT_READ | PROT_WRITE);
if (kIsDebugBuild) {
// Try to read each page of the memory map in case mprotect didn't work properly b/19894268.
temp_space_->GetMemMap()->TryReadable();
}
}
} else if (current_allocator_ == kAllocatorTypeRosAlloc ||
current_allocator_ == kAllocatorTypeDlMalloc) {
collector = FindCollectorByGcType(gc_type);
}
// 执行GC过程
collector->Run(gc_cause, clear_soft_references || runtime->IsZygote());
...
return gc_type;
}这里重点说一下垃圾回收器的Run方法中最后会调用到Heap的RecordFree方法来释放对象,这个方法很关键,是我们把大对象从虚拟机堆内存中排除掉的切入点。
堆内存计数减少
这个函数里freed_bytes可以是正值也可以是负值,正就表示num_bytes_allocated_真正减少,负其实就是增加
c++
void Heap::RecordFree(uint64_t freed_objects, int64_t freed_bytes) {
//释放freed_bytes的空间
num_bytes_allocated_.fetch_sub(static_cast<ssize_t>(freed_bytes), std::memory_order_relaxed);
}方案详情
核心思路
因为堆内存分配是靠 num_bytes_allocated_ 计数,我们只需要通过修改这个值就可以把LOS给排除掉,直接调用RecordFree可以达到这个目的。另外需要考虑GC之后num_bytes_allocated_的数值校正,因为GC本身可能会回收LOS上的对象并调用RecordFree释放掉大小,但因为我们已经将LOS从对上排除了,这种情况相当于多释放了,我们需要在这种情况下把虚拟机多释放的部分加回来以保证num_bytes_allocated_的逻辑正确性。
排除LOS
我们要调用RecordFree方法,虚拟机并没有暴漏相关API直接调用到,只能通过dlsym去寻找so中的特定符号,从而找到函数本身。因为RecordFree是Heap的成员方法,第一个参数是heap实例自己,freed_bytes是释放的大小,freed_objects是对象地址,这里我们把其设置为一个无效数值(-1),我们其实没有真正释放某个对象。
c++
void recordFree(void *heap, int64_t freeSize) {
void *handle = shadowhook_dlopen(SO_NAME_ART);
void *func = shadowhook_dlsym(handle, FUN_HEAP_RECORD_FREE);
((heapRecordFree) func)(heap, -1, freeSize);
}当我们要调用如上recordFree来释放LOS时候会立马遇到三个问题,接下来我们逐一讨论
- freeSize大小怎么决定,也就是如何确定LOS的大小
- 在什么时机去free
- 需要给这个方法传递heap实例,怎么能拿到虚拟机的Heap对象
获取LOS的大小
LOS也是可分配对象的Space,继承自AllocSpace,AllocSpace其实提供了虚方法GetBytesAllocated给子类实现,我们只要调用LOS的GetBytesAllocated方法就可以获取到LOS的大小。
LargeObjectSpace::GetBytesAllocated
c++
// AllocSpace interface.
class AllocSpace {
public:
virtual uint64_t GetBytesAllocated() = 0;
virtual mirror::Object* Alloc(Thread* self, size_t num_bytes, size_t* bytes_allocated,
size_t* usable_size, size_t* bytes_tl_bulk_allocated) = 0;
virtual size_t Free(Thread* self, mirror::Object* ptr) = 0;
};
class LargeObjectSpace : public DiscontinuousSpace, public AllocSpace {
public:
uint64_t GetBytesAllocated() override {
MutexLock mu(Thread::Current(), lock_);
return num_bytes_allocated_;
}
}如下是我们封装好的调用,很明显我们真正调用时候需要获取到LOS的实例。
c++
uint64_t getLOSBytesAllocated(void *los) {
void *handle = shadowhook_dlopen(SO_NAME_ART);
void *func = shadowhook_dlsym(handle,
FUN_LOS_GET_BYTES_ALLOCATED);
uint64_t num_bytes_allocated = ((int (*)(void *)) func)(los);
Utils::log("los_bytes_allocated : %lu",
num_bytes_allocated);
return num_bytes_allocated;
}我们在上文LOS的介绍部分提过LOS的实现类有两个,64位ARM 主要是使用FreeListSpace,32位使用LargeObjectMapSpace,其实要获取的是这两个类的实例。
获取对应类的实例有一个很简单的思路就是hook其成员方法,第一个参数就是,我们这里以FreeListSpace为例,直接hook其核心方法 Alloc
c++
void *freeListSpaceAllocProxy(void *thiz, void *self, size_t num_bytes, size_t *bytes_allocated,
size_t *usable_size,
size_t *bytes_tl_bulk_allocated) {
SHADOWHOOK_STACK_SCOPE();
void *largeObjectMap = SHADOWHOOK_CALL_PREV(freeListSpaceAllocProxy, thiz, self, num_bytes,
bytes_allocated,
usable_size,
bytes_tl_bulk_allocated);
gLos = thiz;
Utils::log("LOS: FreeListSpace alloc");
return largeObjectMap;
}那么到这里我们就可以获取到LOS的大小。
Free时机
时机选择的话主要考虑两点,一是我们这种排除LOS的操作是对虚拟逻辑的侵入存在一定风险,需要尽可能的减少对正常用户的影响;二也就是我们上面的第三个问题,最好能方便地拿到Heap对象。
经过分析把时机选择到濒临OOM是比较合理的,因为线上濒临OOM的用户相对是较少的,只针对这部分用户启用,减少对大部分正常用户的影响。
在第一部分对象分配流程中,我们知道对象分配时内存触顶之后会执行AllocateInternalWithGc,这里我们不妨详细看看具体的逻辑:
c++
mirror::Object* Heap::AllocateInternalWithGc(Thread* self,
AllocatorType allocator,
bool instrumented,
size_t alloc_size,
size_t* bytes_allocated,
size_t* usable_size,
size_t* bytes_tl_bulk_allocated,
mirror::Class** klass) {
...
// 等待上一次GC完成之后,尝试重新分配对象
collector::GcType last_gc = WaitForGcToComplete(kGcCauseForAlloc, self);
if (last_gc != collector::kGcTypeNone) {
mirror::Object* ptr = TryToAllocate<true, false>(self, allocator, alloc_size, bytes_allocated,
usable_size, bytes_tl_bulk_allocated);
if (ptr != nullptr) {
return ptr;
}
}
...
// 遍历进行几种不同强度的GC 并尝试分配
for (collector::GcType gc_type : gc_plan_) {
if (gc_type == tried_type) {
continue;
}
// Attempt to run the collector, if we succeed, re-try the allocation.
const bool plan_gc_ran =
CollectGarbageInternal(gc_type, kGcCauseForAlloc, false) != collector::kGcTypeNone;
if (plan_gc_ran) {
mirror::Object* ptr = TryToAllocate<true, false>(self, allocator, alloc_size, bytes_allocated,
usable_size, bytes_tl_bulk_allocated);
if (ptr != nullptr) {
return ptr;
}
}
}
// 同步Blokcing GC ,对堆扩容然后尝试分配, TryToAllocate<true, true> 模版参数第二true表示grow
mirror::Object* ptr = TryToAllocate<true, true>(self, allocator, alloc_size, bytes_allocated,
usable_size, bytes_tl_bulk_allocated);
if (ptr != nullptr) {
return ptr;
}
// 触发回收软引用的GC,第三个参数true表示回收软引用对象,并且对堆扩容进行分配
CollectGarbageInternal(gc_plan_.back(), kGcCauseForAlloc, true);
ptr = TryToAllocate<true, true>(self, allocator, alloc_size, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);
...
if (ptr == nullptr) {
// 最终分配失败,抛出OOM异常
ThrowOutOfMemoryError(self, alloc_size, allocator);
}
return ptr;
}可以看到最终是调用ThrowOutOfMemoryError抛出OOM的,ThrowOutOfMemoryError如下
c++
void Heap::ThrowOutOfMemoryError(Thread* self, size_t byte_count, AllocatorType allocator_type) {
std::ostringstream oss;
size_t total_bytes_free = GetFreeMemory();
//我们最熟悉的OOM日志
oss << "Failed to allocate a " << byte_count << " byte allocation with " << total_bytes_free
<< " free bytes and " << PrettySize(GetFreeMemoryUntilOOME()) << " until OOM,"
<< " max allowed footprint " << max_allowed_footprint_ << ", growth limit "
<< growth_limit_;
// If the allocation failed due to fragmentation, print out the largest continuous allocation.
if (total_bytes_free >= byte_count) {
....
if (space != nullptr) {
space->LogFragmentationAllocFailure(oss, byte_count);
}
}
//Error真正抛出
self->ThrowOutOfMemoryError(oss.str().c_str());
}因此我们直接在 AllocateInternalWithGc方法一触发就执行LOS的Free 就挺合适的,思路简单并且能拿到Heap对象,方便调用recordFree,实现如下。
c++
void *allocateInternalWitGcProxy(void *heap, void *self,
enum AllocatorType allocator,
bool instrumented,
size_t alloc_size,
size_t *bytes_allocated,
size_t *usable_size,
size_t *bytes_tl_bulk_allocated,
void *klass) {
SHADOWHOOK_STACK_SCOPE();
excludeLOS(heap);
void *object = SHADOWHOOK_CALL_PREV(allocateInternalWitGcProxy, heap, self,
allocator,
instrumented,
alloc_size,
bytes_allocated,
usable_size,
bytes_tl_bulk_allocated,
klass);
return object;
}
c++
void excludeLOS(void *heap) {
if (gLos != nullptr) {
uint64_t currentAllocated = getLOSBytesAllocated(gLos);
int64_t diff = currentAllocated - lastLOSAllocated;
if (diff > 0) {
recordFree(heap, diff);
//record free state
hasExcludedLOS = true;
Utils::log("LOS exclude from heap, size %lu",
diff);
lastLOSAllocated = currentAllocated;
}
}
}GC后num_bytes_allocated_校正
GC时如果回收掉LOS上的对象,它一定会调用RecordFree来减少num_bytes_allocated_ , 那我们想要对这个值做校正,只需要代理RecordFree在其调用之后,检查LOS的大小是否变小,如果变小则需要补偿校正。
c++
void heapRecordFreeProxy(void *heap, uint64_t freed_objects, int64_t freed_bytes) {
SHADOWHOOK_STACK_SCOPE();
SHADOWHOOK_CALL_PREV(heapRecordFreeProxy, heap, freed_objects, freed_bytes);
//adjust heap
if (gLos != nullptr && hasExcludedLOS) {
uint64_t currentAllocLOS = getLOSBytesAllocated(gLos);
uint64_t diff = currentAllocLOS - lastLOSAllocated;
if (diff < 0) {
SHADOWHOOK_CALL_PREV(heapRecordFreeProxy, heap, freed_objects, diff);
Utils::log("LOS adjust heap %lu",
diff);
lastLOSAllocated = currentAllocLOS;
}
}
}到这里整体的方案整体就完成了。
写在最后
该方案在线上验证期间发现在Android 14以上有兼容性问题导致内存触顶时卡死,另外在线上验证后发现对ANR并没有优化效果,没有继续对该方案进行探究,本文仅供参考,如果大家有落地的场景可以交流一下。