LangChain 是一个强大的开源框架,专为大语言模型的集成与应用开发而设计;而 Qwen(通义千问)则是阿里巴巴集团推出的优秀大语言模型,在国内拥有广泛的应用和良好的口碑。对于国内开发者而言,掌握如何在 LangChain 中高效接入 Qwen 大模型是一项关键技能。然而,由于 LangChain 提供了多种接入 Qwen 的方式,许多开发者在选择具体实现方案时常常感到困惑。为此,本文将系统介绍几种主流的 LangChain 接入 Qwen 大模型的方法,并结合实际应用场景,分享最佳实践建议,帮助开发者快速上手并做出最优选择。
方式一:使用LangChain-Community下的ChatTongyi模型
这种方式应该是国内最常用的方式,使用ChatTongyi模型,需要安装langchain-community包,并使用ChatTongyi类。 下面简单介绍一下使用方式。
安装langchain-community包
base
uv add langchain-community langchain使用方式如下: 首先需要设置环境变量
bash
export DASHSCOPE_API_KEY=sk-123456
python
from langchain_community.chat_models import ChatTongyi
model=ChatTongyi(
model="qwen-plus-latest"
)
print(model.invoke("你好"))上面的方式是一个非常简单的使用方式。
这个类应该是目前国内用户接入Qwen的大模型的最常用的方法。但是不是最优的,使用这个类时候,会有一定的问题,具体如下
并行工具调用
由于阿里云百炼的Qwen系列大模型默认是不开启工具调用的,因此每次的返回都只会有一个工具。当然可以通过model_kwargs参数设置,但是如果接入的模型是思考模型的话,则会有以下问题,具体来说见下面代码:
首先接入Qwen-Plus最新版本,默认不是思考模型。
python
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
model = ChatTongyi(model="qwen-plus-latest", model_kwargs={"parallel_tool_calls": True}) # pyright:ignore
@tool
def write_file(path: str, content: str) -> str:
"""Write content to a file at the given path. Returns the path to the file."""
with open(path, "w") as f:
f.write(content)
return path
tool_model = model.bind_tools([write_file])
print(
tool_model.invoke(
"将下面的内容分别保存到两个文件a.txt和b.txt中。1.Qwen大模型是国内的出色模型 2.LangChain是一个开源的AI开发框架"
)
)得到的结果应该是:

可以发现没有什么太大的问题。
但是当我们设置思考模式的时候,则会出现问题。
代码:
python
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
model = ChatTongyi(model="qwen-plus-latest", model_kwargs={"parallel_tool_calls": True,"enable_thinking":True}) # pyright:ignore
@tool
def write_file(path: str, content: str) -> str:
"""Write content to a file at the given path. Returns the path to the file."""
with open(path, "w") as f:
f.write(content)
return path
tool_model = model.bind_tools([write_file])
print(
tool_model.invoke(
"将下面的内容分别保存到两个文件a.txt和b.txt中。1.Qwen大模型是国内的出色模型 2.LangChain是一个开源的AI开发框架"
)
)报错如下:
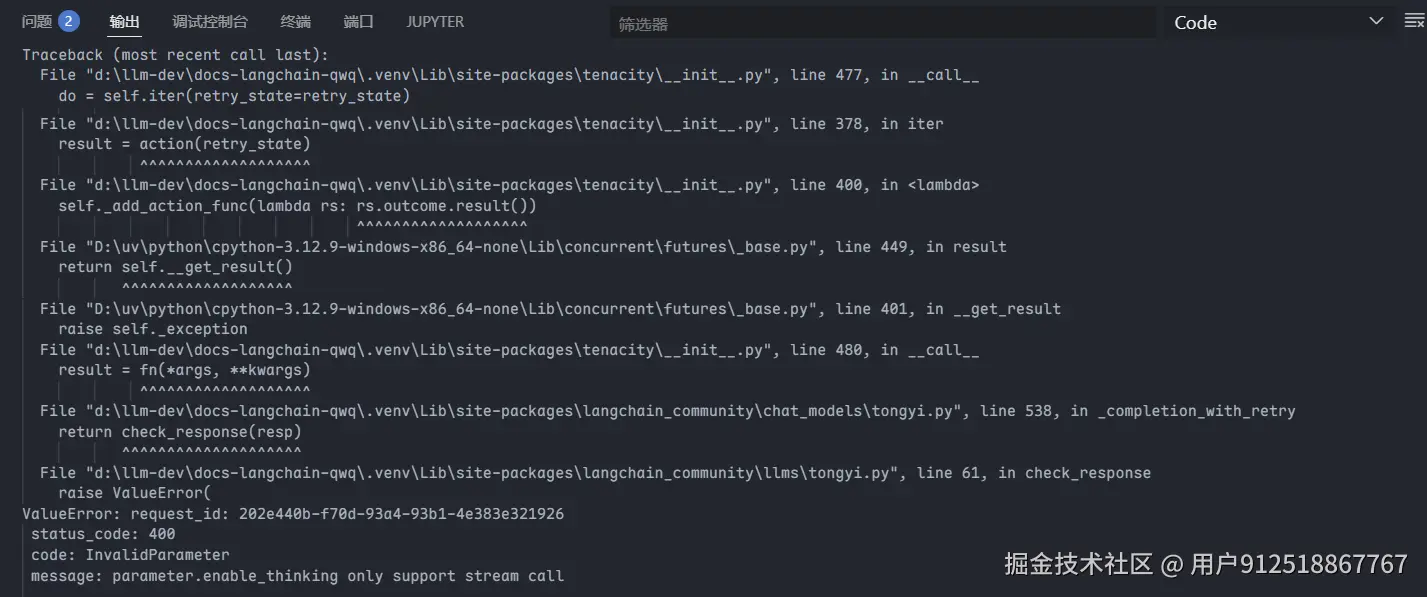
这个报错的原因是因为阿里云的百炼中Qwen的思考模型不支持非流式调用(除了Qwen3-235b-a22b-thinking-2507代表的几个模型可以)。这个报错的解决方法是设置streaming=True 代码如下:
python
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
model = ChatTongyi(
model="qwen-plus-latest",
model_kwargs={
"parallel_tool_calls": True,
"enable_thinking": True,
"incremental_output": True,
},
streaming=True,
) # pyright:ignore
@tool
def write_file(path: str, content: str) -> str:
"""Write content to a file at the given path. Returns the path to the file."""
with open(path, "w") as f:
f.write(content)
return path
tool_model = model.bind_tools([write_file])
print(
tool_model.invoke(
"将下面的内容分别保存到两个文件a.txt和b.txt中。1.Qwen大模型是国内的出色模型 2.LangChain是一个开源的AI开发框架"
)
)结果如下: 
可以发现确实是正常运行了,但是仔细观察会发现问题。
base
tool_calls=[{'name': 'write_filewrite_file', 'args': {'path': 'a.txt', 'content': '1.Qwen大模型是国内的出色模型'}, 'id': 'call_8b844478e6fe438285e4f6call_c23c79ff4108480c811115', 'type': 'tool_call'}]可以看到两个工具的名称被错误地合并了。这是由于源码中的一个缺陷:在处理流式输出的工具调用时,每次只会返回一部分数据,最终需要进行合并。而合并过程依赖于索引(index)来区分不同的工具调用。早期的 Dashscope API 可能并未返回索引信息,因此该类采用了数组索引的方式来进行处理。然而,这种方式会导致问题------当工具1返回完毕后,如果工具2才开始返回,此时其索引仍为0,就会导致两个工具调用被错误地合并。
这个问题已经在 GitHub 上提交过 issue:langchain-community PR #111,但截至目前尚未得到官方的修复响应。尽管我已经提醒过相关维护人员,但仍未获得回复,因此就不管了。
结构化输出
除此之外,这个库还有一个很大的问题,就是它的结构化输出有时候会返回None。相信用这个库的人也或多或少的遇到过吧。 其实这个原因严格来说不算LangChain的bug,因为这个结构化输出的实现方式是工具调用,而大模型不总是会调用工具的因此导致了如果它不调用工具那就会返回None。
方式二:通过LangChain-LiteLLM接入 (简略)
LiteLLM 是一个轻量级的库,它为开发者提供了一种简单的方式来调用各种大语言模型,包括 Qwen。通过 LiteLLM,你可以通过一个函数就可以接入100+的大模型。 使用这个库的前提是需要安装LangChain-LiteLLM
python
uv add litellm langchain-litellm实现代码:
python
from langchain_litellm import ChatLiteLLM
model=ChatLiteLLM(
model="dashscope/qwen-plus-latest"
)
print(model.invoke("你好"))通过这个可以调用DashScope的Qwen大模型。
但是这个库也存在着很多问题
1.不支持结构化输出
虽然你可以.withstruct_output()来进行结构化输出,但是一般是会报错的,原因是这个库没有实现这个方法,因此默认采用了LangChain的默认方法,而这个默认方法是需要模型支持tool_choice="any" ,但是好像百炼没有支持的模型。
2.异步方法有bug
如果你采用的是ainvoke等异步方法,那么一定会报错,这个报错在这个库的github中有人提过,目前是有解决方法的但是作者没有merge。 现在的解决方式是通过ChatLiteLLMRouter类
python
from langchain_litellm import ChatLiteLLMRouter
from litellm.router import Router
router=Router(
[
{
"model_name":"qwen",
"litellm_params":{
"model":"dashscope/qwen-plus-latest"
}
}
]
)
model=ChatLiteLLMRouter(router=router,model_name="qwen")
print(model.invoke("你好"))虽然通过 ChatLiteLLMRouter 接入可以避免异步调用的错误,但当模型数量较少时,配置过程显得繁琐。此外,由于 LiteLLM 库本身存在性能问题,其初始化和启动速度较慢,这可能会影响开发体验和部署效率。 当然了如果你是自己部署的Qwen模型或者你的提供商有限流的限制,那么使用litellm的router机制是一个不错的选择。
方式三:通过 langchain-qwq 来实现(最佳)
langchain-qwq默认采用了OpenAI兼容的方式进行接入。这种方式使得其能够接入大部分的百炼模型。同时这也是我本次觉得集成最好的选择(因为我也是这个库的作者之一)
安装方式
bash
uv add langchain-qwq该库提供了两个核心类:ChatQwQ 和 ChatQwen。对于 QwQ 和 QvQ 模型,推荐使用 ChatQwQ 进行接入;而对于 Qwen 系列模型,则应选择 ChatQwen。
需要注意的是,由于这个库是langchain的衍生库,面向海外,故默认配置下调用的是国际版阿里云 API,因此国内用户需要额外设置环境变量以确保正常访问:
bash
export DASHSCOPE_API_BASE="https://dashscope.aliyuncs.com/compatible-mode/v1"这可能是该库在国内使用时唯一的不便之处。
整体而言,langchain-qwq 在与 LangChain 的集成方面表现出色,提供了良好的开发体验和功能支持。 接下来我们将重点介绍 ChatQwen 的具体使用方式。关于 ChatQwQ,鉴于其对应的 QwQ 模型当前使用频率较低,且由主要第一作者维护,此处暂不展开讨论。
首先我们以接入目前比较火的Qwen3系列模型为例。
简单调用
python
from langchain_qwq import ChatQwen
model=ChatQwen(model="qwen-plus-latest") #也可以用别的模型
model.invoke("你好")上述接入的是Qwen3系列的闭源模型,当然也可以接入别的模型,例如Qwen团队最近发布的
python
from langchain_qwq import ChatQwen
model = ChatQwen(model="qwen3-235b-a22b-instruct-2507")
respose1 = model.invoke("你好")
print(respose1)
model = ChatQwen(model="qwen3-235b-a22b-thinking-2507")
response2 = model.invoke("你好")
print(response2)
print(response2.additional_kwargs.get("reasoning_content"))你将会获得如下的输出
base
content='你好呀!✨ 很高兴见到你!今天过得怎么样呀?希望你度过了愉快的一天。我随时准备好陪你聊天、帮你解决问题,或者就这样轻松愉快地闲聊一会儿。有什么想跟我分享的吗? 🌟' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 51, 'prompt_tokens': 9, 'total_tokens': 60, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'qwen3-235b-a22b-instruct-2507', 'system_fingerprint': None, 'id': 'chatcmpl-910bacc4-a9ed-9386-b9f7-ce8154cf089a', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} id='run--b89d1aba-db15-41d8-a8ab-4ee8c4e9f28c-0' usage_metadata={'input_tokens': 9, 'output_tokens': 51, 'total_tokens': 60, 'input_token_details': {}, 'output_token_details': {}}
content='你好呀!😊 有什么问题或者需要帮忙的吗?' additional_kwargs={'reasoning_content': '嗯,用户发了个"你好",看起来是个简单的打招呼。我需要回应得友好一些。首先,应该用中文回复,保持口语化。可能用户刚开始对话,想测试系统或者有后续问题。我得先回应问候,然后主动提供帮助,这样用户知道可以继续提问。要避免太机械,加个表情符号显得亲切。比如"你好呀!😊 有什么问题或者需要帮忙的吗?"这样既友好又引导用户进一步互动。检查有没有用专业术语,保持简单。对了,用户可能只是测试,所以保持开放,别假设太多。确认回复符合要求:中文、简洁、有帮助。'} response_metadata={'finish_reason': 'stop', 'model_name': 'qwen3-235b-a22b-thinking-2507'} id='run--36970b85-e6ef-4a76-a09f-e398c508441b-0' usage_metadata={'input_tokens': 9, 'output_tokens': 152, 'total_tokens': 161, 'input_token_details': {}, 'output_token_details': {'reasoning': 134}}
嗯,用户发了个"你好",看起来是个简单的打招呼。我需要回应得友好一些。首先,应该用中文回复,保持口语化。可能用户刚开始对话,想测试系统或者有后续问题。我得先回应问候,然后主动提供帮助,这样用户知道可以继续提问。要避免太机械,加个表情符号显得亲切。比如"你好呀!😊 有什么问题或者需要帮忙的吗?"这样既友好又引导用户进一步互动。检查有没有用专业术语,保持简单。对了,用户可能只是测试,所以保持开放,别假设太多。确认回复符合要求:中文、简洁、有帮助。需要注意的是,Qwen团队目前已不再训练混合推理模型,因此最新发布的模型明确区分为普通模型和推理模型,且不支持在两者之间动态切换或开启/关闭推理模式。 但是闭源模型仍然可以进行开启或者关闭推理模式(混合推理),且默认是非思考模型。 代码如下:
python
from langchain_qwq import ChatQwen
model = ChatQwen(model="qwen-plus-latest", enable_thinking=True, thinking_budget=10)
print(model.invoke("你好"))输出如下:
base
content='你好!有什么我可以帮助你的吗?😊' additional_kwargs={'reasoning_content': '嗯,用户发了个"你好",看起来是个'} response_metadata={'finish_reason': 'stop', 'model_name': 'qwen-plus-latest'} id='run--d64de6fa-8b81-4bd7-b44f-0e3a661e0803-0' usage_metadata={'input_tokens': 9, 'output_tokens': 24, 'total_tokens': 33, 'input_token_details': {}, 'output_token_details': {'reasoning': 10}}除了支持切换思考模式之外,Qwen3 的早期开源模型以及当前的闭源模型还支持通过 thinking_budget 参数来控制推理内容的长度。因此,在上述示例中,你可能会注意到返回的推理内容是不完整的。
更重要的是,使用 ChatQwen 类时,你无需关心所接入的模型是否支持非流式调用。
异步调用
除了invoke当然也支持异步的ainvoke
python
await model.ainvoke("你好")流式输出
python
model = ChatQwen(model="qwen-plus-latest", enable_thinking=True, thinking_budget=10)
# print(model.invoke("你好"))
isfirst = True
isend = True
for msg in model.stream("你好"):
if isinstance(msg, AIMessageChunk) and "reasoning_content" in msg.additional_kwargs:
if isfirst:
print("开始思考")
isfirst = False
print(msg.additional_kwargs["reasoning_content"], end="", flush=True)
elif (
isinstance(msg, AIMessageChunk)
and "reasoning_content" not in msg.additional_kwargs
and msg.content
):
if isend:
print("\n")
print("思考结束")
isend = False
print(msg.content,end="",flush=True)
else:
print(msg.content, end="", flush=True)同样异步也是支持的。 当然你会觉得这样很麻烦,因为思考过程不是直接拼接到content中的,这个库还提供了两个函数用于将这个思考过程拼接到content
python
from langchain_qwq import ChatQwen
from langchain_qwq.utils import convert_reasoning_to_content
model = ChatQwen(model="qwen3-235b-a22b-thinking-2507", enable_thinking=True)
for msg in convert_reasoning_to_content(model.stream("你好")):
print(msg.content,end="")得到的输出如下:
bash
<think>嗯,用户发了个"你好",看起来是打招呼。我得先回应这个问候,保持友好。可能用户刚开始对话,想测试一下我的反应,或者有后续问题要问。
首先,应该用中文回复,因为用户用了中文。要简洁,别太长,但也要有帮助。可能需要提供一些选项,引导用户说出需求。比如问他们需要什么帮助,或者有什么问题。
还要注意语气要亲切,用表情符号可能更友好,但别太多。比如加个微笑或者挥手的emoji。不过用户没用表情,可能偏好正式一点?不确定,但第一次回复可以稍微带点表情。
另外,用户可能不知道能问什么,所以列出几个常见的帮助方向,比如解答问题、创作文字、编程之类的。这样他们知道我的能力范围,更容易提出具体需求。
检查有没有拼写错误,保持句子通顺。比如"你好!有什么我可以帮助你的吗?😊" 然后加几个例子,比如"比如解答问题、创作文字、编程等等。"这样结构清晰。
可能还要考虑用户是新手,不太清楚怎么和AI互动,所以用简单明了的语言。避免专业术语,保持口语化。比如"需要帮忙解答问题,还是想聊聊什么话题?"这样更自然。
最后,确保回复及时,别让用户等太久。不过作为AI,回复速度应该很快,所以没问题。现在组织一下语言,确保覆盖这些点。
</think>你好!有什么我可以帮助你的吗?😊
无论是解答问题、创作文字、编程,还是闲聊,我都很乐意为你提供支持~
需要帮忙吗?工具调用
代码如下:
python
from langchain_core.tools import tool
from langchain_qwq import ChatQwen
@tool
def read_file(path: str) -> str:
"""Read content from a file at the given path. Returns the content of the file."""
with open(path, "r") as f:
content = f.read()
return content
model=ChatQwen(model="qwen-plus-latest")
tool_model = model.bind_tools([read_file],)
print(
tool_model.invoke(
"请分布读取a.txt和b.txt文件返回内容"
)
)思考模式:
python
from langchain_core.tools import tool
from langchain_qwq import ChatQwen
@tool
def read_file(path: str) -> str:
"""Read content from a file at the given path. Returns the content of the file."""
with open(path, "r") as f:
content = f.read()
return content
model=ChatQwen(model="qwen-plus-latest",enable_thinking=True)
tool_model = model.bind_tools([read_file],)
print(
tool_model.invoke(
"请分布读取a.txt和b.txt文件返回内容"
)
)
base
content='' additional_kwargs={'reasoning_content': '好的,用户让我分步读取a.txt和b.txt并返回内容。首先,我需要确认可用的工具。提供的工具是read_file函数,可以读取指定路径的文件内容。\n\n用户需要分别读取两个文件,所以应该调用两次read_file。第一次传入a.txt的路径,第二次传入b.txt的路径。不过要注意路径是否正确,但用户没有提供具体路径,可能默认当前目录。假设文件就在当前目录下,所以参数应该是"a.txt"和"b.txt"。\n\n接下来,我需要按照要求生成两个tool_call,每个对应一个文件。每个tool_call要包含函数名和参数。参数是一个JSON对象,包含path键。所以第一个调用是read_file with path "a.txt",第二个是path "b.txt"。\n\n检查是否需要其他参数,但根据函数定义,只需要path,所以没问题。然后确保每个tool_call都在独立的XML标签里。用户要求分步,所以两个调用分开写,可能需要按顺序执行。\n\n确认无误后,生成对应的tool_call结构。注意JSON格式正确,比如引号使用双引号,没有语法错误。最后输出两个tool_call,每个在各自的tool_call标签中。', 'tool_calls': [{'index': 0, 'id': 'call_662e5e61d3f94f039eb7ee', 'function': {'arguments': '{"path": "a.txt"}', 'name': 'read_file'}, 'type': 'function'}, {'index': 1, 'id': 'call_0ed427dce9c84ee685f89c', 'function': {'arguments': '{"path": "b.txt"}', 'name': 'read_file'}, 'type': 'function'}]} response_metadata={'finish_reason': 'tool_calls', 'model_name': 'qwen-plus-latest'} id='run--f460ee34-694a-41a2-a481-8d132b2d7933-0' tool_calls=[{'name': 'read_file', 'args': {'path': 'a.txt'}, 'id': 'call_662e5e61d3f94f039eb7ee', 'type': 'tool_call'}, {'name': 'read_file', 'args': {'path': 'b.txt'}, 'id': 'call_0ed427dce9c84ee685f89c', 'type': 'tool_call'}] usage_metadata={'input_tokens': 168, 'output_tokens': 302, 'total_tokens': 470, 'input_token_details': {}, 'output_token_details': {'reasoning': 256}}无论是思考模式还是普通的都能正常的返回工具调用,且为了方便开发者,ChatQwen默认会设置parallel_tool_calls参数为true。
结构化输出
python
from pydantic import BaseModel
class User(BaseModel):
name:str
age:int
struct_model=model.with_structured_output(User,method="function_calling")
struct_model.invoke("我叫张三,今年21岁")
python
struct_model=model.with_structured_output(User,method="json_mode")
await struct_model.ainvoke("你好,我叫张三,今年21岁") #这个模式下会关闭思考模型不然会报错ChatQwen支持使用function calling或者json mode实现结构化输出。因此更加稳定。
其它模型示例
python
odel=ChatQwen(model="qwen-flash")
print(model.invoke("你好"))
print(model.bind_tools([get_weather]).invoke("查询西安和温州的天气",parallel_tool_calls=True).tool_calls) #type:ignore
print(model.with_structured_output(User,method="json_mode").invoke("你好,我叫张三,今年21岁"))视觉模型:
python
model=ChatQwen(model="qwen-vl-max-latest")
messages=[
HumanMessage(content=[
{
"type": "image_url",
"image_url": {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"
},
},
{"type": "text", "text": "图中描绘的是什么景象?"},
])
]
print(model.invoke(messages))最新最强的Qwen3-Max
python
from langchain_qwq import ChatQwen
model = ChatQwen(model="qwen3-max-preview")
print(model.invoke("你好"))此外你可以使用这个库接入第三方的Qwen模型,只要是兼容OpenAI风格就行。这意味你自己部署的模型也可以通过这个库接入。
例如
python
os.environ["DASHSCOPE_API_BASE"]="http://localhost:8000/v1"
os.environ["DASHSCOPE_API_KEY"]="sk-1234567890"
model = ChatQwen(model="Qwen/Qwen3-30B-A3B-FP8")
await model.ainvoke("你好")总结
对于这三种方式,我觉得优先考虑方式三、其次是方式一、最后是方式二。 对于方式三,其优点是针对模型进行了优化,但是不能接入百炼其它不支持OpenAI风格的Qwen模型,而方式一则可以接入全部的百炼模型,因此如果你的需求是使用一些不兼容OpenAI的百炼模型,那么选择方式一。且方式一如果你不需要并行工具调用也可以考虑。
组合多个集成方式
上面的三种方式,第三种是目前来看最好的,虽然它不支持非OpenAI风格的模型,但是对于很多项目是够用的,当然如果你有想要同时使用上述的三种方式,也是可以的,无外乎就是安装多个库然后导入嘛,但是这样在项目大的时候非常麻烦,我们希望的是有类似于langchain的init_chat_model的实现方式。于是这里分享一下怎么做可以做到这种方式。 需要安装langchain-dev-utils(也是我的一个开源项目)
bash
uv add langchain-dev-utils
python
from langchain_dev_utils import register_model_provider, load_chat_model
from langchain_qwq import ChatQwen
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_litellm import ChatLiteLLM
register_model_provider("dashscope/qwen", ChatQwen)
register_model_provider("dashscope/tongyi", ChatTongyi)
register_model_provider("dashscope/litellm", ChatLiteLLM)
model1 = load_chat_model("dashscope/qwen:qwen3-max-preview")
model2 = load_chat_model("dashscope/tongyi:qwen3-max-preview")
model3 = load_chat_model("dashscope/litellm:dashscope/qwen3-max-preview")
print(model1.invoke("你好"))
print(model2.invoke("你好"))
print(model3.invoke("你好"))其中register_model_provider对于任何的模型类都只需要调用一次,然后你就可以随时的在该项目任何地方使用load_chat_model这个工具函数加载模型对象了。当然请注意这个函数register_model_provider不要在运行时调用,而是在项目启动的时候完成执行。(因为底层是一个全局字典,因此会有线程安全问题,但是读字典是原子性操作不会有)
对于上述的两个第三方库的github地址如下: langchain-qwq:github.com/yigit353/la... langchain-dev-utils:github.com/TBice123123...
欢迎大家使用,如果使用中有问题也可以提issue,当然最好的给这两个库star。