作者:来自 Elastic Eva Ramon
学习使用 Terraform 部署 GKE,并在 Kubernetes 上通过 ECK 运行 Elastic Stack 组件。
想要获得 Elastic 认证吗?了解下一次 Elasticsearch Engineer 培训的时间!
Elasticsearch 拥有丰富的新功能,可以帮助你为你的使用场景构建最佳搜索解决方案。深入学习我们的示例 notebooks,了解更多信息,开始免费的 cloud 试用,或者现在就在本地机器上尝试 Elastic。
完全托管的服务是运行软件的便捷方式,但根据使用场景,它可能并不总是最佳方法。作为替代方案,Kubernetes (K8s) 为本地和云托管的容器平台带来了 cloud-native 优势。
另一方面,Elastic 提供了全面的工具来保护和监控 cloud-native 环境。在这篇博客中,我想换个角度 ------ 把 Elastic 视为一个分布式的 cloud-native 应用,并遵循 DevOps 的最佳实践来进行部署。
这篇博客反映了我在部署一个小型 Elastic 集群时的经验,该集群利用了 Elastic Cloud on Kubernetes (ECK) 和 Google Kubernetes Engine (GKE)。这并不是一篇安装指南,而是分享在过程中获得的见解。
本次实践涉及的技术包括:
- Terraform:基础设施即代码,用于配置和管理 cloud 资源。
- GKE:Google Cloud Platform (GCP) 上的容器即服务。
- Kubernetes:事实上的容器编排器,用于运行容器化应用,在本例中是容器化的 Elastic Stack。
- ECK:Elastic Cloud on Kubernetes,通过 operator 和自定义资源扩展了 Kubernetes API,使 Elasticsearch 以 cloud-native 应用的形式运行。
这里介绍的方法是完全声明式的。所有 manifest 和文件都在 GitHub 上提供。
1)前置条件
要跟随操作,需要事先准备一些工具和账号,它们的安装和设置不在本博客的范围内。对于 Terraform 部分:
-
本地机器必须安装 Terraform、google-cloud-sdk (gcloud)。
-
需要一个 GCP 账号,最好有一个 Service Account(充当技术用户),并且至少具备创建 VPC、配置 K8s 集群、在 Compute Engine 上启动 VM、以及创建 DNS 记录的必要权限。
注意:我建议在分配 GCP 权限时遵循最小权限原则。尽可能避免分配更广泛的角色,而是只授予严格必要的功能。
并不一定必须是 GKE 集群。Kubernetes 部分的说明适用于任何其他 Kubernetes 基础设施,无论是本地还是云托管。对于这一部分,唯一额外的前置条件是在本地机器上安装 kubectl。
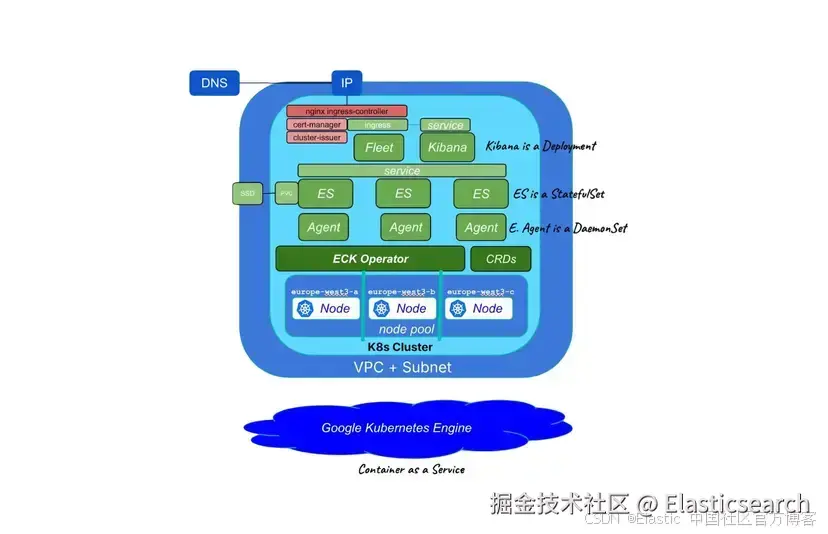
2)架构概览
下图展示了正在部署的元素:Elasticsearch 和 Kibana、一个监控同一 Kubernetes 基础设施的 Elastic Agent,以及一个集中管理 Elastic Agent 配置的 Fleet Server。
所有资源可以分为三类:
-
云基础设施(蓝色表示):通过 Terraform 部署,包括一个带有节点池的 K8s 集群,以及所有必要的网络组件,使我们的 Kibana 可以从外部访问。
-
Elastic 资源(绿色表示):通过 K8s manifest 作为自定义资源部署,包括 Elasticsearch、Kibana、Elastic Agent 和 Fleet,以及对应的 Service 和 Persistent Volume。
-
额外的 K8s 资源(红色表示):通过 Terraform 和 Helm Chart 部署的 Ingress Controller 和 Certificate Manager,以及通过 K8s manifest 部署的 Cluster Issuer。
3)云基础设施
本示例中的云基础设施将托管在 GCP 上,利用 Google Kubernetes Engine (GKE) 作为容器平台。
如果你已经有一个运行中的 K8s 集群,或者你更喜欢在本地或其他云提供商上设置自己的集群,可以跳过这一部分。
Terraform 是一个开源的基础设施即代码 (open-source infrastructure-as-code - IaC) 工具,用于定义和配置基础设施资源,包括 Kubernetes 集群和网络资源。
Terraform 示例文件可在 GitHub 仓库中找到。该仓库包含一个模块化的 Terraform 结构,其中主 terraform 目录下的 main.tf 定义了要应用的模块。在本示例中,仅使用其中两个模块:
-
GKE:配置 GKE 集群及相关资源。
-
Helm:使用 Helm chart 部署必要的 K8s 工具。
在 GKE 模块的 main.tf中定义了以下云资源:
-
一个 VPC (Virtual Private Cloud) 网络和一个子网。
-
一个公共静态 IP,用于将 Kibana 服务暴露到 K8s 集群外部。
-
一个带有自定义节点池的 K8s 集群,可以指定使用的硬件等设置。因此,在创建时需要立即移除默认的节点池。
-
一个单独管理的节点池,包含三个工作节点,以便将 Elastic 集群分布在三个不同的可用区。通过定义一个区域并设置 node_count = 1,可以在该区域的每个可用区各部署一个节点。
-
一个 A 类型的 DNS 记录,指向该公共 IP 地址。
在 Helm 模块的 main.tf 中安装了以下应用:
-
Ingress Nginx Controller:用于管理 SSL 终止并将外部请求路由到 Kibana 服务。
-
Certificate Manager:为 Kibana 端点签发可信证书,这些证书由 Mozilla 的 Let's Encrypt 证书机构签发。
-
Kube-state-metrics:一个从 GKE 集群中暴露遥测数据的工具。
此设置的一个有趣之处在于,GKE 模块的一些输出会直接作为输入参数传递给 Helm 模块。例如,新建的公共 IP 地址会作为参数传递给随后创建的 Ingress Nginx Controller。这就是为什么这些资源的安装直接由 Terraform 管理,而不是包含在后续部署的 K8s manifest 中。
注意:此配置固定了已知的稳定版本(ingress-nginx v1.10.1 和 cert-manager v1.13.3),以避免后续版本中的破坏性更改。对于生产环境,建议始终检查更新的版本。
在运行 Terraform 创建资源之前,必须提供 terraform 目录下 variables.tf 文件中定义的必要参数 ------ 可以通过创建一个 var 文件(例如 myvars.tfvars)来包含它们,或者在执行 terraform apply 命令时直接传递每个参数。
声明变量后,仍在 terraform 文件夹中,初始化 Terraform:
csharp
`terraform % terraform init`AI写代码然后应用配置:
ini
`terraform % terraform apply --var-file=myvars.tfvars`AI写代码在提示时输入 "yes" 进行确认,然后去喝杯咖啡------这将需要几分钟时间,特别是节点池的创建。
Terraform 成功完成后,初始化 Google Cloud SDK:
csharp
`terraform % gcloud init`AI写代码然后配置 gcloud 使用新 Kubernetes 集群的凭据,从而启用 kubectl 访问:
erlang
`
1. terraform % gcloud container clusters get-credentials $(terraform output -raw gke_cluster_name) --region $(terraform output -raw gke_cluster_region)
2. Fetching cluster endpoint and auth data.
3. kubeconfig entry generated for eva-eck-gke.
`AI写代码该命令之所以有效,是因为 gke_cluster_name 和 gke_cluster_region 已定义为 Terraform 输出。
完成后,kubectl 命令行工具已配置为与新的 GKE 集群交互:
arduino
`
1. terraform % kubectl cluster-info
2. Kubernetes control plane is running at https://...
`AI写代码GCP 控制台应类似如下:
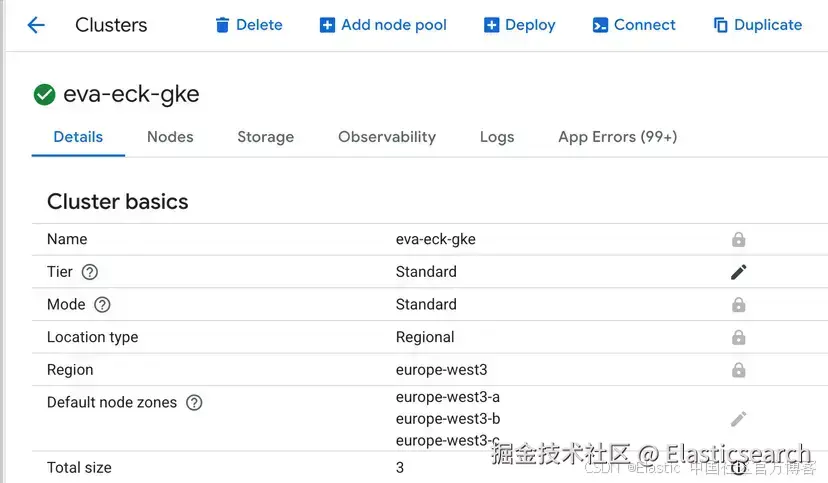
4)Kubernetes
Kubernetes:开源的容器编排系统,用于自动化部署、扩展和管理容器化应用。该项目由 Cloud Native Computing Foundation 托管。
与 Kubernetes 集群交互需要使用 kubectl 命令行工具,它有两种使用方式:
-
命令式方式:向 K8s 控制平面发送命令,告诉它你想做什么。
-
声明式方式:在 YAML 文件中定义期望的集群状态,该文件称为 manifest,然后控制平面负责执行所有步骤以达到该状态。
采用声明式方法是 cloud-native 思维的最佳实践:它促进幂等性、更容易的版本控制和自动化。让我们通过查看集群的工作节点来实践一下:
markdown
`
1. terraform % kubectl get nodes
2. NAME STATUS ROLES AGE VERSION
3. gke-eva-4ebcee09-w534 Ready <none> 36m v1.33.3-gke.1136000
4. gke-eva-5983ceac-xxcx Ready <none> 36m v1.33.3-gke.1136000
5. gke-eva-f3b02c55-jz82 Ready <none> 36m v1.33.3-gke.1136000
`AI写代码正如预期,Kubernetes 集群由三个工作节点组成,均匀分布在该区域的三个可用区。这种配置非常适合运行一个包含三个节点的小型 Elasticsearch 集群。
Elastic Cloud on Kubernetes
此时,Kubernetes 集群已运行并准备好承载我们的 cloud-native Elastic 部署。运行 Elastic 作为容器化应用的推荐方式是使用 Elastic Cloud on Kubernetes (ECK)。
5.1. 自定义资源定义
Custom Resources 是对 Kubernetes API 的扩展。Custom Resource Definitions (CRD) 告诉 K8s 控制器如何将 Custom Resources 作为 K8s 对象进行管理。
Custom Resource Definitions (CRDs) 用于将 Elasticsearch 组件管理为标准 K8s 资源。
要安装 CRD,进入 k8s 目录并使用 kubectl 应用 manifest:
bash
`k8s % kubectl create -f https://download.elastic.co/downloads/eck/3.1.0/crds.yaml`AI写代码5.2. ECK Operator
Operators 是 Kubernetes 的软件扩展,使用 Custom Resources 来管理应用及其组件。
基于 Kubernetes Operator 模式,ECK 扩展了基本的 Kubernetes 编排能力,以支持在 Kubernetes 上设置和管理 Elasticsearch、Kibana、APM Server、Enterprise Search、Beats、Elastic Agent、Elastic Maps Server 和 Logstash。
要安装 ECK operator,使用 kubectl 应用 manifest,就像之前为 CRD 做的那样:
bash
`k8s % kubectl apply -f https://download.elastic.co/downloads/eck/3.1.0/operator.yaml`AI写代码elastic operator 运行在 elastic-system 命名空间中。我们可以查看该命名空间中运行的 pod,以确认 operator 是否已启动并运行:
markdown
`
1. k8s % kubectl get pods -n elastic-system
2. NAME READY STATUS RESTARTS AGE
3. elastic-operator-0 1/1 Running 0 4m41s
`AI写代码为了确认是否正确运行,我们也可以查看 operator 的日志:
arduino
`k8s % kubectl -n elastic-system logs statefulset.apps/elastic-operator`AI写代码5.3. 部署 Elasticsearch
此时,ECK operator 已运行,CRD 已安装在 Kubernetes 集群上。现在是部署 Elasticsearch 和 Kibana 的时候了。
为了保持整洁和有序,我个人喜欢使用 Kustomize,这是一种通过 kustomization.yaml 文件自定义 Kubernetes 对象的工具。
k8s/elasticsearch/base 目录下的 kustomization.yaml 包含一个基础的 Elastic 安装,并引用了 Elasticsearch 和 Kibana 的 manifest。
注意 :manifest 可以从头编写、根据此示例进行调整,或者仅作为参考。我建议查看官方 ECK 文档。
让我们浏览 elasticsearch.yaml manifest 中最相关的部分。
对象配置(K8s):
markdown
`
1. apiVersion: elasticsearch.k8s.elastic.co/v1
2. kind: Elasticsearch
3. metadata:
4. name: elasticsearch
5. spec:
6. version: 9.1.2
7. http:
8. service:
9. spec:
10. type: ClusterIP
`AI写代码在此指定了版本为 9.1.2(本文撰写时的最新版本)的 Elasticsearch 类型资源。由于 Elasticsearch API 未对外暴露,服务类型为 ClusterIP。
注意:在生产环境中,可以使用顶层 Kustomize overlay 来集中覆盖 spec.version 参数。
资源配置(Elasticsearch):
yaml
`1. nodeSets:
2. - name: data
3. count: 3`AI写代码声明了一个包含三个节点的 node set。每个节点将拥有所有角色(master、data 和 ml),因此无需专门声明节点类型。
Pod 模板配置:
markdown
`1. podTemplate:
2. spec:
3. containers:
4. - name: elasticsearch
5. resources:
6. requests:
7. memory: 2Gi
8. cpu: 1
9. limits:
10. memory: 2Gi
11. cpu: 2` AI写代码对于每个容器,必须定义资源请求和限制,这是 Kubernetes 的最佳实践。对于这个小型用例,每个 Elasticsearch 节点分配 2 GB RAM 和 1 个虚拟核心(CPU 限制为 2,以便于垃圾回收)。
markdown
`1. volumeClaimTemplates:
2. - metadata:
3. name: elasticsearch-data
4. spec:
5. accessModes:
6. - ReadWriteOnce
7. resources:
8. requests:
9. storage: 2Gi` AI写代码为了管理存储,我们使用 Persistent Volumes。云提供商提供 Storage Classes,通过 Persistent Volume Claim,pod 可以请求一个存储卷。这正是我们在这里做的:每个 Elasticsearch 节点请求一个容量为 2 GB 的卷。
根据最佳实践,分布式应用应尽可能保持无状态。Kubernetes 本身支持大部分这些原则,并提供相应机制。但像 Elasticsearch 这样的数据库和数据存储呢?
数据存储本质上是有状态的。Kubernetes 通过 StatefulSets 处理这种情况。ECK 将 Elasticsearch 部署定义为 StatefulSet,以确保 Elasticsearch 节点始终部署在同一工作节点上,并附加本地存储。
此外,ECK 应用反亲和性规则(anti-affinity rules),避免将主分片和其副本调度到同一工作节点,从而在机器故障时保证数据冗余。
注意 :Elastic 还允许通过 Elastic Stack Configuration Policies 将声明式方法扩展到集群部署之外,实现集群设置、生命周期管理、ingest pipelines、安全设置等的配置即代码。
5.4. 部署 Kibana
kibana.yaml manifest 的结构类似。让我们看看配置中的相关部分。
对象配置(K8s):
markdown
`
1. apiVersion: kibana.k8s.elastic.co/v1
2. kind: Kibana
3. metadata:
4. name: kibana
5. spec:
6. version: 9.1.2
7. count: 1
8. elasticsearchRef:
9. name: elasticsearch
10. http:
11. service:
12. spec:
13. type: ClusterIP
14. tls:
15. selfSignedCertificate:
16. disabled: true
`AI写代码我们指定了一个版本为 9.1.2(本文撰写时的最新版本)的 kibana 类型资源实例。声明 elasticsearchRef 让 Kibana 知道要连接哪个 Elastic 实例,而无需指定端点。
服务类型为 ClusterIP:Kibana 服务不会直接暴露,而是通过 Ingress Controller,如下所述。Ingress 是 Kubernetes 的一种机制,用于暴露 HTTP(s) 服务。TLS 被禁用,因为我更喜欢直接在 Ingress 上进行 SSL 终止,而不是在应用层。
Pod 模板配置:
markdown
`1. podTemplate:
2. spec:
3. containers:
4. - name: kibana
5. resources:
6. requests:
7. memory: 1Gi
8. cpu: 1
9. limits:
10. memory: 1Gi
11. cpu: 1`AI写代码与 Elasticsearch 一样,定义了资源请求和限制。对于本示例中的单个 Kibana 实例,1 GB RAM 和 1 个 CPU(虚拟核心)就足够了。
关于持久性,Kibana 是无状态的:我们不需要关心存储,也不需要将容器固定到特定工作节点。Kibana 是一个 Deployment。
考虑到所有 manifest 的正确设置需要时间和精力;然而,从现有 manifest 部署 Elasticsearch 和 Kibana 的速度如下:
markdown
`
1. base % kubectl apply -k .
2. elasticsearch.elasticsearch.k8s.elastic.co/elasticsearch created
3. kibana.kibana.k8s.elastic.co/kibana created
`AI写代码在列出正在运行的 pod 时,应该有三个 Elasticsearch 节点------每个运行在不同的工作节点上 ------ 以及一个 Kibana 节点:
markdown
`
1. base % kubectl get pods -o wide
2. NAME READY STATUS NODE
3. elasticsearch-es-data-0 1/1 Running gke-eva-4ebcee09-l5sf
4. elasticsearch-es-data-1 1/1 Running gke-eva-5983ceac-6rj4
5. elasticsearch-es-data-2 1/1 Running gke-eva-f3b02c55-qh42
6. kibana-kb-747b77875d-dw5c6 1/1 Running gke-eva-4ebcee09-l5sf
`AI写代码由于 Elasticsearch 是一个自定义资源,可以列出所有 "Elasticsearches":
markdown
`
1. base % kubectl get elasticsearch
2. NAME HEALTH NODES VERSION PHASE AGE
3. elasticsearch green 3 9.1.2 Ready 4m1s
`AI写代码也可以列出所有 "Kibanas":
markdown
`
1. base % kubectl get kibana
2. NAME HEALTH NODES VERSION AGE
3. kibana green 1 9.1.2 22h
`AI写代码在本示例中,外部访问完全由 Ingress Controller 管理,Kibana 被配置为唯一面向互联网的组件。Cert-manager 和 Let's Encrypt 用于自动为 Ingress Controller 签发可信 TLS 证书。
注意:另外,也可以通过将 Kibana(或 Elasticsearch)的服务类型设置为 LoadBalancer,依赖云提供商提供的负载均衡器资源。
使用的 Ingress Controller 是 ingress-nginx,它在本博客的第一部分通过 Terraform 安装。Ingress 资源的配置定义在 k8s/elasticsearch/ingress 目录下的 ingress.yaml 文件中。
注意:GitHub 中的 ingress.yaml.sample 文件包含占位符------必须编辑以指向实际托管 Kibana 的域名,并重命名为 ingress.yaml。
在 k8s/elasticsearch/ingress 目录下应用 Ingress 和 Issuer manifest:
go
`ingress % kubectl apply -k .`AI写代码要获取默认 "elastic" 用户的默认密码,运行以下命令:
arduino
`ingress % kubectl get secret elasticsearch-es-elastic-user -o go-template='{{.data.elastic | base64decode}}'`AI写代码一分钟后,你应该可以通过浏览器访问你的 Kibana 实例:
像往常一样,Kibana 是面向用户的组件,将所有内容联系在一起。
5.5. Fleet 和 Elastic Agent
将数据导入 Elastic 通常需要 Elastic Agent(或 Beats 和/或 Logstash,或者它们的组合)。在本示例中,通过 Kubernetes Integration 将 Kubernetes 日志和指标导入 Elasticsearch。Fleet 在 Kibana 中提供了一个集中管理 agent 配置的中心。
注意:作为替代方案,也可以直接在 ConfigMap 中定义 agent 配置,而不使用 Fleet。
为了允许 Kubernetes integration 收集集群数据,必须安装 kube-state-metrics。在本博客中,它是通过 Terraform Helm 模块中包含的 Helm chart 在配置云基础设施时安装的。
注意:Kubernetes integration 仅用于说明 Elastic Agent 的配置和部署示例。Kubernetes 可观测性不在本博客的范围内。
Fleet 和 Elastic Agent 的 kustomization.yaml 有一些不同,引入了 overlay 的概念:在运行的基础安装之上,部署新资源并对现有资源进行 patch。
通过 kibana-patch.yaml,修改正在运行的 Kibana 实例的 manifest,以包含 Elastic Agent 的集中配置:
yaml
`1. config:
2. xpack.fleet.agents.fleet_server.hosts: ["http://fleet-server-agent-http.default.svc:8220"]
3. xpack.fleet.agents.elasticsearch.hosts: ["https://elasticsearch-es-http.default.svc:9200"]
4. xpack.fleet.packages:
5. - name: fleet_server
6. version: latest
7. - name: kubernetes
8. version: latest
9. xpack.fleet.agentPolicies:
10. - name: Fleet Server on ECK policy
11. id: eck-fleet-server
12. ...
13. - name: Elastic Agent on ECK policy
14. id: eck-agent`AI写代码packages 和 agent 策略配置包含在 config 部分,同时还包括 agent 访问 Elasticsearch 和 Fleet Server 的端点。
关于 elastic-agent.yaml manifest,让我们看看一些重要方面:
markdown
`
1. apiVersion: agent.k8s.elastic.co/v1alpha1
2. kind: Agent
3. metadata:
4. name: elastic-agent
5. spec:
6. version: 9.1.2
7. kibanaRef:
8. name: kibana
9. fleetServerRef:
10. name: fleet-server
11. mode: fleet
12. policyID: eck-agent
`AI写代码agent 已注册到用于 K8s integration 的 agent 策略中,Fleet Server 通过 fleetServerRef 被引用。
markdown
`1. daemonSet:
2. podTemplate:
3. spec:
4. ...
5. volumes:
6. - hostPath:
7. path: /var/lib/elastic-agent
8. type: DirectoryOrCreate
9. name: elastic-agent-state`AI写代码Elastic Agent 以 DaemonSet 形式部署:对于 Kubernetes integration,每个工作节点上必须运行一个 agent。一个映射到工作节点本地目录的小型 Persistent Volume 为 agent 状态提供持久性。
最后,关于 fleet-server.yaml manifest,有几个要点需要强调:
markdown
`
1. apiVersion: agent.k8s.elastic.co/v1alpha1
2. kind: Agent
3. metadata:
4. name: fleet-server
5. spec:
6. version: 9.1.2
7. kibanaRef:
8. name: kibana
9. elasticsearchRefs:
10. - name: elasticsearch
11. mode: fleet
12. fleetServerEnabled: true
13. policyID: eck-fleet-server
`AI写代码Fleet 本质上是一个 Elastic Agent,因此它是 kind 为 "Agent" 的资源。Kibana 和 Elasticsearch 分别通过 kibanaRef 和 elasticsearchRefs 被引用。Fleet 已注册到 Fleet integration 的 agent 策略中。
在 k8s/elasticsearch/fleet 目录下应用 Elastic Agent 和 Fleet 的 manifest:
markdown
`
1. fleet % kubectl apply -k .
2. serviceaccount/elastic-agent created
3. serviceaccount/fleet-server created
4. kibana.kibana.k8s.elastic.co/kibana configured
`AI写代码监控正在运行的 pod 可以让我们知道 Fleet 何时可用:
markdown
`
1. fleet % kubectl get pods -l agent.k8s.elastic.co/name
2. NAME READY STATUS AGE
3. elastic-agent-agent-rdwnq 1/1 Running 5m39s
4. elastic-agent-agent-rqkzc 1/1 Running 5m39s
5. elastic-agent-agent-v8kdt 1/1 Running 5m39s
6. fleet-server-agent-579b948f49-hzbmx 1/1 Running 5m40s
`AI写代码与 Elasticsearch 和 Kibana 类似,也可以列出 "agent" 自定义资源:
markdown
`
1. fleet % kubectl get agent
2. NAME HEALTH AVAILABLE EXPECTED VERSION AGE
3. elastic-agent green 3 3 9.1.2 6m15s
4. fleet-server green 1 1 9.1.2 6m15s
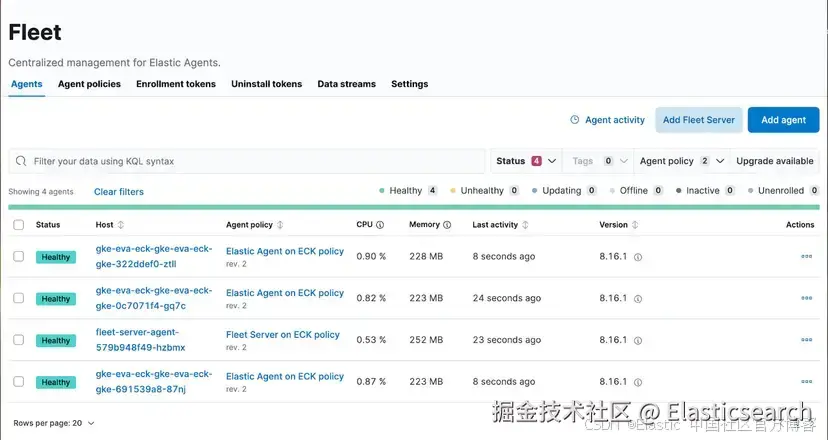
`AI写代码在 Kibana 中,Fleet 部分现在可用,K8s integration 应该正在传输数据。
总结
一旦所有内容以代码声明,并且所有 manifest 和配置文件就位,设置云基础设施并使用 ECK 启动 Elasticsearch 集群就很简单。
对我来说,这种方法真正体现了 cloud-native 的核心,以及分布式应用的本质。玩得开心 :)
这篇博客是人工撰写的,因为作者坚信写作 ------ 即便是技术写作------是个人表达的基本方式。